NLP自然语言处理
什么是自然语言处理
【什么是人工智能,分别对应哪几个领域】
AI是模仿甚至超越人的某项机能,NLP、CV、ASR
NLP是机器理解并生成人类语言
自然语言处理的发展简史
1950 -- 图灵提出“机器能思考吗”,划时代性的话题
1956 -- 达特茅斯会议,提出人工智能(Artificial Intelligence),AI的元年,之前都是人类智能(Human Intelligence)
1957-1970 -- NLP开始出现两大阵营:规则 + 统计
1994-1999 -- 统计学开始占据主导地位
2000-2012 -- 机器学习开始盛行
2012-2022 -- 传统的深度学习占据主导地位
2023 -- 大模型时代
- 基于规则举例:设计语言学规则,解析句子结构,例如一个句子由主谓宾构成。
- 基于统计举例:统计机器翻译模型,收集大量平行语料库,例如中英互译,统计不同短语的分配概率,计算给定源语言翻译为目标语言的可能性。
自然语言处理的应用场景
语音助手:小爱同学
机器翻译:谷歌翻译
搜素引擎:百度翻译
智能对话:文心一言
推荐系统:短视频app推荐
。。。
认识文本预处理
- 文本预处理及作用
所处阶段:数据输入到模型之前
作用:数据清洗、指导超参数的确定
- 文本预处理的主要环节
1.文本处理的基本方法:分词、NER、POS
2.文本张量的表示方法:one-hot、word2vec、wordEmbedding
3.文本语料的数据分析:标签数量分析(类别不均衡问题)、句子长度分析、词频统计
4.文本特征处理:添加n-gram特征、文本长度规范
5.数据增强方法:回译数据增强
Anaconda沙箱/虚拟环境介绍
作用:同台电脑能够同时拥有多个不同的Python环境;因为实际工作中,偶尔会出现你参与的/维护项目使用的Python解释器版本的要求是不同的。
每个项目创建单独的虚拟环境
优点:各个项目间隔离开了,相互之间不影响;用到啥库就安装上,开发的时候效率比较高
缺点:需要根据开发需求一个个安装对应的第三方库
Anaconda沙箱/虚拟环境相关命令
conda env list:查看当前有哪些虚拟环境
conda create -n 虚拟环境名称 python==版本号:创建新的虚拟环境,注意虚拟环境的名称不要用中文
conda activate 虚拟环境名称:进入指定的虚拟环境
conda deactivate:退出当前的虚拟环境
conda remove -n 虚拟环境名称 --all:彻底删除指定的虚拟环境
dl_study虚拟环境中安装软件的流程如下:
1- 进入dl_study中查看有哪些工具包
conda activate dl_study
conda list
2- 安装jieba分词器
pip install jieba -i https://mirrors.aliyun.com/pypi/simple/
pip install tensorflow -i https://mirrors.aliyun.com/pypi/simple/
pip install joblib -i https://mirrors.aliyun.com/pypi/simple/
pip install fasttext -i https://mirrors.aliyun.com/pypi/simple/
或者
pip install fasttext-wheel -i https://mirrors.aliyun.com/pypi/simple/
如果不管是安装fasttext还是fasttext-wheel都失败,那么原因是python版本过高。
操作步骤如下:
1- 先进入对应的虚拟环境
2- 安装低版本的python解释器
conda install python=3.10
3- 安装fasttext
pip install fasttext-wheel -i https://mirrors.aliyun.com/pypi/simple/
pip install tensorboard -i https://mirrors.aliyun.com/pypi/simple/
pip install seaborn -i https://mirrors.aliyun.com/pypi/simple/
pip install matplotlib==3.8.4 -i https://mirrors.aliyun.com/pypi/simple/
如果运行matplotlib代码报错,依次执行如下两行命令:
pip uninstall -y matplotlib
pip install matplotlib==3.8.4 -i https://mirrors.aliyun.com/pypi/simple/
pip install wordcloud -i https://mirrors.aliyun.com/pypi/simple/
文本处理的基本方法
分词器(必掌握):把连续长文本切割成独立词语,是所有文本任务的前置基础步骤。
NER 命名实体识别:从文本里提取专有实体(人名、地名、时间、机构等)并分类。
POS 词性标注:给拆分后的每个词语标注词性(名词、动词、形容词等)。
一句话速记: 先分词拆词,再标词语词性,最后提取专属实体。
分词器【掌握】
- 分词的意义
分词就是将连续的字序列,按照一定的规范,重新组合成词序列的过程
一般实现模型训练的时候,模型接受的文本基本最小单位是词语,因此我们需要对文本进行分词
词语是语意理解的基本单元
英文具有天然的空格分隔符,而中文分词的目的:寻找一个合适的分词边界,进行准确分词
- 支持用户自定义词典和繁体字分词
词典的意义
可以根据自定义词典,修改jieba分词方式,优先考虑词典里面的词来切分
格式:词语 词频(可省略) 词性(可省略)
自定义词典内容
# 自定义词典的格式要求:词语 词频(可选) 词性(可选)
传智教育 999 n
我是 66666
黑马程序员 n
旗下有
代码实现
import jieba
def demo01():
content = "传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能"
# 1- 精确模式【掌握】
result = jieba.lcut(content)
print("精确模式:",result)
# 2- 全词模式
# 参数解释:cut_all拆分的词更加细致
result = jieba.lcut(content,cut_all=True)
print("全词模式:", result)
# 3- 搜索引擎模式
# 注意:没有cut_all参数
result = jieba.lcut_for_search(content)
print("搜索引擎模式:", result)
def demo02():
# content = "煩惱即是菩提,我暫且不提"
content = "煩惱hello how菩提,我暫且不提"
result = jieba.lcut(content)
print("繁体分词结果:", result)
def demo03():
content = "传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能"
# 加载自定义词典
jieba.load_userdict("data/my_dict.txt")
# 分词
result = jieba.lcut(content)
print(f"自定义词典:{result}")
if __name__ == '__main__':
# 1- 基础分词
demo01()
# 2- 繁体分词
demo02()
# 3- 自定义词典
demo03()
命名实体识别(NER)
- 定义
命名实体:通常指人名、地名、机构名等专有名词
NER:从一段文本中识别出上述描述的命名实体
常见的7类命名实体:人名、地名、机构名、时间、日期、货币、百分比
- 作用
同词汇一样,命名实体也是人类理解文本的基础单元,也是AI解决NLP领域高阶任务的重要环节
词性标注(pos)
- 定义
对每个词语进行词性的标注:动词、名词、形容词等
- 实现方式
import jieba.posseg as pseg # POS词性标注
# POS词性
def demo1():
result = pseg.lcut("鲁迅爱北京天安门,他骑车去商务部上班")
print(result) # 将pair当成元组/list列表进行处理
for word,pos in result:
print(f"{word}-->{pos}")
if __name__ == '__main__':
# POS词性标注
demo1()
文本张量的表示方法【熟悉】
文本张量的表示方法有几种
onehot
word2vec
- CBOW:连续词袋模式。使用两边的词预测中间的内容
- Skip-gram:跳词模式。使用中间的词预测两边的内容
word embedding
One-Hot 词向量表示
- 介绍
针对每一个词汇,都会用一个向量表示,向量的长度是n(n就是词表大小),n代表去重之后的词汇总量,而且向量中只有0和1两种数字
也称之为:独热编码、01编码
- 代码实现
# from tensorflow.keras.preprocessing.text import Tokenizer # 词汇映射器
from keras.src.legacy.preprocessing.text import Tokenizer # 另一种导包的形式
import joblib
"""
One-hot总结:
1- 优点:简单、好理解
2- 缺点:生成的是一个稀疏向量,也就是只有一个地方是1,其他地方都是0,非常浪费存储和计算资源;语义信息保留的很少
3- 使用:当词和词之间没有关系的时候可以使用。例如:根据人名,预测该名字所属的国家
"""
if __name__ == '__main__':
# 1- 准备数据
vocab = ["周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗", "周杰伦"]
# 2- 创建并且训练词汇映射器
# 2.1- 创建词汇映射器实例对象
tokenizer = Tokenizer()
# 2.2- 训练
tokenizer.fit_on_texts(vocab)
# 2.3- 保存
joblib.dump(tokenizer, "model/my_tokenizer.pkl")
# 2.4- 获得词汇表
# 解释:word_index是dict字典类型。key->词,value->索引,注意索引从1开始
word_index = tokenizer.word_index
# print(type(word_index))
# print(word_index)
# 3- 获得每个词的词向量
for name in vocab:
# 3.1- 初始化词向量
one_hot = [0] * len(word_index)
# 3.2- 获得人名的对应索引
index = word_index[name] - 1
# 3.3- 将指定索引位置的值改为1即可
one_hot[index] = 1
print(f"{name}-->{one_hot}")
- One-hot总结
One-hot总结:
1- 优点:简单、好理解
2- 缺点:生成的是一个稀疏向量,也就是只有一个地方是1,其他地方都是0,非常浪费存储和计算资源;语义信息保留的很少
3- 使用:当词和词之间没有关系的时候可以使用。例如:根据人名,预测该名字所属的国家
Word2Vec模型
Word2Vec是思想,基于one-hot进行了改造
1- CBOW连续词袋模式
2- Skip-gram跳词模式
Fasttext用来实现Word2Vec的工具
word2vec介绍
1- word2vec是一个概念,需要基于Fasttext工具来实现。也就是它们是同一个东西
2- word2vec是对one-hot进行了优化。具体的优化流程:底层是构建了一个深度学习的网络模型,输入层的数据就是one-hot的数据,训练模型,得到权重矩阵。该权重矩阵就是word2vec的词向量
3- word2vec有两种具体模型训练方式:
3.1- CBOW:用上下文两边的词预测中间
3.2- skipgram:用中间的词预测上下文两边的词
4- 优点:避免产生稀疏向量,用的是权重矩阵表示词向量,能够节约存储和计算资源
5- 缺点:是一个静态的词向量编码的过程,因此无法处理一词多意的情况
例如:手机就买苹果、水果中苹果最好吃:两句话中的苹果的词向量是同一个
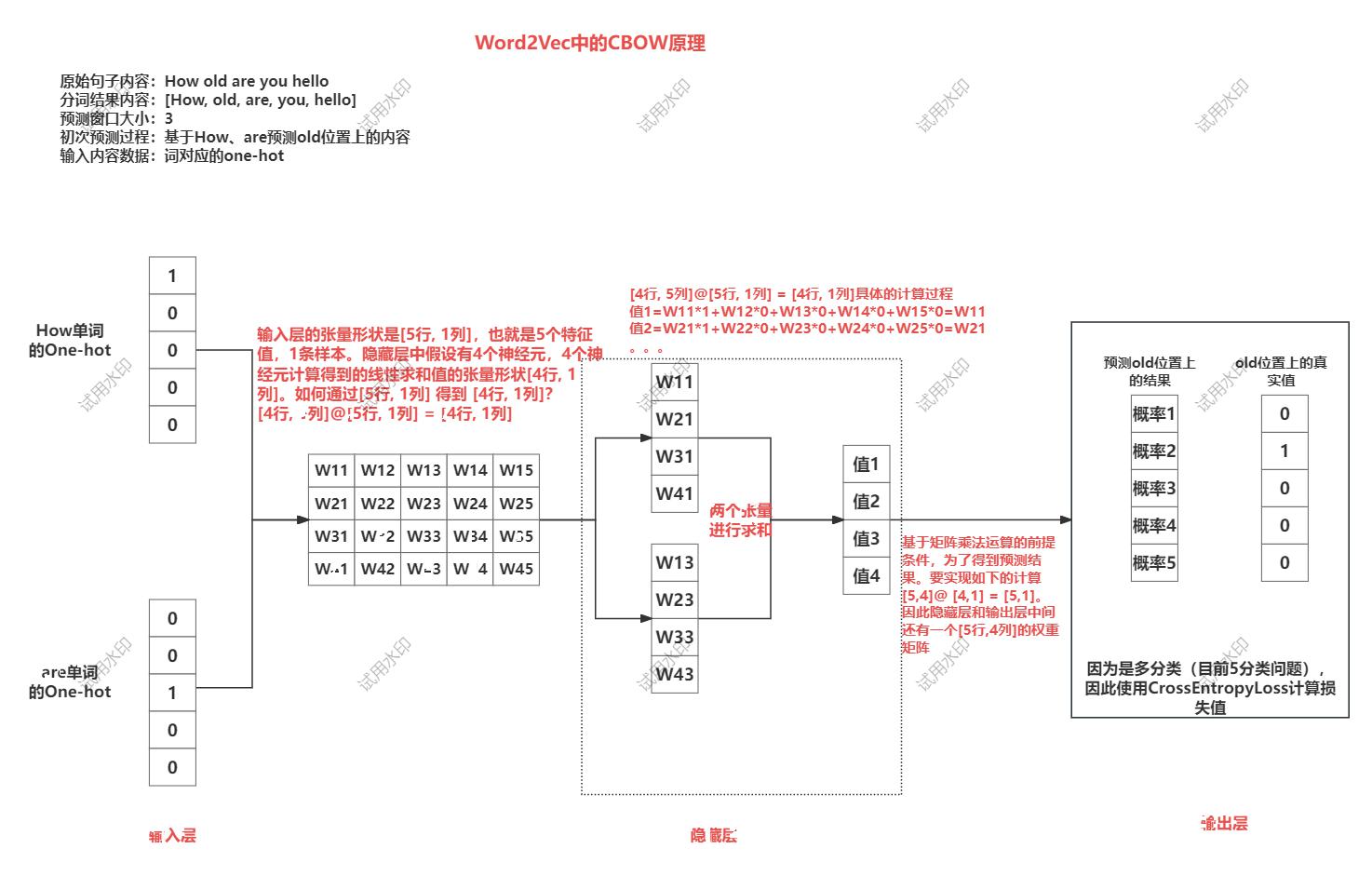
CBOW【了解】
核心思想:给一段文本,选择一定的窗口,然后利用上下文预测中间目标词
- 实现过程
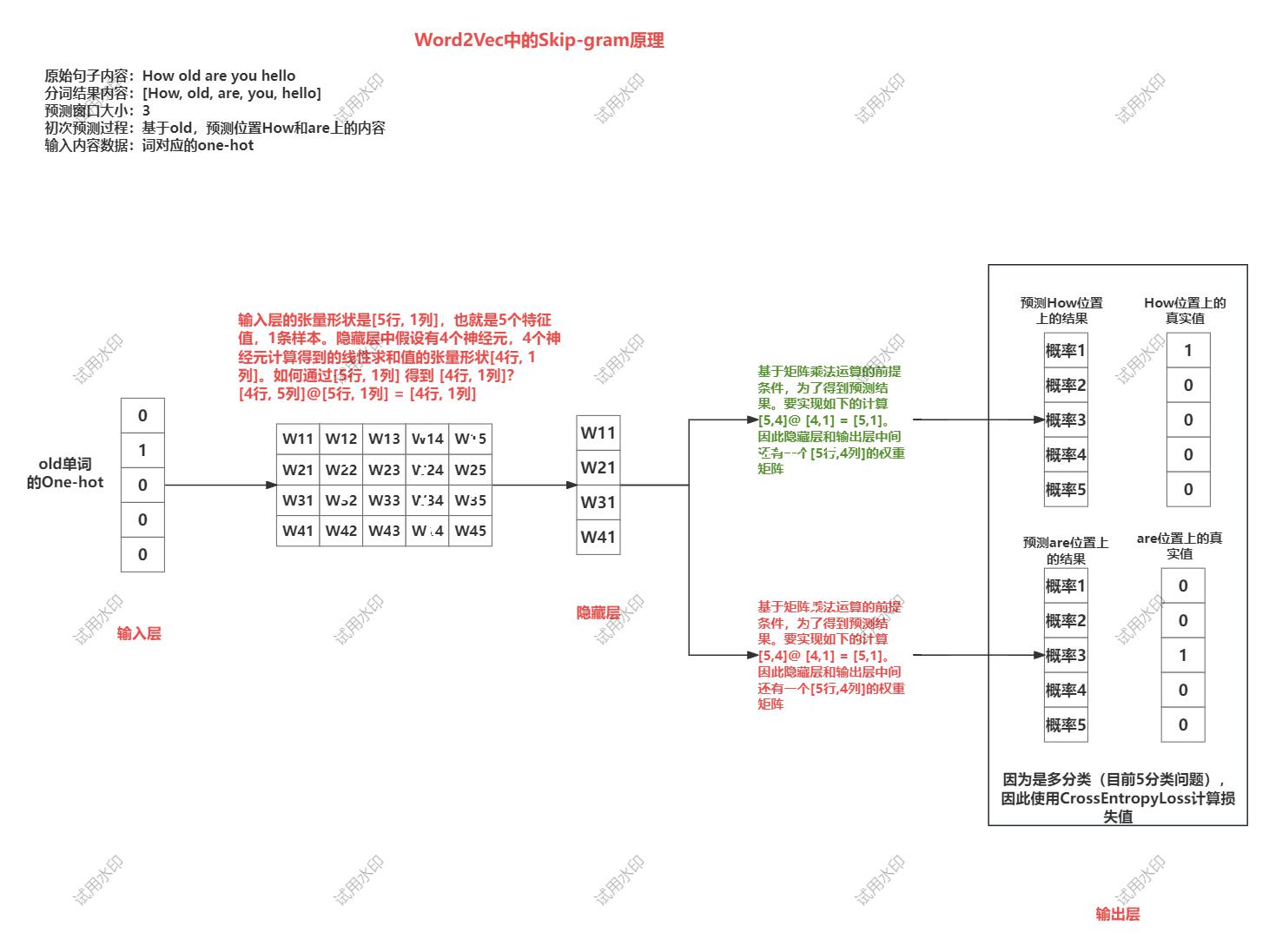
skip-gram【了解】
核心思想: 给出一段文本,选择一定窗口获取数据集,利用中间词来预测上下文
- 实现过程
Fasttext实现Word2Vec代码【掌握】
fasttext 无监督词向量代码核心
适用场景:数据无__label__标签,只能用无监督训练
基础流程:训练 (train_unsupervised)→保存 (save_model)→加载 (load_model)
常用功能:
get_word_vector:获取单词向量
get_nearest_neighbors:查询近义 / 近形词
可调超参:input 文件、model (skipgram/cbow)、dim 向量维度、epoch 轮数、lr 学习率、thread 线程数
- 基本过程
1.获取数据
2.训练模型(训练词向量)
正常安装:pip install fasttext -i https://mirrors.aliyun.com/pypi/simple/
如果失败:pip install fasttext-wheel -i https://mirrors.aliyun.com/pypi/simple/
3.向量的检验
4.超参数设定
5.模型的保存和加载
- 代码实现
"""
如果不管是安装fasttext还是fasttext-wheel都失败,那么原因是python版本过高。
操作步骤如下:
1- 先进入对应的虚拟环境
2- 安装低版本的python解释器
conda install python=3.10
3- 安装fasttext
pip install fasttext-wheel -i https://mirrors.aliyun.com/pypi/simple/
"""
import fasttext
def demo01():
# 1- 使用无监督学习训练模型
"""
为什么这里只能使用无监督学习?
答:因为数据中没有明确标记目标值。有监督学习对文件内容有严格要求,有__label__
"""
# model = fasttext.train_unsupervised("data/fil9")
model = fasttext.train_unsupervised("data/fil9_min")
# 2- 保存训练好的模型
model.save_model("model/word2vec.pkl")
def demo02():
# 1- 加载训练好的模型
model = fasttext.load_model("model/word2vec.pkl")
# 2- 获得某个词的词向量
word_vec = model.get_word_vector("hello")
print(word_vec)
def demo03():
# 1- 加载训练好的模型
model = fasttext.load_model("model/word2vec.pkl")
# 2- 获得相近的几个词
# 会从词形、词义方面进行查找。
# result_list = model.get_nearest_neighbors("dog")
result_list = model.get_nearest_neighbors("cat")
# 3- 输出
print(result_list)
def demo04():
"""
参数解释:
input:训练集路径
model:word2vec的模式。默认是skipgram,可以设置为cbow
dim:词向量的维度
epoch:训练的轮次
lr:初始学习率
thread:训练的线程个数
"""
model = fasttext.train_unsupervised(
input="data/fil9_min",
model="cbow",
dim=200,
epoch=1,
lr=0.1,
thread=10
)
model.save_model("word2vec_better.pkl")
if __name__ == '__main__':
# 1- 训练并保存模型
# demo01()
# 2- 获得词的词向量
# demo02()
# 3- 获得相近的词
# demo03()
# 4- 超参数调优设置【掌握】
demo04()
词嵌入Word Embedding【复习】
Word2Vec总结
1- 优点: 相对One-hot来说,Word2Vec产生的是稠密向量(使用较少的数据来包含比较丰富的语义信息),能够减少存储和计算资源。而且Word2Vec考虑是词的上下文语义信息
2- 缺点: Word2Vec产生的词向量是静态的,也就是同个词的词向量永远不会发生变化,那么对于一词多意的情况解决的不好。例如:吃的苹果和苹果手机中的苹果,Word2Vec无法区分
Word Embedding总结
1- 优点: Word Embedding产生的是稠密向量。而且相对Word2Vec来说,它产生的词向量是动态的,能够比较好的区分一词多意的情况。同时,相对Word2Vec来说,它产生的词向量可以直接给到神经网络的隐藏层使用
2- 缺点: 因为要根据词所在的不同句子,来动态的生成对应的词向量,因此训练耗时比较多
- 实现过程
# 词汇映射器:
my_tokenizer = Tokenizer() #创建词汇映射器
my_tokenizer.fit_on_texts(word_list) # fit_on_texts 训练
# word_index:类型是字典。key->词,value->词索引,注意索引是从1开始的
word_index = my_tokenizer.word_index
借助nn.Embedding(num_embeddings, embed_dim):
num_embeddings:代表词汇(去重之后)的总量
embed_dim:是我们设定的词向量维度
- 代码实现
import os
os.environ["TF_ENABLE_ONEDNN_OPTS"]="0" # 环境变量的参数值必须是字符串类型
import jieba
from keras.src.legacy.preprocessing.text import Tokenizer # 词汇映射器:用来创建词汇表
import torch
import torch.nn as nn
# pip install tensorboard -i https://mirrors.aliyun.com/pypi/simple/
from torch.utils.tensorboard import SummaryWriter # 可视化查看词向量
if __name__ == '__main__':
# 1- 准备数据
sentence1 = '传智教育是一家上市公司,旗下有黑马程序员品牌。我是在黑马这里学习人工智能'
sentence2 = "我爱自然语言处理"
article = [sentence1, sentence1]
# 2- 分词
word_list = []
for sen in article:
word_list.append(jieba.lcut(sen))
# print(word_list)
# 3- 构建词汇表:使用词汇映射器构建
my_tokenizer = Tokenizer()
my_tokenizer.fit_on_texts(word_list)
# word_index:类型是字典。key->词,value->词索引,注意索引是从1开始的
word_index = my_tokenizer.word_index
# print(type(word_index))
# print(word_index)
# 4- 获得词向量
# 4.1- 创建词嵌入层的实例对象
"""
参数解释:
num_embeddings:词汇表中词的个数
embedding_dim:词向量维度
"""
ebd = nn.Embedding(num_embeddings=len(word_index),embedding_dim=6)
# 4.2- 调用
for word,index in word_index.items():
word_vec = ebd(torch.tensor(index-1))
print(f"{word}->{word_vec}")
# 5-【了解】可视化展示
# log_dir不要手动创建;完整的路径中不要有中文
summary_obj = SummaryWriter(log_dir="./runs")
summary_obj.add_embedding(ebd.weight.data, word_index.keys())
summary_obj.close()
结果可视化
- 命令:tensorboard –logdir=runs –host 127.0.0.1
- 截图:注意,runs所在完整路径中不要有任何的中文
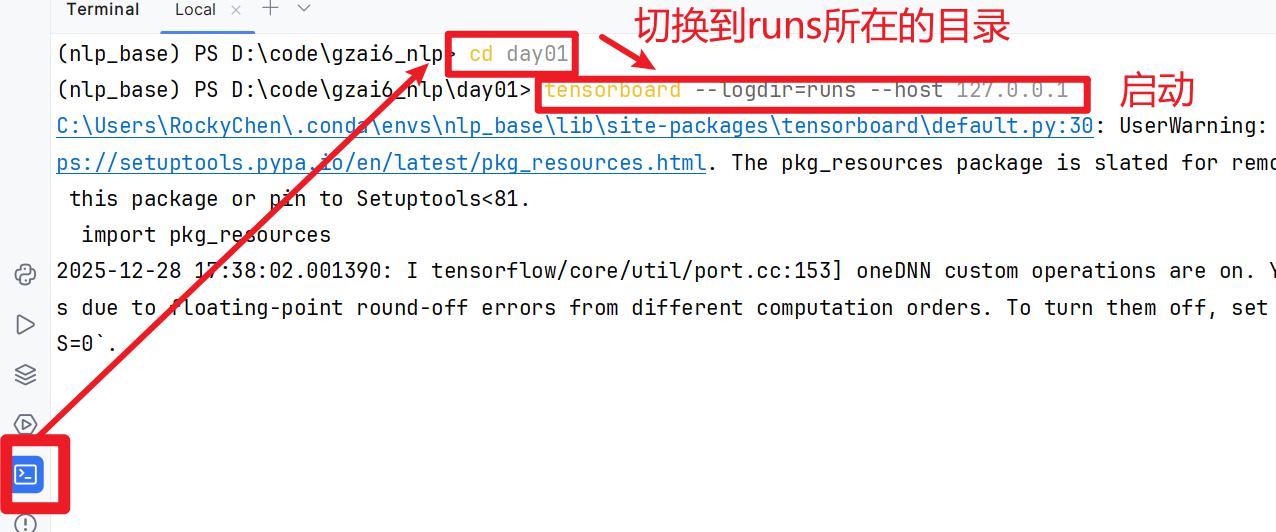
- 访问:使用Edge浏览器来访问。输入链接 http://127.0.0.1:6006
张量表示方法总结
| 方案 | 优点 | 缺点 | 适用场景 / 补充 |
|---|---|---|---|
| One-hot | 简单易懂 | 稀疏向量,耗费存储算力,几乎无语义信息 | 词语无关联,如人名预测国籍 |
| Word2Vec | 稠密向量,节省资源,携带上下文语义 | 静态固定向量,无法区分一词多义 | 基础通用词表征 |
| Word Embedding | 稠密动态向量,区分多义词,可直接输入神经网络隐藏层 | 逐句动态生成向量,训练耗时久 | 需区分多义词、对接深度学习网络 |
核心区分一句话: One-hot 无语义;Word2Vec 静态单一向量;Word Embedding 动态多义但训练费时。
文本数据分析【理解】
文本数据分析有哪些方法
1、标签数量分布
2、句子长度分布
3、词频统计
文本数据分析的作用
1、帮助我们理解语料
2、帮助我们检查语料, 快速分析语料中可能存在的问题.
例如:
数据质量类: 错别字, 语法错误, 重复内容, 缺失值...
数据均衡类: 标签分布不均, 句子长度不同...
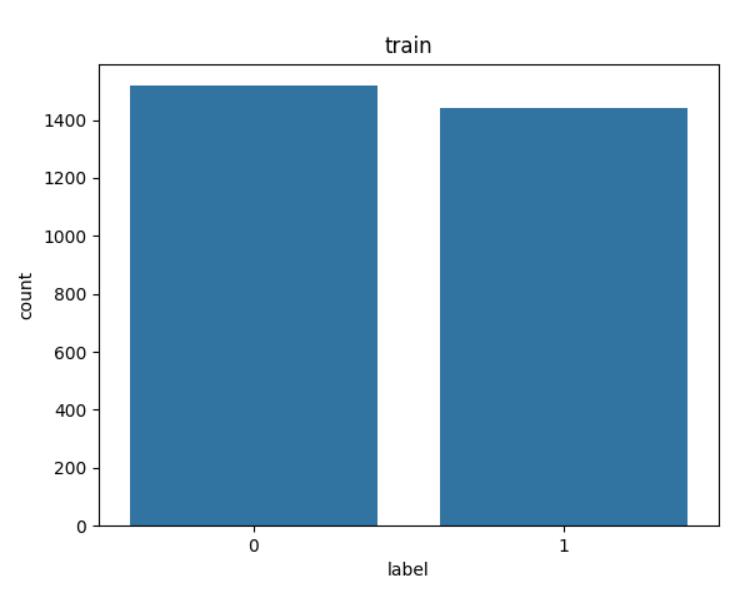
标签数量分布
目的: 查询【样本类别是否均衡】,如果样本过大,需要减少数据;如果样本过少,需要增加数据
- 代码实现
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
"""
如果出现AttributeError: 'FigureCanvasInterAgg' object has no attribute 'tostring_rgb'. Did you mean: 'tostring_argb'?
那么是matplotlib的版本过高导致的
pip uninstall -y matplotlib
pip install matplotlib==3.8.4 -i https://mirrors.aliyun.com/pypi/simple/
"""
if __name__ == '__main__':
# 1- 读取文件
"""
注意:需要指定具体的分隔符sep,否则会报错pandas.errors.ParserError: Error tokenizing data. C error: Expected 6 fields in line 12, saw 8
"""
train_df = pd.read_csv("data/train.tsv",encoding="UTF-8",sep="\t")
dev_df = pd.read_csv("data/dev.tsv",encoding="UTF-8",sep="\t")
# 2- 展示训练集
plt.style.use("fivethirtyeight")
sns.countplot(x="label",data=train_df)
plt.title("train")
plt.show()
# 3- 展示验证集
sns.countplot(x="label", data=dev_df)
plt.title("dev")
plt.show()
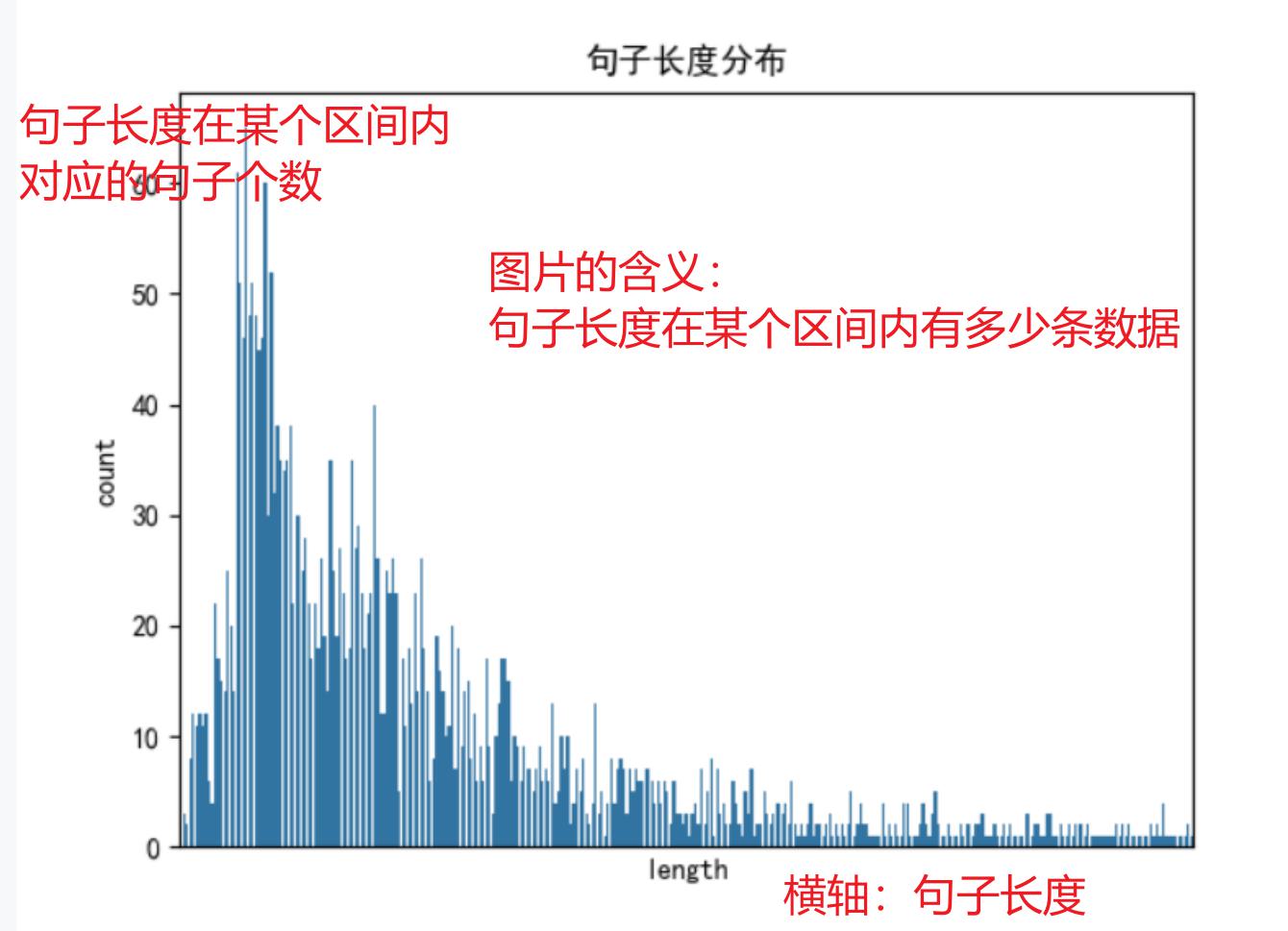
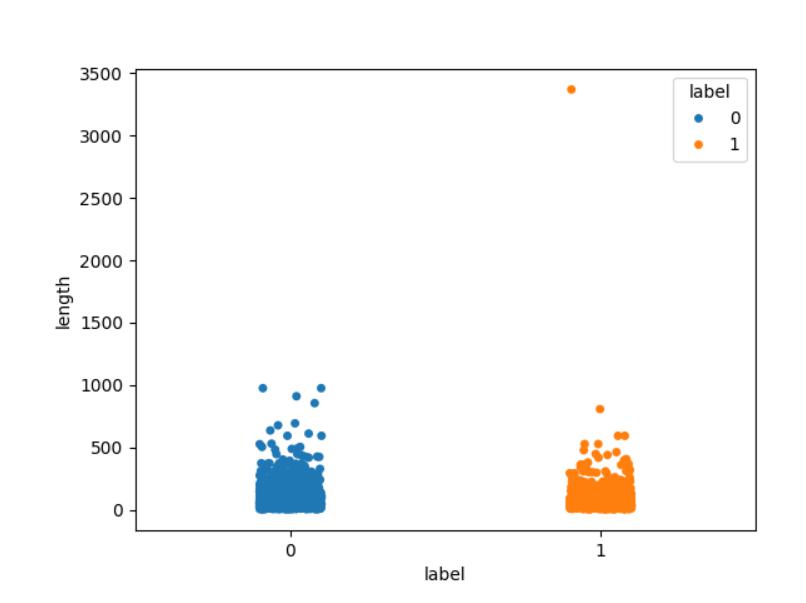
句子长度分布
目的: 模型一般规定需要输入固定的尺寸,也就是长度统一,通过分析句子长度,可以【明确大部分样本属于什么长度范围】,然后进行句子的长短【补齐或截断】
- 解释list( map(lambda x: len(x), sentence_series))
if __name__ == '__main__':
my_data = [11,22,33]
map_result = map(lambda num:num*10, my_data) # 这里实际是得到了一个生成器对象
# print(map_result) # 得到的是内存地址值
# 取值方式一【推荐】:转成List列表
# list_result = list(map_result)
# print(list_result)
print("-"*30)
# 取值方式二:for循环
# for i in map_result:
# print(i)
print("-" * 30)
# 取值方式三:next一个个取值
print(next(map_result))
print(next(map_result))
print(next(map_result))
- 代码实现
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
def demo01():
# 1- 读取文件
df = pd.read_csv("data/train.tsv",sep="\t",encoding="UTF-8")
# 2- 统计句子的长度
# 2.1- 取出句子列
sentence = df["sentence"]
# 2.2- 统计长度
# 方式一
df["length"] = sentence.apply(func=lambda line:len(line))
# 方式二
# df["length"] = list(map(lambda line:len(line), sentence))
# print(df.head())
# 3- 绘制图形
sns.countplot(x="length",data=df)
plt.xticks([]) # 横坐标不展示刻度尺
plt.show()
# 4- 柱状图的趋势线
# kde:为了让曲线更加光滑
sns.displot(x="length",data=df,kde=True)
plt.show()
def demo02():
# 1- 读取数据
df = pd.read_csv("data/train.tsv",sep="\t",encoding="UTF-8")
# 2- 统计句子长度
# 2.1- 取出句子的列
sentence = df["sentence"]
# 2.2- 统计长度
df["length"] = sentence.apply(lambda line:len(line))
# 3- 绘制散点图展示
# 参数解释:hue对散点的颜色以什么为标准进行渲染
sns.stripplot(x="label",y="length",data=df,hue="label")
plt.show()
if __name__ == '__main__':
# 1- 句子长度分布:获得句子长度规范应该设置为多少
# demo01()
# 2- 好评、差评的句子长度分布
demo02()
词频和高频词云
词频: 这里指的是统计样本中词汇的总数量(需要去重)
高频词云目的: 可以方便我们查看数据集中【是否存在脏数据】,进而实现人工的审核和清洗
- 解释chain(*map())
chain的作用可以简单理解为和List.extend等价,但是有区别:chain返回一个的是一个迭代器,因此对内存的使用极低,而且不修改原始列表
# 导包
from itertools import chain
import jieba
def dm01():
list1 = ['今天天很好', '今天天很热']
# 对每个字符串进行分词处理
tmp_result = map(lambda x: jieba.lcut(x), list1)
print(list(tmp_result))
print(*tmp_result)
# 把上述结果合并, 不会去重.
result = list(chain(*tmp_result))
print(f'result: {result}')
# 上述格式最终版写法, 即: 一行.
result = list(chain(*map(lambda x: jieba.lcut(x), list1)))
print(f'result: {result}')
if __name__ == '__main__':
dm01()
- 词频_代码实现
# 导包
import jieba
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt # 推荐安装 pip install matplotlib==3.9
from itertools import chain # 迭代器工具
# 解决Matplotlib绘图时 中文乱码问题.
plt.rcParams['font.sans-serif'] = ['SimHei'] # Mac本字体改为: ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 1. 词频统计.
def dm01_word_count():
# 1. 读取数据.
train_data = pd.read_csv('./data/train.tsv', sep='\t')
test_data = pd.read_csv('./data/dev.tsv', sep='\t')
# 2. 统计 训练集中 词汇总数.
train_vocab = set(chain(*map(lambda x: jieba.lcut(x), train_data['sentence'])))
# 3. 统计 测试集中 词汇总数.
test_vocab = set(chain(*map(lambda x: jieba.lcut(x), test_data['sentence'])))
# 4. 打印结果.
print(f'训练集的 词汇总数: {len(train_vocab)}')
print(f'测试集的 词汇总数: {len(test_vocab)}')
if __name__ == '__main__':
# 词频统计
dm01_word_count()
- 高频词云_代码实现
import pandas as pd
from itertools import chain
from wordcloud import WordCloud # 词云类
import jieba.posseg as pseg
import matplotlib.pyplot as plt
def get_a_word(line):
# 分词并且标注词性
word_dict = pseg.lcut(line)
# print(word_dict)
result_list = []
# 过滤形容词
for word,pos in word_dict:
if pos=="a":
result_list.append(word)
return result_list
def show_cloud(a_word_list):
# 1- 创建词云对象
wordcloud_obj = WordCloud(font_path="data/SimHei.ttf",max_words=100,background_color="white")
# 2- 词汇列表以空格分隔拼接成字符串
words_str = " ".join(a_word_list)
# 3- 绘制图形
wordcloud_obj.generate(words_str)
plt.figure()
# bilinear:让文字边缘更加平滑
plt.imshow(wordcloud_obj,interpolation="bilinear")
plt.axis("off")
plt.show()
def word_cloud():
# 1- 读取文件,并且取出评价内容
df = pd.read_csv("data/train.tsv",sep="\t",encoding="UTF-8")
sentence_series = df["sentence"]
# 2- 句子分词,过滤出形容词
# 注意:map返回的是生成器,你要真的调用它,才会触发数据的产生
a_word_list = list(chain(*map(get_a_word,sentence_series)))
# 3- 绘制词云
show_cloud(a_word_list)
if __name__ == '__main__':
word_cloud()
文本特征处理【理解】
【介绍一下n-gram】
将n个连续相邻的token组合到一起,n-gram特征
【为什么要规范文本长度】
模型的输入需要【每个batch】或者【整个数据集】,统一句子长度
对语料添加普适性的特征:n-gram
对语料进行规范长度:适配模型的输入
添加N-Gram特征
n-gram介绍:
概念: 将相邻的N个词合并到一起的过程
作用: 增加词的上下文语义信息
常见种类如下:
1-gram: 也称之为uni-gram,不对词进行合并
2-gram: 也称之为bi-gram,将相邻的2个词合并到一起
3-gram: 也称之为tri-gram,将相邻的3个词合并到一起
举例:
原始文本:我爱黑马程序员
分词结果:我、爱、黑马、程序员
1-gram:我、爱、黑马、程序员
2-gram:我爱、爱黑马、黑马程序员
3-gram:我爱黑马、爱黑马程序员
- zip函数解释
def zip_demo():
list_1 = ["a","c","b","d"]
list_2 = [11, 33, 22]
result = zip(list_2,list_1)
print(type(result))
print(result)
print(list(result))
if __name__ == '__main__':
# 1- zip函数解释
zip_demo()
- 代码实现
import jieba
# 下面代码讲的是N-gram的底层原理
def n_gram_demo(n):
# 1- 准备数据
content = "我爱黑马程序员"
# 2- 实现N-gram
"""
原始句子:我爱黑马程序员
分词结果:['我', '爱', '黑马', '程序员']
['我', '爱', '黑马', '程序员']
['爱', '黑马', '程序员']
n=2时候:['我爱', '爱黑马', '黑马程序员']
['我', '爱', '黑马', '程序员']
['爱', '黑马', '程序员']
['黑马', '程序员']
n=3时候:['我爱黑马', '爱黑马程序员']
"""
# 2.1- 分词
word_list = jieba.lcut(content)
# 2.2- 构建n个子列表
lists = [word_list[i:] for i in range(n)]
# print(lists)
# 2.3- 拉链拼接
result = list(zip(*lists))
print(result)
if __name__ == '__main__':
# n_gram_demo(n=1)
n_gram_demo(n=2)
# n_gram_demo(n=3)
文本长度规范
意义: 一般模型的输入需要等尺寸大小的矩阵, 所以需要对【超长文本做截断, 不足的做补齐】。这就是文本长度规范.
from keras.preprocessing import sequence
sequence.pad_sequences(sequences=sen_list, maxlen=10, padding="post", truncating="post", value=666)
- 代码实现
"""
为什么要进行句子长度的规范?
答:如果一个批次中的句子长度不等长,那么批次大小只能是1
DataLoader(batch_size),batch_size>1的前提是张量数据的形状完全一样
[seq_len, 128]
[3, 128] -> 填充 -> [4, 128]
[5, 128] -> 截断 -> [4, 128]
stack()
"""
# from tensorflow.keras.preprocessing import sequence
from keras.preprocessing import sequence
# 下面代码讲的是句子长度规范处理的底层实现过程。后续课程不会写这块代码,而是通过参数设置的方式实现
sen_list = [
[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1],
[2, 32, 1, 23, 1]
]
def demo01():
"""
参数解释:
sequences:需要处理的句子列表
maxlen:句子长度规范的上限
padding:如果句子的长度小于maxlen,就进行填充。具体参数值如下
pre:在句子的前面填充内容
post:在句子的后面填充内容
truncating:如果句子的长度大于maxlen,就进行截断。具体参数值如下
pre:在句子的前面截断内容
post:在句子的后面截断内容
value:填充句子的时候使用的数值。推荐使用0
"""
# result = sequence.pad_sequences(sequences=sen_list, maxlen=10)
result = sequence.pad_sequences(sequences=sen_list, maxlen=10, padding="post", truncating="post", value=666)
print(result)
def demo02():
# 1- 定义一个空列表用来存储规范化后的句子
result_list = []
maxlen = 10 # 句子的长度
# 2- 分别对每条句子进行处理
for sen in sen_list:
if len(sen)>maxlen:
# 超长的要截断
result_list.append(sen[:maxlen])
else:
# 短的要填充
result_list.append(sen + [0]*(maxlen-len(sen)))
print(result_list)
if __name__ == '__main__':
# demo01()
demo02()
文本数据增强【了解】
回译数据增强
定义:通过将一种语言翻译成不同的语言,再转换回来的一种方式
例如:中文---韩文----英语---中文
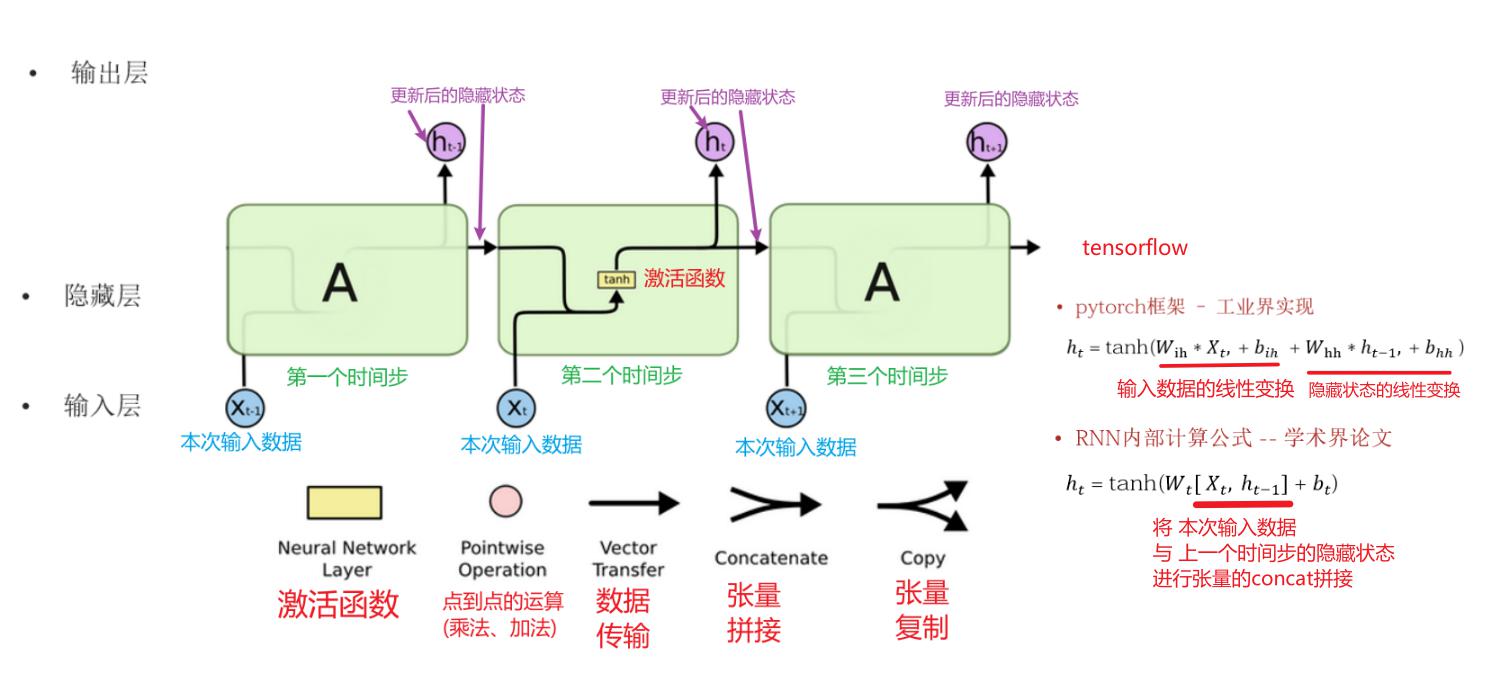
认识RNN模型
- 定义
循环神经网络:一般接受的一序列进行输入,输出也是一个序列
- 作用和应用场景
RNN擅长处理连续语言文本,机器翻译、文本生成、文本分类、摘要生成
RNN模型的分类
- 根据输入与输出结构
N Vs N : 输入和输出等长,应用场景:对联生成;词性标注;NER N Vs 1 : 输入N,输出为单值,应用场景:文本分类 1 Vs N : 输入是一个,输出为N,应用场景:图片文本生成 N Vs M : 输入和输出不等长,应用场景:文本翻译、摘要总结- 根据RNN内部结构
传统RNN LSTM BI-LSTM GRU BI-GRU
传统RNN模型【复习】
基本概念
RNN(Recurrent Neural Network)即循环神经网络,输入输出均为序列数据,可捕捉序列间关联特征。
参数解释:


内部结构
来源文章:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
- 输入:当前时间步xt和上一时间步输出的ht-1
- 输出:ht和ot (一个时间步内:ht=ot)
多层RNN的解析
output记录的是 最后一层 在每个时间步的隐藏状态。(h21+h22) hidden 记录的是 每一层 在最后一个时间步的隐藏状态。(h12+h22)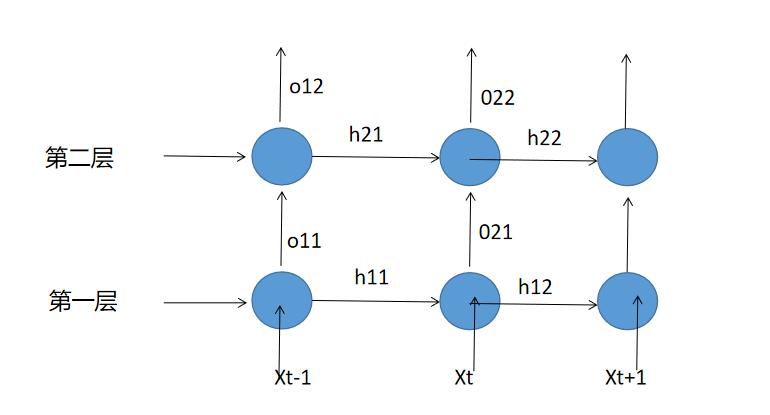
代码实现
import torch
import torch.nn as nn
def rnn_demo(num_layers):
# 1- 搭建RNN循环网络层
"""
参数解释:
input_size:输入数据的向量维度
hidden_size:隐藏状态的向量维度
num_layers:隐藏层的层数
bidirectional:是否是双向的神经网络。True:表示双向;False:表示单向
batch_first:是否将张量中的batch_size形状放在最前面。
注意:只会影响input本次输入数据、output本次输出数据;不会影响隐藏状态
"""
rnn = nn.RNN(input_size=4,hidden_size=5,num_layers=num_layers,batch_first=False,bidirectional=False)
# 2- 准备数据
batch_size = 2
# 2.1- 本次输入数据
input = torch.randn(size=(3, batch_size, 4))
# 2.2- 上一个时间步的隐藏状态:一般使用全0初始化
h0 = torch.zeros(size=(num_layers, batch_size, 5))
# 3- 调用RNN
"""
输入参数的张量形状
input本次输入数据:[seq_len每条句子中词的个数, batch_size每个批次中句子的条数, input_size输入数据的向量维度]
h0上一个时间步的隐藏状态:[num_layers隐藏层的层数, batch_size每个批次中句子的条数, hidden_size隐藏状态的向量维度]
返回数据的张量形状
output本次输出数据:[seq_len每条句子中词的个数, batch_size每个批次中句子的条数, hidden_size隐藏状态的向量维度]
hidden更新后的隐藏状态:[num_layers隐藏层的层数, batch_size每个批次中句子的条数, hidden_size隐藏状态的向量维度]
"""
output,hidden = rnn(input,h0)
# 4- 输出信息
print(f"本次输出数据:\n{output}")
print(f"本次更新后的隐藏状态数据:\n{hidden}")
print(f"本次输出数据的形状:{output.shape}") # [3,2,5]
print(f"本次更新后的隐藏状态数据的形状:{hidden.shape}") # [num_layers,2,5]
if __name__ == '__main__':
# rnn_demo(1)
rnn_demo(2)
总结
张量形状速记:
1. 入参维度
input:[seq_len, batch, input_size]
h0:[num_layers, batch, hidden_size]
2. 返回维度
output:[seq_len, batch, hidden_size]
hidden:[num_layers, batch, hidden_size]
极简记忆
首位:隐藏状态对应隐藏层层数,输入输出对应词个数(序列长度)
中间都是批次(句子条数);末尾都是隐藏状态(hidden_size),除了输入是input_size
传统RNN的优缺点:
优点:
内部结构简单, 资源消耗相对较小.
缺点:
处理长序列(一句话中词的个数很多)数据时, 因为 反向传播 结合 梯度连乘, 过大或者过小的梯度值都会导致 梯度爆炸或者梯度消失.
梯度爆炸:梯度值越来越大,导致权重值越来越大偏离最优的结果
梯度消失:梯度值越来越小,导致权重值更新非常缓慢甚至不更新
梯度震荡:学习率设置的不合理,导致权重值在最优点附近来回横跳
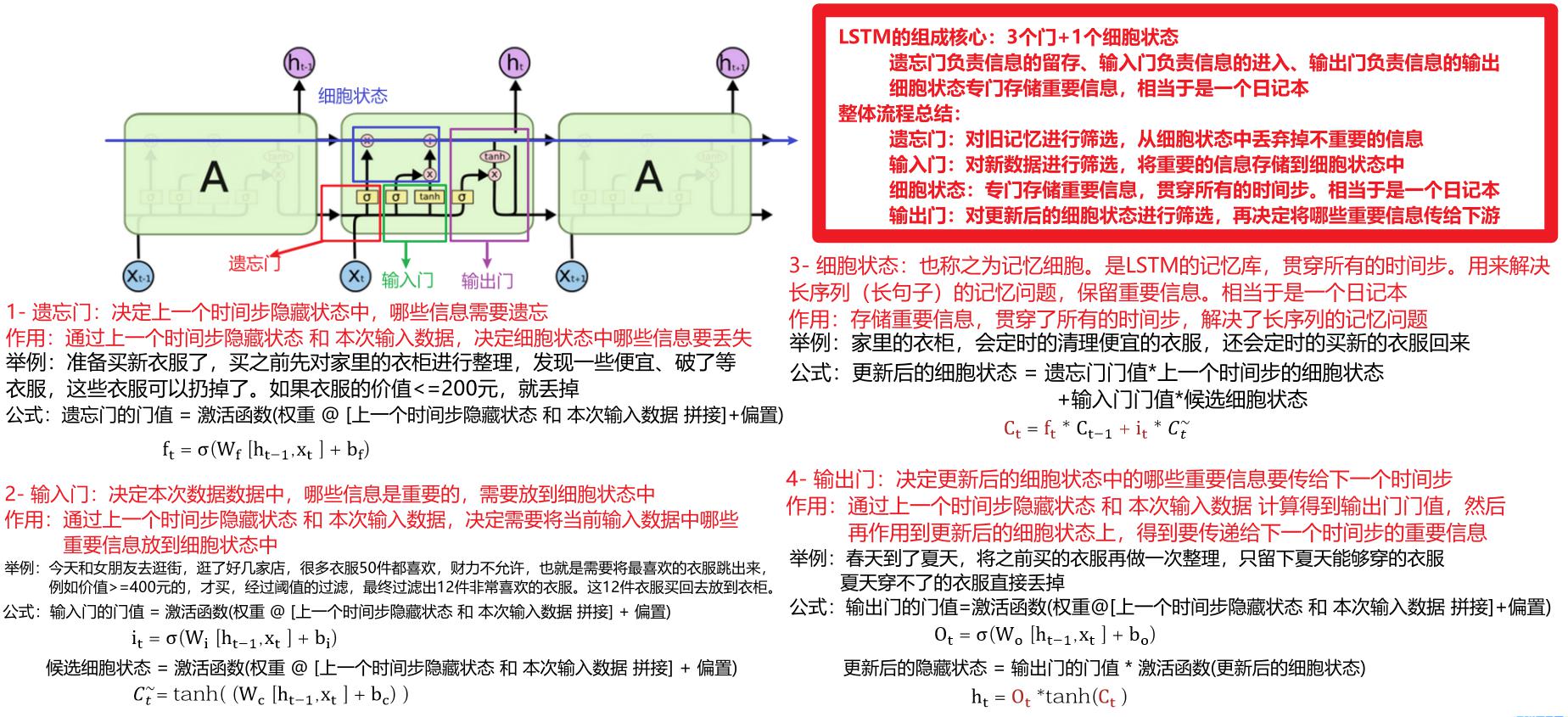
LSTM模型
基本概念
LSTM(Long Short-Term Memory)
定位:RNN 变体,缓解 RNN 长序列梯度消失 / 爆炸、长文本效果差问题,能捕获长距离语义,结构更复杂
四大核心组件:遗忘门、输入门、细胞状态、输出门
内部结构【理解】
- 细胞状态:是 LSTM 的记忆库,贯穿整个序列,用来解决长序列记忆问题
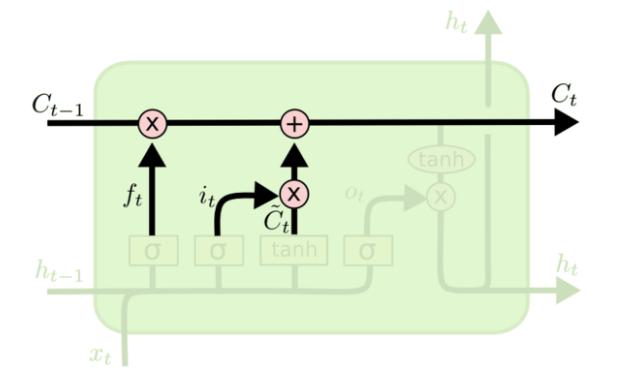
- 遗忘门:决定上一个时间步输出的细胞状态中,哪些内容需要丢弃掉
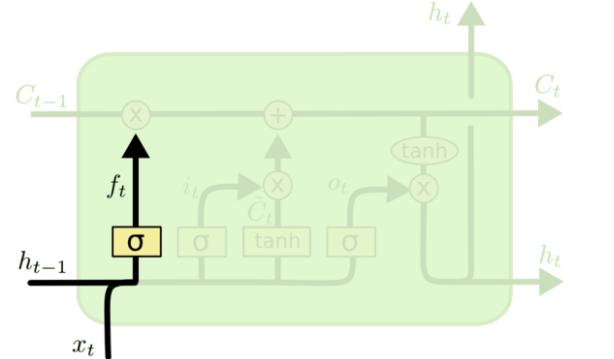
- 输入门:决定当前输入的数据中,哪些要记录到细胞状态中
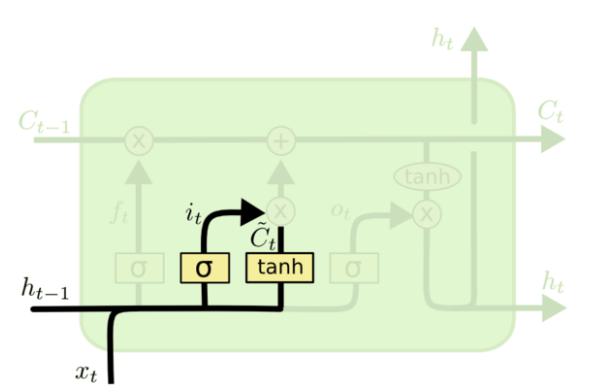
- 输出门:决定本次隐藏状态要输出哪些信息
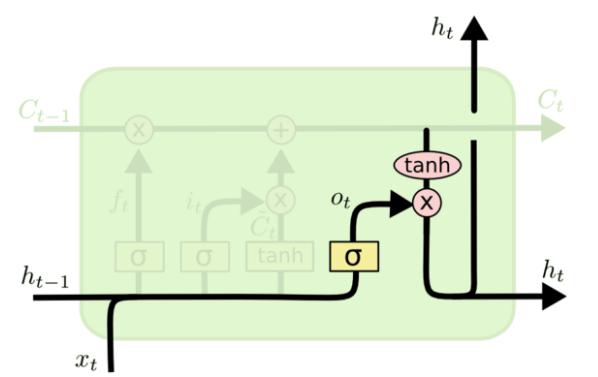
- 完整结构图解释
代码实现【掌握】
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1- 搭建神经网络结构
lstm = nn.LSTM(input_size=4,hidden_size=5,num_layers=1,batch_first=False,bidirectional=False)
# 2- 准备数据
batch_size = 2
# 2.1- 本次输入数据
input = torch.randn(size=(3,batch_size,4))
# 2.2- 初始化隐藏状态
h0 = torch.zeros(size=(1,batch_size,5))
# 2.3- 初始化细胞状态
c0 = torch.zeros(size=(1,batch_size,5))
# 3- 调用LSTM
"""
1- 细胞状态 与 隐藏状态 的张量形状是一样的。而且细胞状态一般使用全0初始化
2- 注意事项:细胞状态 与 隐藏状态 传递参数的时候,以及获得返回结果的时候,都必须使用小括号包起来
"""
output,(hidden,c1) = lstm(input,(h0,c0))
# 4- 输出
print(f"本次输出数据:\n{output}")
print(f"本次更新后的隐藏状态数据:\n{hidden}")
print(f"本次更新后的细胞状态数据:\n{c1}")
print(f"本次输出数据的形状:{output.shape}")
print(f"本次更新后的隐藏状态数据的形状:{hidden.shape}")
print(f"本次更新后的细胞状态数据的形状:{c1.shape}") # [1,2,5]
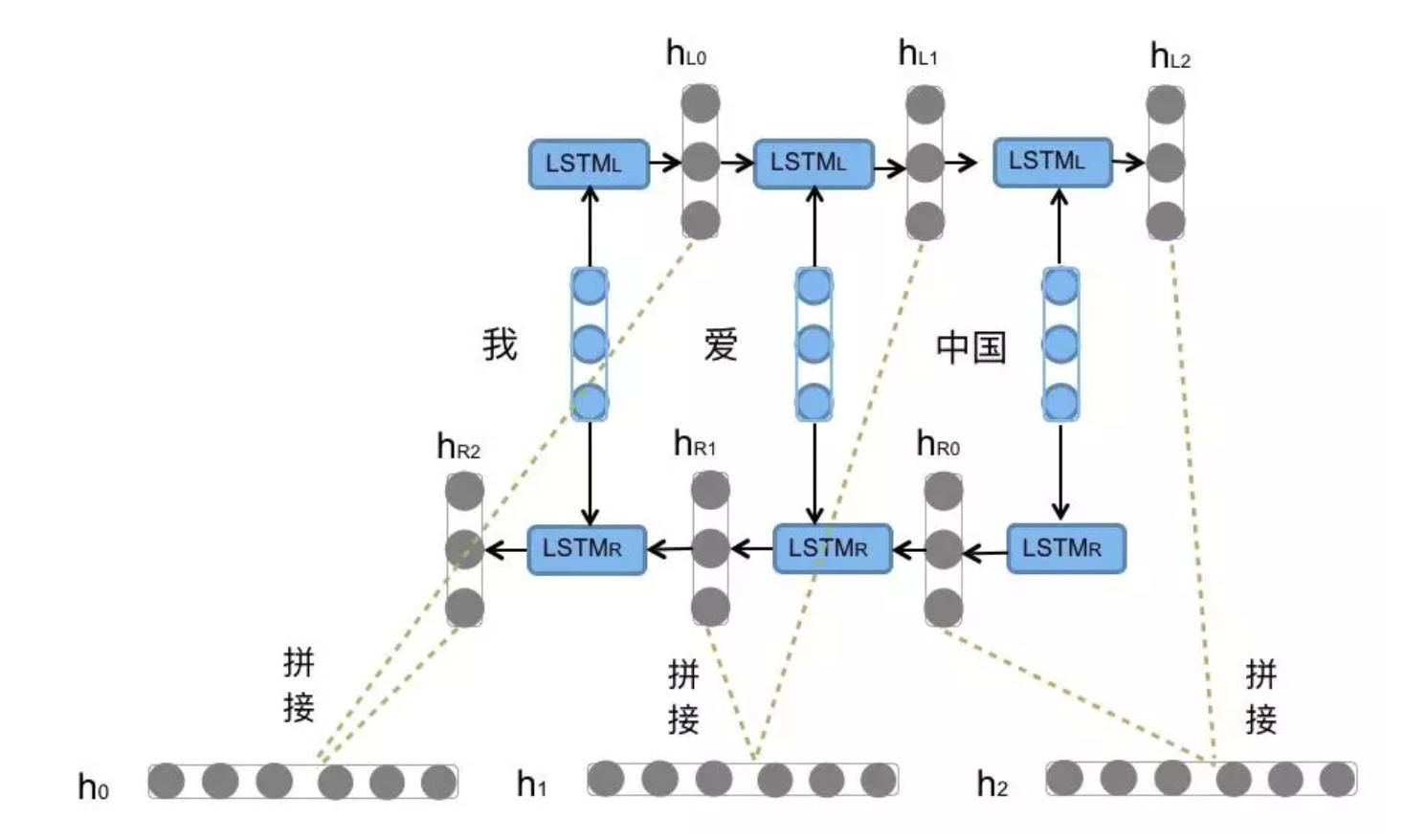
Bi-LSTM
定义: 不改变原始的LSTM模型内部结构,只是将文本从左到右计算一遍,再从右到左计算一遍,把最终的输出结果拼接得到模型的完整输出
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1- 创建LSTM
"""
参数解释:
bidirectional:LSTM循环网络层是否是双向的。如果为True,那就是Bi-LSTM
如果是双向的LSTM,那么隐藏状态 和 细胞状态 张量中第一个形状=num_layers*2
"""
lstm = nn.LSTM(input_size=4,hidden_size=5,num_layers=2,batch_first=False,bidirectional=True)
# 2- 准备数据
# 2.1- 本次输入数据
input = torch.randn(size=(3,2,4))
# 2.2- 上一个时间步的隐藏状态。初始隐藏状态一般全0初始化
h0 = torch.zeros(size=(4,2,5))
# 2.3- 上一个时间步的细胞状态。初始细胞状态一般全0初始化,它的形状与隐藏状态的形状完全一样
c0 = torch.zeros(size=(4, 2, 5))
# 3- 调用LSTM
"""
注意:隐藏状态 与 细胞状态 顺序,不能调整;并且这两个值要用小括号包起来
输入参数:本次输入数据, (上一个时间步的隐藏状态, 上一个时间步的细胞状态)
返回结果:本次预测结果, (更新后的本次时间步隐藏状态, 更新后的细胞状态)
"""
output,(hidden,c) = lstm(input,(h0,c0))
print(f"output的形状-->{output.shape}") # [3,2,5]
print(f"hidden的形状-->{hidden.shape}") # [4,2,5]
print(f"细胞状态的形状-->{c.shape}") # [4,2,5]
print(f"output的内容-->\n{output}")
print(f"hidden的内容-->{hidden}")
print(f"细胞状态的内容-->{c}")
总结
LSTM的优缺点是什么?
优点:
1- 能够处理更长的序列
2- 能够缓解梯度消失或梯度爆炸,因为反向传播过程的公式是加法运算而不是累乘
3- 能够处理更加复杂的特征
缺点:
神经元内部结构非常复杂,也就是会引起运行效率低,调参数复杂
单层 / 多层、单向 / 双向 LSTM 合并速记
1.构造参数:nn.LSTM(input_size, hidden_size, num_layers, batch_first, bidirectional)
bidirectional-是否双向
2.输入 shape(batch_first=False):(seq_len, batch, input_size)
3.隐 / 细胞状态维度统一公式:
单向:num_layers
双向:num_layers × 2
完整 shape:(层数系数, batch, hidden_size),h、c 尺寸永远相同,默认全 0 初始化
4.调用格式固定:
入参:input, (h0, c0)
返回:output, (hidden, c)
h、c 顺序不能换,必须括号封装
例如:output,(hidden,c) = lstm(input,(h0,c0))
5.输出含义:
output:全部时间步结果
hidden、c:序列最后时刻状态
GRU模型
基本概念
GRU(Gated Recurrent Unit)
定位:RNN 变体,同 LSTM 解决长序列梯度消失 / 爆炸,捕获长距离语义
对比:结构、计算比 LSTM 更简易
两大核心门:更新门、重置门
内部结构【理解】

代码实现【掌握】
import torch
import torch.nn as nn
def gru_demo(num_layers):
# 1- 搭建GRU循环网络层
"""
参数解释:
input_size:输入数据的向量维度
hidden_size:隐藏状态的向量维度
num_layers:隐藏层的层数
bidirectional:是否是双向的神经网络。True:表示双向;False:表示单向
batch_first:是否将张量中的batch_size形状放在最前面。
注意:只会影响input本次输入数据、output本次输出数据;不会影响隐藏状态
"""
gru = nn.GRU(input_size=4,hidden_size=5,num_layers=num_layers,batch_first=False,bidirectional=False)
# 2- 准备数据
batch_size = 2
# 2.1- 本次输入数据
input = torch.randn(size=(3, batch_size, 4))
# 2.2- 上一个时间步的隐藏状态:一般使用全0初始化
h0 = torch.zeros(size=(num_layers, batch_size, 5))
# 3- 调用GRU
"""
输入参数的张量形状
input本次输入数据:[seq_len每条句子中词的个数, batch_size每个批次中句子的条数, input_size输入数据的向量维度]
h0上一个时间步的隐藏状态:[num_layers隐藏层的层数, batch_size每个批次中句子的条数, hidden_size隐藏状态的向量维度]
返回数据的张量形状
output本次输出数据:[seq_len每条句子中词的个数, batch_size每个批次中句子的条数, hidden_size隐藏状态的向量维度]
hidden更新后的隐藏状态:[num_layers隐藏层的层数, batch_size每个批次中句子的条数, hidden_size隐藏状态的向量维度]
"""
output,hidden = gru(input,h0)
# 4- 输出信息
print(f"本次输出数据:\n{output}")
print(f"本次更新后的隐藏状态数据:\n{hidden}")
print(f"本次输出数据的形状:{output.shape}") # [3,2,5]
print(f"本次更新后的隐藏状态数据的形状:{hidden.shape}") # [num_layers,2,5]
if __name__ == '__main__':
# gru_demo(1)
gru_demo(2)
Bi-GRU
定义: 不改变原始的GRU模型内部结构,只是将文本从左到右计算一遍,再从右到左计算一遍,把最终的输出结果拼接得到模型的完整输出
import torch
import torch.nn as nn
def gru_demo(num_layers):
# 1- 搭建GRU循环网络层
"""
参数解释:
bidirectional:是否是双向的神经网络。True:表示双向;False:表示单向
注意:如果该值设置为True,需要注意隐藏状态的向量维度中num_layers需要乘以2
"""
gru = nn.GRU(input_size=4,hidden_size=5,num_layers=num_layers,batch_first=False,bidirectional=True)
# 2- 准备数据
batch_size = 2
# 2.1- 本次输入数据
input = torch.randn(size=(3, batch_size, 4))
# 2.2- 上一个时间步的隐藏状态:一般使用全0初始化
h0 = torch.zeros(size=(num_layers*2, batch_size, 5))
# 3- 调用GRU
output,hidden = gru(input,h0)
# 4- 输出信息
print(f"本次输出数据:\n{output}")
print(f"本次更新后的隐藏状态数据:\n{hidden}")
print(f"本次输出数据的形状:{output.shape}") # [3,2,5]
print(f"本次更新后的隐藏状态数据的形状:{hidden.shape}") # [num_layers*2,2,5]
if __name__ == '__main__':
# gru_demo(1)
# gru_demo(2)
gru_demo(3)
总结
GRU的优缺点是什么?
优点:相比LSTM,结构较为简单,能够和lstm一样缓解梯度消失问题
缺点:只能缓解了梯度消失和爆炸问题, 不能并行计算
RNN、LSTM、GRU的使用总结:
1- 如果项目、需求比较简单,或者序列的长度比较短(<50)的时候,可以使用RNN
2- 如果序列的长度在50-200之间的时候,可以使用GRU
3- 如果序列的长度在200以上的时候,可以使用LSTM
4- 如果计算资源充足,推荐使用LSTM、GRU。甚至可以考虑用Bi-LSTM、Bi-GRU
让代码运行在GPU上
Windows、Linux、Mac(M芯片)均可
Windows(无独显)、Mac(Intel芯片)不行
- 步骤
1: 【推荐】创建新的虚拟环境进行操作
conda create -n nlp_cuda python==3.10
2: 进入虚拟环境
conda activate nlp_cuda
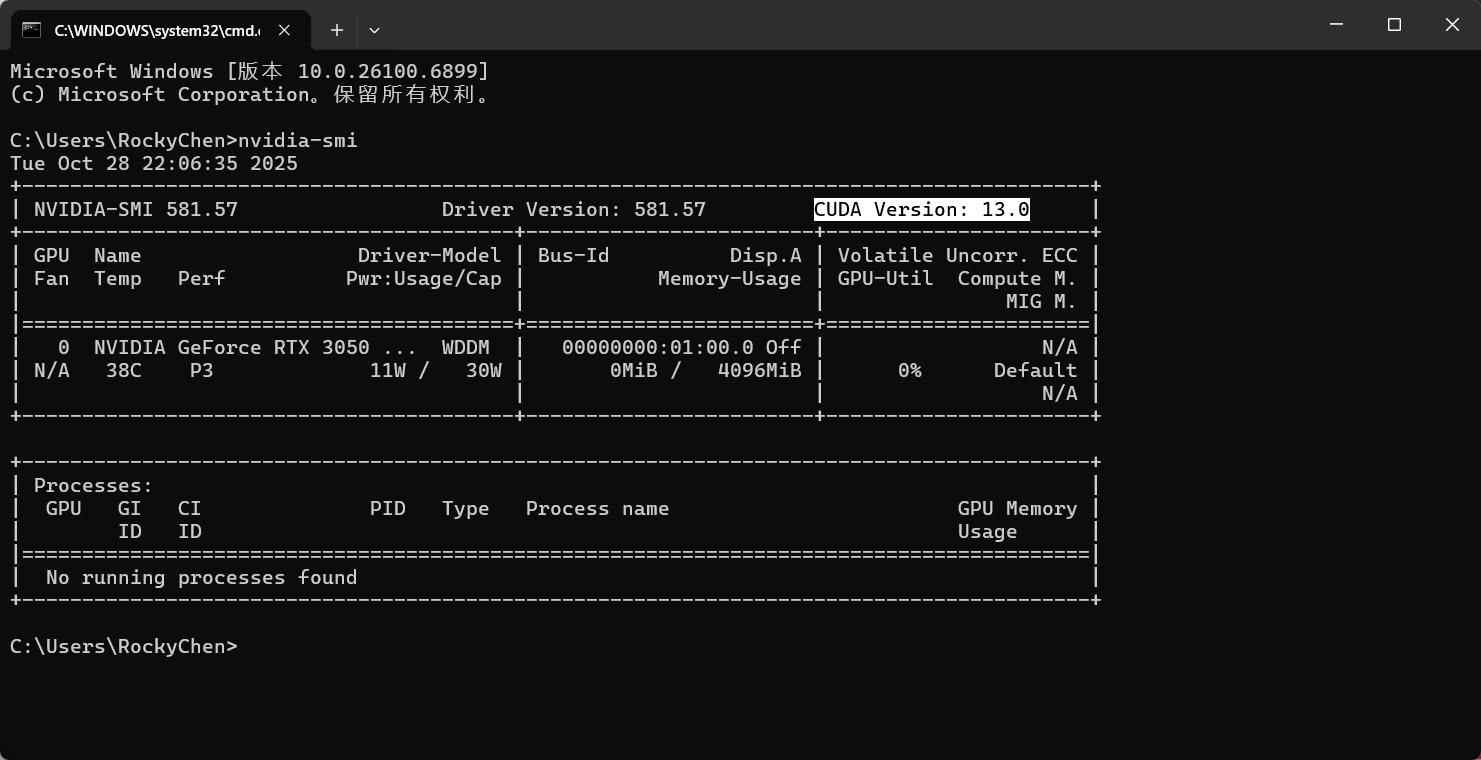
3: 去黑窗口查看你本机的CUDA版本。【推荐】先升级英伟达。【操作截图见下面】
nvidia-smi
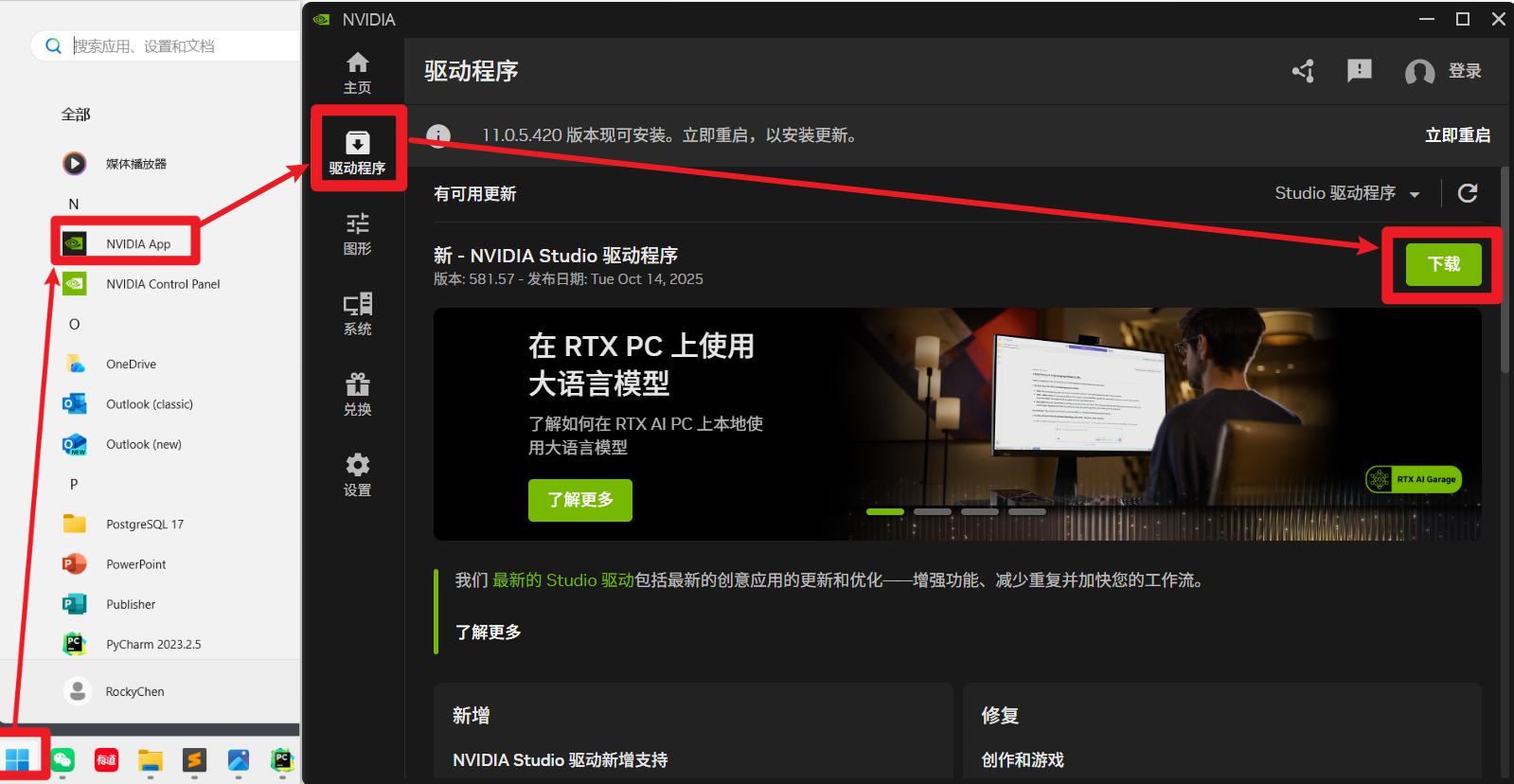
4: 去Pytorch官网找到对应你cuda版本的下载命令,【截图见下面】
官网地址: https://pytorch.org
5: 安装对应版本的cuda。安装命令
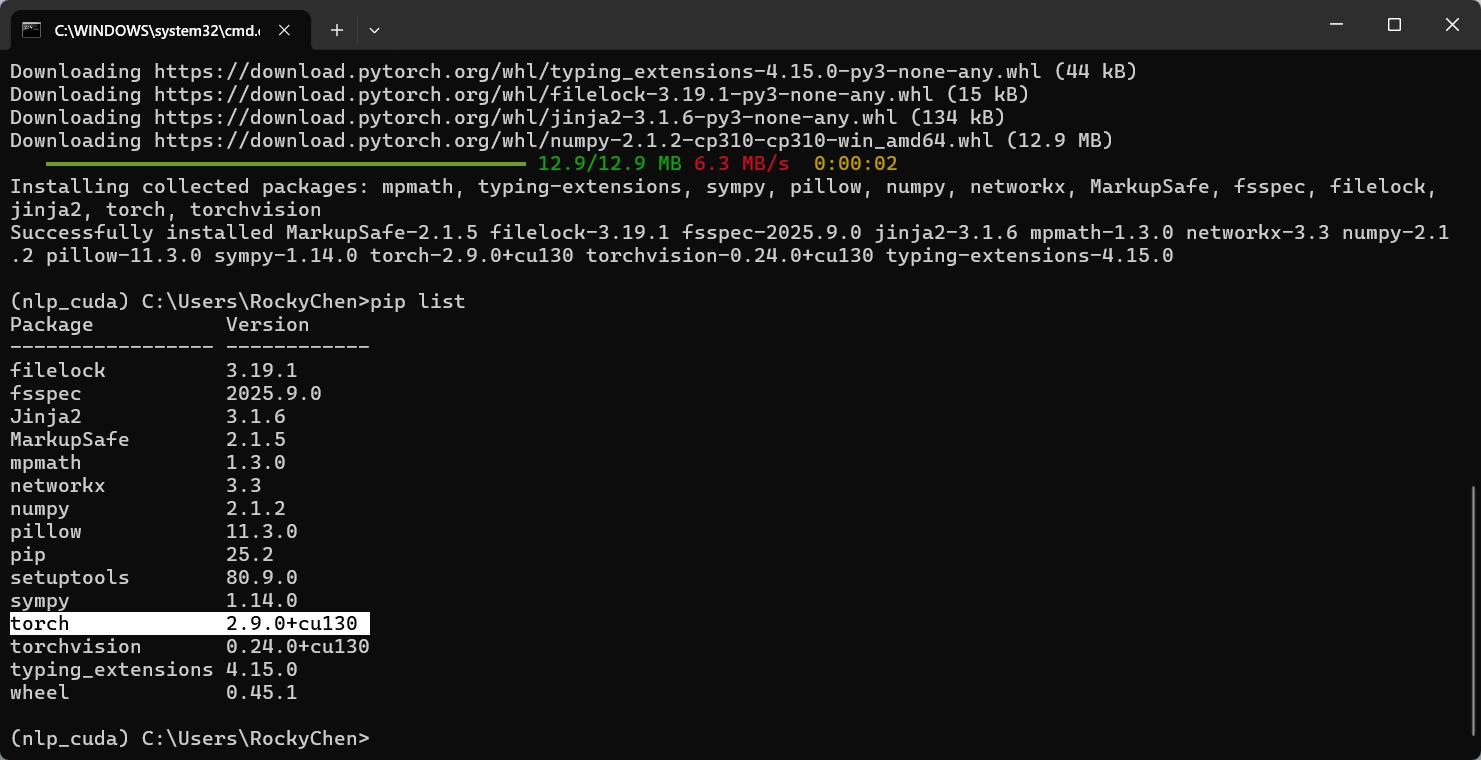
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cu130
6: 在PyCharm中关联新的沙箱, 运行下边的代码测试即可.
7: 如果不OK,大概率是 显卡驱动(Cuda版本) 和 你的PyTorch版本不兼容, 建议: 直接更新驱动.
8: 要安装的其他包,一个一个安装即可
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install tensorflow -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install joblib -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install fasttext-wheel -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install matplotlib==3.8.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple/

- 代码
import torch
# 设备选择,我们可以选择在cuda或者cpu上运行你的代码
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 如果是Mac M芯片, 写这个
# device = 'mps'
print(f'device: {device}')
fasttext
基本概念
fasttext优势:
- 十分简单的网络结构.
- 使用fasttext模型训练词向量时使用层次softmax结构, 来提升超多类别下的模型性能.
- 由于fasttext模型过于简单无法捕捉词序特征, 因此会进行n-gram特征提取以弥补模型缺陷提升精度.
霍夫曼树:高频近,低频远(按词频建最优树);
层次softmax:把多分类变成多次二分类
两者关系:霍夫曼树是层次Softmax的“最佳路网”。
安装命令
pip install fasttext -i https://mirrors.aliyun.com/pypi/simple/
或者
pip install fasttext-wheel -i https://mirrors.aliyun.com/pypi/simple/
负采样 = 正样本 + 少量随机负样本。
它用概率近似代替精确计算,牺牲了一点点精度,换来了巨大的训练速度提升,是处理海量数据时的“性价比之王”。
示例:Word2Vec 训练
假设要学“国王”和“王后”是相似的词:
正样本:(国王, 王后) -> 标签 1
负样本:随机抽 (国王, 苹果)、(国王, 汽车) -> 标签 0
操作:模型只需要计算这3个组合的误差,而不是去算“国王”和字典里几万个词的组合。
负采样的优势:
- 提高训练速度, 选择了部分数据进行计算损失, 损失计算更加简单.
- 改进效果, 增加部分负样本, 能够模拟真实场景下的噪声情况, 能够让模型的稳健性更强.
补充的知识:
训练集->模型开发
测试集->评估模型的效果
验证集->项目经理
运行fasttext代码报如下错:

解决:
1- 卸载虚拟环境中的numpy
pip uninstall -y numpy
2- 重新安装1.x版本的numpy
pip install numpy==1.26.4
fasttext文本分类
import fasttext
def demo01():
# 1- 模型训练
model = fasttext.train_supervised("data/cooking_train.txt")
# 2- 预测
# predict_result = model.predict("How much does potato starch affect a cheese sauce recipe?")
predict_result = model.predict("How much does potato starch affect a cheese sauce recipe?",k=3)
print(f"预测结果:{predict_result}")
# 3- 评估
val_result = model.test("data/cooking_valid.txt")
# 返回结果(3000, 0.14166666666666666, 0.06126567680553553),解释 验证集样本条数 精确率 召回率
print(f"评估结果:{val_result}")
def demo02():
# 1- 模型训练
model = fasttext.train_supervised("data/cooking.preprocessed.txt")
# 2- 预测
predict_result = model.predict("how much does potato starch affect a cheese sauce recipe ?",k=3)
print(f"预测结果:{predict_result}")
# 3- 评估
val_result = model.test("data/cooking_valid.txt")
print(f"评估结果:{val_result}")
def demo03():
# 1- 模型训练
model = fasttext.train_supervised(input="data/cooking.preprocessed.txt",epoch=50)
# 2- 预测
predict_result = model.predict("how much does potato starch affect a cheese sauce recipe ?",k=3)
print(f"预测结果:{predict_result}")
# 3- 评估
val_result = model.test("data/cooking_valid.txt")
print(f"评估结果:{val_result}")
def demo04():
# 1- 模型训练
"""
参数解释:
wordNgrams:n-gram中n的值。也就是将相邻的多少个词合并起来
loss:输出层中的激活函数。推荐使用hs,层次softmax,能够大大提升训练速度
"""
model = fasttext.train_supervised(
input="data/cooking.preprocessed.txt",
epoch=200,
dim=200,
lr=0.1,
wordNgrams=2,
loss="hs",
thread=8
)
# 2- 预测
predict_result = model.predict("how much does potato starch affect a cheese sauce recipe ?",k=3)
print(f"预测结果:{predict_result}")
# 3- 评估
val_result = model.test("data/cooking_valid.txt")
print(f"评估结果:{val_result}")
def demo05():
# 1- 模型训练
"""
参数解释:
autotuneValidationFile:验证集文件
autotuneDuration:自动寻找最优超参数的时长。单位是秒
verbose:查看内部的超参数组合情况。
2:默认值,看不到太详细的信息
3:能够看到内部的运行细节
"""
model = fasttext.train_supervised(
input="data/cooking.preprocessed.txt",
autotuneValidationFile="data/cooking_valid.txt",
autotuneDuration=3*60,
thread=8,
verbose=3
)
# 2- 预测
predict_result = model.predict("how much does potato starch affect a cheese sauce recipe ?",k=3)
print(f"预测结果:{predict_result}")
# 3- 评估
val_result = model.test("data/cooking_valid.txt")
print(f"评估结果:{val_result}")
def demo06():
# 1- 模型训练
"""
参数解释:
loss="ova":将多标签多分类 问题 转成 单标签多分类问题。ova one vs all
"""
model = fasttext.train_supervised(
input="data/cooking.preprocessed.txt",
loss="ova",
epoch = 50,
dim = 200,
lr = 0.1,
wordNgrams = 2,
thread = 8
)
# 2- 预测
predict_result = model.predict("how much does potato starch affect a cheese sauce recipe ?",k=3)
print(f"预测结果:{predict_result}")
# 3- 评估
val_result = model.test("data/cooking_valid.txt")
print(f"评估结果:{val_result}")
if __name__ == '__main__':
# 1- 原始数据文件
# demo01() # (3000, 0.139, 0.06011244053625486)
# 2- 数据经过预处理
# demo02() # (3000, 0.18433333333333332, 0.07970596713750361)
# 3- 增加训练轮次
# demo03() # (3000, 0.631, 0.272845200345921)
# 4- 手动设置其他超参数
# demo04() # (3000, 0.7893333333333333, 0.3413087345056212)
# 5- 自动寻找最优超参数
# demo05() # (3000, 0.546, 0.23609109253387142)
# 6- 将多标签简化成单标签多分类
demo06() # (3000, 0.7643333333333333, 0.33049870279619487)
训练词向量
参考NLP课程第一天,使用fasttext实现word2vec代码
核心api总结
FastText 核心 API 极简总结
1. 训练
model = fasttext.train_supervised(input="文件路径", 超参...)
核心入参:
input:训练文本路径
epoch:迭代轮数
dim:词向量维度
lr:学习率
wordNgrams:n-gram的最大长度
loss:hs-(层次softmax)加速训练 / ova-多标签转单分类 / softmax
thread:线程数
autotuneValidationFile:开启自动调参,指定验证集
autotuneDuration:自动调参时长 (秒)
verbose:日志详细等级
2. 预测
model.predict(文本, k=3)
k:返回 Top-k 预测标签
3. 模型评估
model.test(验证集路径)
返回元组:(样本总数,精确率,召回率)
迁移学习的概念
魔搭社区:https://www.modelscope.cn/models?page=1&tabKey=task
迁移学习 = 把从任务A学到的“知识”,拿来帮助解决任务B。
学自行车 → 学摩托车
你会骑自行车(任务A),掌握了“平衡感”。学摩托车(任务B)时,不用从零开始学平衡,直接复用这个能力,只需重点学“拧油门”和“脚刹”即可。这就是迁移学习。
- 预训练模型:别人在大数据集上(比如ImageNet)训练好的现成模型,它已经学会了通用的“识图”能力(比如边缘、纹理、形状)。
- 微调:把这个现成模型拿过来,在你自己小数据集上再稍微训练一下,让它适应你的特定任务(比如区分猫和狗)。
预训练模型
定义: 简单来说别人训练好的模型。一般预训练模型具备复杂的网络模型结构;一般是在大量的语料下训练完成的
预训练语言模型的类别
现在我们接触到的预训练语言模型,基本上都是基于transformer这个模型迭代而来的
因此划分模型类别的时候,以transformer架构来划分:
Encoder-Only: 只有编码器部分的模型,代表:BERT
Decoder-Only: 只要解码器部分的模型,代表:GPT
Encoder-Decoder: 本质就transformer架构,代表:T5
微调
定义:一般是对预训练语言模型,进行垂直领域数据的微调,可以将预训练模型的参数全部微调或者部分微调或者不微调,但是一般我们在做任务的时候,会在预训练模型后加入自定义网络,自定义网络模型的参数需要训练
迁移学习的两种方式
开箱即用: 当预训练模型的任务和我们要做的任务相似时,可以直接使用预训练模型来解决对应的任务
微调: 进行垂直领域数据的微调,一般在预训练网络模型后,加入自定义网络,自定义网络模型的参数需要训练,但是预训练模型的参数可以全部微调或者部分微调或者不微调。
NLP常用预训练模型
当下NLP流行的预训练模型
1. BERT
核心:仅编码器、双向上下文、掩码 MLM 预训练,擅长理解类任务(分类、问答、实体识别)
示例:文本情感分类、抽取文章关键词
2. GPT / GPT-2
核心:仅解码器、单向从左到右、自回归生成,主打文本续写生成
示例:写文案、续写故事;GPT2 是轻量化初代生成模型
3. Transformer-XL / XLNet
核心:解决长文本上下文断裂,XLNet 去掉 BERT 掩码、用排列语言建模,长文本理解更强
示例:超长小说、长文档阅读理解
4. XLM / XLM-RoBERTa
核心:多语言模型,跨语言迁移;XLM-R 效果更强,支持百种语言
示例:中英互译、多语言情感分析
5. RoBERTa
核心:BERT 优化版,去掉 NSP 任务、更大批量训练,效果优于原生 BERT
示例:替换 BERT 做文本分类,精度更高
6. DistilBERT / ALBERT
核心:BERT 轻量化变体,参数量更小、推理更快
DistilBERT:蒸馏压缩模型
ALBERT:共享层参数减少权重
示例:部署到手机 / 轻量服务器做线上文本识别
7. T5
核心:编码器 + 解码器完整架构,统一所有 NLP 任务为 “文本生成”
示例:翻译、摘要、问答、文本改写统一用一套模型
BERT及其变体
- Base 系列(共5个):12层 / 768维 / 12头 / 1.1亿参数
- Large 系列(共2个):24层 / 1024维 / 16头 / 3.4亿参数
- 命名中含 uncased → 小写;含 cased → 保留大小写
- 含 multilingual → 102种语言;含 chinese → 中文;两者皆无 → 仅英文
| 完整模型名称 | 隐层数 | 输出维度 | 自注意力头数 | 参数量 | 训练数据 |
|---|---|---|---|---|---|
| bert-base-uncased | 12 | 768 | 12 | 110M | 小写英文 |
| bert-large-uncased | 24 | 1024 | 16 | 340M | 小写英文 |
| bert-base-cased | 12 | 768 | 12 | 110M | 英文(保留大小写) |
| bert-large-cased | 24 | 1024 | 16 | 340M | 英文(保留大小写) |
| bert-base-multilingual-uncased | 12 | 768 | 12 | 110M | 小写102种语言 |
| bert-large-multilingual-uncased | 24 | 1024 | 16 | 340M | 小写102种语言 |
| bert-base-chinese | 12 | 768 | 12 | 110M | 简/繁体中文 |
常用数量级单位(了解)
| 缩写 | 英文全称 | 中文 | 数值 | 口语对应 |
|---|---|---|---|---|
| K | Kilo | 千 | 1,000 | — |
| M | Million | 百万 | 1,000,000 | 100万 |
| B | Billion | 十亿 | 1,000,000,000 | 10亿 |
换算口诀:
- 1M = 100万
- 10M = 1000万 = 0.1亿
- 100M = 1亿
- 110M = 1.1亿
- 340M = 3.4亿
Transformers库使用
了解Transformers库
- Huggingface总部位于纽约,是一家专注于自然语言处理、人工智能和分布式系统的创业公司。他们所提供的聊天机器人技术一直颇受欢迎,但更出名的是他们在NLP开源社区上的贡献。Huggingface一直致力于自然语言处理NLP技术的平民化(democratize),希望每个人都能用上最先进(SOTA, state-of-the-art)的NLP技术,而非困窘于训练资源的匮乏。同时Hugging Face专注于NLP技术,拥有大型的开源社区。尤其是在github上开源的自然语言处理,预训练模型库 Transformers,已被下载超过一百万次,github上超过24000个star。
- Huggingface Transformers 是基于一个开源基于 transformer 模型结构提供的预训练语言库。它支持 Pytorch,Tensorflow2.0,并且支持两个框架的相互转换。Transformers 提供了NLP领域大量state-of-art的 预训练语言模型结构的模型和调用框架。
- 框架支持了最新的各种NLP预训练语言模型,使用者可快速的进行模型调用,并且支持模型further pretraining 和 下游任务fine-tuning。举个例子Transformers 库提供了很多SOTA的预训练模型,比如BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, CTRL。
- 社区Transformer的访问地址为:https://huggingface.co/。
三层应用结构
- 管道(Pipline)方式:高度集成的极简使用方式,只需要几行代码即可实现一个NLP任务。
- 自动模型(AutoMode)方式:可载入并使用BERTology系列模型。
- 具体模型(SpecificModel)方式:在使用时,需要明确指定具体的模型,并按照每个BERTology系列模型中的特定参数进行调用,该方式相对复杂,但具有较高的灵活度。
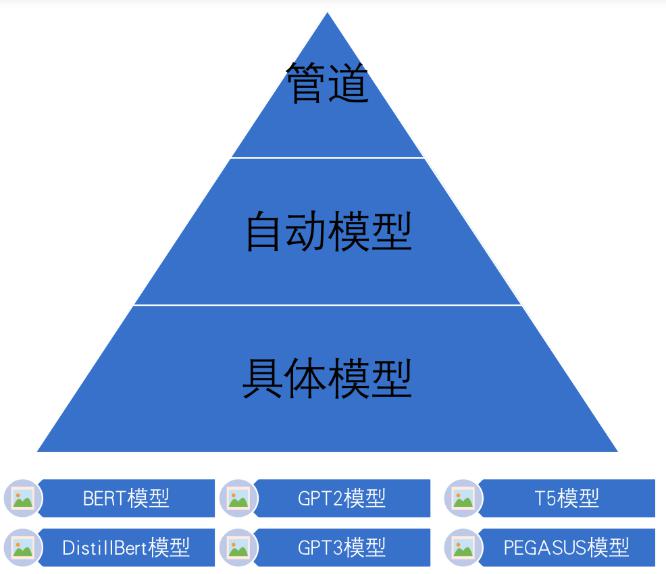
环境搭建
注意: 最好不要在base虚拟环境中安装、卸载相关的库
使用transformers需要执行如下安装命令
1- 进入到你的虚拟环境
conda activate nlp_cuda
2- 安装命令
pip install transformers==4.57.6 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install datasets -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tf-keras -i https://pypi.tuna.tsinghua.edu.cn/simple
Pipeline方式应用预训练模型
文本分类
定义:对一个文本进行分类:eg:对一个评论文本,判断其实好评还是差评
代码实现
def text_classification():
# 1- 加载预训练模型
"""
参数解释:
task:任务类型。注意:需要根据你的要求来设置,不要乱给
model:下载好的预训练模型路径 或者 是模型的名称。如果本地没有该模型,会自动去huggingFace下载
注意:路径要改成自己的
"""
model = pipeline(task="text-classification",model=r"D:\PretrainedModel\chinese_sentiment")
# 2- 对未知数据进行分类
# pred_result = model("王大锤很帅")
# pred_result = model("王大锤很丑")
pred_result = model("王大锤实在是太丑,无法直视")
"""
结果解释:
'label': 'star 5' 预测结果
score:预测概率值
"""
print(f"预测结果:{pred_result}") # [{'label': 'star 5', 'score': 0.709129273891449}]
特征提取
定义:将文本输入模型,得到特征向量的表示
代码实现
def feature_extraction():
# 1- 加载预训练模型
model = pipeline(task="feature-extraction",model=r"D:\PretrainedModel\bert-base-chinese")
# 2- 将文本转成张量
feature_data = model("王大锤实在是太丑,无法直视")
print(type(feature_data)) # List列表
print(feature_data)
# 转成张量
"""
为什么上面的句子最终得到了15个词?
答:目前bert-base-chinese预训练模型的分词策略是以单个字进行分词,然后在句子的前面和后面分别增加对应的标识,最终的结果如下
[CLS] 王 大 锤 实 在 是 太 丑 , 无 法 直 视 [SEP]
"""
result_tensor = torch.tensor(feature_data)
print(result_tensor.shape) # torch.Size([1, 15, 768]) 1条句子,句子中有15个词,每个词的向量维度是768
完形填空
掩码任务,将一段文本中的某个token进行MASK,然后通过模型来预测被MASK掉的词
代码实现
def fill_mask():
# 1- 加载预训练模型
model = pipeline(task="fill-mask",model=r"D:\PretrainedModel\chinese-bert-wwm")
# 2- 准备数据
"""
注意:需要模型为你填空的地方需要使用[MASK]进行站位。一定注意 单词、大小写等不要写错
"""
content = "我想明天去[MASK]家吃饭。"
fill_result = model(content)
"""
预测结果解释:[{'score': 0.39558693766593933, 'token': 1961, 'token_str': '她', 'sequence': '我 想 明 天 去 她 家 吃 饭 。'}]
score:概率值,值越大可能性就越高
token:填充词在词汇表中的索引
token_str:索引对应的词内容
sequence:填充以后的句子内容
"""
print(fill_result)
阅读理解
question-answer,根据文本以及问题,从文本里面解答问题的答案
代码实现
def q_and_a():
# 1- 加载预训练模型
model = pipeline(task="question-answering",model=r"D:\PretrainedModel\chinese_pretrain_mrc_roberta_wwm_ext_large")
# 2- 准备数据
context = '我叫张三,我是一个程序员,我的喜好是打篮球。'
questions = ['我是谁?', '我是做什么的?', '我的爱好是什么?','我爸姓啥?','我儿子姓啥?']
"""
参数解释:
context:给模型进行理解的上下文内容
question:你的问题
结果解释:[{'score': 1.2071785628411935e-12, 'start': 2, 'end': 4, 'answer': '张三'}]
score:答案的概率值
answer:问题对应的答案
start、end:答案在上下文context中的开始索引和结束索引,区间是左闭右开
"""
answers = model(context=context, question=questions)
print(type(answers))
print(answers)
文本摘要
对文档的概括总结
代码实现
def summary():
# 1- 加载预训练模型
model = pipeline(task="summarization",model=r"D:\PretrainedModel\distilbart-cnn-12-6")
# 2- 准备数据
text = "BERT is a transformers model pretrained on a large corpus of English data " \
"in a self-supervised fashion. This means it was pretrained on the raw texts " \
"only, with no humans labelling them in any way (which is why it can use lots " \
"of publicly available data) with an automatic process to generate inputs and " \
"labels from those texts. More precisely, it was pretrained with two objectives:Masked " \
"language modeling (MLM): taking a sentence, the model randomly masks 15% of the " \
"words in the input then run the entire masked sentence through the model and has " \
"to predict the masked words. This is different from traditional recurrent neural " \
"networks (RNNs) that usually see the words one after the other, or from autoregressive " \
"models like GPT which internally mask the future tokens. It allows the model to learn " \
"a bidirectional representation of the sentence.Next sentence prediction (NSP): the models" \
" concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to " \
"sentences that were next to each other in the original text, sometimes not. The model then " \
"has to predict if the two sentences were following each other or not."
result = model(text)
print(type(result))
print(result)
命名实体识别
对一段文本进行序列标注,对每一个词汇都要进行分类,习惯用BIO或者BIOES的标识符
代码实现
def ner():
# 1- 加载预训练模型
"""
NER命名实体识别 本质就是 词的分类任务
task的取值:token-classification,它有一个简写的值ner
"""
model = pipeline(task="ner",model=r"D:\PretrainedModel\roberta-base-finetuned-cluener2020-chinese")
# 下面的代码验证了:不同的预训练模型针对的业务场景是不一样的,下面的模型无法提取出NER
# model = pipeline(task="ner",model=r"D:\PretrainedModel\bert-base-chinese")
# 2- 准备数据
content = "鲁迅原名周树人,代表作有《朝花夕拾》,在商务部上班,今天他去故宫游览"
ner_result = model(content)
print(type(ner_result))
print(ner_result)
Pipeline总结
通用流程(所有任务共用)
调用pipeline(task="任务名", model="本地路径/模型名"),无本地模型自动下载
传入文本数据推理,输出带置信分score的预测结果
1. 文本分类 text-classification
作用:整体文本归类(如情感正负)
输出:label类别 + score概率
2. 特征提取 feature-extraction
作用:输出文本向量表征
BERT 分词规则:【单字分词】,首尾加[CLS]/[SEP]
输出结构:[句子数, 词数, 768维向量]列表,可转 Tensor
3. 完形填空 fill-mask
作用:掩码预测,文本用[MASK]占位待填充
返回字段:score、词索引token、文字token_str、完整句子sequence
4. 阅读理解 question-answering
输入:context上下文 + question问题
输出:answer答案、答案在文本的起止索引、置信分
5. 文本摘要 summarization
作用:长文本自动概括浓缩
6. 命名实体识别 ner (token-classification 简写)
本质:逐字序列标注,用 BIO/BIOES 标识实体
关键点:模型需适配中文实体任务,通用 BERT 无法做 NER
AutoModel方式应用预训练模型
文本分类【掌握】
定义:对一个文本进行分类:eg:对一个评论文本,判断其实好评还是差评
代码实现
import torch
# 自动加载模型的配置文件
from transformers import AutoConfig
# 自动加载对应的模型
from transformers import AutoModel
# 自动加载模型词汇表,分词器
from transformers import AutoTokenizer
# 文本分类
from transformers import AutoModelForSequenceClassification
# 完型填空
from transformers import AutoModelForMaskedLM
# 阅读理解
from transformers import AutoModelForQuestionAnswering
# 文本摘要
from transformers import AutoModelForSeq2SeqLM
# NER命名实体识别
from transformers import AutoModelForTokenClassification
def text_classification():
# 1- 创建类的实例对象
# 1.1- 预训练模型路径
model_path = r"D:\PretrainedModel\chinese_sentiment"
# 1.2- 分词器实例对象
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 1.3- 预训练模型实例对象
model = AutoModelForSequenceClassification.from_pretrained(model_path)
# 2- 准备数据
content = "我爱武汉"
# 3- 分词
"""
分词后结果解释:tensor([[ 101, 2769, 4263, 3636, 3727, 102]])
分词前会在句子的前面增加[CLS],句子的末尾增加[SEP]
CLS:classification分类
SEP:separate分隔
参数解释:
text:要分词的内容
max_length:句子长度规范的上限
padding:是否要对长度不够的句子进行内容填充
truncation:是否要对长度超过的句子进行内容截断
return_tensors:分词以后返回的数据类型是啥。推荐使用pt
"""
data_tensor = tokenizer.encode(
text=content,
max_length=10,
padding=True,
truncation=True,
return_tensors="pt"
)
print(f"分词后的结果:{type(data_tensor)}")
print(f"分词后的结果:{data_tensor}")
# 4- 调用预训练模型
# 4.1- 将模式设置为评估模式
model.eval()
# 4.2- 调用模型
result = model(data_tensor)
print(type(result))
print(result)
"""
代码解释:
result:代表的是某个类的实例对象
result.logits:通过实例对象 获得 实例属性值,属性值是二维的张量
"""
print(torch.argmax(result.logits, dim=-1))
特征提取【掌握】
定义:将文本输入模型,得到特征向量的表示
代码实现
def feature_extraction():
# 1- 创建类的实例对象
# 1.1- 预训练模型路径
model_path = r"D:\PretrainedModel\bert-base-chinese"
# 1.2- 分词器对象
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 1.3- 预训练模型对象
model = AutoModel.from_pretrained(model_path)
# 2- 准备数据
message = ['你是谁', '人生该如何起头']
# 3- 分词
"""
encode和encode_plus的区别:推荐使用encode_plus
1- encode_plus输出内容:{'input_ids': tensor([[ 101, 872, 3221, 6443, 102, 782, 4495, 6421, 1963, 862, 6629, 1928,
102, 0, 0, 0, 0, 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]])}
2- input_ids
对句子进行分词,词以词索引的形式表示。101有且仅有一个,句子有多少个那么102也有多少个
3- token_type_ids:
对应位置的词索引 来自的 句子索引(也就是词属于哪个句子)
4- attention_mask:
0:对应位置的词无意义,也就是通过padding填充的0
1:对应位置的词是句子中的原始词(包含[CLS]和[SEP])
参数解释:
padding:句子长度不够上限的,进行补0操作。具体的取值如下:
True:首先在送进来的所有句子中获得最长句子的长度,然后其他不够该长度的句子,进行补0操作。最终补完0以后的句子长度 最长句子的长度
max_length:长度不够max_length参数设置的长度,那么补0。补完0以后的句子长度等于max_length参数设置的长度
"""
data_tensor = tokenizer.encode_plus(
text=message,
max_length=20,
padding="max_length",
truncation=True,
return_tensors="pt"
)
# print(type(data_tensor))
# print(data_tensor)
# 4- 调用模型
model.eval()
result = model(**data_tensor) # **对字典进行解包
print(type(result))
print(result)
"""
last_hidden_state:是编码器中最后一层隐藏层的隐藏状态数据
pooler_output:池化层。它的来源 last_hidden_state[:,0] 先经过线性网络层的处理,再经过激活函数的处理得到。它与CNN中的池化没有关系
对应的源代码在 from transformers import BertModel 中700行
池化:从大量数据中,挑选一部分数据出来的过程,称之为池化
"""
print(f"Encoder编码器中最后一层编码器层的隐藏状态:{result.last_hidden_state}")
print(f"Encoder编码器中最后一层编码器层的隐藏状态 经过池化处理(线性求和)以后的结果:{result.pooler_output}")
print(f"Encoder编码器中最后一层编码器层的隐藏状态:{result.last_hidden_state.shape}")
print(f"Encoder编码器中最后一层编码器层的隐藏状态 经过池化处理(线性求和)以后的结果:{result.pooler_output.shape}")
扩展知识:
bert中的池化层和CNN中的池化,压根不是同一个东西
bert中的池化层,实际是一个线性层
为什么都叫“池化”?
“Pooling” 在机器学习中泛指将多个值聚合为一个值的操作
完形填空【掌握】
掩码任务,将一段文本中的某个token进行MASK,然后通过模型来预测被MASK掉的词
代码实现
def fill_mask():
# 1- 创建实例对象
model_path = r"D:\PretrainedModel\chinese-bert-wwm"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForMaskedLM.from_pretrained(model_path)
# 2- 准备数据
content = "我想明天去[MASK]家吃饭"
# 3- 分词
data_tensor = tokenizer.encode_plus(text=content,return_tensors="pt")
# print(data_tensor)
# 4- 调用模型
model.eval()
result = model(**data_tensor)
# 5- 结果解析
# print(type(result))
# print(result)
# 5.1- 取出张量数据
"""
logits形状解释:torch.Size([1, 11, 21128])
1:1条句子
11:包含[CLS]和[SEP]在内,总共有11个词
21128:因为chinese-bert-wwm预训练模型的词汇表中有21128个词
"""
logits = result.logits
# print(logits.shape) # torch.Size([1, 11, 21128])
# 5.2- 取出[MASK]索引对应的预测概率分布
# logits[0]:取第一条句子;logits[0][6]:取第一条句子中索引为6的词对应的概率分布。
mask_tensor = logits[0][6]
# print(mask_tensor.shape)
# print(mask_tensor)
# 5.3- 取概率值最高那个对应的索引,就是得到了词索引
pred_index = torch.argmax(mask_tensor, dim=-1).item()
# 5.4- 根据词索引 得到 词的内容
# convert_ids_to_tokens:根据词索引,得到词内容
pred_word = tokenizer.convert_ids_to_tokens(pred_index)
print(f"预测词的词索引{pred_index},对应内容是{pred_word}")
阅读理解
question-answer,根据文本以及问题,从文本里面解答问题的答案
代码实现
def q_and_a():
# 1- 创建类的实例对象
model_path = r"D:\PretrainedModel\chinese_pretrain_mrc_roberta_wwm_ext_large"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForQuestionAnswering.from_pretrained(model_path)
# 2- 准备数据
# 注意:如果问题、上下文中有中文的标点符号,在进行阅读理解的时候,会自动的被过滤掉。
context = '我叫张三 我是一个程序员 我的喜好是打篮球'
questions = ['我是谁?', '我是做什么的?', '我的爱好是什么?']
# 3- 问题回答
model.eval()
for q in questions:
# 3.1- 分词
"""
data_tensor的结构:[CLS]问题内容[SEP]上下文[SEP]
举例:[CLS]我是谁?[SEP]我叫张三,我是一个程序员,我的喜好是打篮球。[SEP]
"""
data_tensor = tokenizer.encode_plus(q,context,return_tensors="pt")
# print(data_tensor)
# 3.2- 调用模型
result = model(**data_tensor)
# 3.3- 结果解析
# print(type(result))
# print(result)
# 3.3.1- 分别获得start_logits、end_logits
start_logits = result.start_logits
end_logits = result.end_logits
# 3.3.2- 分别获得start索引和end索引:使用argmax()取最大值的索引即可
start_index = torch.argmax(start_logits, dim=-1).item()
end_index = torch.argmax(end_logits, dim=-1).item() + 1
# 3.3.3- 对context进行切片
answer = tokenizer.convert_ids_to_tokens(data_tensor.input_ids[0][start_index:end_index])
print(f"问题{q},答案{answer}")
文本摘要
对文档的概括总结
代码实现
def summary():
# 1- 创建类的实例对象
model_path = r"D:\PretrainedModel\distilbart-cnn-12-6"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForSeq2SeqLM.from_pretrained(model_path)
# 2- 准备数据
text = "BERT is a transformers model pretrained on a large corpus of English data " \
"in a self-supervised fashion. This means it was pretrained on the raw texts " \
"only, with no humans labelling them in any way (which is why it can use lots " \
"of publicly available data) with an automatic process to generate inputs and " \
"labels from those texts. More precisely, it was pretrained with two objectives:Masked " \
"language modeling (MLM): taking a sentence, the model randomly masks 15% of the " \
"words in the input then run the entire masked sentence through the model and has " \
"to predict the masked words. This is different from traditional recurrent neural " \
"networks (RNNs) that usually see the words one after the other, or from autoregressive " \
"models like GPT which internally mask the future tokens. It allows the model to learn " \
"a bidirectional representation of the sentence.Next sentence prediction (NSP): the models" \
" concatenates two masked sentences as inputs during pretraining. Sometimes they correspond to " \
"sentences that were next to each other in the original text, sometimes not. The model then " \
"has to predict if the two sentences were following each other or not."
# 3- 分词
data_tensor = tokenizer.encode_plus(text,return_tensors="pt")
# 4- 调用模型
model.eval()
"""
为什么调用model.generate,而不是直接调用model(**data_tensor)?
答:因为前面的generate内部会自动执行argmax,将生成词的词索引返回。如果使用后面的model(**data_tensor),你需要自己调用argmax
"""
result = model.generate(**data_tensor)
# print(f"result-->{result}")
# result_2 = model(**data_tensor)
# print(f"result_2-->{result_2}")
# 5- 结果解析
# 5.1- 使用convert_ids_to_tokens
# 参数解释:skip_special_tokens特殊符号不展示
result_content = tokenizer.convert_ids_to_tokens(result[0], skip_special_tokens=False)
print(" ".join(result_content))
result_content = tokenizer.convert_ids_to_tokens(result[0], skip_special_tokens=True)
print(" ".join(result_content))
# 5.2- 使用分词器进行解码
# convert_ids_to_tokens 展示的是模型“眼中”的原始文本形态,而 decode 方法才是将其还原为人类可读文本的正确工具。
result_content = [tokenizer.decode(word_index, skip_special_tokens=True, clean_up_tokenization_spaces=False) for word_index in result[0]]
print(" ".join(result_content))
命名实体识别
对一段文本进行序列标注,对每一个词汇都要进行分类,习惯用BIO或者BIOES的标识符
代码实现
def ner():
# 1- 创建类的实例对象
model_path = r"D:\PretrainedModel\roberta-base-finetuned-cluener2020-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForTokenClassification.from_pretrained(model_path)
config = AutoConfig.from_pretrained(model_path)
# 2- 准备数据
content = "鲁迅原名周树人,代表作有《朝花夕拾》,在商务部上班,今天他去故宫游览"
# 3- 分词
data_tensor = tokenizer.encode_plus(content,return_tensors="pt")
# 4- 调用模型
model.eval()
result = model(**data_tensor)
# 5- 结果解析
# 5.1- 取出预测结果数据
logits = result.logits
"""
结果形状解释:[1, 36, 32]
1:1条句子
36:句子的长度,再加上[CLS]和[SEP],总共有36个词
32:该预训练模型支持的命名实体的类别数
"""
# print(logits.shape) # [1, 36, 32]
# 5.2- 将词索引 解析回 词内容
word_list = [tokenizer.decode(word_index,skip_special_tokens=True, clean_up_tokenization_spaces=False) for word_index in data_tensor.input_ids[0]]
# 5.3- 遍历解析每个词对应的NER类型
# 获得NER的配置字典
id2label_dict = config.id2label
for word,prob_list in zip(word_list,logits[0]):
# 取概率最大的索引
ner_index = torch.argmax(prob_list, dim=-1).item()
# 通过索引获得对应的NER的名称
ner_name = id2label_dict[ner_index]
print(f"{word}={ner_name}")
AutoModel总结
1. 文本分类
定义:判断文本类别(好评/差评等)
核心模型:AutoModelForSequenceClassification
关键:result.logits → argmax 取类别
2. 特征提取
定义:将文本转为特征向量
核心模型:AutoModel
关键输出:
last_hidden_state:最后一层隐藏状态
pooler_output:[CLS]经过线性层+激活函数(≠CNN池化)
3. 完形填空
定义:预测被[MASK]的词
核心模型:AutoModelForMaskedLM
关键:logits → 取[MASK]位置 → argmax → 还原词
4. 阅读理解
定义:根据上下文回答问题
核心模型:AutoModelForQuestionAnswering
关键:start_logits和end_logits → argmax → 切片取答案
5. 文本摘要
定义:概括文档内容
核心模型:AutoModelForSeq2SeqLM
关键:使用model.generate()(内部自动argmax),而非直接调用模型
6. 命名实体识别
定义:对每个词分类(BIO/BIOES标注)
核心模型:AutoModelForTokenClassification
关键:logits → 每个词取argmax → 通过config.id2label映射
具体模型方式完成NLP任务
import torch
from transformers import BertTokenizer # Bert模型的专属分词器:对文本进行分词、词转成词索引
from transformers import BertForMaskedLM # 完型填空
def fill_mask():
# 1- 创建实例对象
model_path = r"D:\PretrainedModel\chinese-bert-wwm"
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForMaskedLM.from_pretrained(model_path)
# 2- 准备数据
content = "我想明天去[MASK]家吃饭"
# 3- 分词
data_tensor = tokenizer.encode_plus(text=content,return_tensors="pt")
# 4- 调用模型
model.eval()
result = model(**data_tensor)
# 5- 结果解析
# 5.1- 取出张量数据
logits = result.logits
# 5.2- 取出[MASK]索引对应的预测概率分布
mask_tensor = logits[0][6]
# 5.3- 取概率值最高那个对应的索引,就是得到了词索引
pred_index = torch.argmax(mask_tensor, dim=-1).item()
# 5.4- 根据词索引 得到 词的内容
pred_word = tokenizer.convert_ids_to_tokens(pred_index)
print(f"预测词的词索引{pred_index},对应内容是{pred_word}")
if __name__ == '__main__':
fill_mask()
预训练模型总结【掌握】
预训练模型使用总结:
1- pipeline管道:
优点:代码开发非常简单
缺点:底层高度封装,可调整的超参数少
使用:一般用来快速验证预训练模型/大模型是否满足业务需求
2- AutoModel自动模型:
优点:代码相对比较简单,有一定可以可调整的超参数
缺点:相对具体模型来说,可调整的超参数相对较少
3- 具体模型:
优点:可调整的超参数很多,能够针对具体的大模型进行指定参数的微调。每种大模型的可调整的参数都是不一样
缺点:比较灵活,不同的大模型可调整的参数有区别
使用:针对业务场景需要比较高的情况,推荐使用
后续课程:LoRA、QLoRA
使用推荐:如果上级给到的开发时间比较短,使用pipeline;如果时间充足,推荐使用具体模型
迁移学习实践(文本分类案例)【掌握】
实现流程
1.获取数据集
2.数据预处理: 实例化dataset,dataloader,注意这里面在dataloder里用了自定义函数进行文本张量化处理
3.搭建模型: 注意,我们这里用bert预训练模型来得到文本的特征表示,然后在经过自定义网络实现分类
4.模型训练: 注意,不训练bert模型的参数,只更新自己定义的网络参数
5.模型测试: 注意,如果在GPU上训练的模型,想在CPU上使用, model.load_state_dict(torch.load(path, map_location="cpu")) #将模型放到cpu上
数据预处理
定义批处理函数
在Dataloader里面自动调用,目的是处理dataset里面的数据,进行张量化处理
代码实现
import os
os.environ["TF_ENABLE_ONEDNN_OPTS"]="0"
import torch
import torch.nn as nn
# HuggingFace 提供的据集加载工具, 可以加载本地数据, 也可以加载公开数据源
from datasets import load_dataset
from torch.utils.data import DataLoader
from tqdm import tqdm
# 导入BERT相关组件(中文文本分词器, 预训练的BERT模型)
from transformers import BertTokenizer, BertModel
# 使用GPU或者MPS
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # windows的写法
# device = torch.device("mps" if torch.backends.mps.is_available() else "cpu") # MAC的写法
# 1- 创建预训练模型对象
model_path = r"D:\PretrainedModel\bert-base-chinese"
# 只负责文本预处理,不涉及张量计算,所以不需要也不可以发送到 GPU
bert_tokenizer = BertTokenizer.from_pretrained(model_path)
bert_model = BertModel.from_pretrained(model_path).to(device)
# 2- 数据探索【可选】
def load_data():
# 查看训练集数据
"""
path:可以写文件所在目录,也可以写文件类型例如:csv
data_files:可以写文件路径,也可以写文件名称。可以传递字典
split:标明这份数据的作用是什么,训练集、测试集、验证集。想想机器学习中train_test_split的作用。
"""
# 方式一:推荐写法。注意:data_files不要再跟前面path的路径了
train_data = load_dataset(path="data",data_files="train.csv",split="train")
# 方式二
# train_data = load_dataset(path="csv",data_files="data/train.csv",split="train")
print(type(train_data))
print(train_data[0])
print(len(train_data))
# 3- 针对每个批次的数据进行额外的处理
def collate_fn(data):
# 1- 从每个批次中分别取出特征(也就是句子)和目标值(0/1)
sents = [item["text"] for item in data] # 格式:['句子1','句子2'...]
labels = [item["label"] for item in data] # 格式:[1,1,0,1,0...]
# print(f"sents-->{sents}")
# print(f"labels-->{labels}")
# 2- 对句子进行批量处理
data_tensor = bert_tokenizer.batch_encode_plus(
sents,
return_tensors="pt",
padding=True,
truncation=True,
max_length=300
)
# 3- 提取分词处理后的数据内容
input_ids = data_tensor["input_ids"]
token_type_ids = data_tensor["token_type_ids"]
attention_mask = data_tensor["attention_mask"]
# 4- 将目标值labels转成张量
labels = torch.LongTensor(labels)
return input_ids,token_type_ids,attention_mask,labels
实例化Dataloader
代码实现
# 4- 创建数据加载器
def get_dataloader(file_path):
# 1- 加载指定路径下的文件
dataset = load_dataset(path="data",data_files=file_path,split="train")
# 2- 创建DataLoader实例对象
"""
参数解释:
dataset:数据集对象
batch_size:每个批次中样本的条数。如果样本长度不一致,batch_size只能设置为1
shuffle:是否对数据打散。让模型训练更加充分
drop_last:如果最后一个批次的样本条数不足batch_size大小,那么直接不要
collate_fn:针对每个批次数据的具体处理函数。注意:传递的是函数名称,不要带小括号
"""
dataloader = DataLoader(
dataset=dataset,
batch_size=8,
shuffle=True,
drop_last=True,
collate_fn=collate_fn
)
return dataloader
测试DataLoader数据加载器
if __name__ == '__main__':
# 测试数据加载器
dataloader = get_dataloader(file_path="train.csv")
for input_ids,token_type_ids,attention_mask,labels in dataloader:
print(input_ids)
break
搭建模型
应用迁移学习的思路:bert预训练模型特征处理+自定义模型(分类)
代码实现
# 5- 创建自定义模型类:前面是预训练模型,后面是我们自己的网络结构
class MyTextClassification(nn.Module):
def __init__(self):
# 1- 初始化父类
super().__init__()
# 2- 在Bert预训练模型的后面增加我们自己的网络结构
"""
bert_model.config.hidden_size:获得对应预训练模型的隐藏状态向量维度。目前这里是768。
好处是后续即使更换了其他的预训练模型,这个地方不需要做任何修改
out_features为什么是2?
答:我们目前的业务场景是2分类问题
"""
bert_hidden_size = bert_model.config.hidden_size
self.output_linear = nn.Linear(in_features=bert_hidden_size,out_features=2)
def forward(self,input_ids,token_type_ids,attention_mask):
# 1- 先调用预训练模型
"""
这里为什么要写torch.no_grad()?
答:
1- 该代码的作用是禁用梯度下降和反向传播,那么就不能更新参数w和b
2- 如果不禁用,那么会对Bert预训练模型的参数进行全量微调,那么运行会比较耗时
3- 使用推荐:
3.1:如果想要速度更快,推荐使用torch.no_grad()
3.2:如果想要更好的效果,模型更加准确,推荐不使用torch.no_grad()
"""
with torch.no_grad():
bert_output = bert_model(input_ids,token_type_ids,attention_mask)
# 2- 再调用我们自己的网络层
"""
为什么写成bert_output.last_hidden_state[:,0]?
答:
bert_output.last_hidden_state:获得BERT中最后一层隐藏层所有时间步(也就是句子中词的个数)的隐藏状态
bert_output.last_hidden_state[:,0]:获得的是句子中第一个词的隐藏状态,也就是[CLS]的隐藏状态
bert->只有Transformer中的Encoder编码器端->计算的是自注意力机制
理论上来说取任意一个词的隐藏状态都行,但是传递进来的句子长度我们不知道,Bert为了简单方便因此使用[:,0]
上面对应的论文:https://arxiv.org/pdf/1810.04805
内容:The first token of every sequence is always a special classification token ([CLS]). The final hidden state corresponding to this token is used as the aggregate sequence representation for classification
"""
return self.output_linear(bert_output.last_hidden_state[:,0])
模型训练
注意:
1: 因为使用的预训练模型,所以在训练的时候,对自定义的模型加上,model.train()
2: 不更新bert预训练模型的参数requires_grad=False
3: 如果要想在GPU上训练:
3.1将预训练模型的对象放到GPU上
3.2自定义的模型对象放到GPU上
3.3模型的输入放到GPU上,eg:input_ids = input_ids.to('cuda');model = model.to('cuda')
代码实现
# 6- 模型训练
def train_model():
# 1- 准备数据
dataloader = get_dataloader("train.csv")
# 2- 禁用预训练模型的参数更新:需要与with torch.no_grad()一起配合使用
for param in bert_model.parameters():
param.requires_grad_(False)
# 3- 创建类的实例对象
# 3.1- 模型实例
model=MyTextClassification().to(device)
# 3.2- 优化器对象
optimizer = torch.optim.Adam(params=model.parameters(),lr=1e-4)
# 3.3- 损失函数对象
loss = nn.CrossEntropyLoss()
# 4- 设置模式
model.train()
# 5- 训练
epochs = 5
for epoch in range(epochs):
for i,(input_ids,token_type_ids,attention_mask,labels) in enumerate(tqdm(dataloader), start=1):
# 5.1- 将数据发送到指定设备
input_ids = input_ids.to(device=device)
token_type_ids = token_type_ids.to(device=device)
attention_mask = attention_mask.to(device=device)
labels = labels.to(device=device)
# 5.2- 前向传播
pred_output = model(input_ids,token_type_ids,attention_mask)
# 5.3- 计算损失
loss_value = loss(pred_output,labels)
# 5.4- 反向传播固定代码
optimizer.zero_grad()
loss_value.sum().backward()
optimizer.step()
# 5.5- 每隔20个批次输出统计信息
if i%20==0:
# 统计预测正确的样本条数
pred_index = torch.argmax(pred_output,dim=-1)
pred_correct_cnt = (pred_index==labels).sum().item()
# 计算预测的准确率
acc_rate = pred_correct_cnt/len(labels)
print(f"第{epoch+1}轮次,第{i}批次,平均准确率{round(acc_rate,4)}")
# 6- 将训练的模型保存
torch.save(model.state_dict(),"model/my_text_classification.pkl")
模型预测
注意: model.eavl()和with torch.no_grad()
# 如果在GPU上训练的模型,想在CPU上使用, model.load_state_dict(torch.load(path, map_location="cpu")) #将模型放到cpu上
代码实现
def predict():
# 1- 加载数据
dataloader = get_dataloader("test.csv")
# 2- 加载训练好的模型
model = AiModel().to(device)
model.load_state_dict(torch.load("model/bert.pkl"))
# 3- 定义准确率统计变量
correct_count = 0 # 预测正确的样本条数
total_sample_count = 0 # 已经预测的总样本条数
# 4- 预测
model.eval()
with torch.no_grad():
for i,(input_ids,token_type_ids,attention_mask,labels) in enumerate(tqdm(dataloader),start=1):
# 4.1- 将数据发送到对应设备
input_ids = input_ids.to(device)
token_type_ids = token_type_ids.to(device)
attention_mask = attention_mask.to(device)
labels = labels.to(device)
# 4.2- 预测得到结果
pred_result = model(input_ids,token_type_ids,attention_mask)
# 4.3- 计算准确率:算的累计平均准确率
pred_index = torch.argmax(pred_result,dim=-1)
correct_count += (pred_index==labels).sum().item()
total_sample_count += len(labels)
# print("labels-->",labels)
# print("pred_index-->",pred_index)
# print("input_ids-->",input_ids)
# 4.4- 间隔输出相关指标
if i % 20 == 0:
# 计算准确率
acc = correct_count / total_sample_count
print(f"已预测的样本批次{i},累计平均准确率{round(acc, 4)}")
# 恢复得到原始句子内容
text_content = "".join(tokenizer.convert_ids_to_tokens(input_ids[0], skip_special_tokens=True))
print(f"每个批次中第一条样本的原始评价内容:{text_content},预测的类别是:{pred_index[0]}")
版权声明
本文为 程序员青阳 原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文链接及本声明。