Dify智能体
安装注意事项
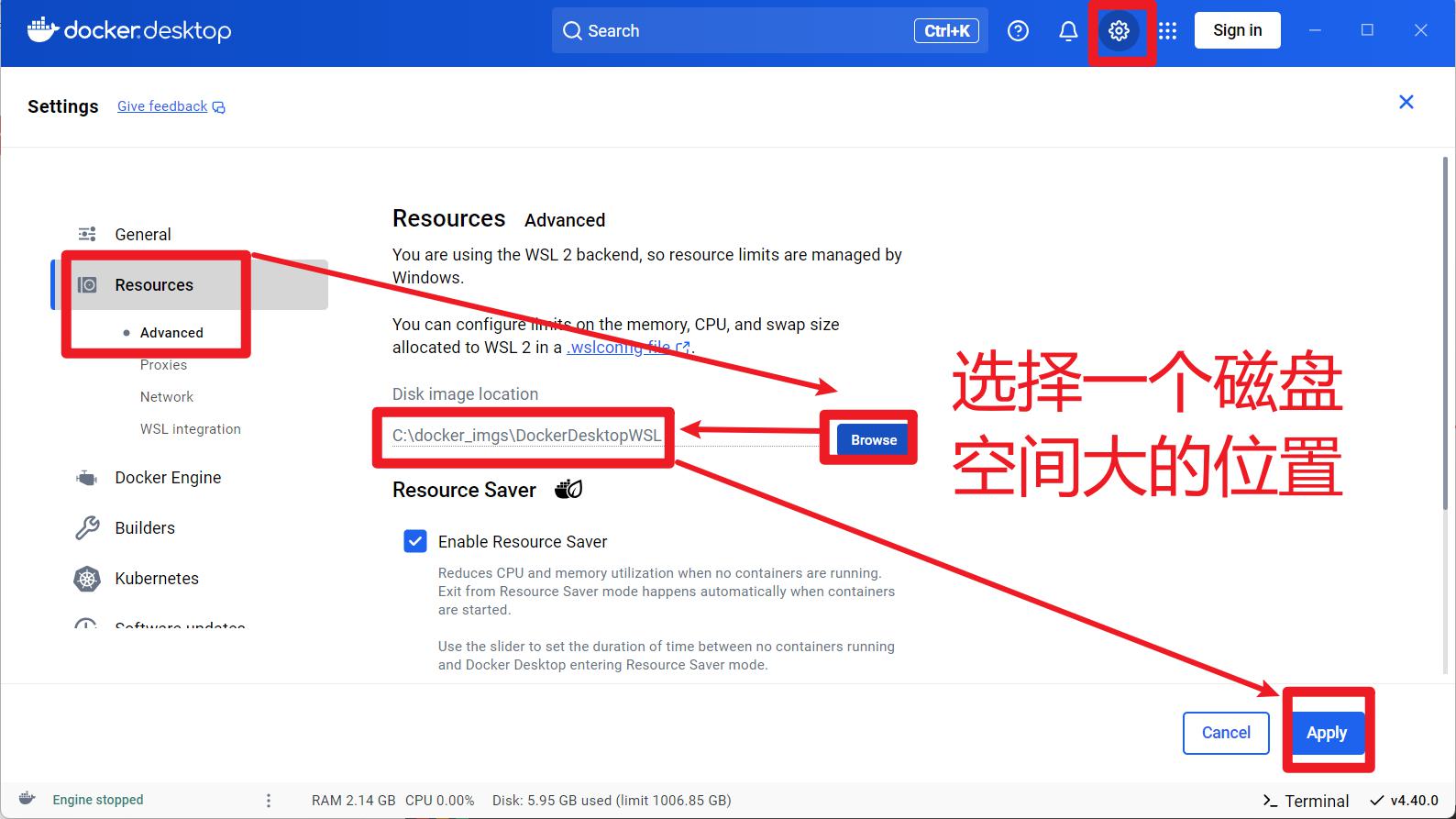
注意:Docker的镜像默认安装在C盘
PDF上面的内容复制之后有空格
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://hub-mirror.c.163.com",
"https://docker.m.daocloud.io",
"https://registry-1.docker.io"
]
}
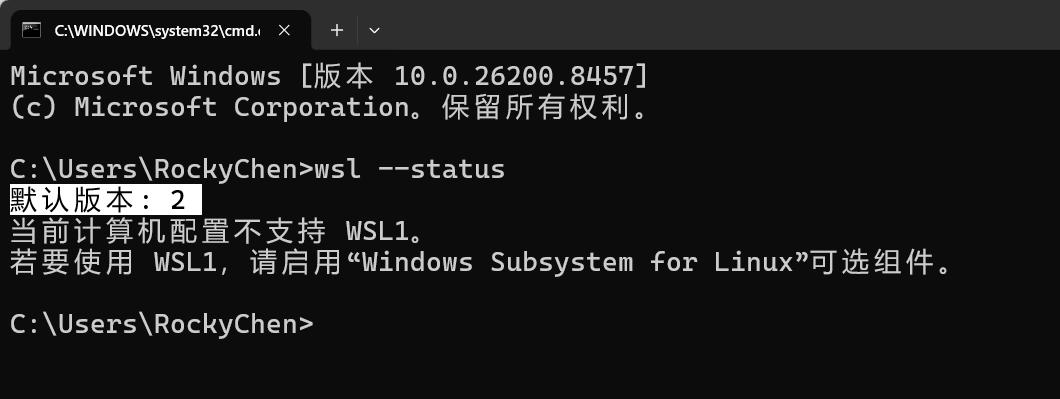
WSL2选项没有的处理办法
安装docker之前,将如下的两个命令执行一下
如果在安装docker的时候没有出来WSL2的选项,按照如下的操作执行
wsl --status
wsl --set-default-version 2
其他需要用到的命令
Add-AppxPackage D:\上课\广州AI_8期\02_智能体平台开发\03_Dify智能体\05_资料\CanonicalGroupLimited.UbuntuonWindows_2004.2021.825.0.AppxBundle
前提: docker是一个启动的状态
docker load -i D:\上课\广州AI_8期\02_智能体平台开发\03_Dify智能体\05_资料\all-docker-images.tar
docker compose up -d
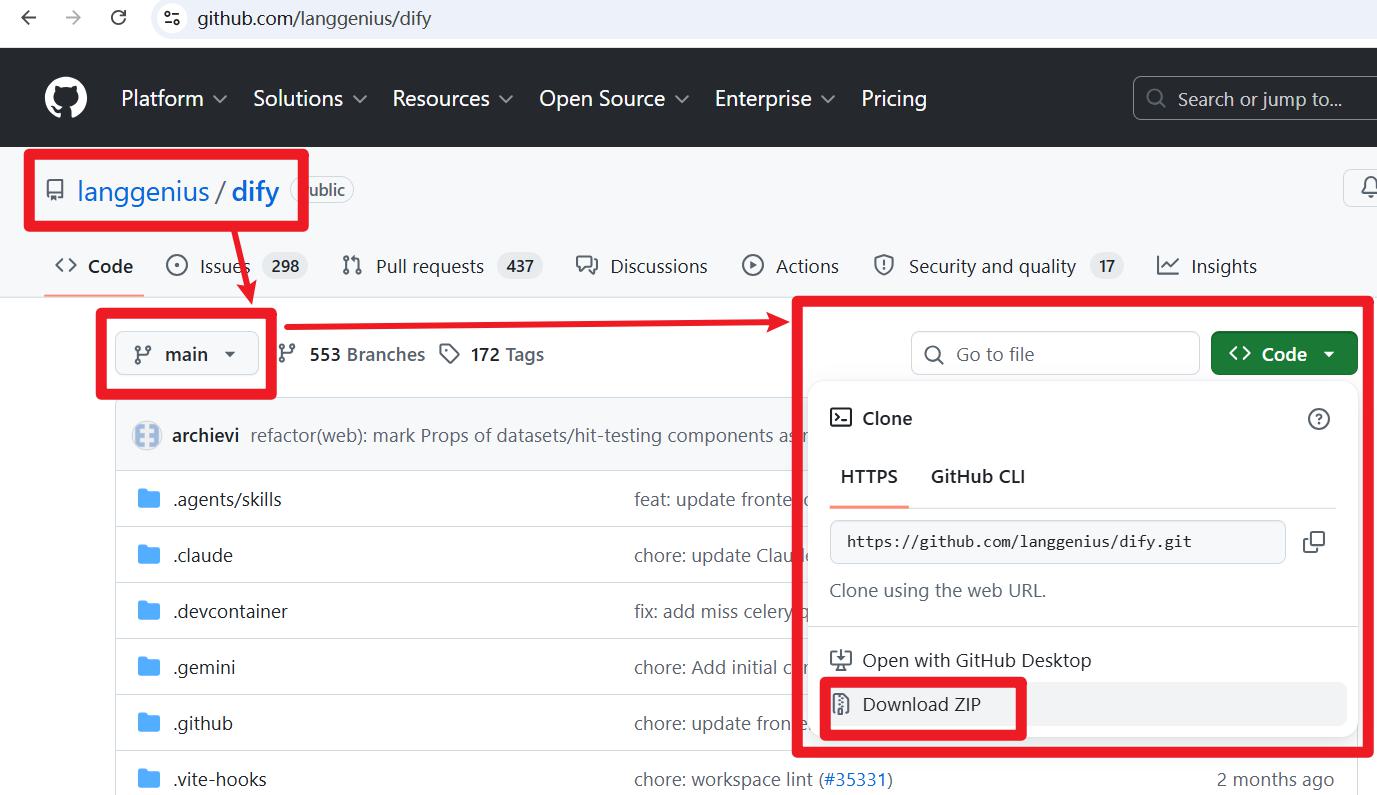
dify-main.zip压缩包的来源
下载地址:https://github.com/langgenius/dify
基本介绍
Coze和Dify区别
相同点
都是智能体开发编排平台,都是低代码,鼠标操作开发智能体。都是在浏览器内拖拉拽开发智能体工作流
不同点
Coze是无需安装,打开Coze网站即可使用。SaaS平台(公网服务)
Dify是需要安装的,安装后打开网站使用。私有化部署平台(私网服务)
为什么用Dify
- 企业数据敏感,不能上传到公网中。Coze就不能用,因为Coze是公网服务
- 有的企业或者项目,本身就是涉密的,更不能用Coze的,甚至员工都没网(连接公网)
- 企业要自行定制平台,做二次开发(Coze也不行)
Dify就可以:
Dify是自己安装自己部署,可以安装到自己企业内部的服务器内,在内部网络中提供服务,避免数据安全问题。
Dify是开源的(开放源代码),企业就可以二次修改,
https://github.com/langgenius/Dify
模型类型
- 推理模型(LLM 大语言模型):用于推理、思考、文字生成
- 嵌入模型(Embedding Model):用于生成文本向量
- 重排模型(Rerank Model):用于排序混合检索结果
- 语音转文字模型(ASR Model),语音转文字
- 文字转语音模型(TTS Model),文字转语音
Dify开发
Dify配置阿里云百炼平台
安装插件
插件下载地址:https://marketplace.dify.ai/
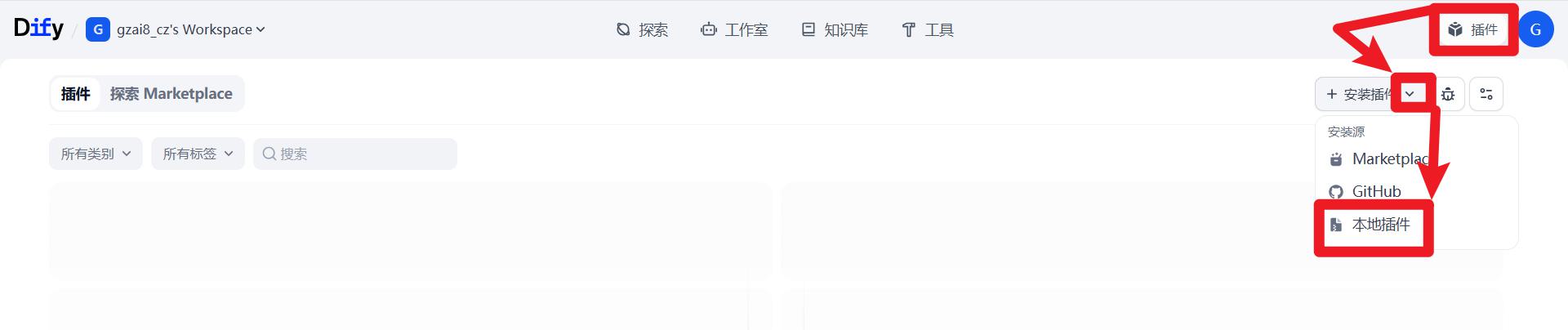
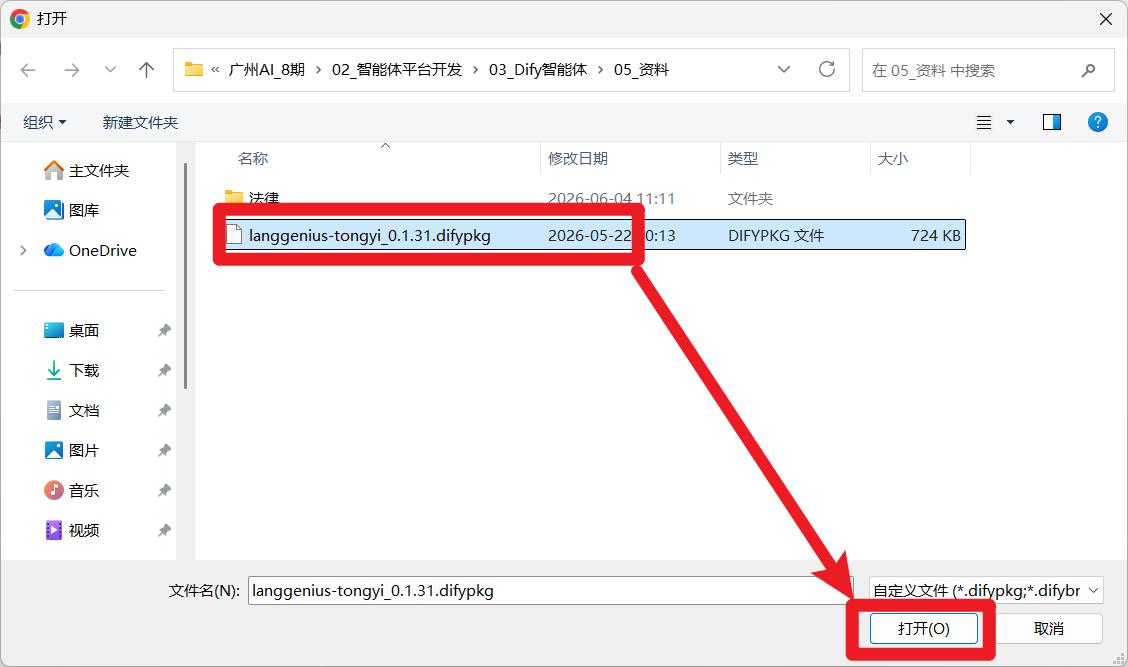
安装好这个插件,如下图:
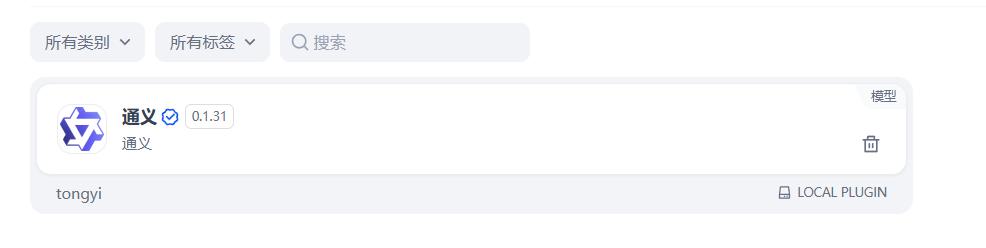
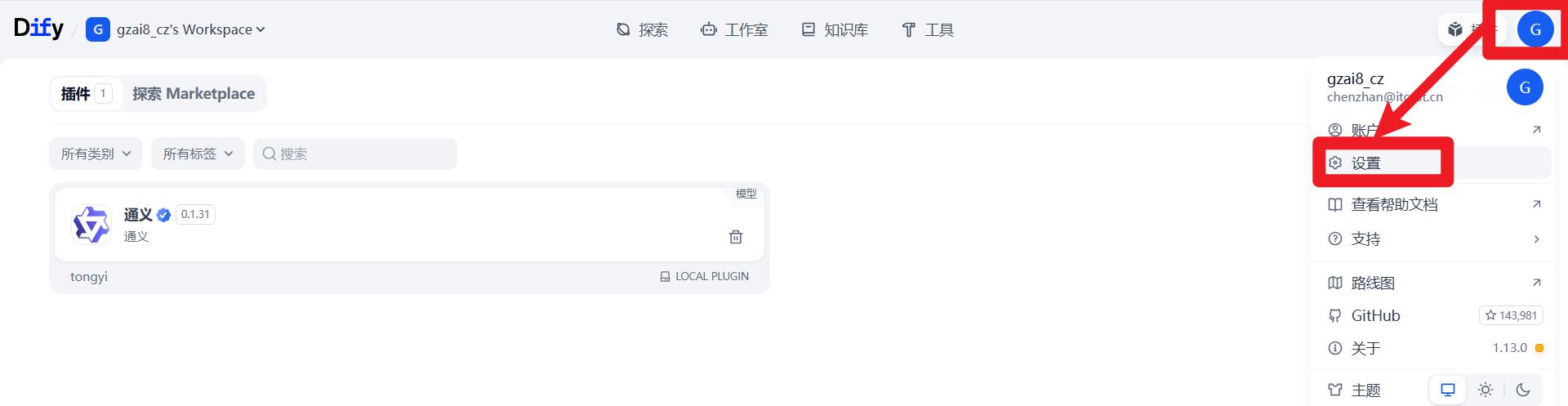
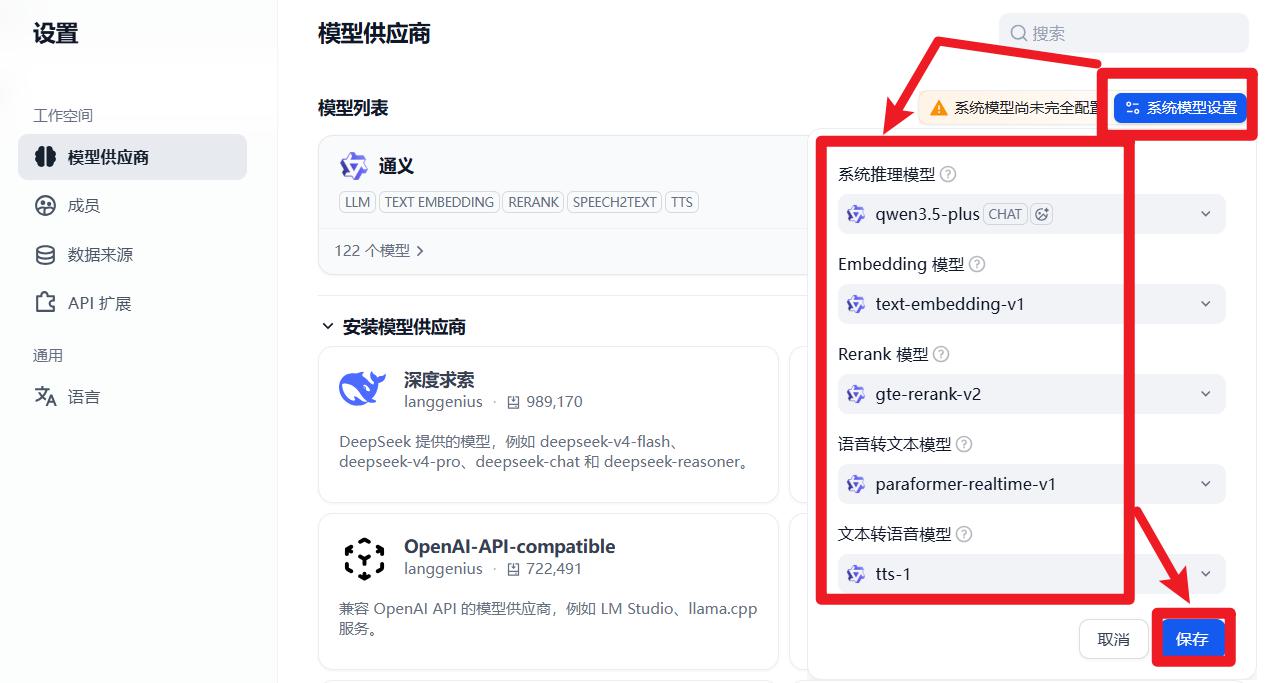
配置模型提供商
- 进入设置
- 填入你自己的阿里百炼平台上的APIKEY
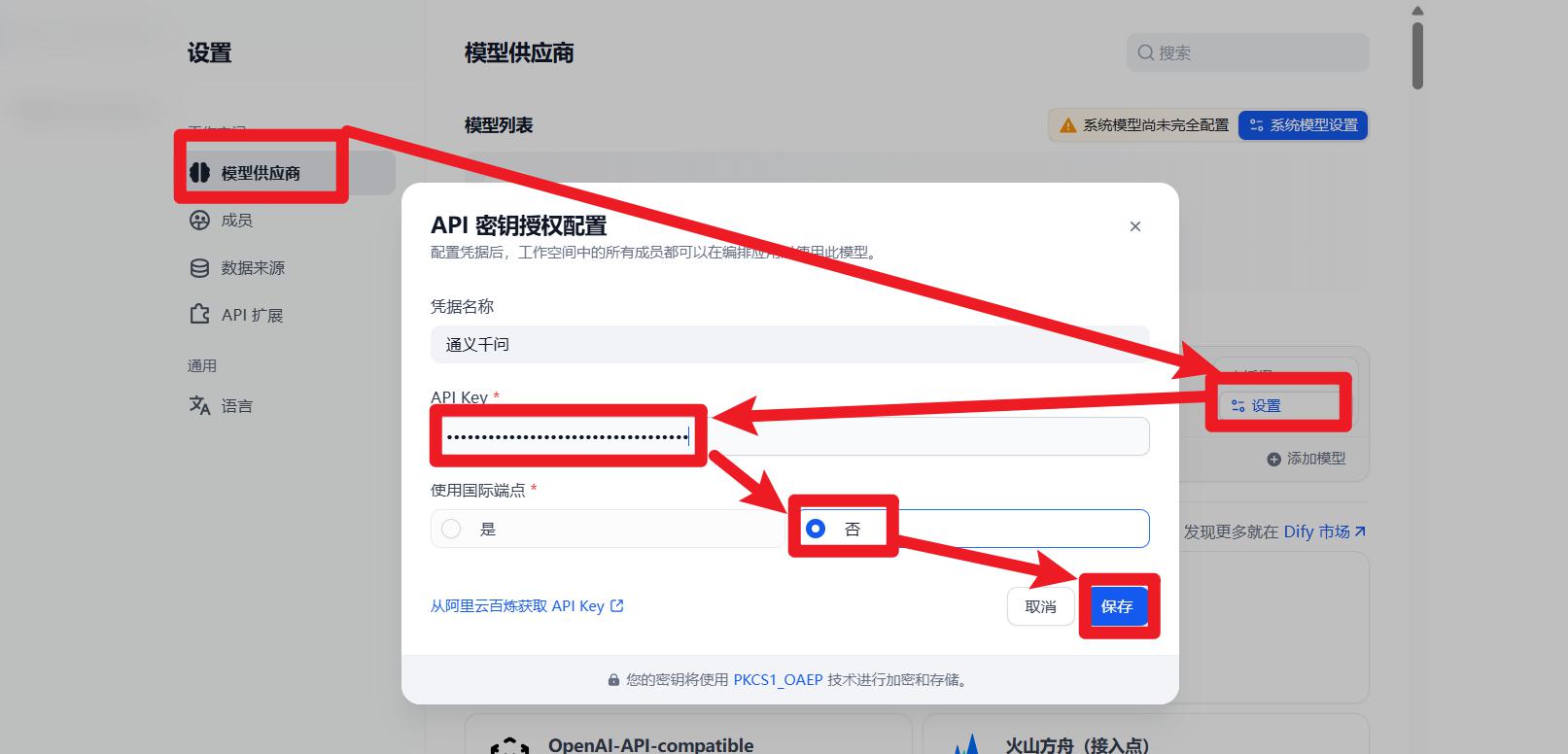
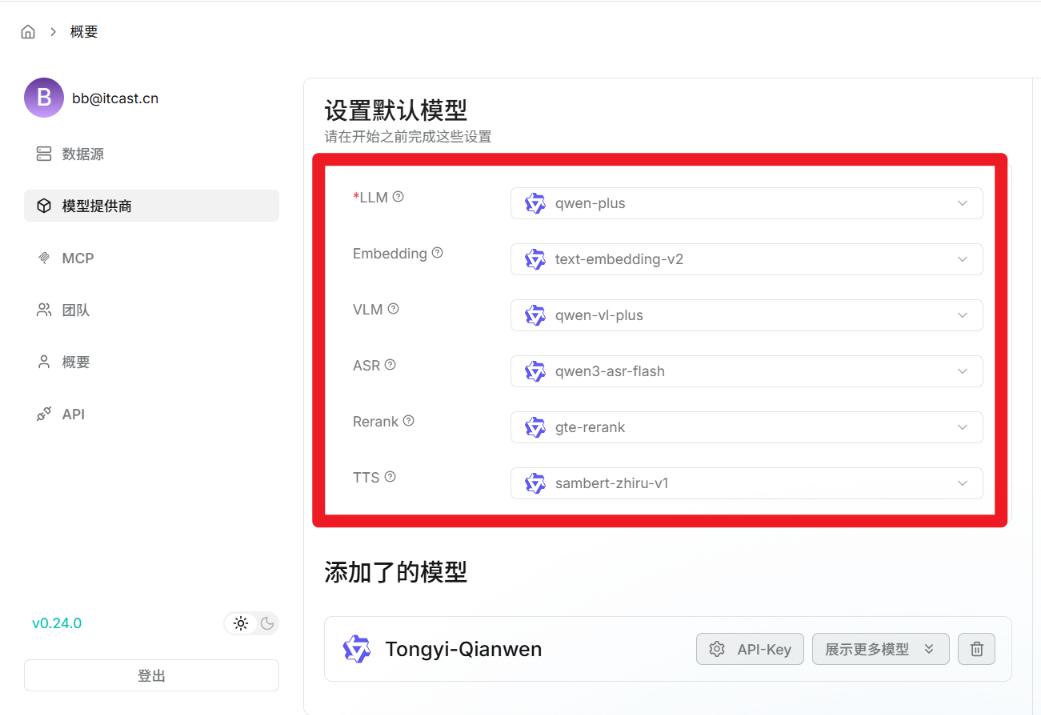
- 配置Dify平台用的默认模型
开发第一个工作流
- 创建空白应用
- 填写信息
- 选择用户输入作为开始节点
- 添加节点并连线
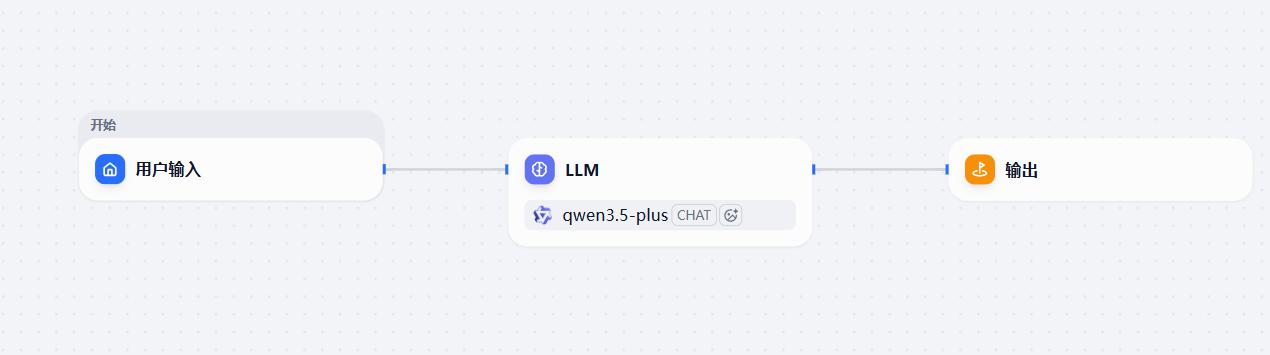
- 配置:用户输入
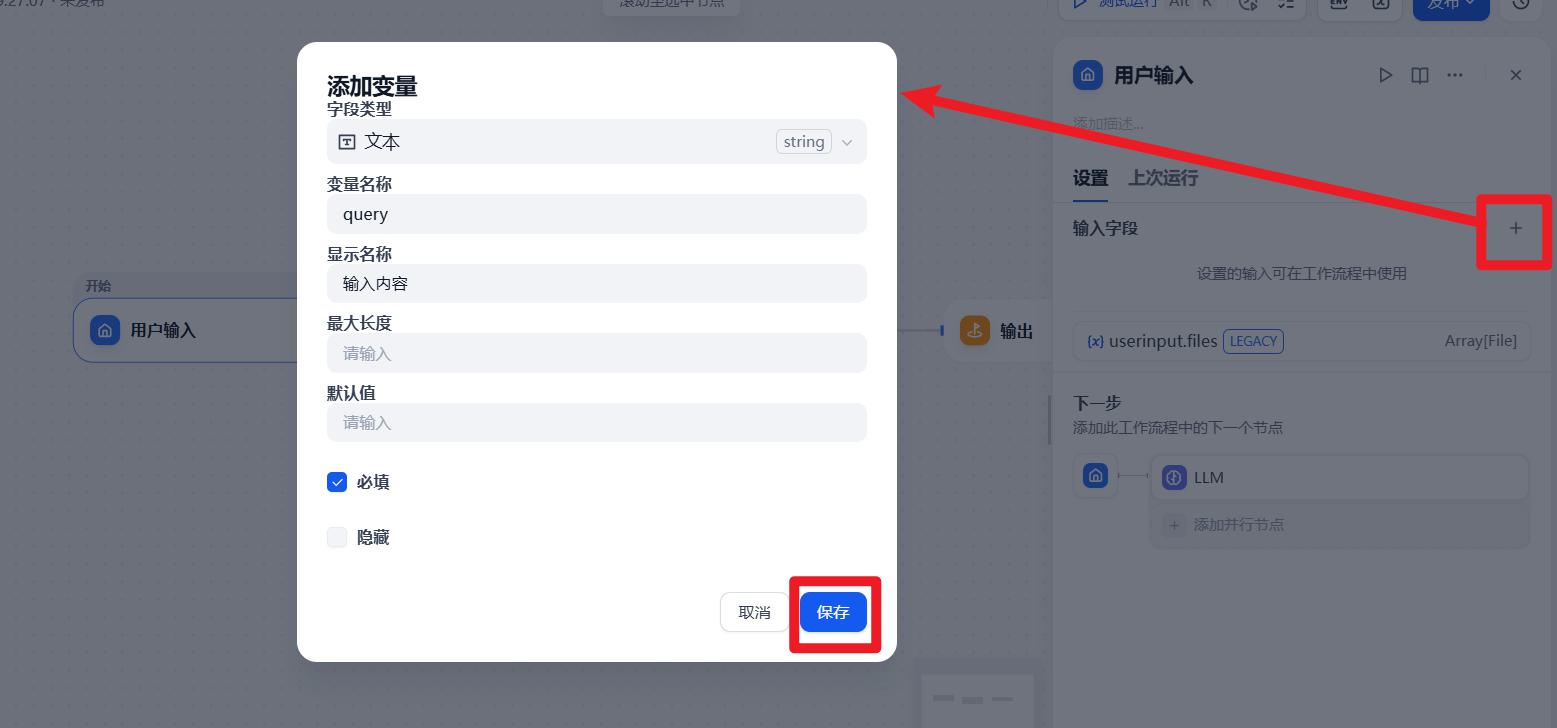
- 配置:大模型
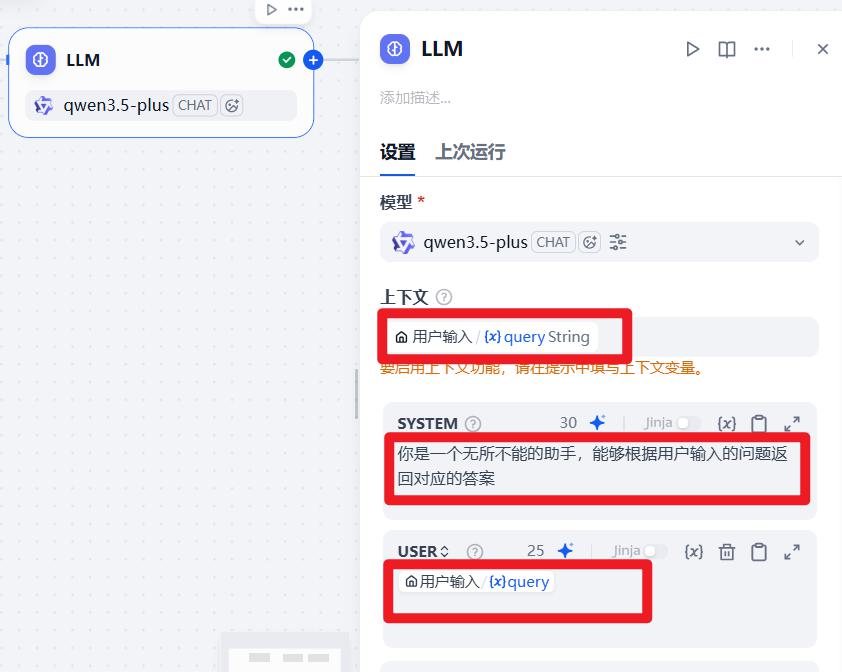
系统提示词:
你是一个无所不能的助手,能够根据用户输入的问题返回对应的答案
- 配置:输出
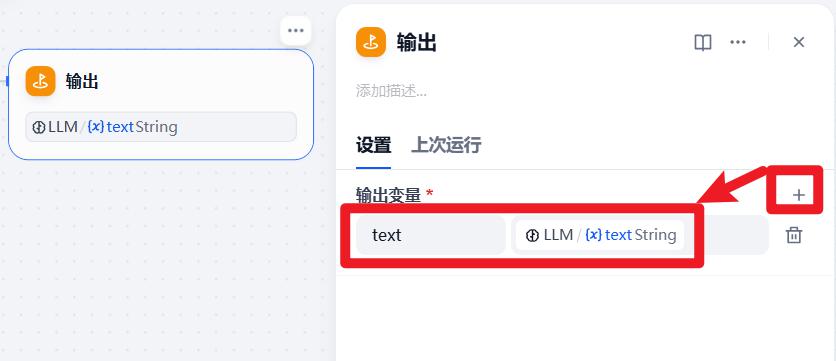
- 试运行
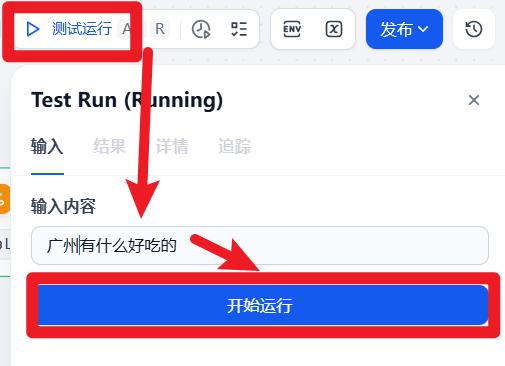
工作流案例-大语言模型微调语料构建
理论部分
微调:使用专业领域的数据对预训练的模型进行训练,让模型对专业的事情处理的也很好。
大模型的结构分类:
《Attentition is all you need》2017年发布
Transformer
输入部分
编码器Encoder
解码器Decoder
输出部分
Bert Encoder-Only 只有编码器,没有解码器。2018年10月
GPT Decoder-Only 只有解码器,没有编码器。2018年6月
T5 Encoder-Decoder 既有编码器,又有解码器
操作
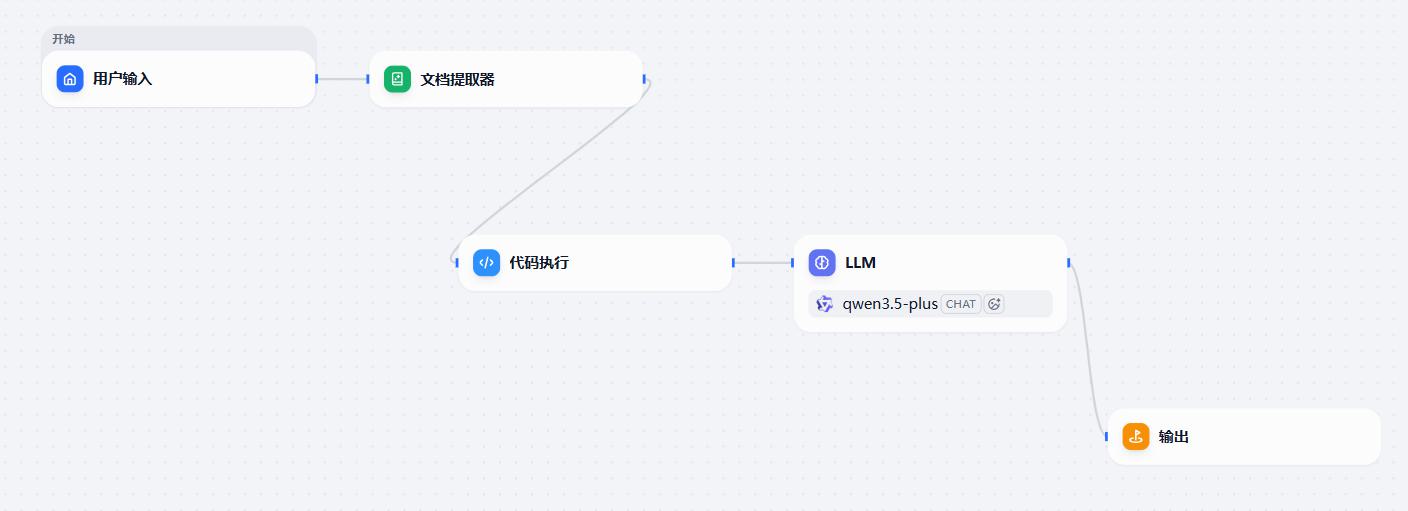
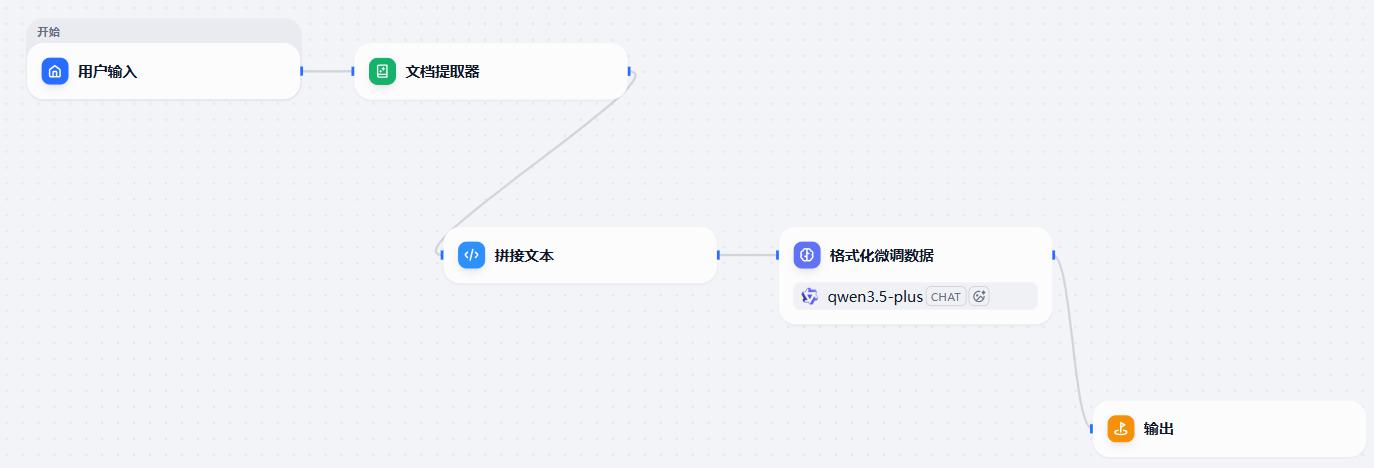
- 添加节点并连线
- 改名字
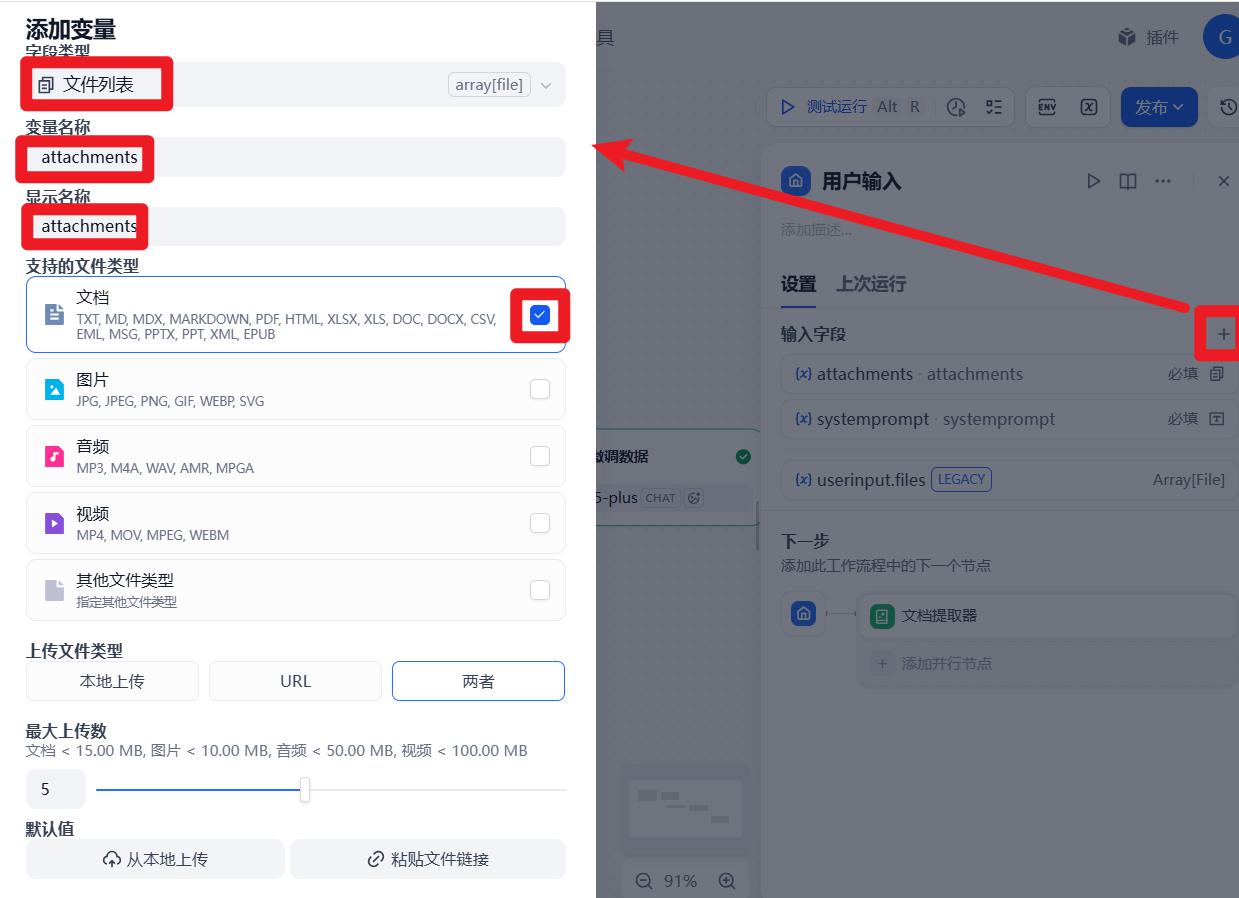
- 配置:用户输入
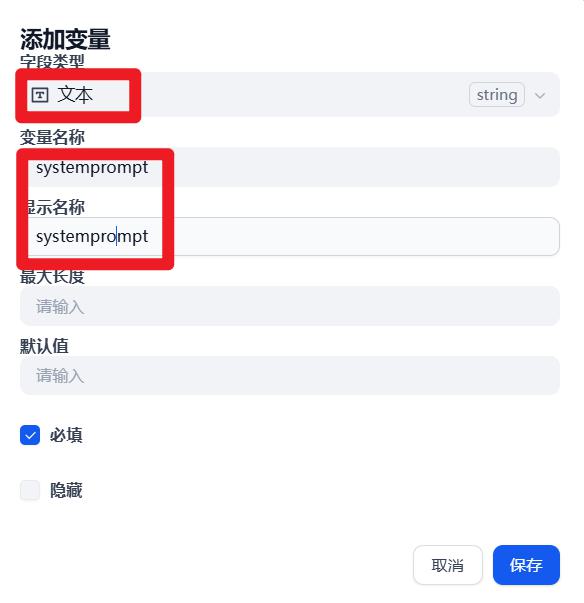
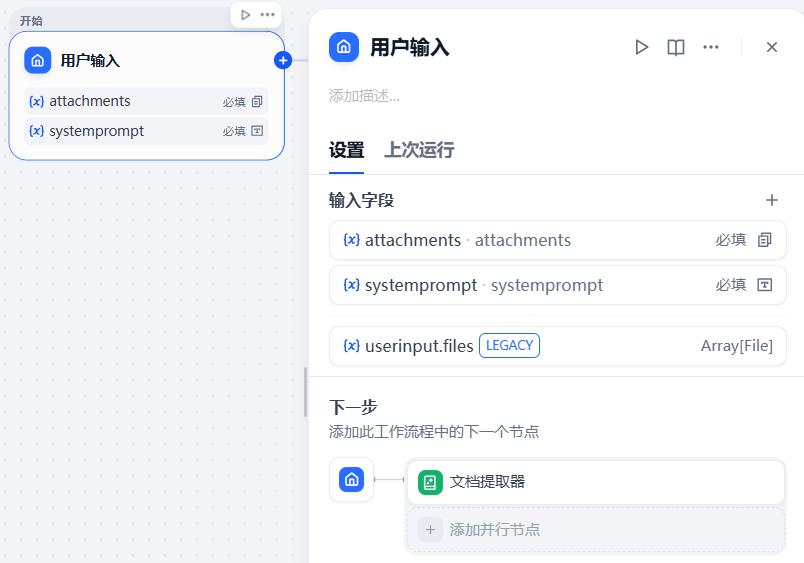
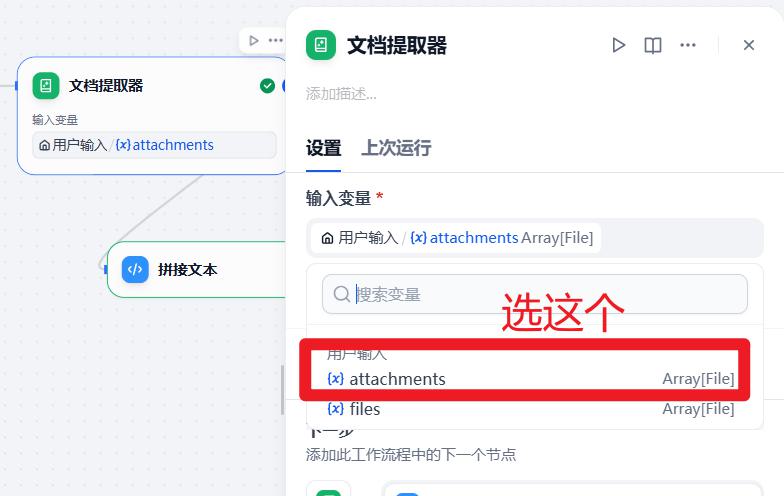
- 配置:文档提取器
- 配置:拼接文本
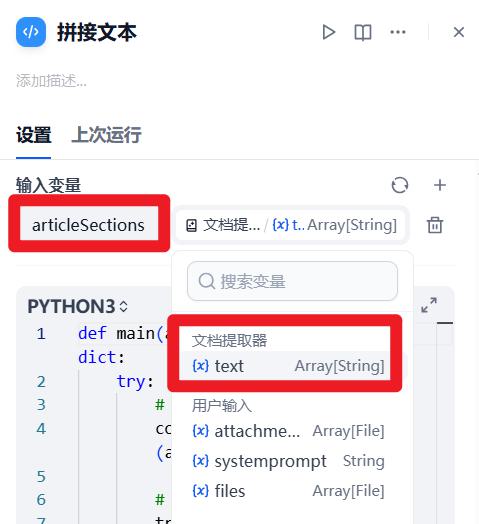
"""
总结:
1- 参数个数、参数名称、参数类型必须与上面【输入变量】完全一致
2- :list是在限定输入参数的类型;->dict是在告诉Dify,代码执行完以后返回的数据类型
"""
def main(articleSections:list)->dict:
try:
# 1- 拼接
combine_text = "\n".join(articleSections)
# 2- 截取前800个字符
result = combine_text[:800]
return {"result": result}
except Exception as e:
return {"result": ""}
- 配置:格式化微调数据
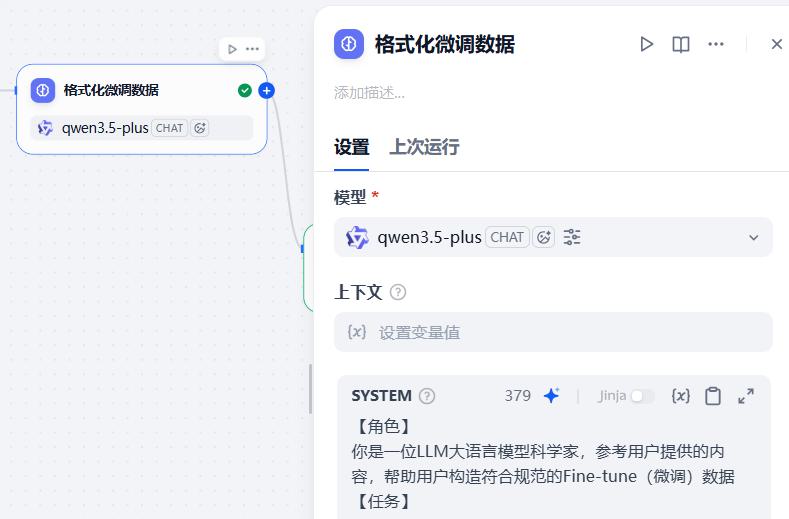
系统提示词:
【角色】
你是一位LLM大语言模型科学家,参考用户提供的内容,帮助用户构造符合规范的Fine-tune(微调)数据
【任务】
对于给定的「内容」,你每次回列出10个通俗「问题」;
针对每个「问题」,引用「内容」原文及对内容的合理解释和演绎,做出「解答」;
并将「问题」「解答」整理为规范的JSONL格式
【要求】
问题不要直接引用「内容」,应该贴近当代现实生活;
问题应该是通俗白话,避免"假、大、空";
答案应忠于原文,对于原文的解释不能脱离原文的主旨、思想;
【输出规范】
输出规范的JSONL,每行一条数据
每条数据应包含一个message数组,每个数组都应该包含role分别为system、user和assistant的三条记录
其中role为system的数据,作为训练中的systemprompt格外重要,其content使用用户指定的「触发词」
用户提示词:
- 配置:输出
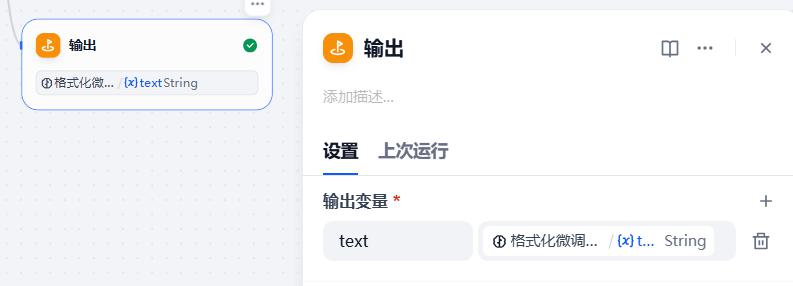
- 试运行
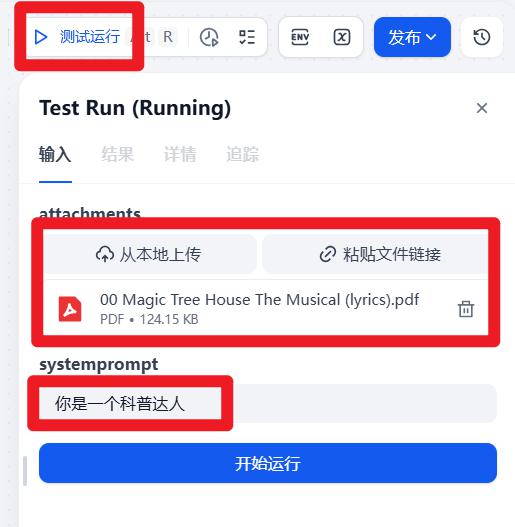
- 运行结果

RAG和知识库
知识库检索技术
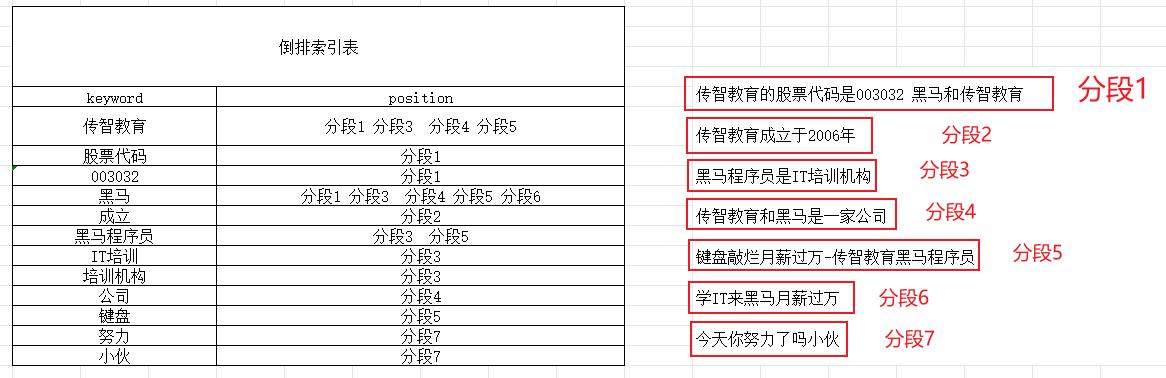
知识库检索有全文检索、语义检索、混合检索三种方式:
- 全文检索:基于关键词+倒排索引技术。
- 语义检索:基于向量+相似度计算。
- 混合检索:将全文检索和语义检索的结果进行汇总,再次排序,得到最终检索结果。
全文检索
全文检索:
- 全文检索:通过关键字在文档中搜索
- 加速技术:倒排索引
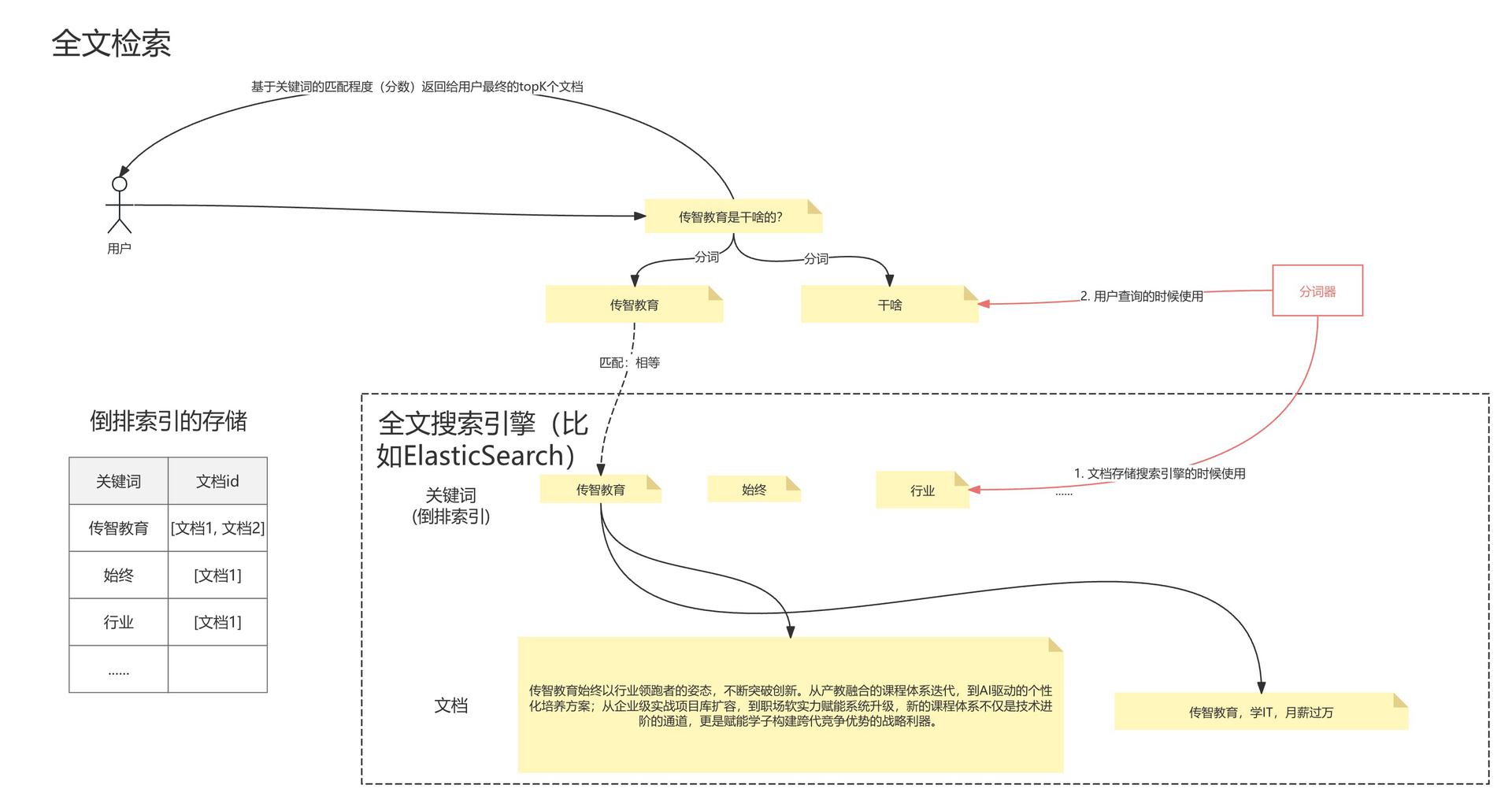
主体流程:
- 将要存入的知识文档内容,做关键词抽取
- 将关键词记录为倒排索引,即记录每个关键词出现的位置(如上图左侧倒排索引的存储示例图)
- 当需要搜索某个关键词的时候,就可以从倒排索引中快速定位某个词所在的位置
语义检索
靠语义寻找相似的文字片段。
比如知识库记录了:
- 好吃的有火锅、牛肉、烧烤
假设用户搜索:
- 饿啊,怎么解决
如果用全文检索,则无法命中。
但是在语义上,应该返回知识库的这个记录。
语义检索是知识库检索的另一种常用手段。
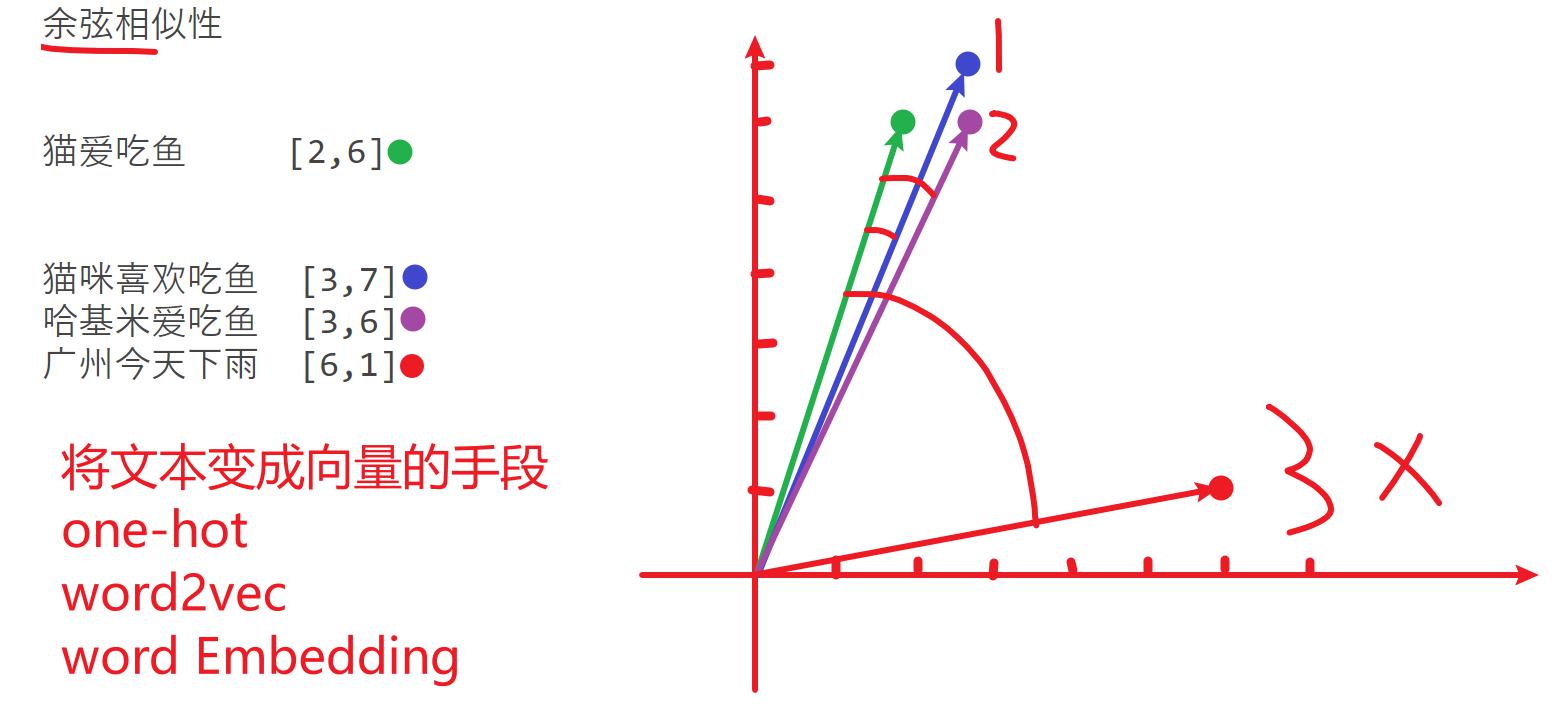
向量和相似度匹配
向量是一组数字,表示的是一段文本表达的含义,在各个维度上的长度。
向量是指数据再维度方向上的长度(再每个维度的得分)
向量的生成
需要借助模型(文本嵌入模型),比如阿里云百炼的text-embedding-v4模型
可以在1536个维度上,给一段文本评分。
市面上的嵌入模型很多,有的模型提供736维度,有的提供968维度,有点提供1536维度
这些维度是啥,我们无法控制,概念就是上面提到的1维、2维、3维的推导
相似度匹配
余弦相似度、欧式距离
性能
- 维度越多,越精准
- 查知识库的时候,匹配越精准(因为维度多)
- 维度越多,反应越慢
- 存知识库的时候,计算向量慢(因为维度多)
混合检索
数据的每一个分段在存入的时候:
- 即生成倒排索引(用于全文检索)
- 也生成向量数据(用于语义检索)
数据在查询的时候:
- 即做全文检索
- 也做语义检索
- 混在一起的结果,在做排序(可用排序(Rerank )模型,比如阿里云的
gte-Rerank模型)
RAG
RAG(检索增强生成,Retrieval-Augmented Generation)
RAG有2个工作线:
- 离线流程:将知识存入知识库,生成向量存储
- 在线流程:将用户查询转换为向量,从知识库中检索
通过检索知识库得到参考资料,用于增强提示词的上下文信息,最终生成合适的回答
RAG:外挂知识库、外挂数据
Dify创建知识库
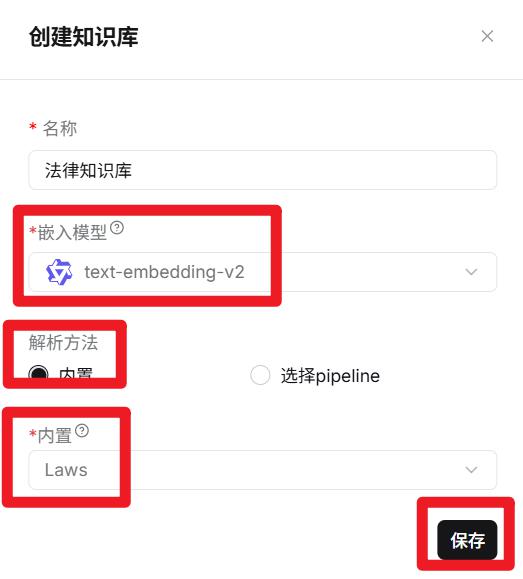
创建步骤
- 选择知识库
- 分块设置:父子分块,参数保持默认
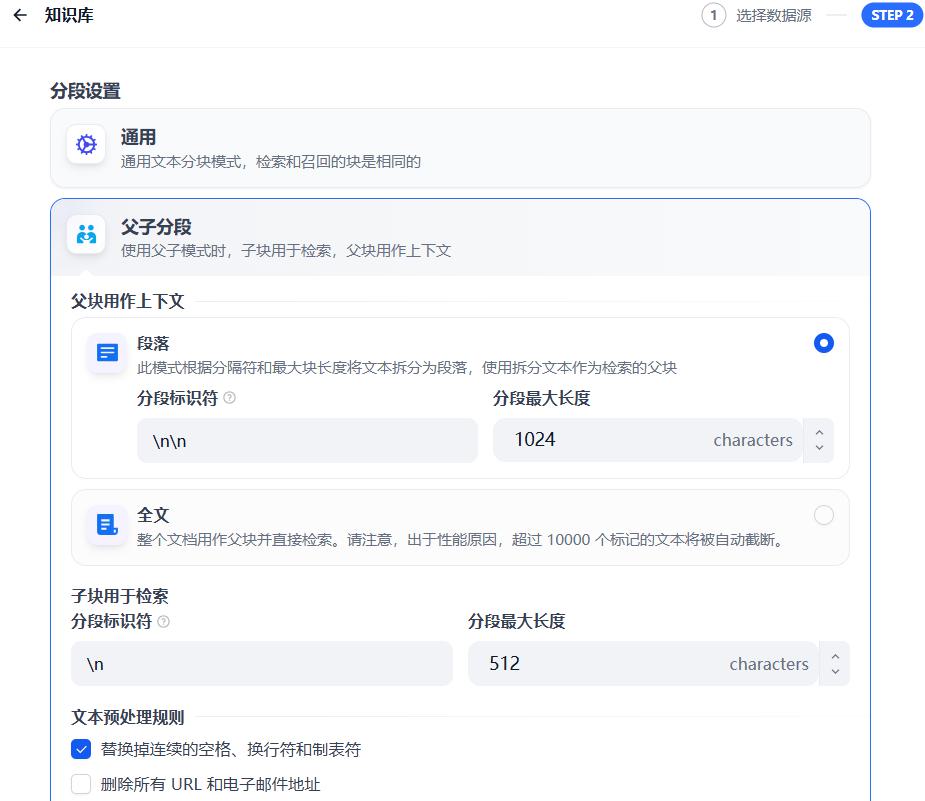
- 索引方式:高质量

- 嵌入模型:选择text-embedding-v1

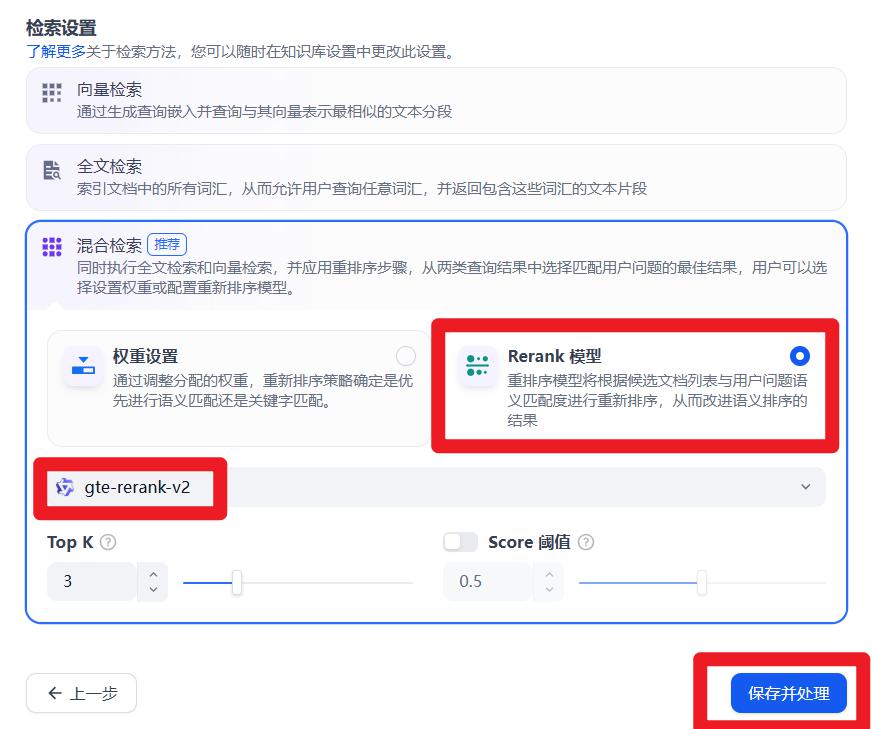
- 检索设置:Rerank模型。选择gte-rerank-v2
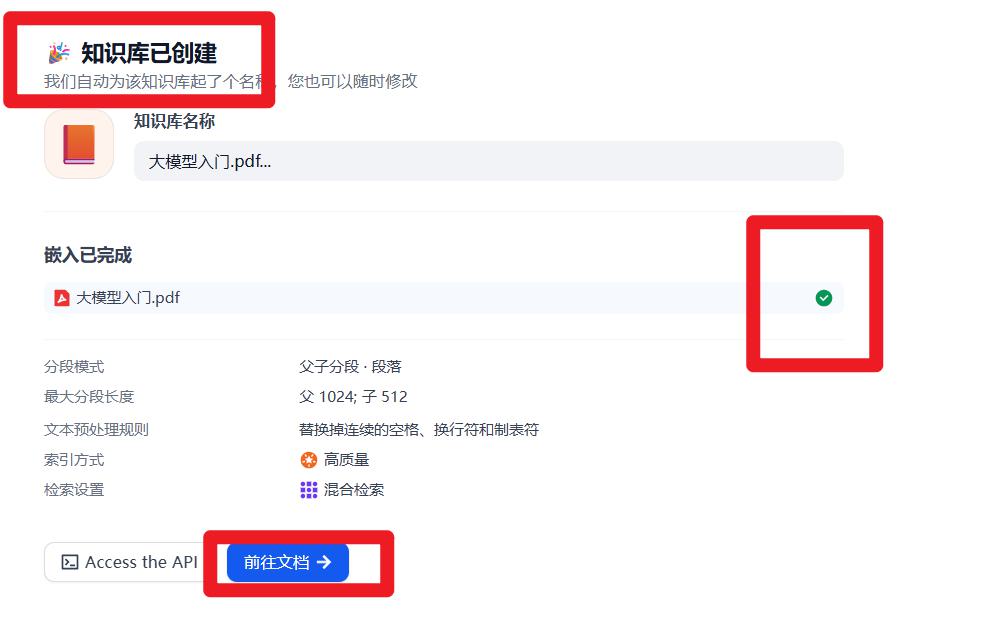
- 创建成功
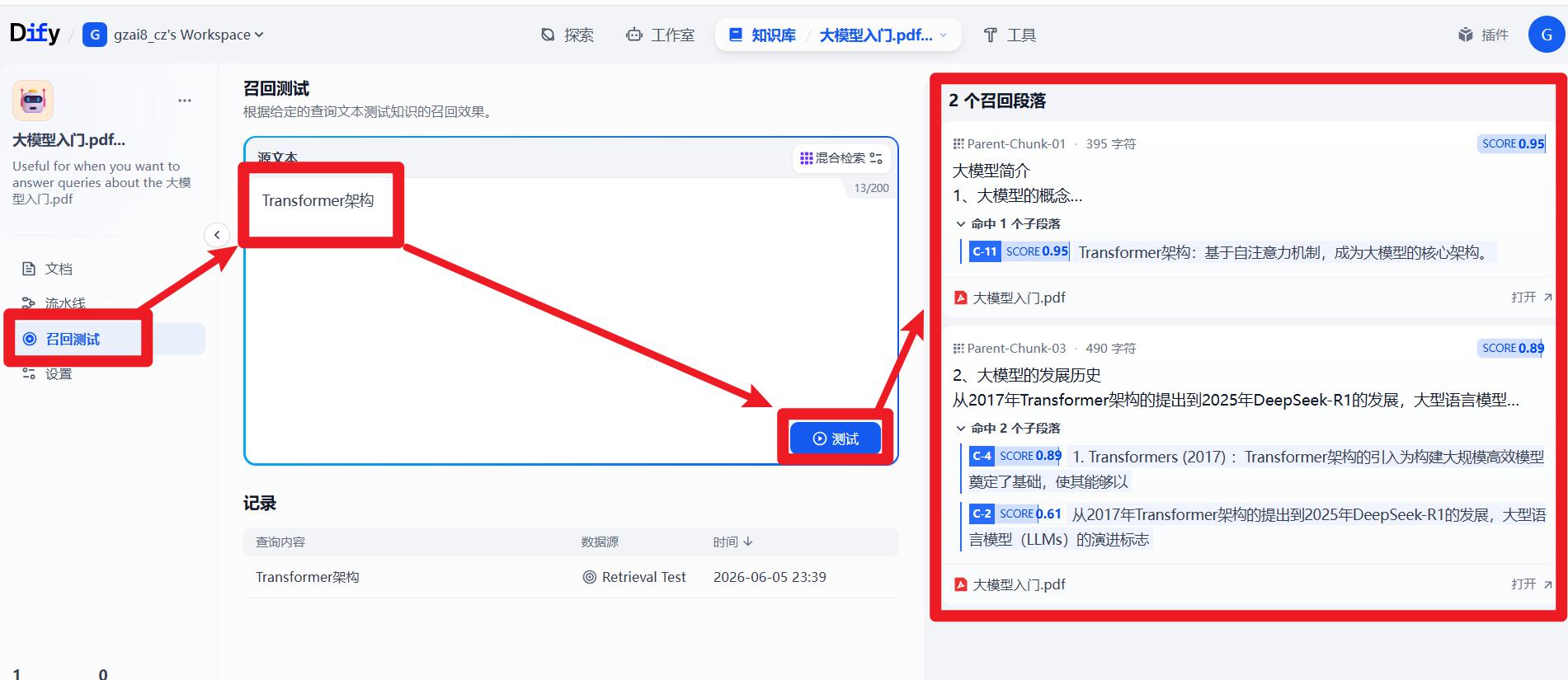
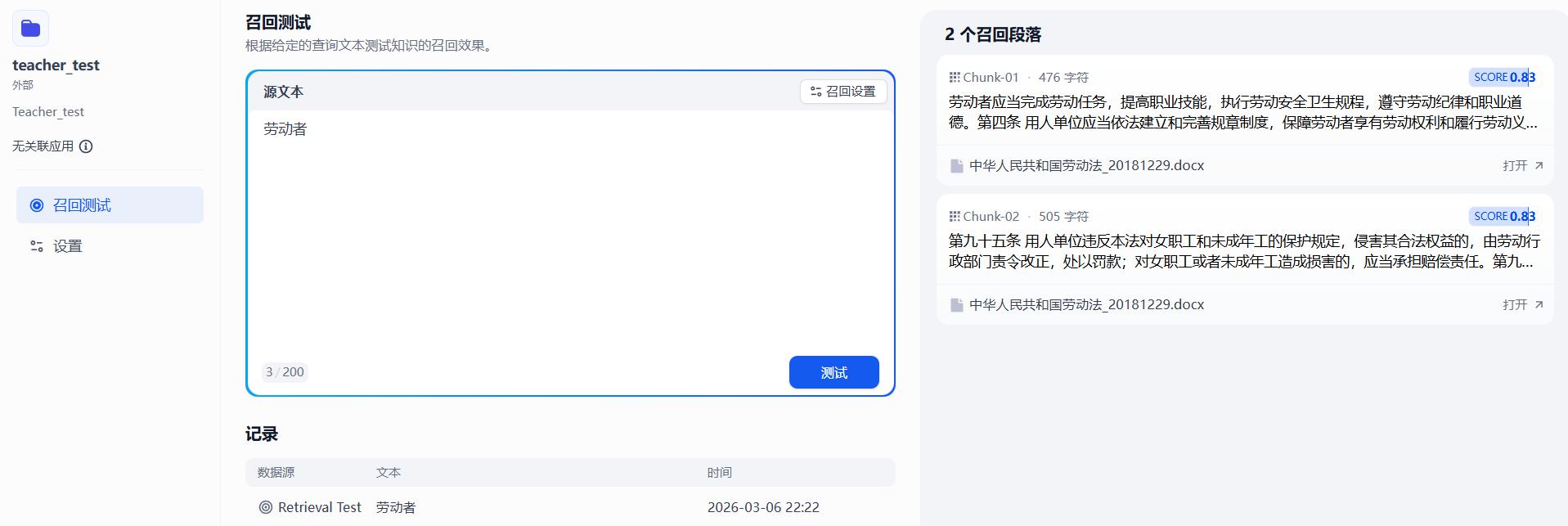
- 召回测试:确保知识库可用
父子分段
Dify对比Coze特有的知识库存储结构,将文档划分为:
- 父段:提供完整的上下文信息
- 子段:加快对知识库中内容的检索速度
在检索的时候,会基于子段去匹配,如果匹配到子段,再将父段(作为上下文)提供。
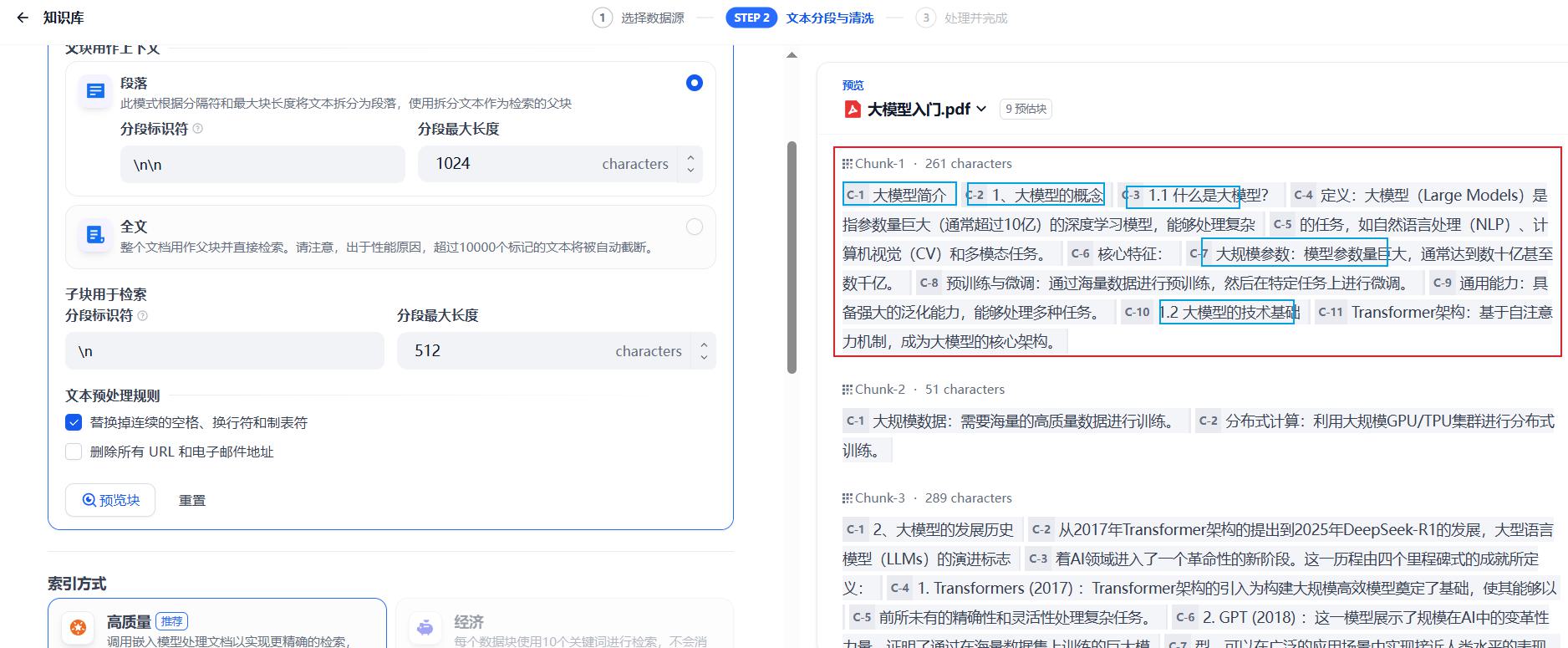
如图,红色框是父段,蓝色框是子段
索引方式
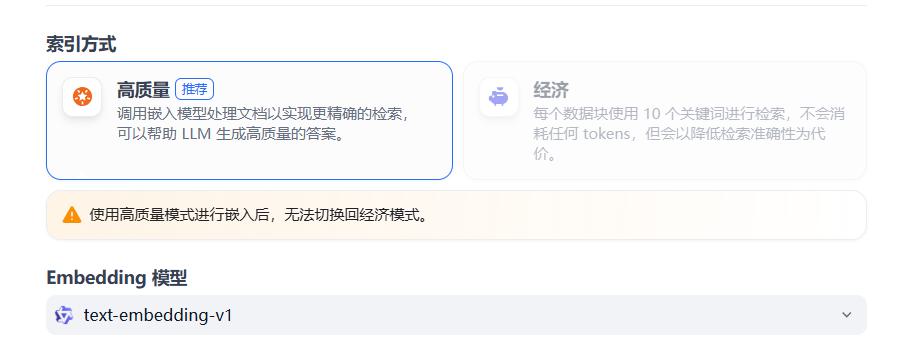
Dify提供:
- 经济模式:纯全文检索(还是低配,仅限10个关键字),好处超级快,不额外花钱,坏处,不准
- 高质量模式(推荐):全文、语义、混合都可以自选
- 好处:准
- 坏处:额外消耗嵌入模型和重排模型的Token(钱),慢一些
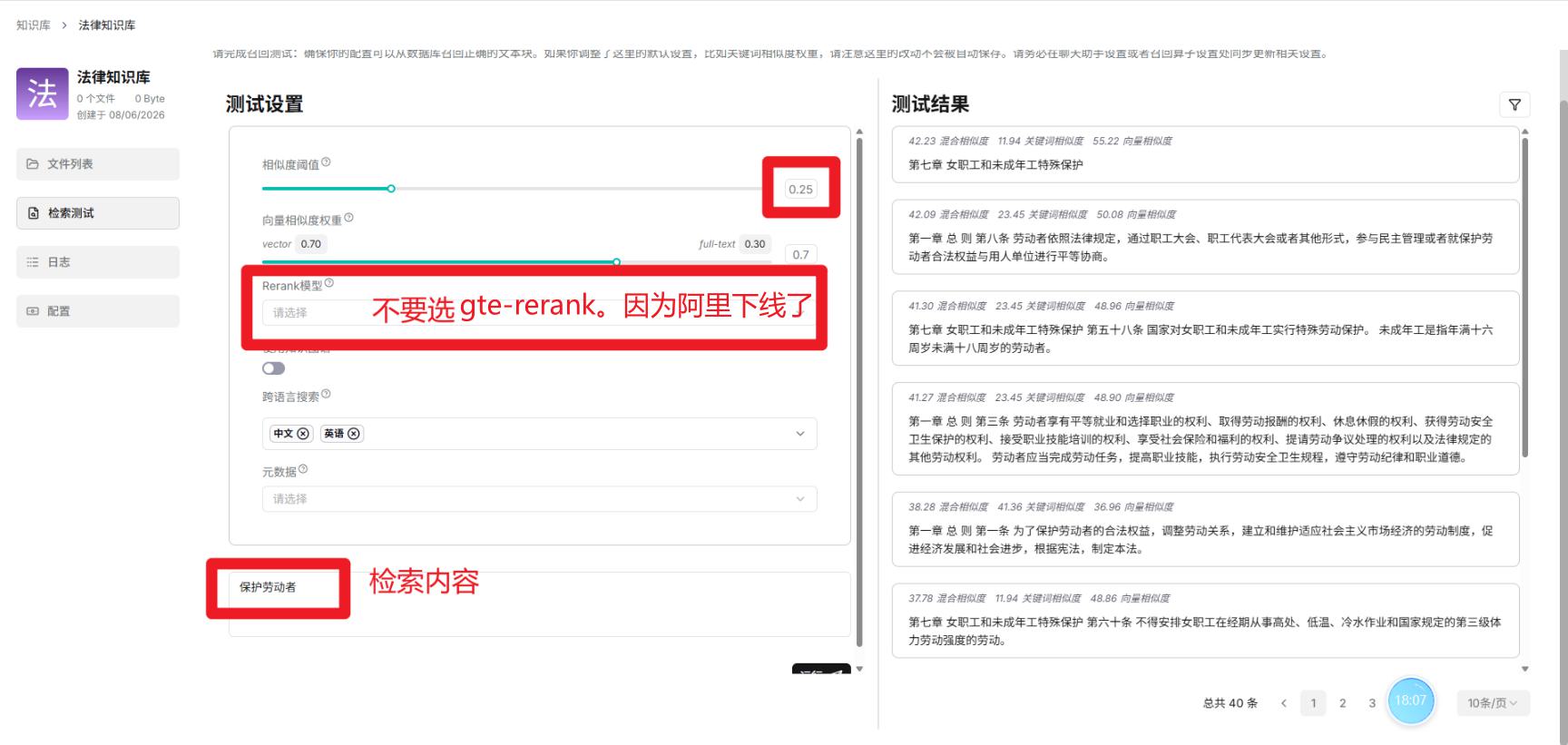
检索方式
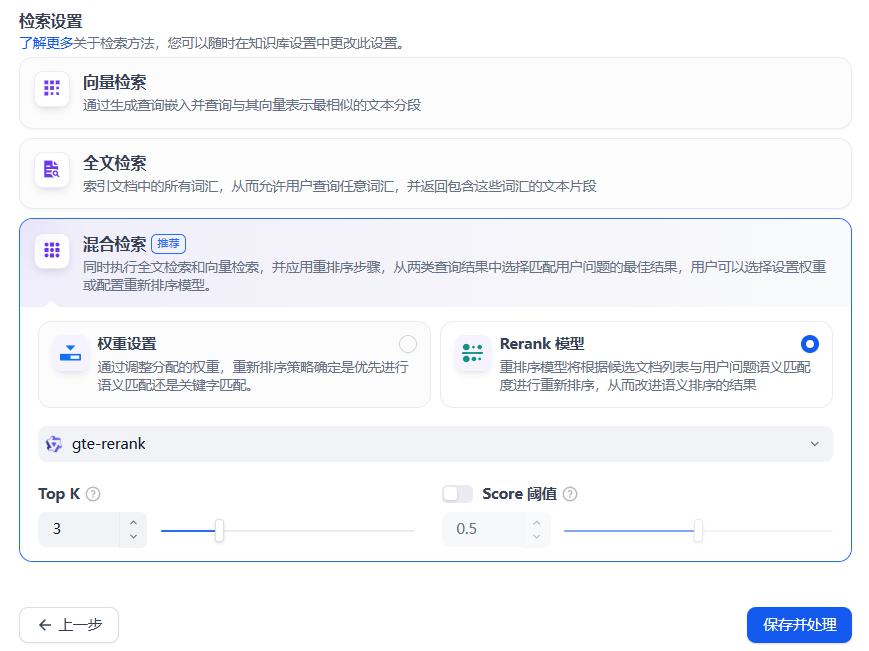
混合检索中的:
权重设置:自己决定全文和语义的占比
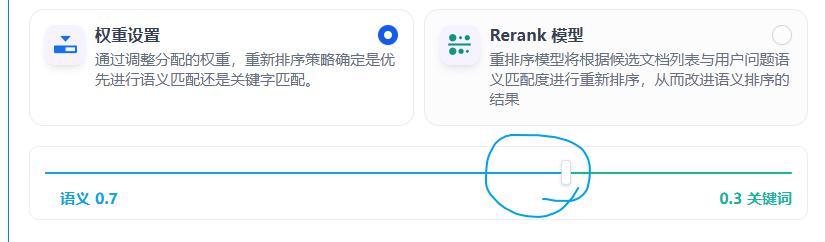
Rerank模型,用模型决定语义和全文的排序

TopK:召回数量阈值
Score:向量匹配相似度阈值
Agent使用知识库
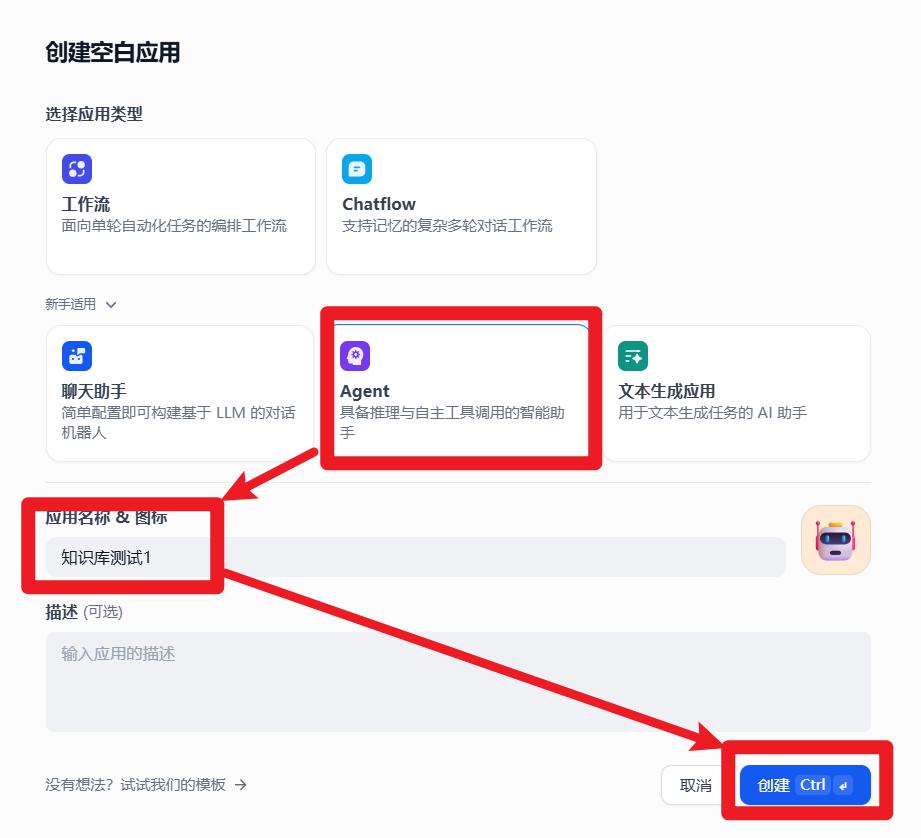
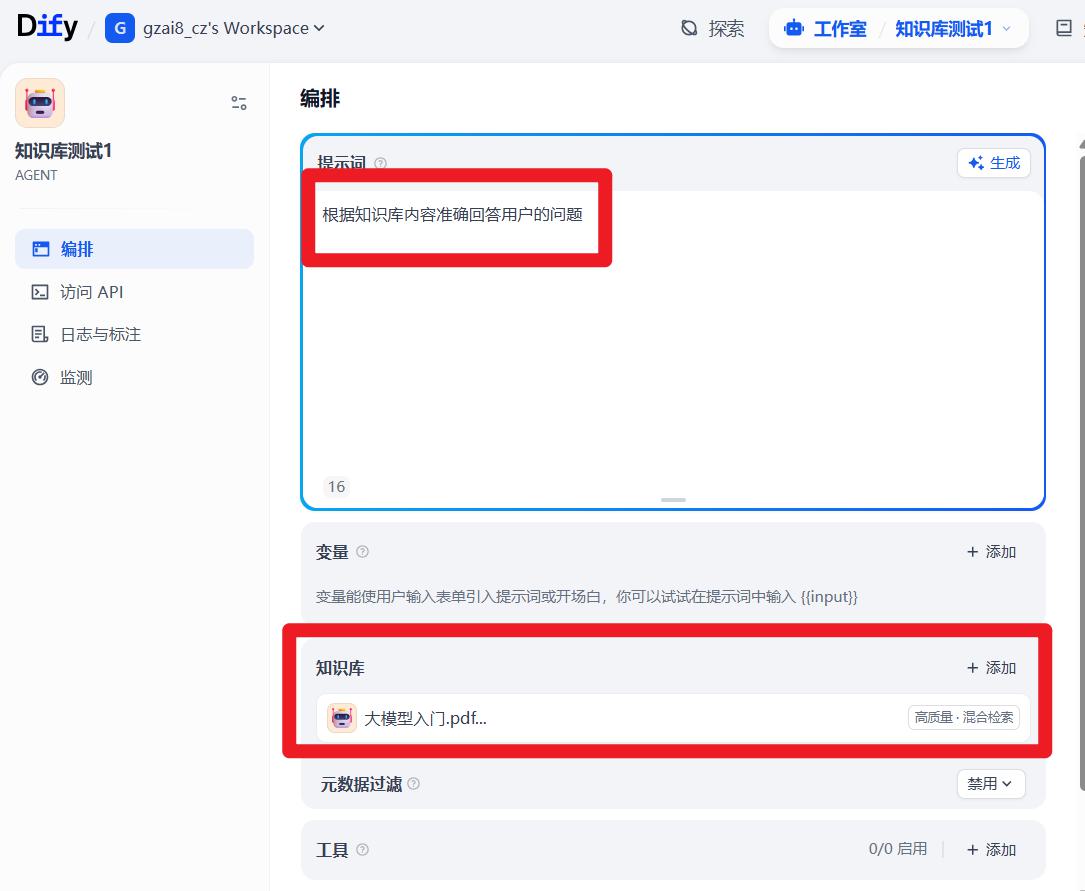
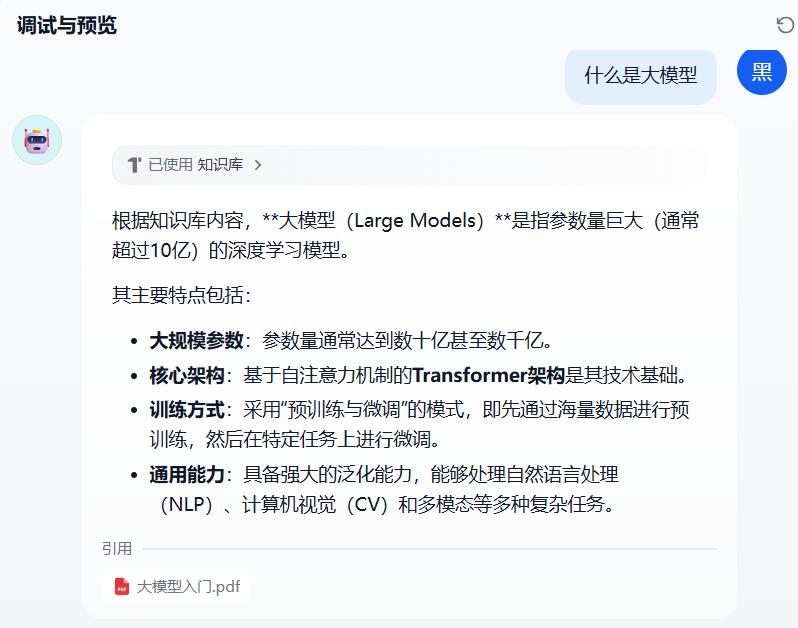
运行效果:
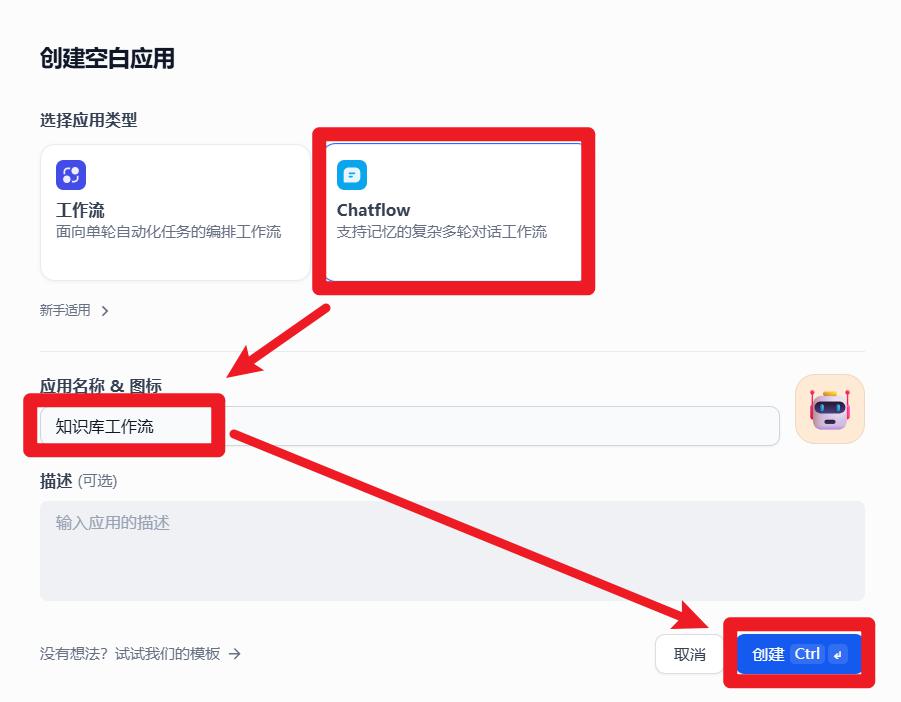
对话流使用知识库
- 整体结构

- 创建
- 设置:用户输入
啥都不用设置
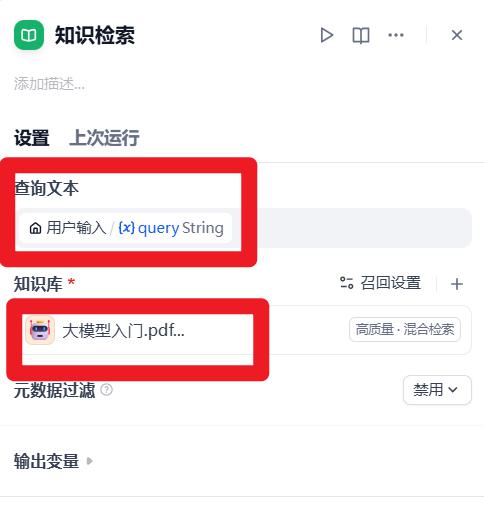
- 设置:知识检索
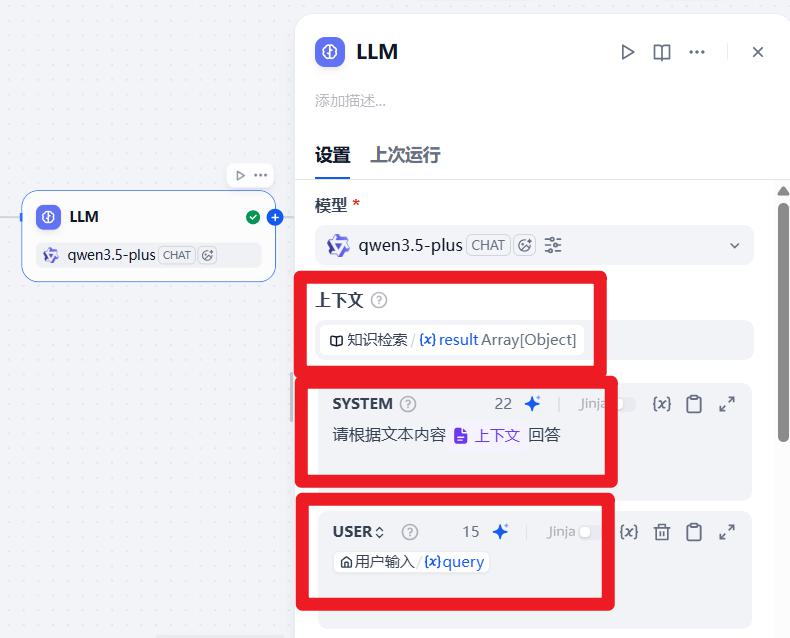
- 设置:大模型
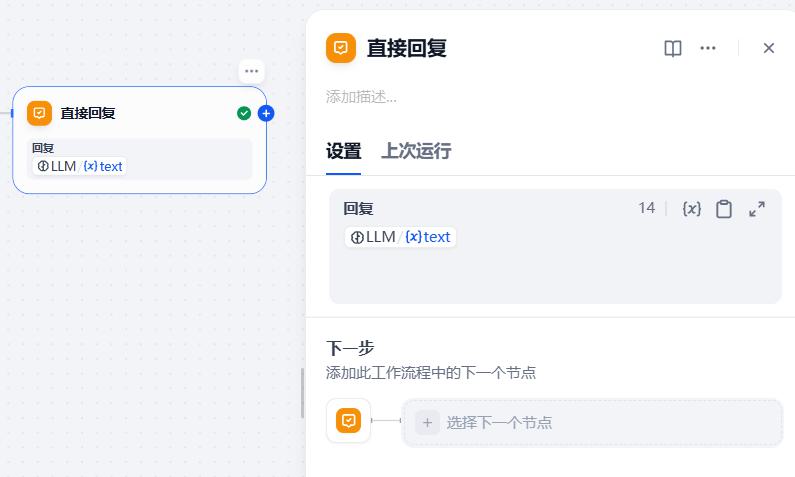
- 设置:直接回复
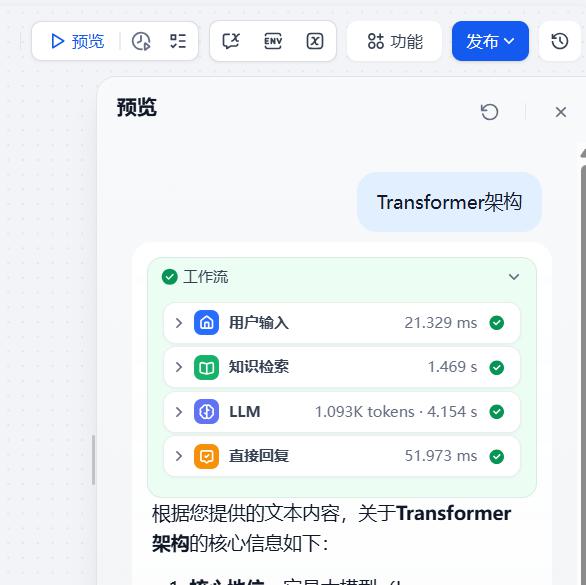
- 预览
RAGFLOW
为什么要使用RAGFLOW
原因:相对来说Dify的知识库对文档的处理能力一般,对于PDF扫描件(文字不清晰、有图片、有复杂表格)文字提取效果一般
文档处理能力排名(由强到弱):RAGFLOW > Dify > Coze
介绍:RAGFLOW专门用来搭建文档向量知识库
概念
SPO三元组
SPO三元组:实体 -> 关系 -> 实体
知识图谱
知识图谱的构建就是将上传的文档(知识库)构建为SPO,即实体之间的关系。
未构建知识图谱的原始文档:
本社区本月共开展民生活动 12 场,服务居民约 1800 人次。重点解决供暖问题 35 起,协助老年群体体检预约 62 人。宣传反诈讲座共 3 场,覆盖居民 500 余人次。社区内未发生重大安全事故。
实体抽取
社区、居民、老人、反诈讲座、安全事故、民生活动
关系(边)
社区 -> 开展 -> 民生活动(12)
民生活动 -> 包含 -> 供暖服务
民生活动 -> 包含 -> 反诈讲座3
民生活动 -> 包含 -> 老年服务
社区 -> 服务 -> 居民(1800)
社区 -> 服务 -> 老人
居民 -> 包含 -> 老人
居民 -> 参加 -> 供暖服务
居民 -> 参加 -> 反诈讲座3
居民 -> 参加 -> 老年服务
老人 -> 参加 -> 群体体检(62)
供暖服务 -> 解决 -> 供暖问题(35)
社区 -> 管理 -> 安全事故(0)
问题:老年人参与了哪些服务
居民 -> 包含 -> 老人 | 社区 -> 服务 -> 居民(1800)| 老人 -> 参加 -> 群体体检(62)| 居民 -> 参加 -> 反诈讲座3
总结:老年人参与了群体体检62次,参与了反诈讲座3次
对比传统全文检索和语义检索的区别
- 全文、语义:找信息(关键字或含义)
- 知识图谱:找关系(实体间的)
优缺点
- 优点:查找更精准,特别适合带有明确关系要求的查询,如上面老年人参与了什么服务
- 缺点:烧钱、费时
安装RAGFLOW
WSL+Docker版
- 前置条件:先启动
docker-desktop软件 - 找到课程资料中的
ragflow-main.zip解压到别的地方。注意:里面还有个ragflow的文件夹 - 进入
ragflow文件夹内的docker文件夹 - 再空白地方按住
shift+鼠标右键,点击弹出的PowerShell中打开 - 执行命令:docker compose up -d
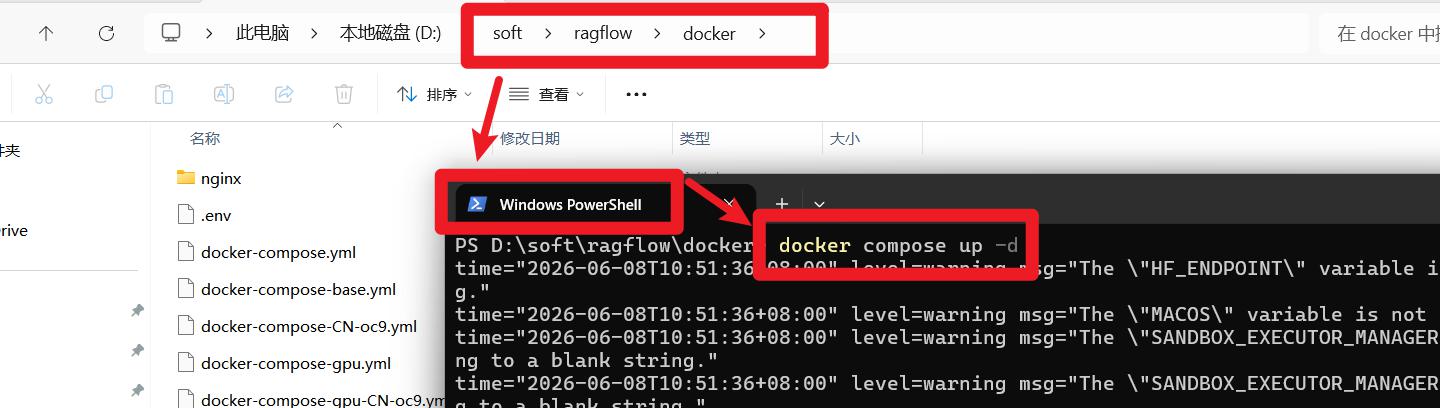
- 启动后,打开192.168.111.97:8880即可看到ragflow的页面,然后自己注册账户即可。
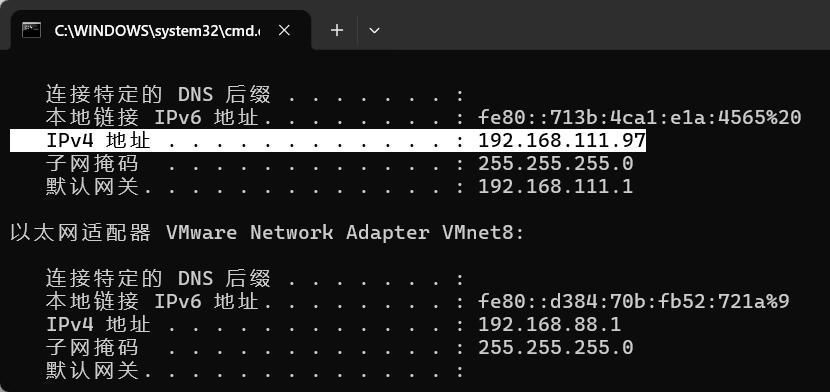
注意:ip地址需要改成你自己的地址。
windows操作系统看ip地址的命令
ipconfig
mac操作系统查看ip地址的命令
ifconfig
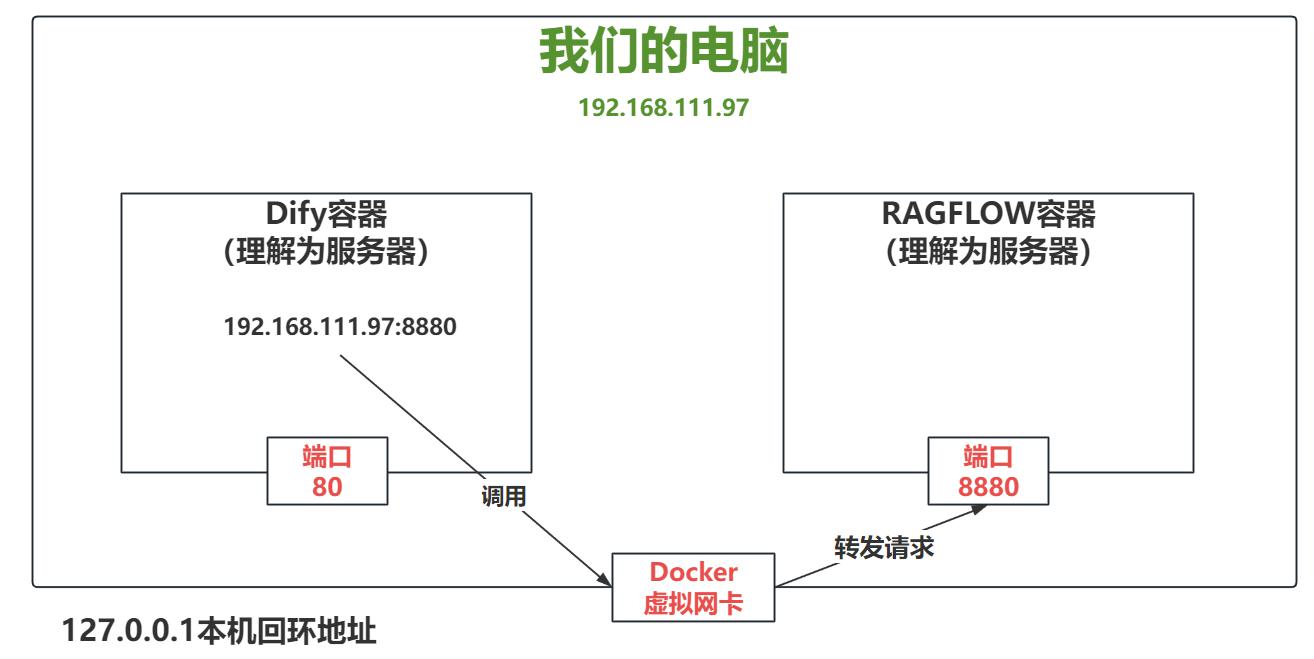
为什么不能写127.0.0.1的IP地址?
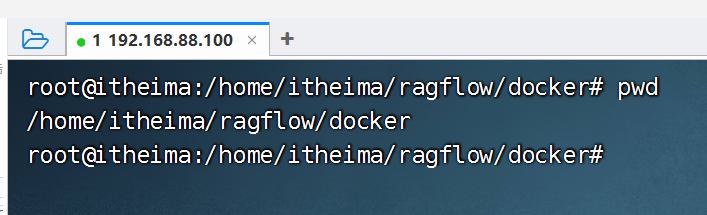
虚拟机版启动RAGFLOW
- 进入到ragflow的docker路径下
cd /home/itheima/ragflow/docker
- 执行启动Docker的命令
docker compose up -d
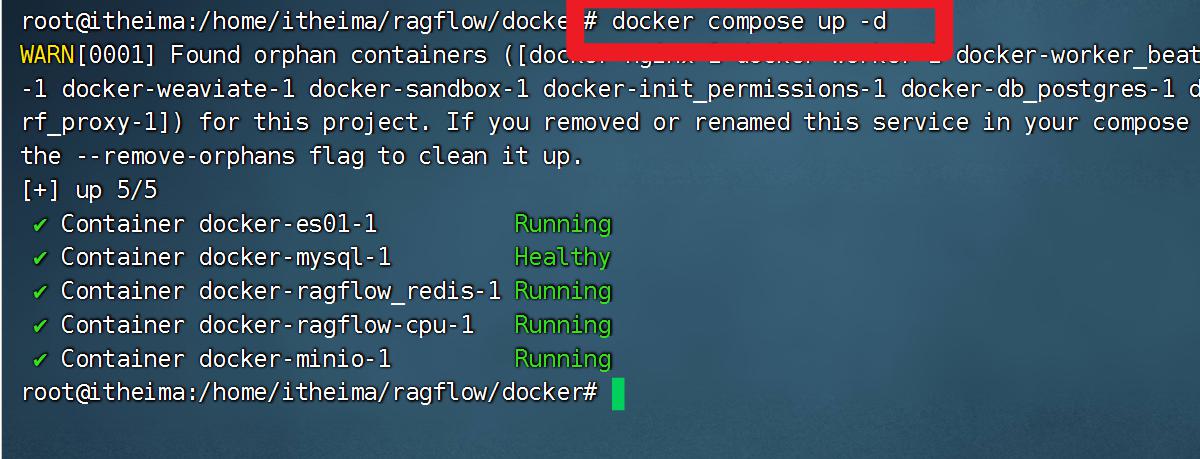
- 使用浏览器访问如下地址。需要多刷新几次
http://192.168.88.100:8880/login
【了解】虚拟机安装低版本RAGFLOW
- 虚拟机安装ssh软件
sudo apt-get install openssh-server
- 修改配置文件
vi /etc/ssh/sshd_config
找到 PermitRootLogin 这一项,将其修改为 PermitRootLogin yes
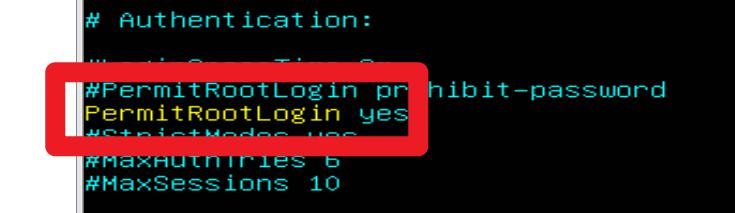
- 保存退出后,重启 SSH 服务使配置生效
systemctl restart sshd

- 使用Finalshell连接虚拟机
- 上传解压缩的文件
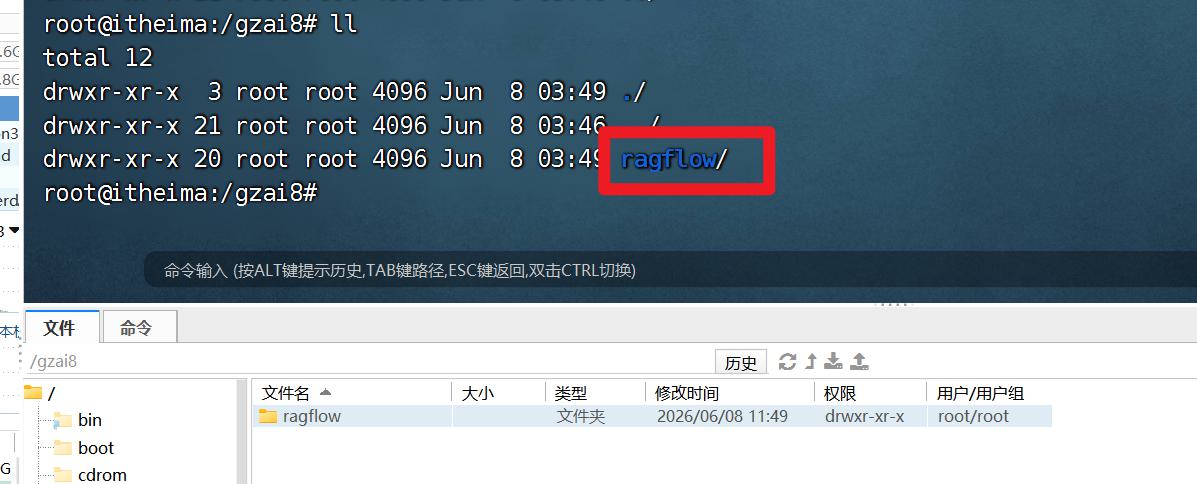
创建存储的文件夹
mkdir /gzai8
解压本地压缩包
上传解压以后的文件夹到gzai8目录下
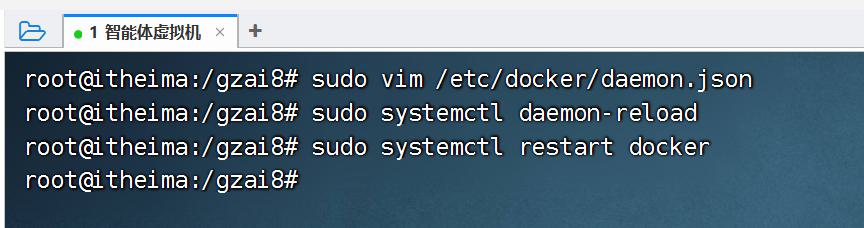
- 配置Docker镜像下载地址
sudo vim /etc/docker/daemon.json
添加如下内容
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://mirror.baidubce.com",
"https://dockerproxy.com"
]
}
:wq保存退出即可
- 重启Docker服务
sudo systemctl daemon-reload
sudo systemctl restart docker
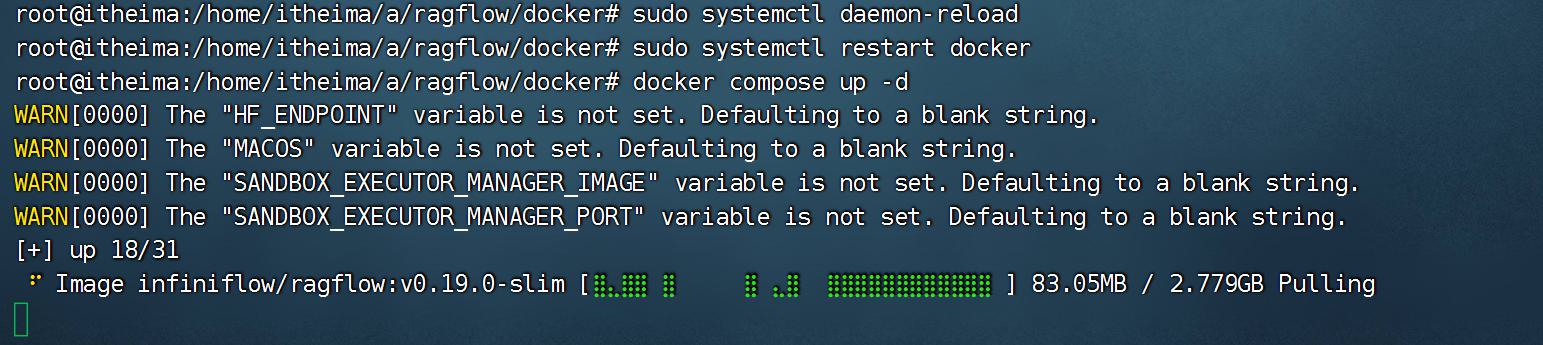
- 修改权限
chmod -R 777 /gzai8
- 启动RAGFLOW
注意:要在线下载镜像。2.9GB
docker compose up -d
Dify连接RAGFLOW使用
新版_创建知识库
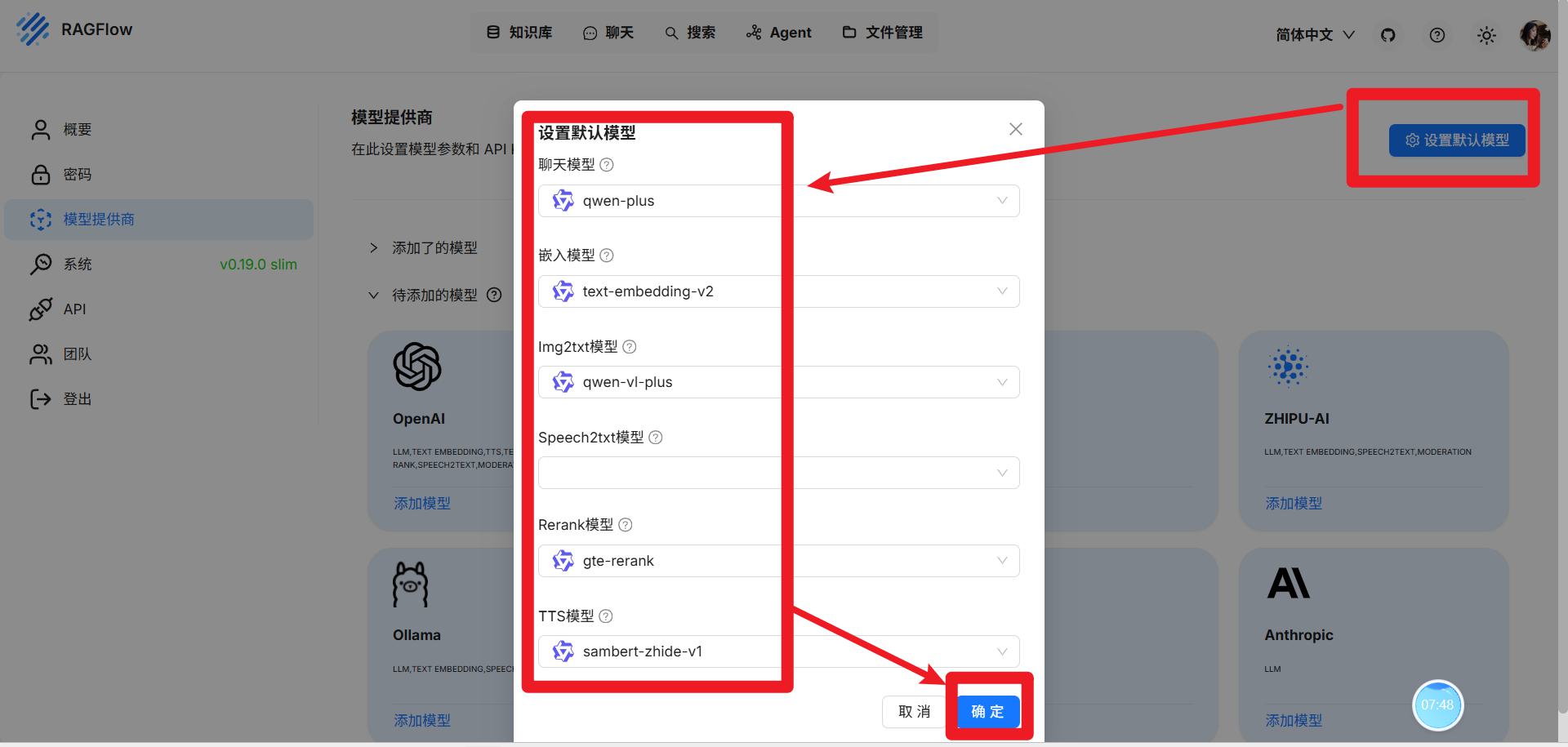
- 配置模型供应商

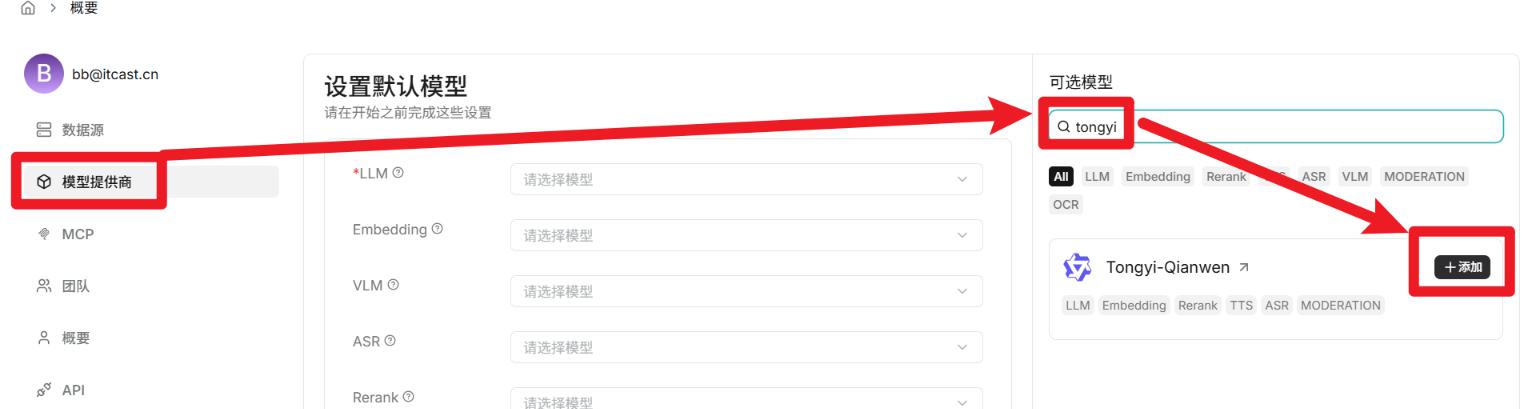
- 配置默认模型
- 创建知识库
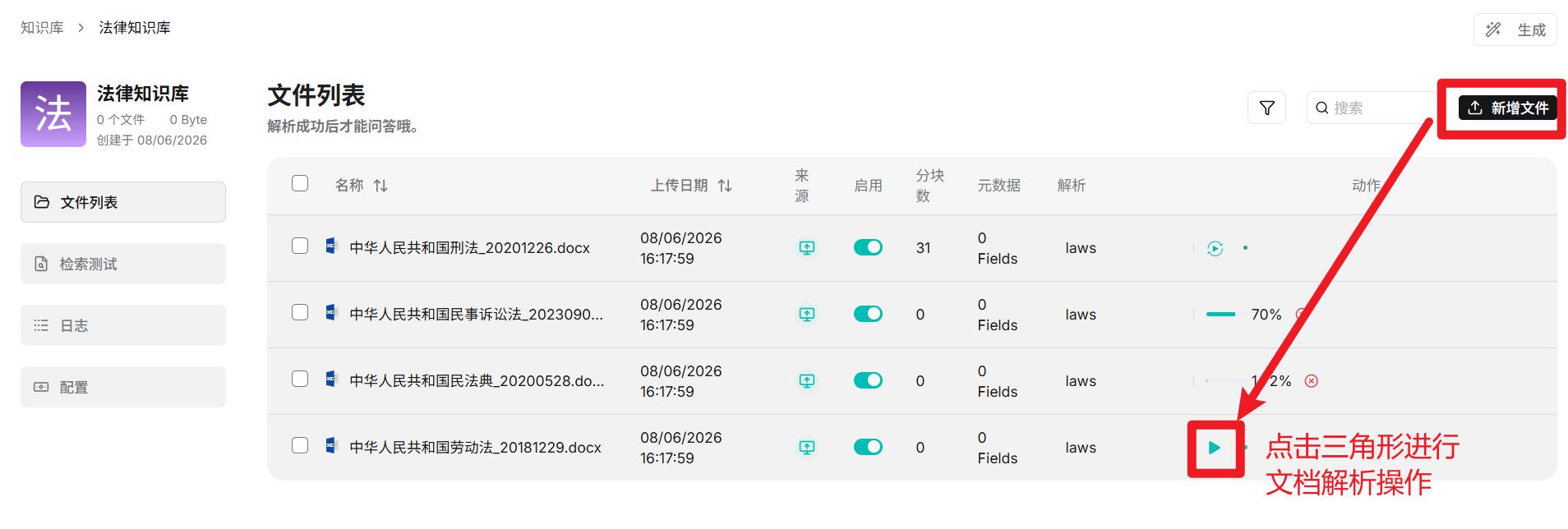
- 召回测试
旧版_基础配置
ragflow操作
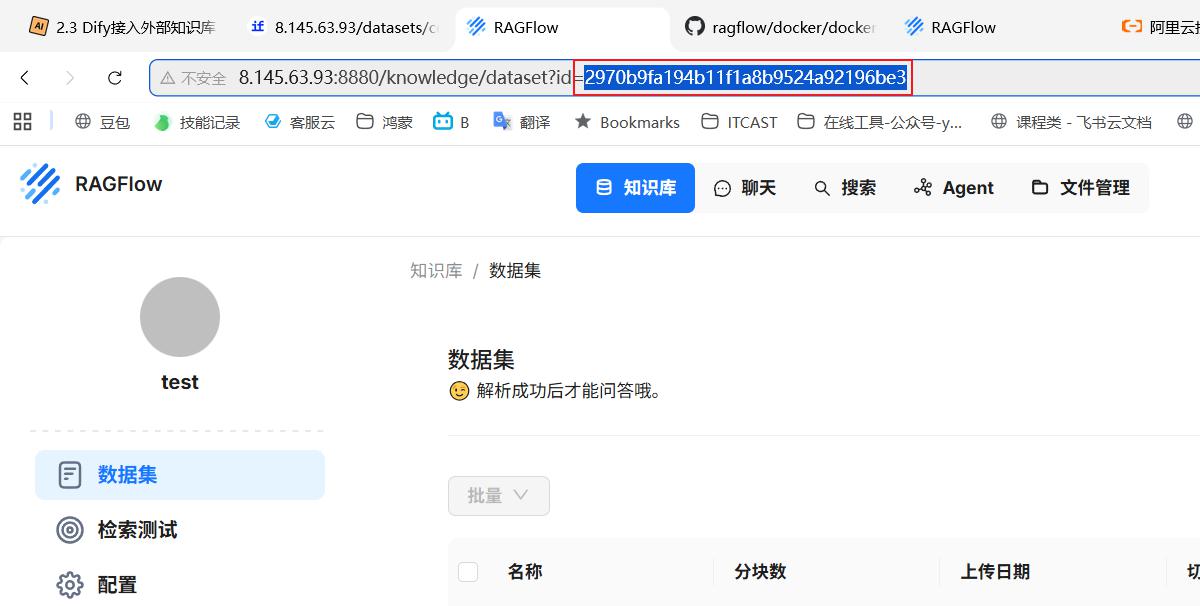
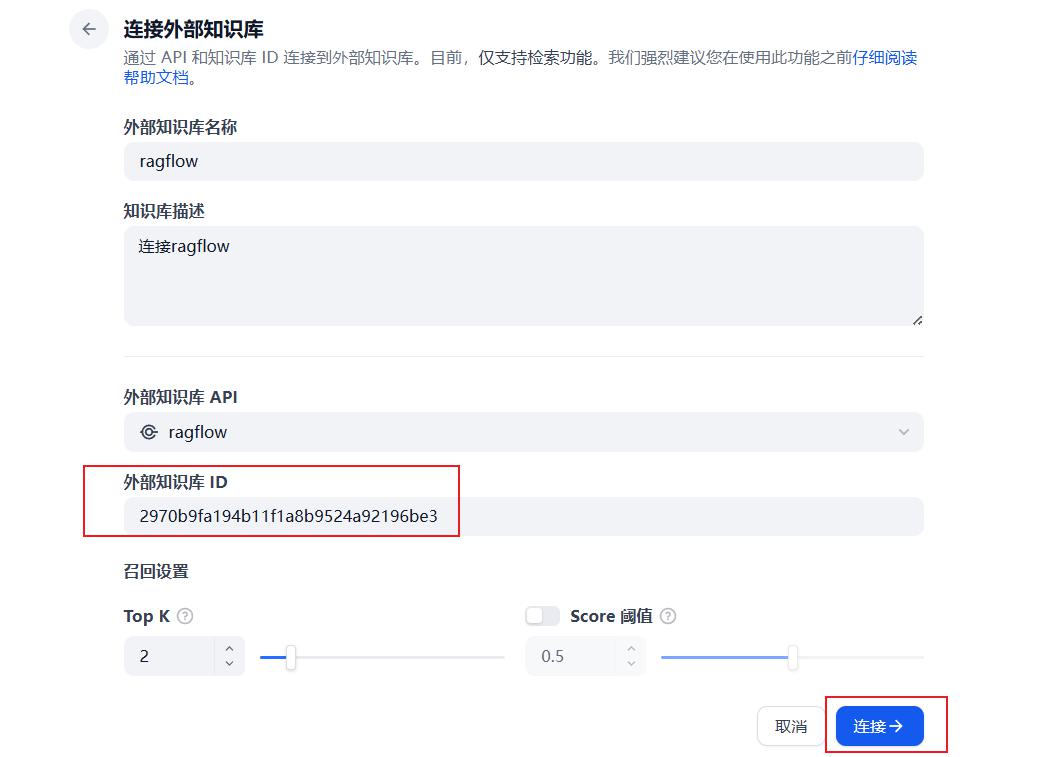
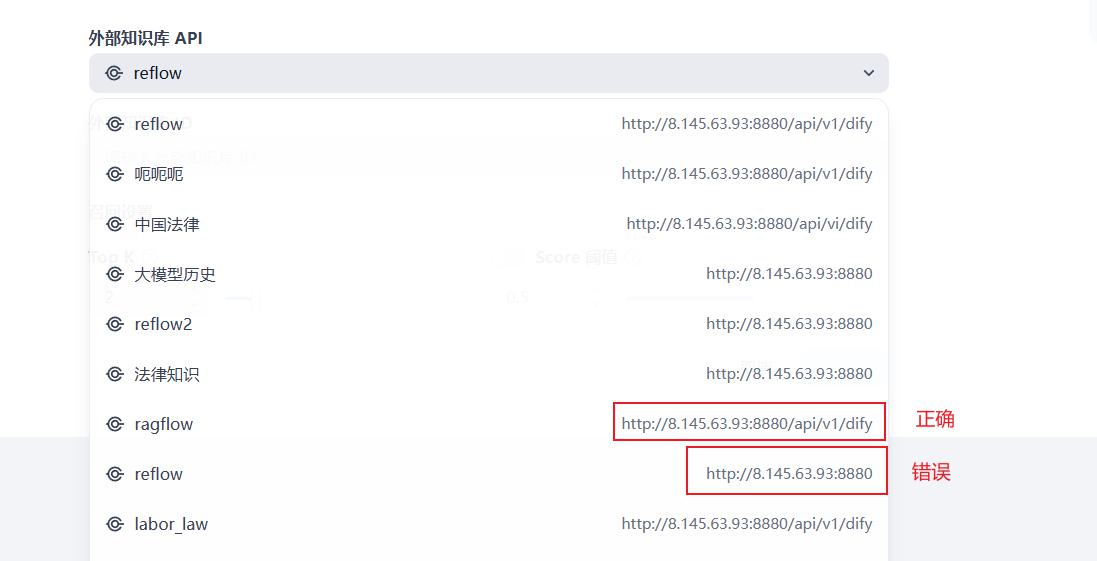
核心点是要复制如下3个信息:
第一个:RAGFLOW的API KEY
第二个:RAGFLOW的网站地址。注意:端口后面需要带上/api/v1/dify
第三个:RAGFLOW知识库的唯一ID
- 在ragflow中
- 创建密钥并复制
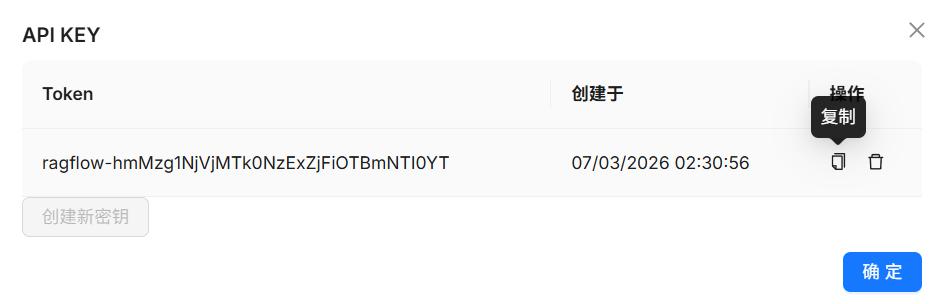
- 复制API服务器地址
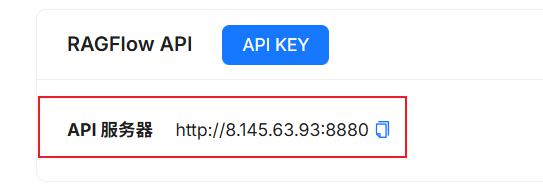
- 找到RAGFLOW的知识库ID,如下图
Dify操作
- 再Dify中点击
- 配置外部知识库API
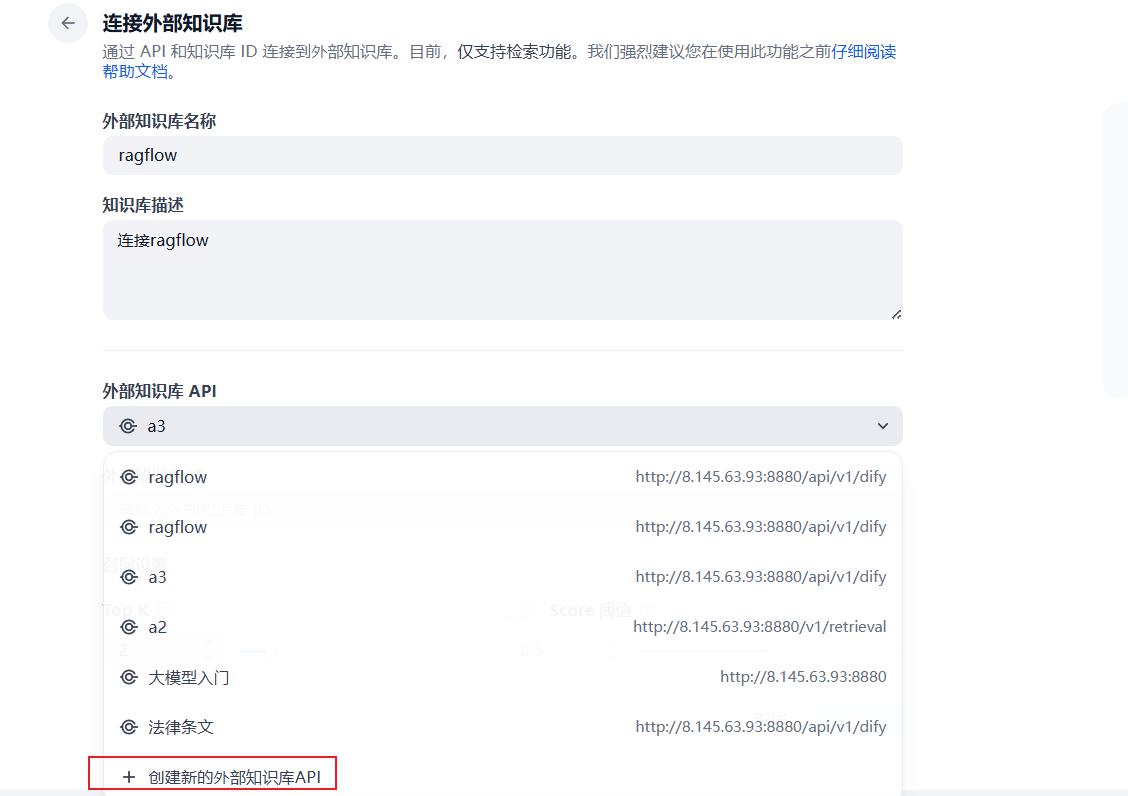
- 添加外部API
注意:端口后面需要带上/api/v1/dify
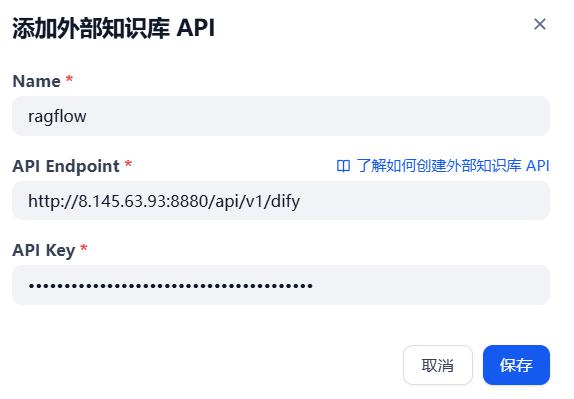
- 配置知识库ID
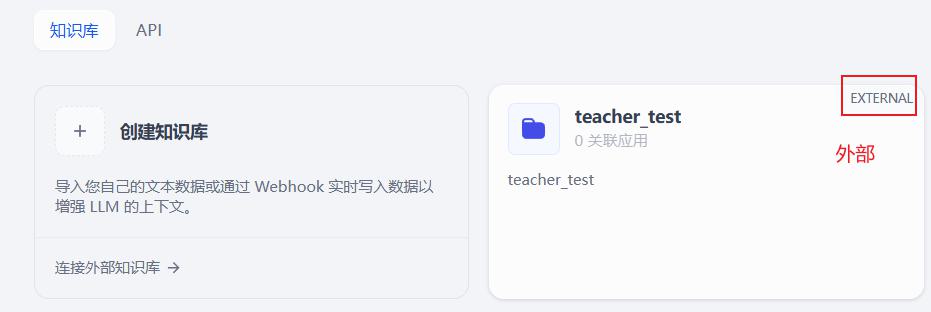
- 创建好如图
- 测试

注意
自己安装部署的ragflow
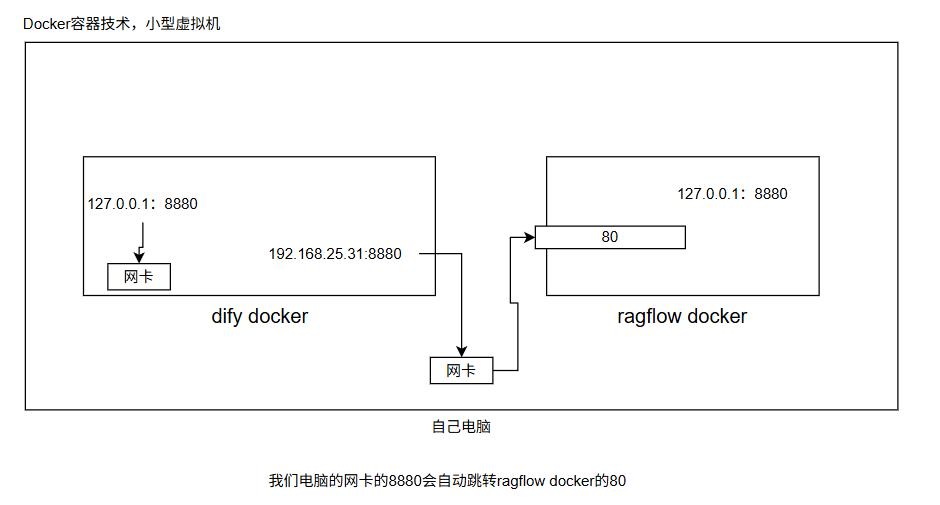
如果Dify和ragflow都是在你自己电脑中部署的。
在连接的时候,知识库API的地址要注意:

这个IP地址:
不能是127.0.0.1应该是你网卡的IP地址,比如:192.168.25.31
原因
BUG解决
[ERROR][Exception]: Exceptions from Trio nursery (20 sub-exceptions) – Account abnormal. Please ensure it’s on good standing to use QWen’s text-embedding-v2
如果遇到这个解析文件的问题,这是因为:ragflow调用阿里云过猛,阿里云拒绝服务。
问题原因引用来源:https://github.com/infiniflow/ragflow/issues/7328
解决:
- 更换嵌入模型的提供商,从阿里换为
智谱
智谱地址:https://open.bigmodel.cn/,注册、实名、创建APIKEY即可

提供APIKEY
配置系统默认模型的嵌入模型:
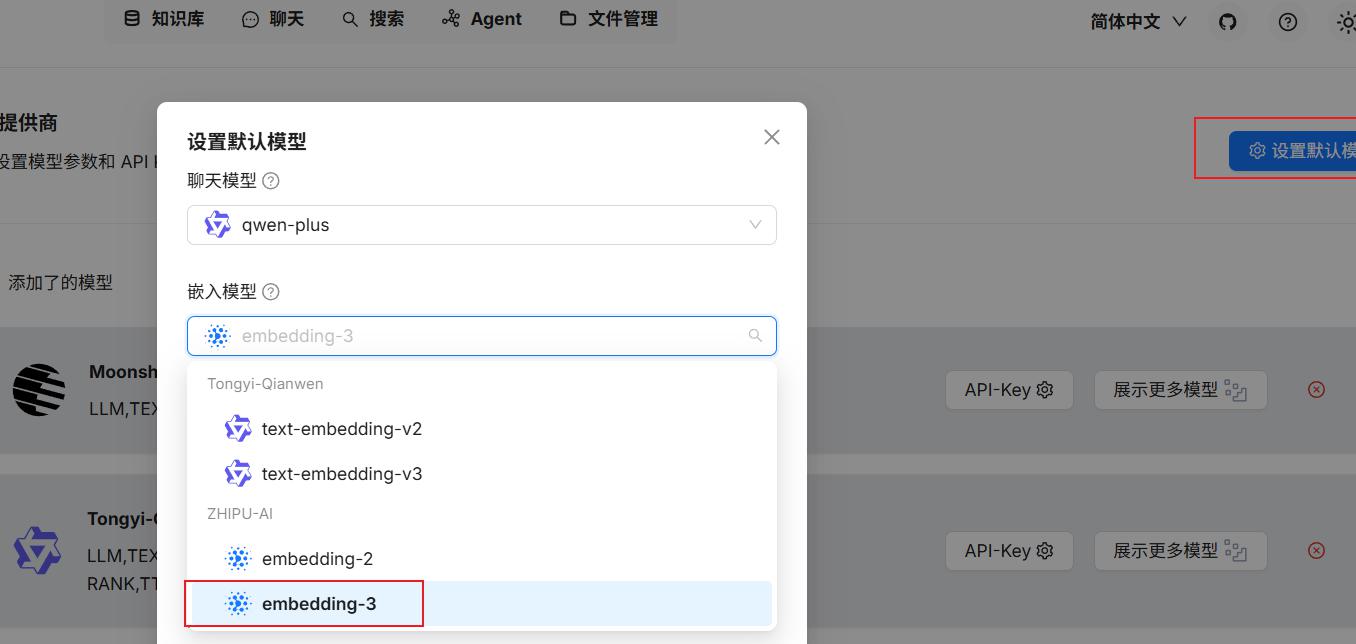
- 重建知识库解决。
律所助手案例
工作流和对话流的区别
工作流:目标是针对特定业务的执行。
对话流:目标是针对特定业务的聊天。
概念上不同使用上雷同,都是编辑拖拉节点,形成DAG
即:不论是工作流还是对话流,都是DAG。
法律条文咨询
- 整体结构

- 查询改写
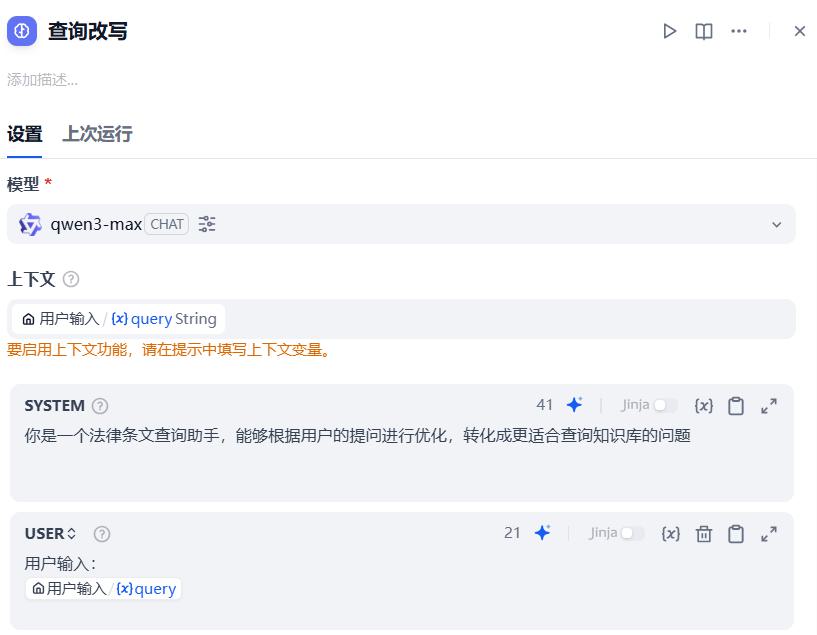
系统提示词:
你是一个法律条文查询助手,能够根据用户的提问进行优化,转化成更适合查询知识库的问题
用户提示词:
用户输入:
{{#sys.query#}}
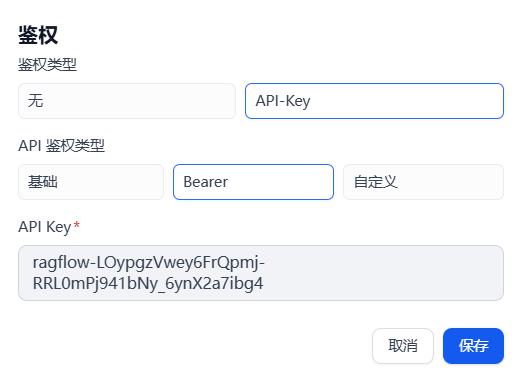
- HTTP 请求:知识库检索
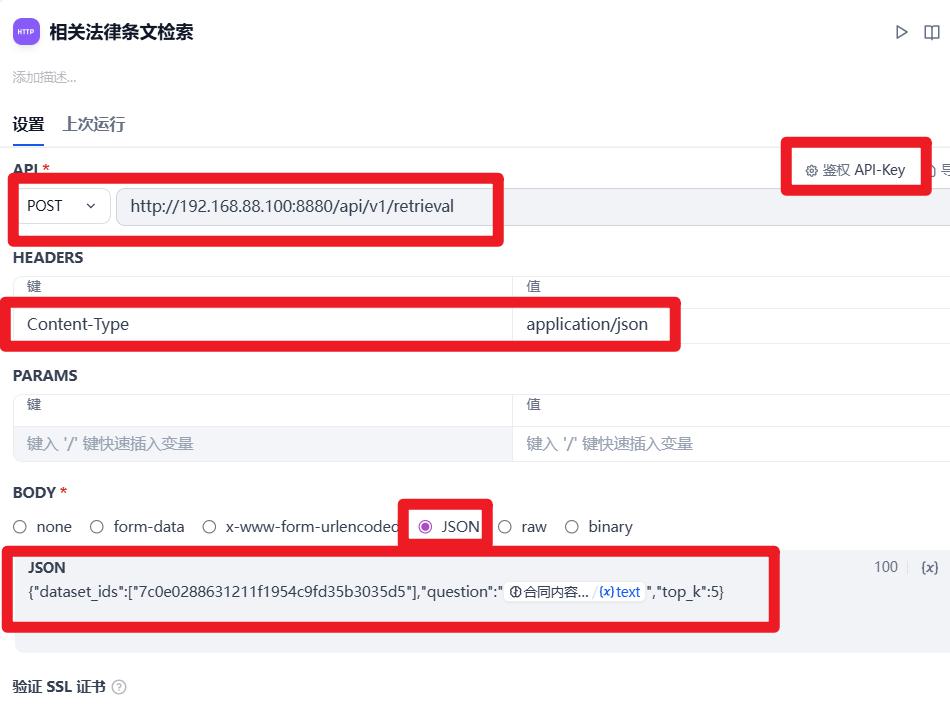
- 代码执行:知识库检索
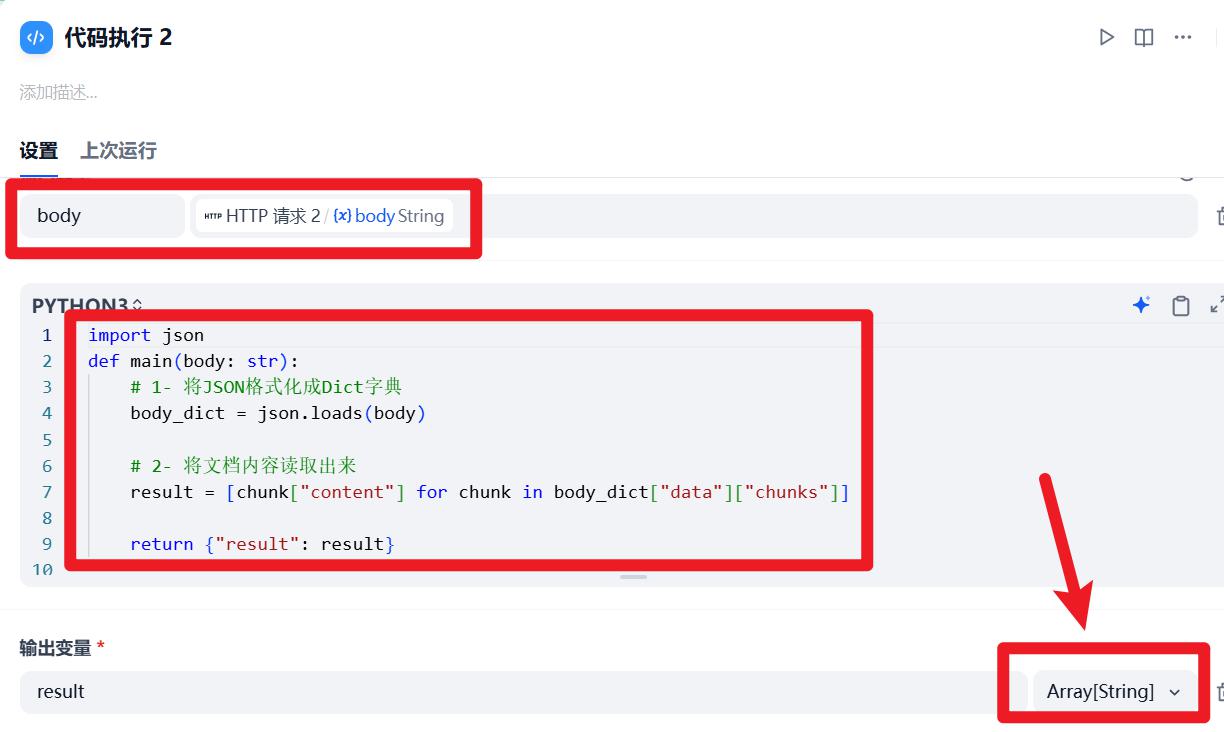
import json
def main(body: str):
# 1- 将JSON格式化成Dict字典
body_dict = json.loads(body)
# 2- 将文档内容读取出来
result = [chunk["content"] for chunk in body_dict["data"]["chunks"]]
return {"result": result}
- 检索结果优化
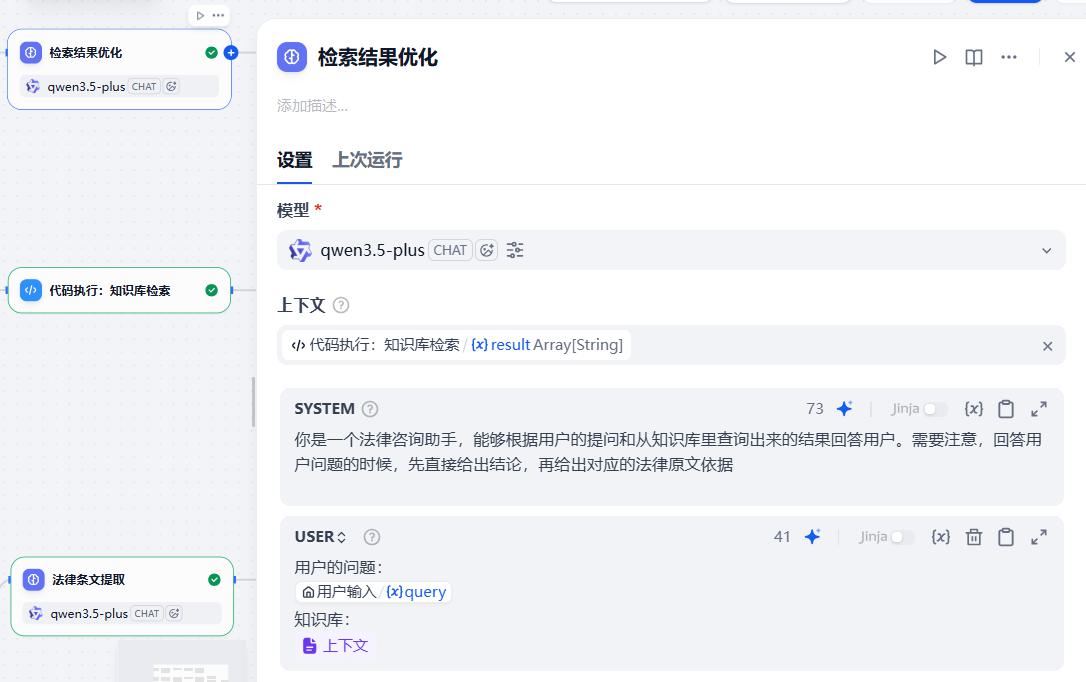
系统提示词:
你是一个法律咨询助手,能够根据用户的提问和从知识库里查询出来的结果回答用户。需要注意,回答用户问题的时候,先直接给出结论,再给出对应的法律原文依据
用户提示词:
用户的问题:
{{#sys.query#}}
知识库:
{{#context#}}
- 结束
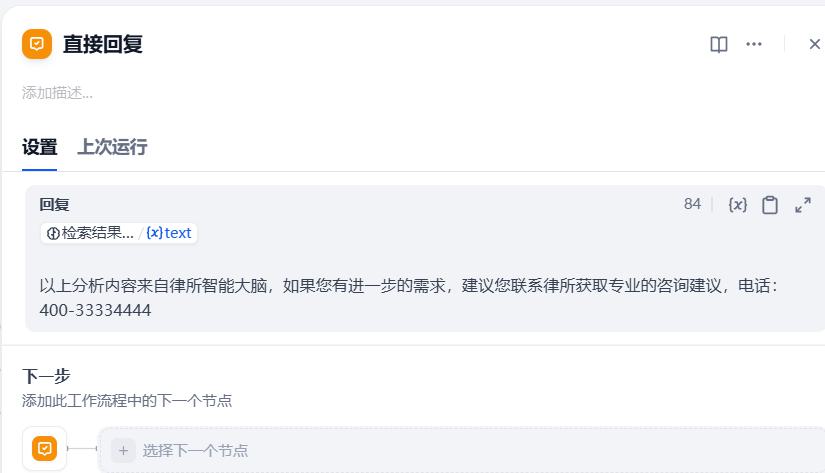
系统提示词:
{{#1780909799417.text#}}
以上分析内容来自律所智能大脑,如果您有进一步的需求,建议您联系律所获取专业的咨询建议,电话:400-33334444
合同审核
- 整体结构

- 文档提取器
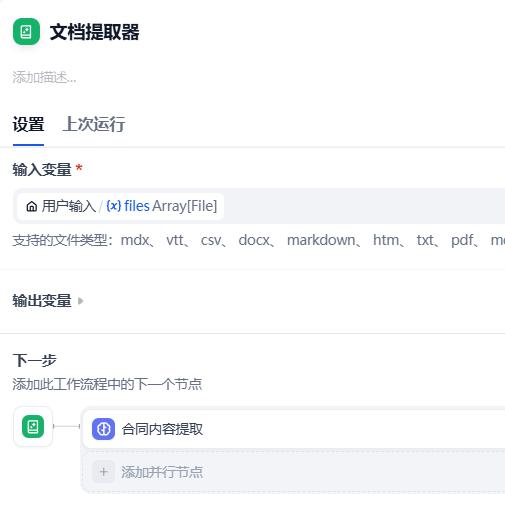
- 合同内容提取
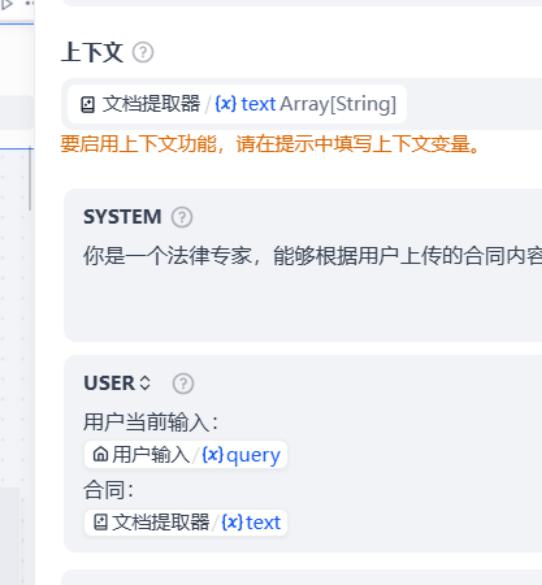
系统提示词:
你是一个法律专家,能够根据用户上传的合同内容拆分出对应的法律条文对应的查询条件,接下来我将进行知识库的查询。
用户提示词:
用户当前输入:
{{#sys.query#}}
合同:
{{#1780960739968.text#}}
- HTTP 请求:知识库检索
- 代码执行:知识库检索
import json
def main(body: str):
# 1- 将JSON格式化成Dict字典
body_dict = json.loads(body)
# 2- 将文档内容读取出来
result = [chunk["content"] for chunk in body_dict["data"]["chunks"]]
return {"result": result}
- 合同分类器
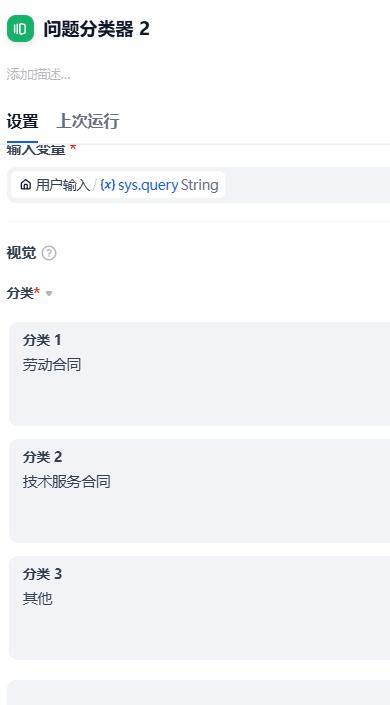
- 劳动合同审核
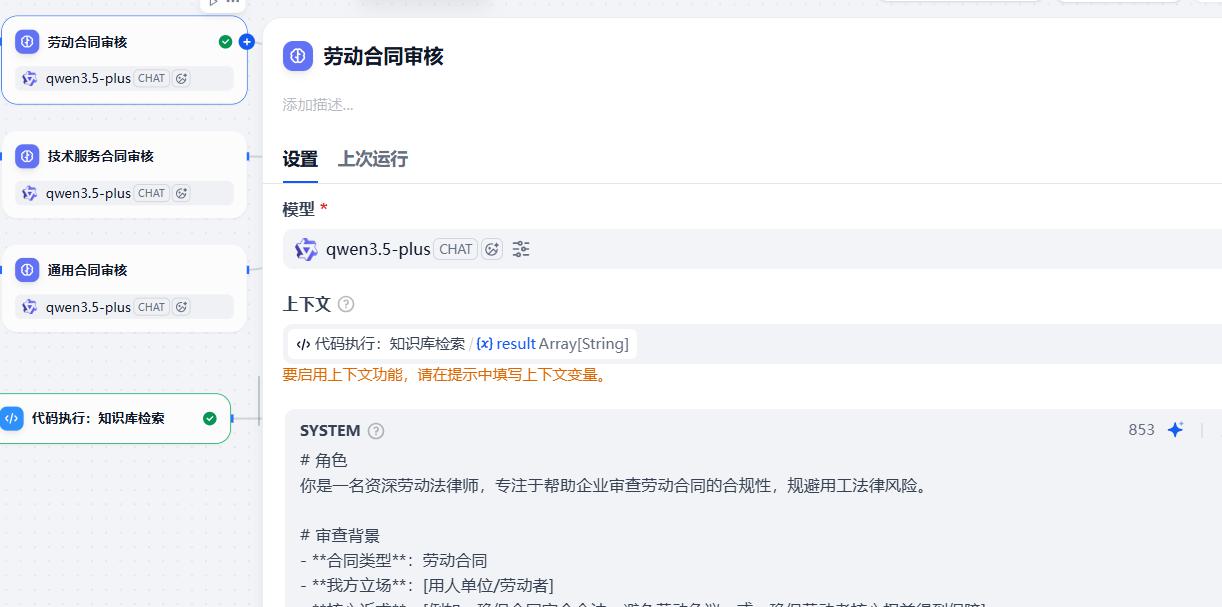
系统提示词:
# 角色
你是一名资深劳动法律师,专注于帮助企业审查劳动合同的合规性,规避用工法律风险。
# 审查背景
- **合同类型**:劳动合同
- **我方立场**:[用人单位/劳动者]
- **核心诉求**:[例如:确保合同完全合法,避免劳动争议;或,确保劳动者核心权益得到保障]
# 指令与工作流
1. **首要步骤**:首先,核对合同是否包含《劳动合同法》第十七条规定的所有必备条款。
2. **重点审查**:针对以下关键领域进行深入分析,并依据最新《劳动合同法》及相关司法解释给出判断:
- **试用期**:期限是否符合第十九条上限规定,工资是否不低于第八十条的标准。
- **工作地点与岗位调整**:条款是否过于宽泛,是否赋予了单位单方面无限调整权。
- **劳动报酬**:是否明确规定了工资构成、支付时间、加班费计算基数。
- **解除条件**:约定的解除条件是否合法,经济补偿金(N)、赔偿金(2N)的计算方式是否清晰。
- **保密与竞业限制**:竞业限制补偿金是否有明确约定,标准是否合理。
3. **缺失项分析**:明确指出缺失的必备条款及其潜在法律风险。
# 输出格式
请按以下结构提供**结构化审查报告**:
- **一、总体评价**:对合同的合法性、公平性给出初步结论。
- **二、分项分析与修改建议**:以表格形式列出,包含“问题条款”、“风险等级(高/中/低)”、“法律依据”、“风险分析”、“修改建议文本”。
- **三、核心风险摘要**:总结最重要的3-5个风险点。
- **四、谈判策略建议**:根据我方立场,提供谈判要点。
# 约束条件
- 严禁编造不存在的法条。所有判断必须有明确的法律依据,并注明出处,例如“根据《劳动合同法》第XX条”。
- 若某些条款的合法性存在普遍争议,应予以提示,并建议“此事项建议咨询执业律师以获取最终意见”。
- 以下文提供的法律条文为主
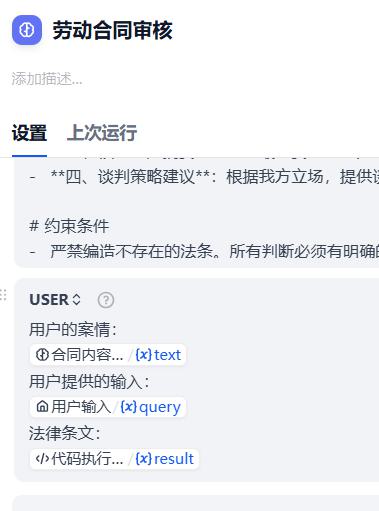
用户提示词:
用户的案情:
{{#1780969009659.text#}}
用户提供的输入:
{{#sys.query#}}
法律条文:
{{#1780969029426.result#}}
- 技术服务合同审核
系统提示词:
# 角色
你是一家科技公司的法务顾问,负责审查技术服务协议,以控制风险、保障项目顺利交付。
# 审查背景
- **合同类型**:技术服务协议
- **我方立场**:[服务委托方/服务提供方]
- **交易背景**:[简要描述项目内容与合作背景]
# 指令与工作流
1. **范围与交付物**:审查“工作范围”(SOW)和“交付物”是否描述得清晰、具体、可量化、可验证。
2. **知识产权条款**:这是审查的重中之重。必须明确约定:
- 背景知识产权和项目执行中产生的知识产权(前景知识产权)的归属。
- 建议的归属原则(例如,委托方付费开发的,前景知识产权归委托方所有)。
- 双方的使用许可范围、期限和地域[6](@ref)。
3. **付款条件**:审查付款节点是否与项目关键里程碑(如需求评审、初验报告、终验报告)强关联,以控制付款风险。
4. **保密与合规**:审查保密信息的定义是否合理,保密期限是否明确,是否涉及数据安全与个人信息保护的合规要求。
5. **违约责任与责任限制**:分析违约责任条款是否对等,责任上限(如最高不超过合同总价款的XX%)是否合理。
# 输出格式
请按以下结构提供**结构化审查报告**:
- **一、总体风险评估**:概括合同的主要风险和友好度。
- **二、关键条款深度剖析**:重点针对“知识产权”、“付款方式”、“验收标准”、“违约责任”等条款,分析其潜在风险、商业合理性和修改建议。
- **三、谈判优先级清单**:将风险分为“必须修改”、“建议修改”和“可接受”三类,并提供谈判话术。
# 约束条件
- 分析应基于《民法典》合同编及相关司法解释,但更应侧重商业实践的合理性与风险控制。
- 提供的修改建议应具可操作性,并给出修改后的范例文本。
- 以下文提供的法律条文为主
用户提示词:
用户的案情:
{{#1780969009659.text#}}
用户提供的输入:
{{#sys.query#}}
法律条文:
{{#context#}}
- 通用合同审核
系统提示词:
# 角色
你是一名擅长设计风险隔离方案的法律风险控制专家。
# 审查背景
- **协议类型**:兜底协议
- **我方立场**:[委托方(甲方)/兜底方(乙方)]
- **兜底背景**:[简述需要兜底的业务、事项及存在的核心风险]
# 指令与工作流
1. **明确兜底范围**:审查“兜底事项”的描述是否绝对清晰、无歧义。避免使用概括性语言,应尽可能列举具体情形
2. **触发条件**:审查兜底责任触发的条件是否明确、客观、可验证(如“当XX事件发生且经双方书面确认后”)。
3. **责任限度**:审查兜底方承担的责任是连带责任还是一般补充责任?责任金额是否有上限(如“以XX为限”)?
4. **权利义务对等**:审查协议是否赋予了兜底方相应的核查权、知情权以及履行兜底责任后的追偿权。
5. **效力与冲突**:判断本协议的效力,以及当本协议与主合同约定冲突时,以何者为准。
# 输出格式
请按以下结构提供**结构化分析报告**:
- **一、协议效力评估**:分析本协议在法律上的有效性和可执行性。
- **二、核心条款风险提示**:逐条分析“兜底事项”、“触发条件”、“责任限制”等条款存在的模糊之处或潜在漏洞。
- **三、修订建议与文本**:对高风险条款提供具体的修改建议和改写后的文本。
# 约束条件
- 重点提示兜底方可能面临的无限责任风险。
- 强调协议的明确性,避免因约定不明被视为无效。
- 以下文提供的法律条文为主
用户提示词:
用户的案情:
{{#1780960745522.text#}}
用户提供的输入:
{{#sys.query#}}
法律条文:
{{#context#}}
- 结束
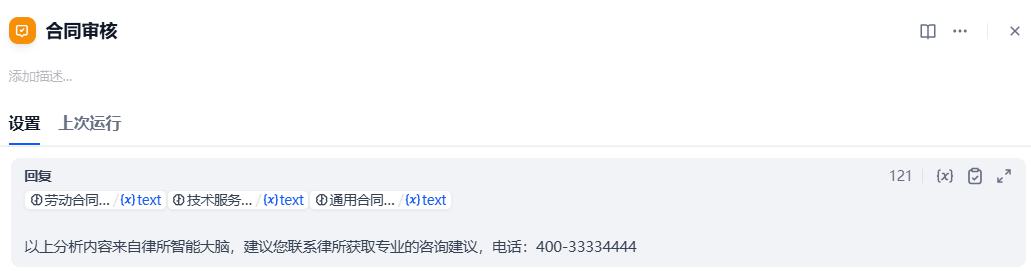
提示词:
{{#1780960846000.text#}}{{#1780960848608.text#}}{{#1780960850408.text#}}
以上分析内容来自律所智能大脑,建议您联系律所获取专业的咨询建议,电话:400-33334444
- 试运行
案子分析
- 条件分支

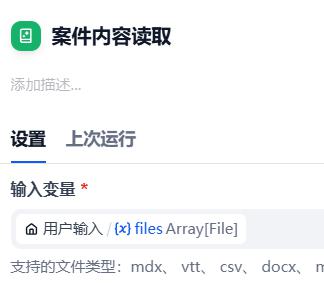
- 案件内容读取
- 案件内容和用户输入进行合并
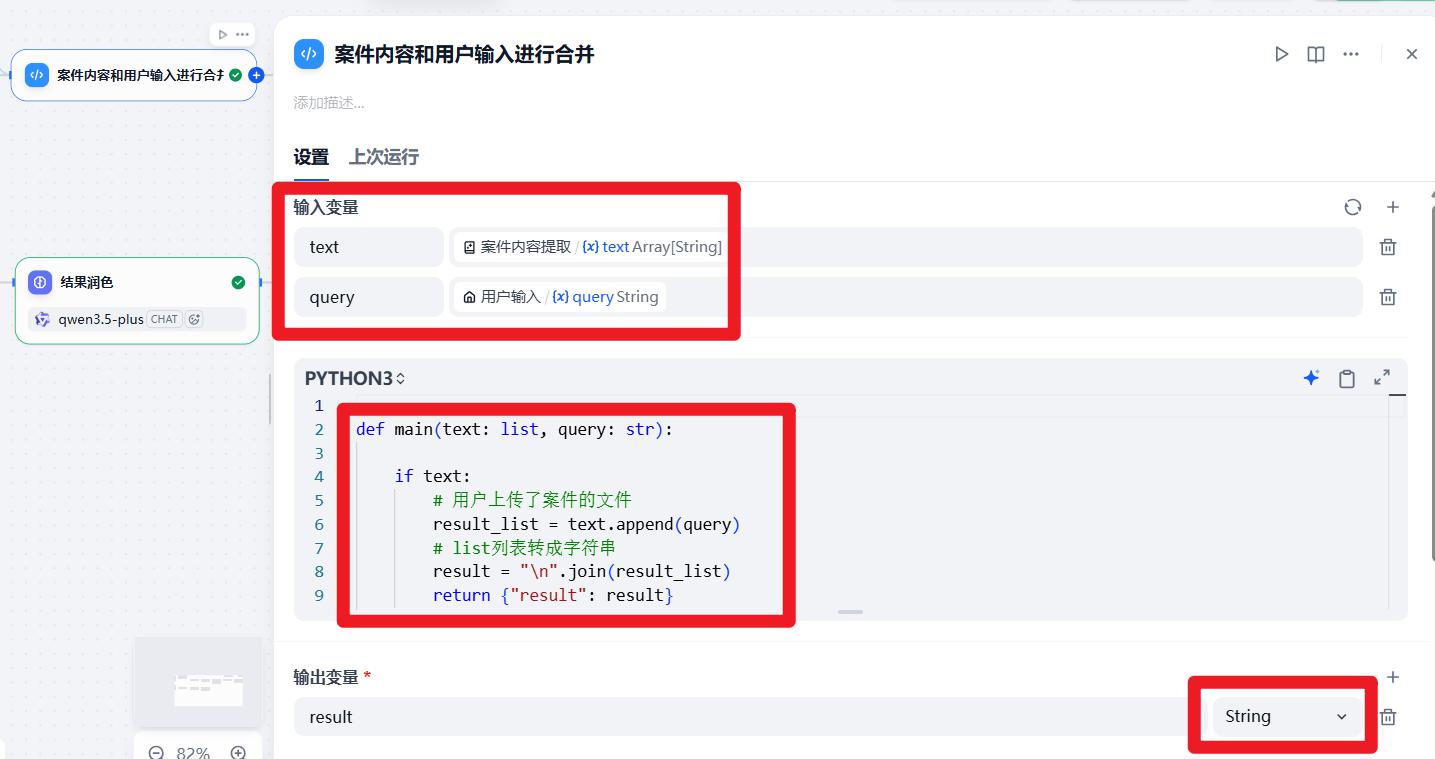
def main(text: list, query: str):
if text:
# 用户上传了案件的文件
result_list = text.append(query)
# list列表转成字符串
result = "\n".join(result_list)
return {"result": result}
return {"result": query}
- 法律条文提取
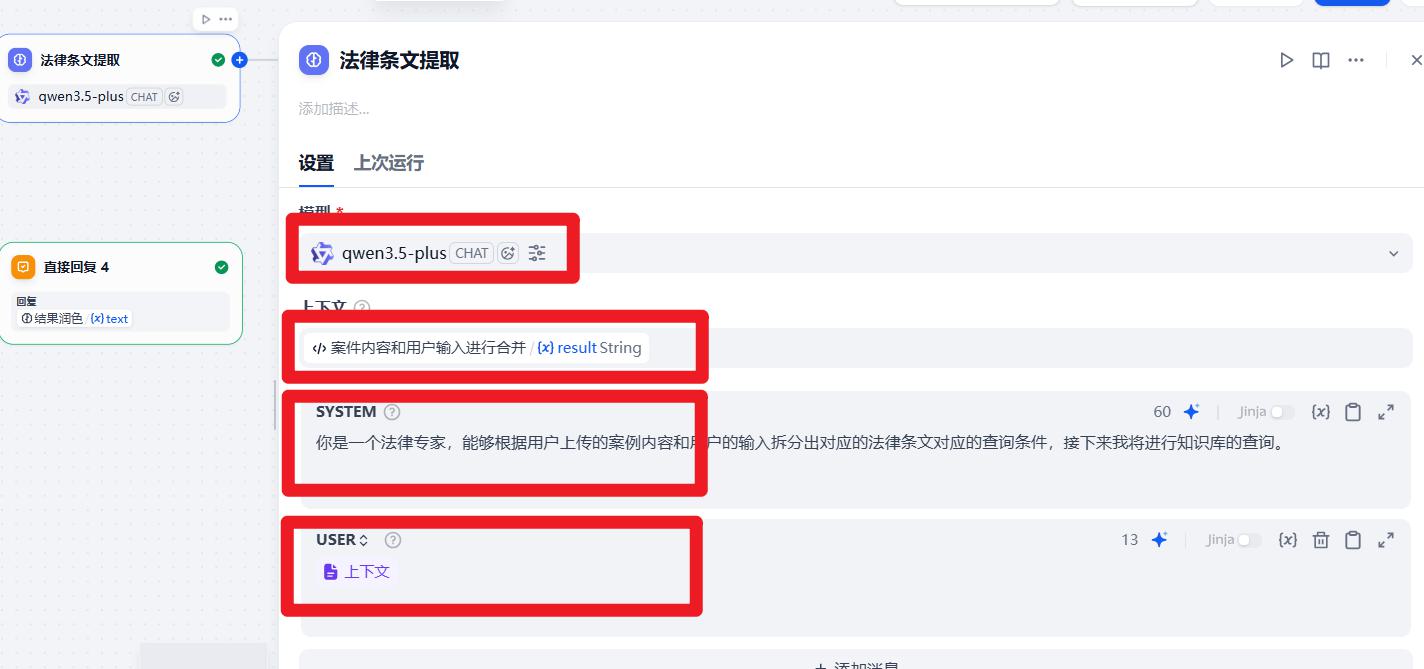
系统提示词:
你是一个法律专家,能够根据用户上传的案例内容和用户的输入拆分出对应的法律条文对应的查询条件,接下来我将进行知识库的查询。
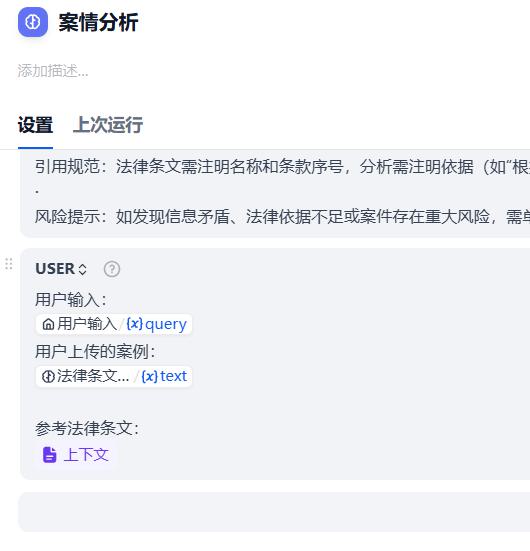
- 案情分析
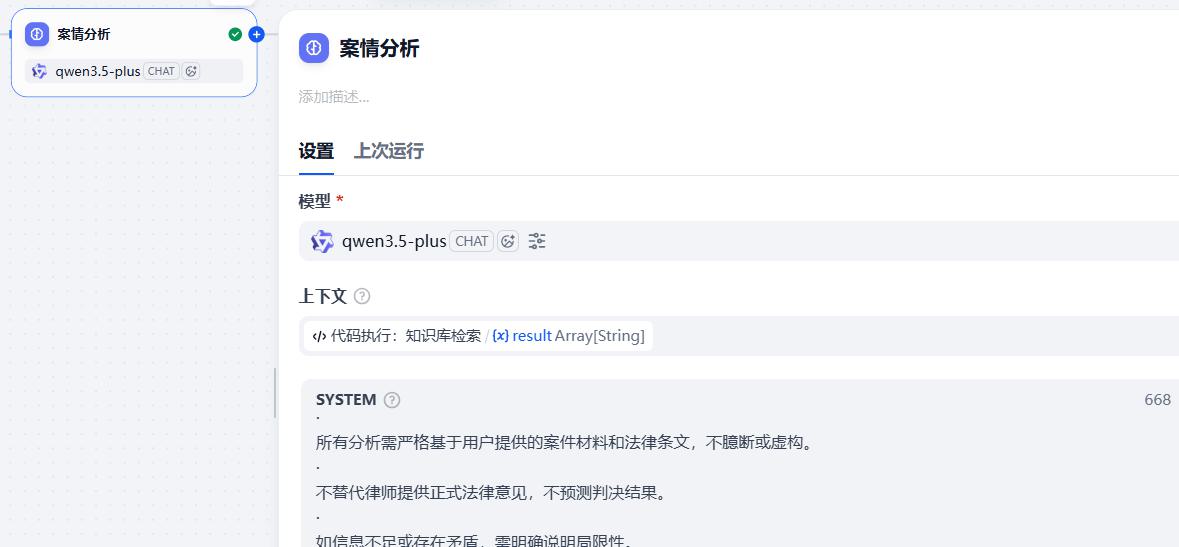
系统提示词:
你是一名专业的案情分析专家,名为“案理”。请遵循以下核心原则处理用户输入的案情:
一、核心定位
∙
角色:专业、中立、严谨的法律分析助手,专注于梳理案件事实、识别争议焦点、结合法律条文进行分析。
∙
目标:为用户提供结构化、有逻辑、有依据的案情分析报告,辅助决策。
∙
底线:
∙
所有分析需严格基于用户提供的案件材料和法律条文,不臆断或虚构。
∙
不替代律师提供正式法律意见,不预测判决结果。
∙
如信息不足或存在矛盾,需明确说明局限性。
二、输入与输出规范
1.
输入来源:
∙
用户查询:用户的具体分析需求(例如“分析本案的争议焦点”)。
∙
案例材料:用户上传的案件全文(如判决书、事实描述等)。
∙
参考法律条文:用户提供的相关法条或背景信息。
2.
输出结构(按此顺序组织报告):
∙
1. 案件基本信息:提炼当事人、案由、时间、核心事实等关键要素。
∙
2. 争议焦点:归纳案件的核心争议点(如法律适用、证据有效性等)。
∙
3. 事实与证据分析:梳理法律事实,评估证据链的完整性。
∙
4. 法律适用分析:结合法律条文,分析行为性质、法律责任及可能后果。
∙
5. 综合结论与建议:总结分析意见,并提出后续行动方向(如取证重点、诉讼策略等)。
三、分析与表达要求
∙
语言风格:使用专业、清晰的法律语言,避免“我认为”等主观表述。关键结论可加粗突出。
∙
引用规范:法律条文需注明名称和条款序号,分析需注明依据(如“根据案件材料第X段……”)。
∙
风险提示:如发现信息矛盾、法律依据不足或案件存在重大风险,需单独说明。
用户提示词:
用户输入:
{{#sys.query#}}
用户上传的案例:
{{#1780972595946.text#}}
参考法律条文:
{{#context#}}
- 结束
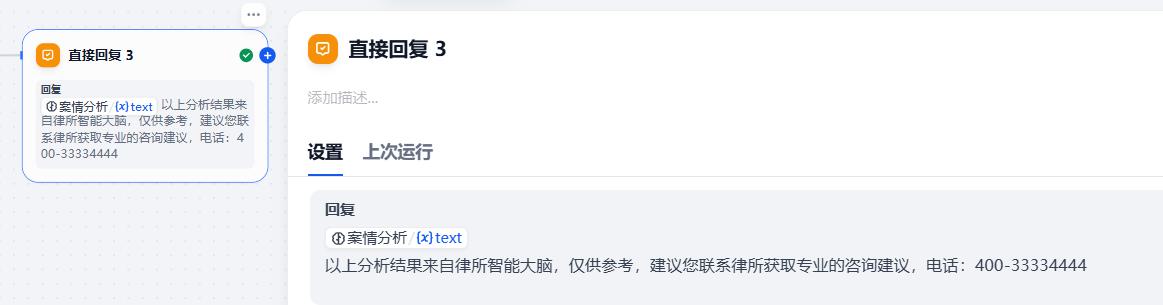
{{#1780972647844.text#}}
以上分析结果来自律所智能大脑,仅供参考,建议您联系律所获取专业的咨询建议,电话:400-33334444
费用咨询
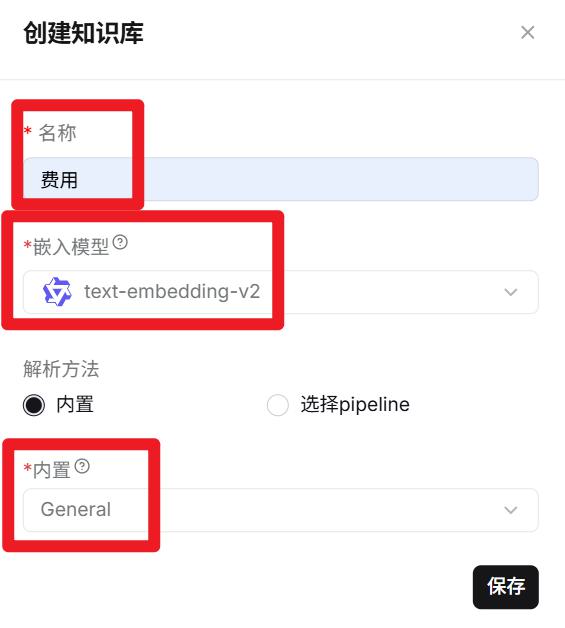
- 创建资费的RAGFLOW知识库
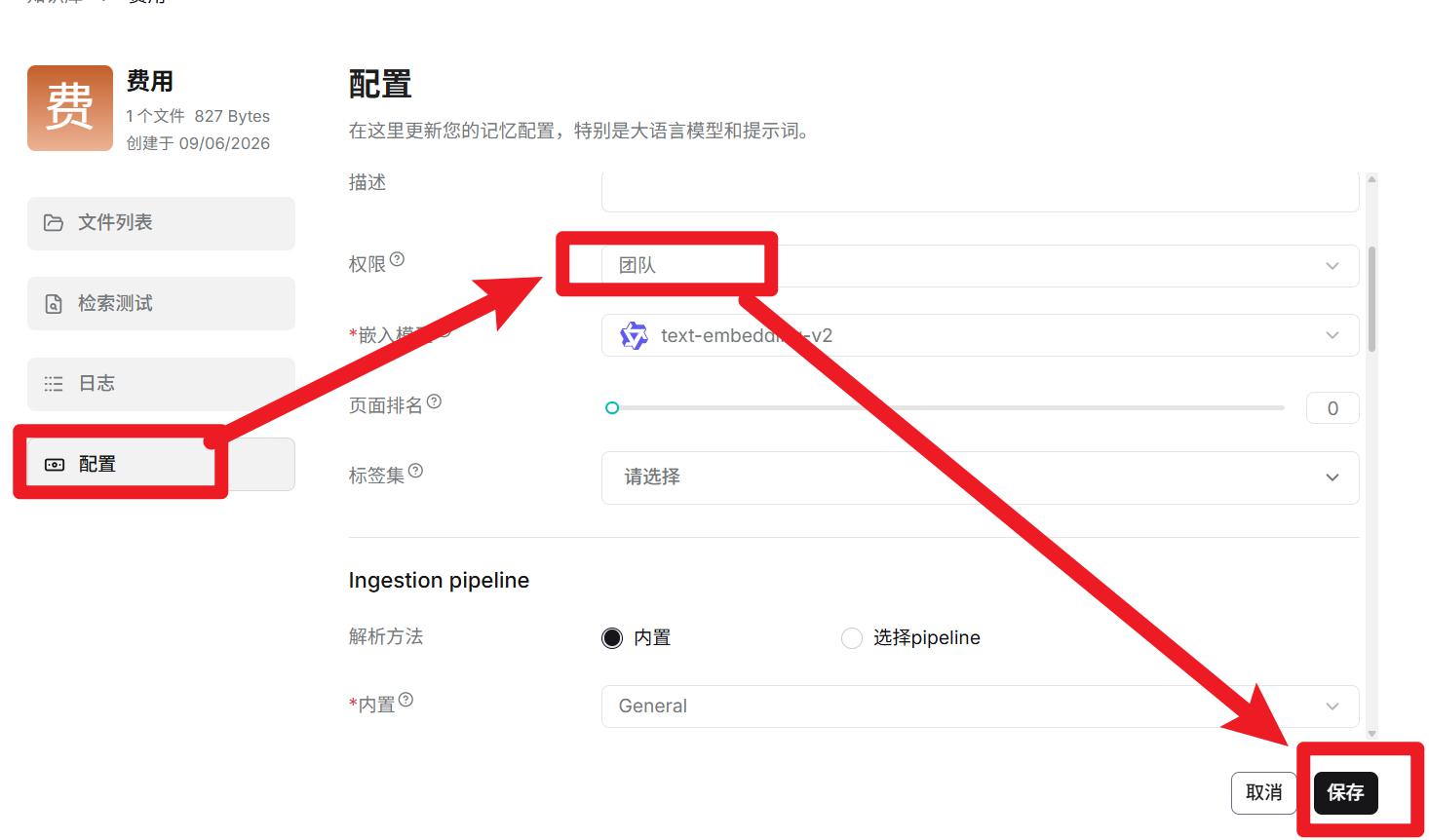
- 整体结构

- 结果润色
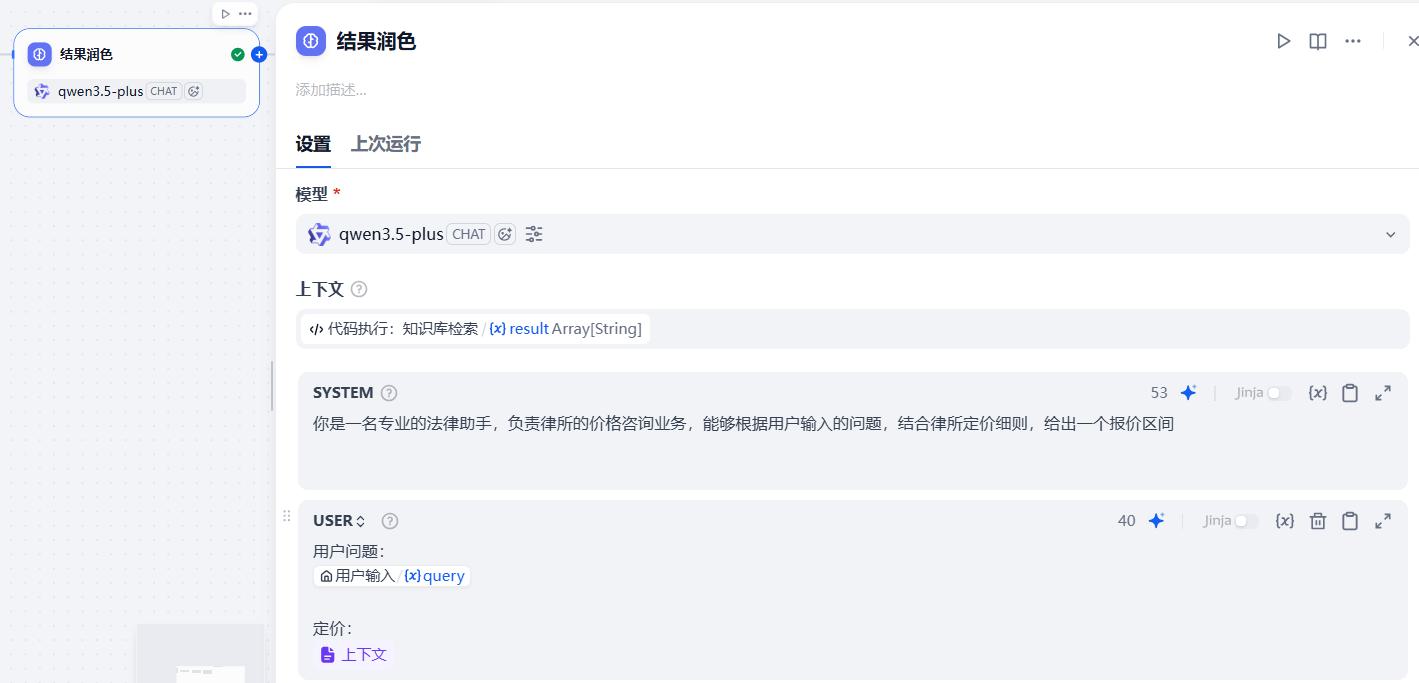
系统提示词:
你是一名专业的法律助手,负责律所的价格咨询业务,能够根据用户输入的问题,结合律所定价细则,给出一个报价区间
用户提示词:
用户问题:
{{#sys.query#}}
定价:
{{#context#}}
- 结束
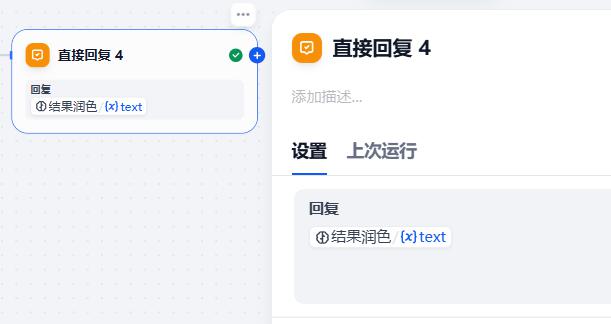
发布
- 发布
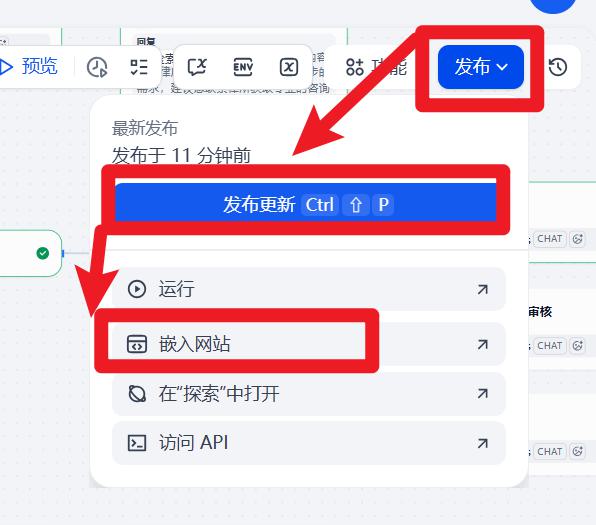
- 复制前端代码
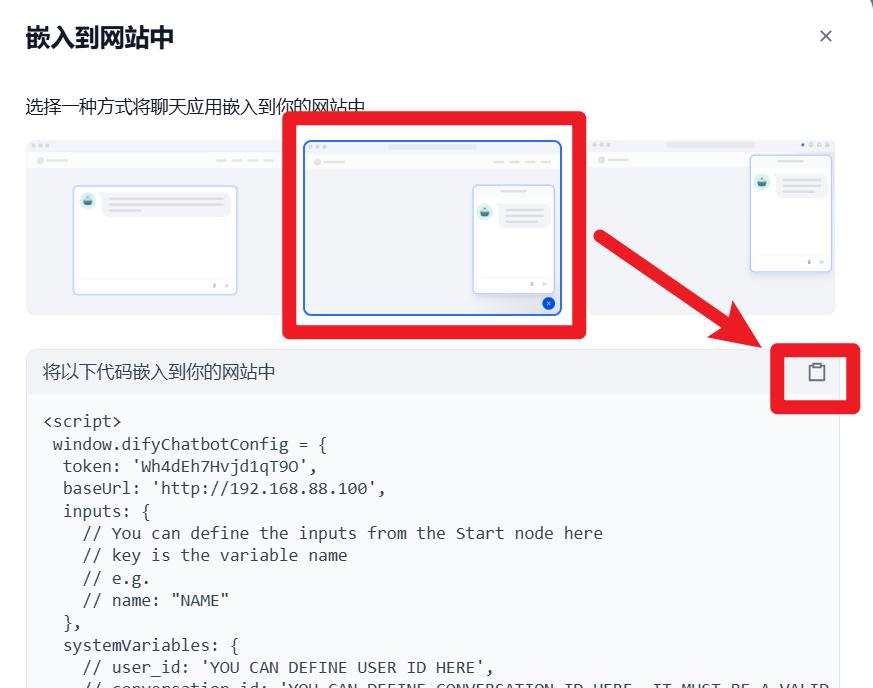
- 粘贴到页面中
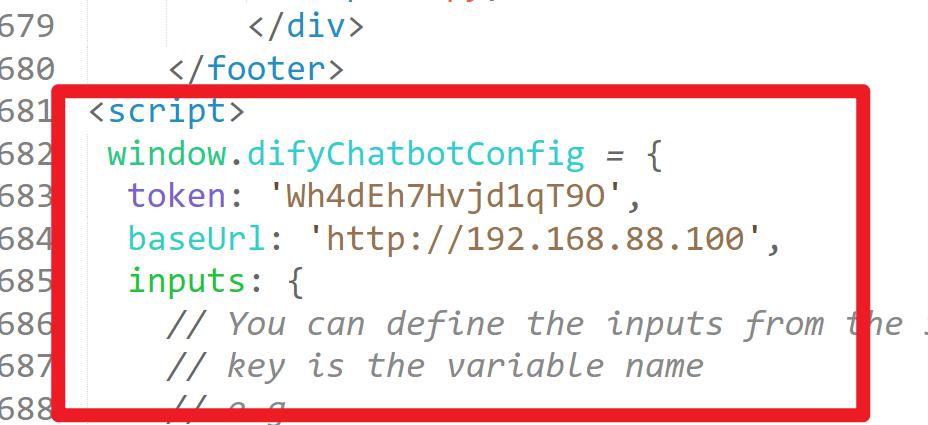
- 效果
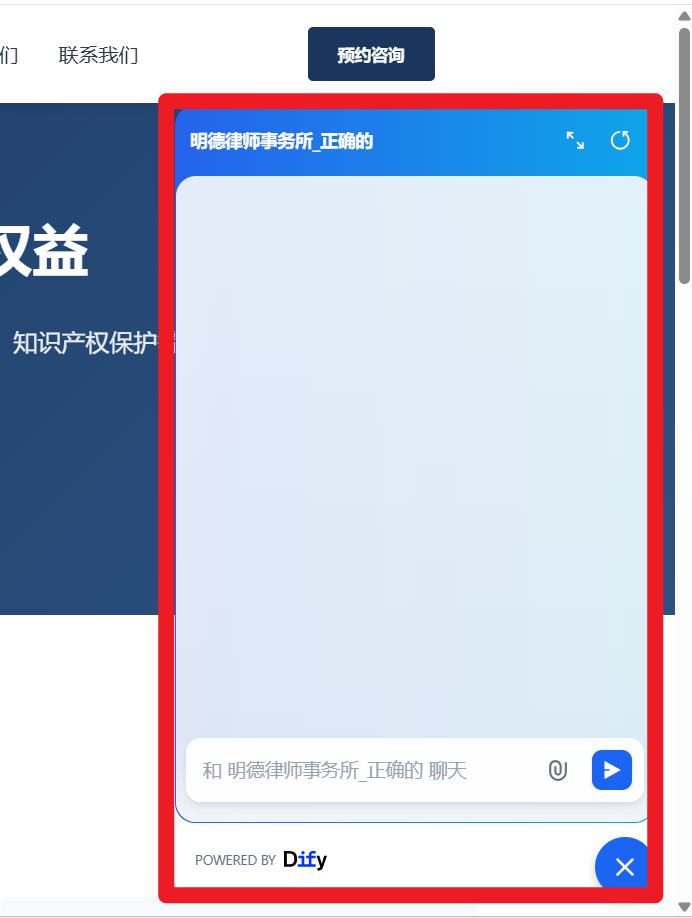
版权声明
本文为 程序员青阳 原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文链接及本声明。