Coze智能体
Coze介绍和入门
Agent智能体概念
Agent智能体:大模型+工具,就形成了智能体
- 大模型:只能思考(脑袋),给模型文字输入,模型给出文字输出
- 工具:程序员写的函数(这些函数可以做什么就非常自由了)(手脚、身体)
大模型(脑袋)+工具(身体) = 智能体
智能体:以大模型作为思考核心,以工具函数作为行动,形成的能思考,能行动(干真正的活)的智能。
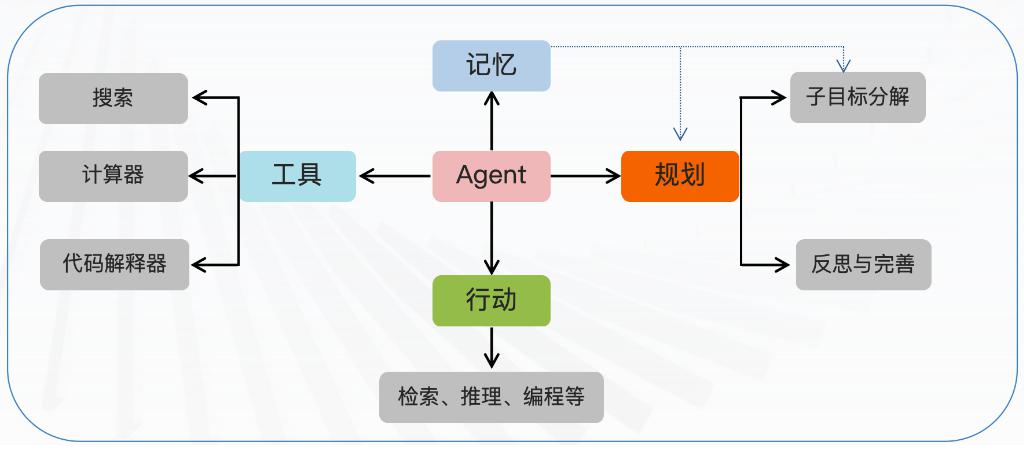
智能体主要有如下核心:
工具(核心):这就是智能体的核心中的核心,是智能体的行动依据- 行动(辅助):基于模型的思考给出的行动方案,指导决定调用哪个工具
- 规划(辅助):模型的思考、用来形成决策方案(调哪个工具、如何执行下一步)
- 记忆(辅助):历史对话记录
Coze平台介绍
Coze和Dify的对比总结:
1- Coze
优点:插件丰富,实现需求效率高
缺点:闭源;你上传的数据、文档,字节公司是知道的
使用:功能不涉及保密的数据,而且工期很短,可以使用Coze
2-Dify
优点:开源,部署在本地;你上传的数据、文档,只有你们公司知道,别人不知道
缺点:插件比较少,需要自己公司开发
使用:功能涉及保密的数据,而且工期很短,可以使用Dify
低代码智能体开发平台。
- 低代码:无需代码或少量代码,即可做开发的相关技术或框架平台。
Coze是基于网页使用的,全程联网,通过鼠标拖拉拽的方式即可自由完成模型+工具的组合,形成符合自己想法的各类智能体。
Coze中的模块
资源库
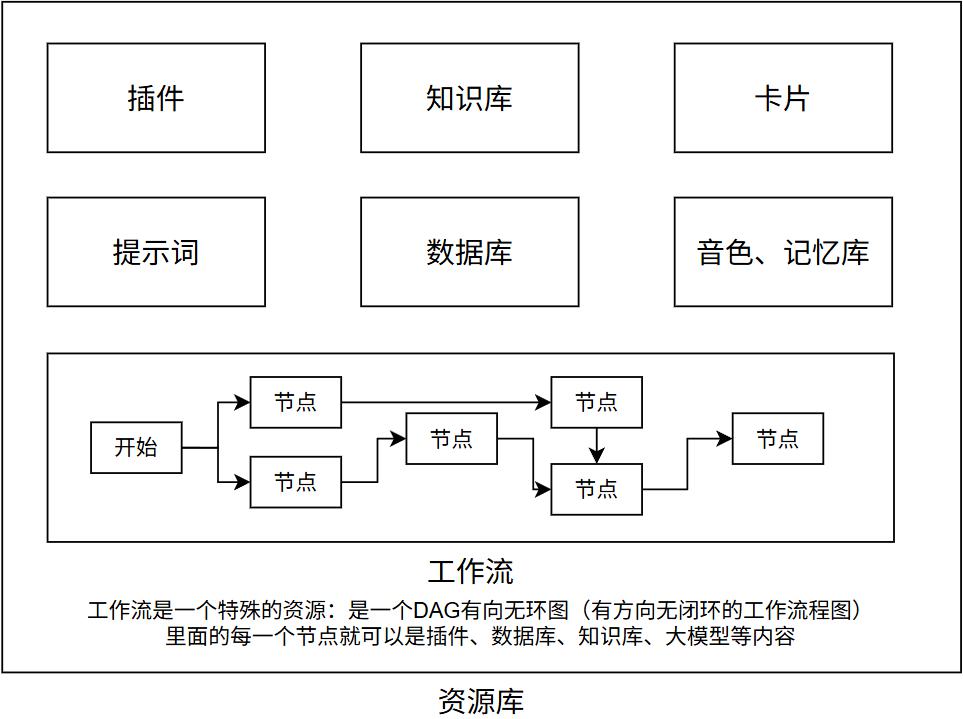
插件
就是模型的技能,可以提供联网搜索、天气查询、车票查询、硬件控制、等各类功能,插件可以在Coze网页内搜索使用。
工作流
工作流是一个特殊的资源:是一个DAG有向无环图(有方向无闭环的工作流程图)
里面的每一个节点就可以是插件、数据库、知识库、大模型等内容

工作流和对话流的区别:
1: 工作流:主要用来基于设置好的流程,自动化执行固定的任务
2: 对话流:处理与大模型的聊天,主要用于构建聊天机器人。不会自动调用工具、不会拆解复杂需求
知识库
就是外挂的知识库,可以支持上传PDF、Word等文档知识,作为模型的辅助参考资料。
提示词
可以记录用户自己准备好的提示词,随时取用。
数据库
支持用户上传数据作为二维表格数据库,供模型使用。
创建第一个工作流
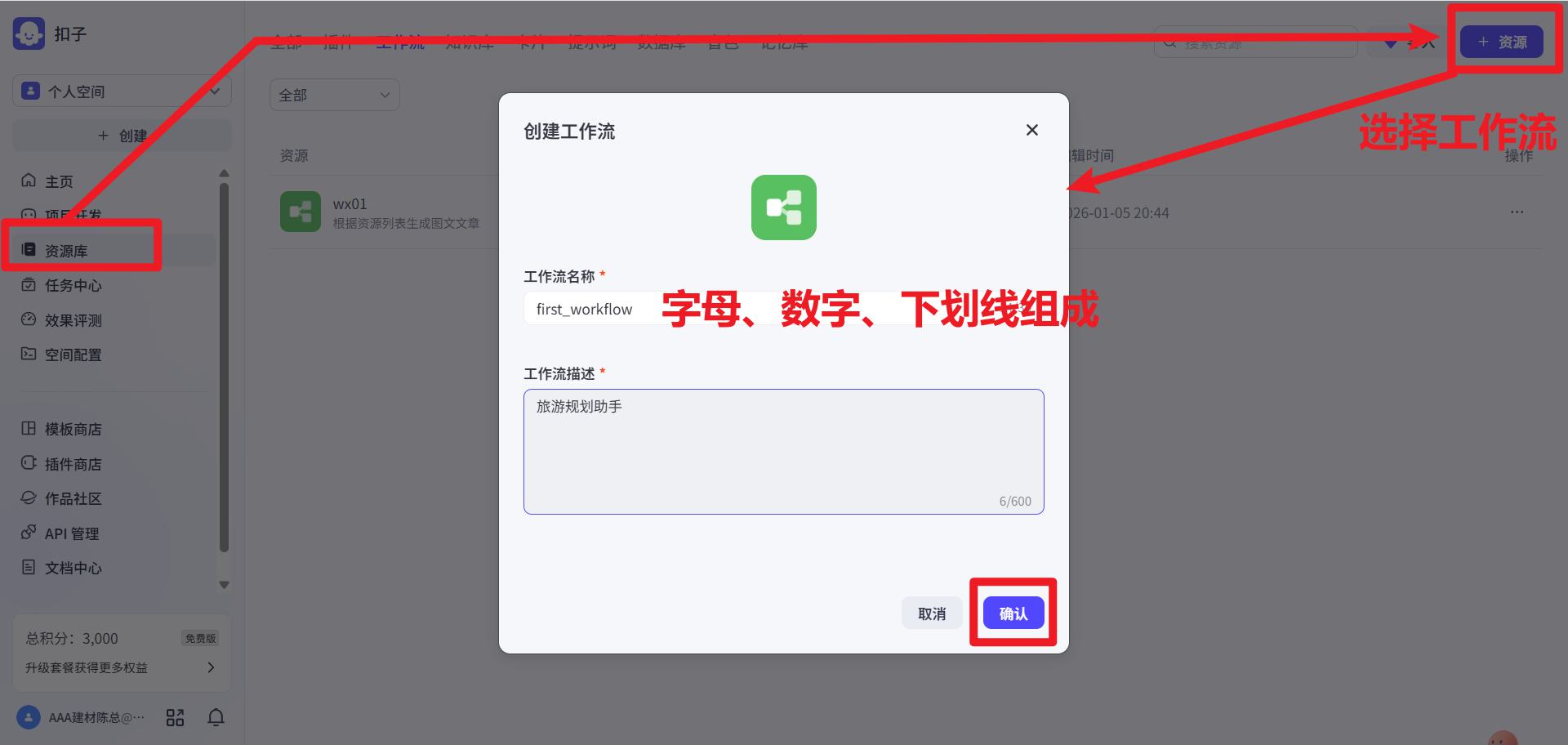
创建工作流
资源库 -> 右上角资源 -> 选择工作流 -> 填写信息 -> 确认
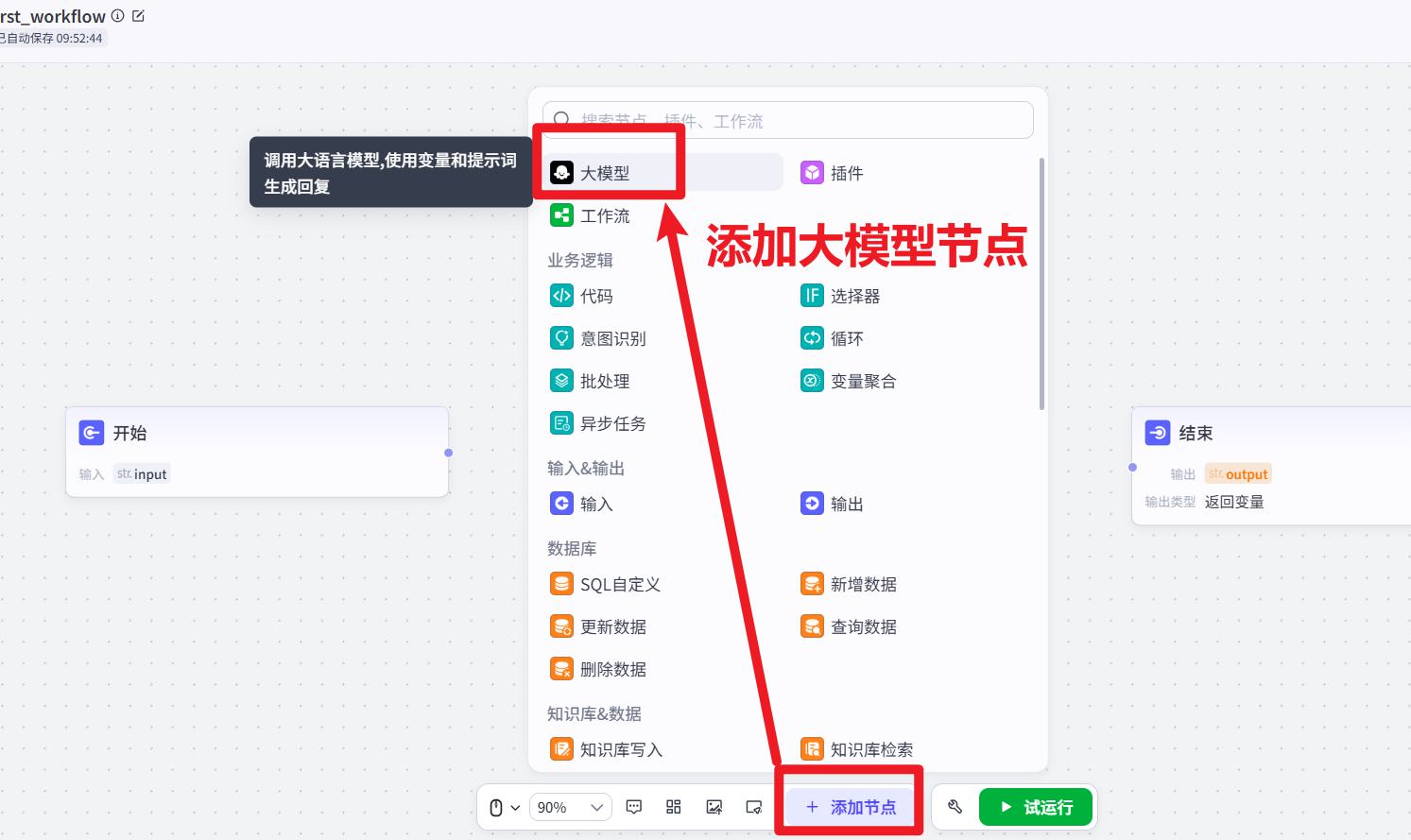
- 添加大模型节点
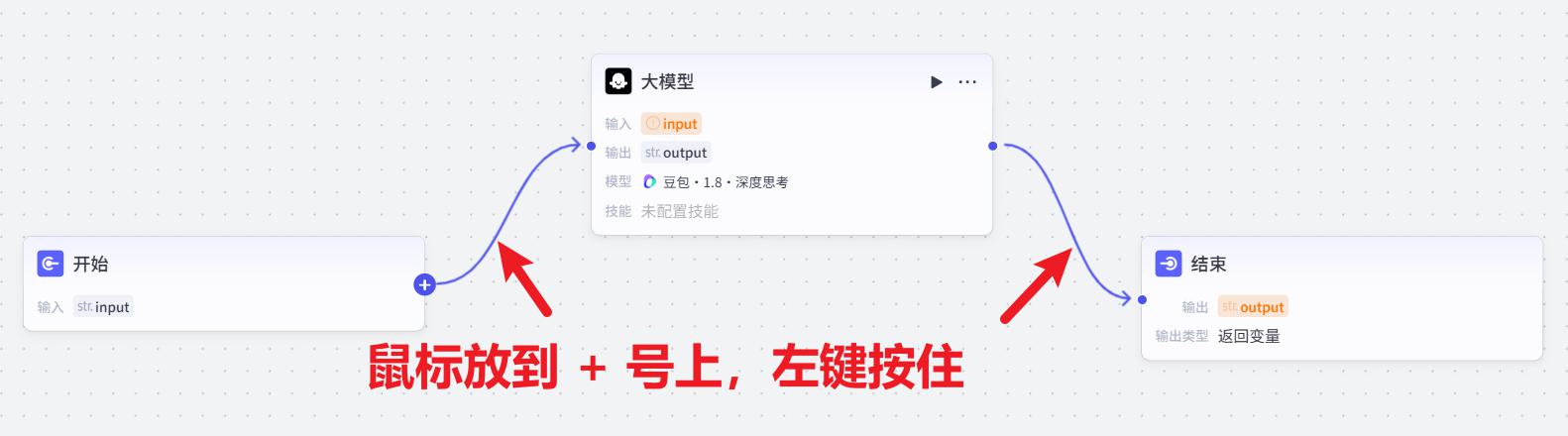
- 节点间连线
前后连接起来。鼠标放在 + 号上,左键按住进行连线
- 大模型基础配置
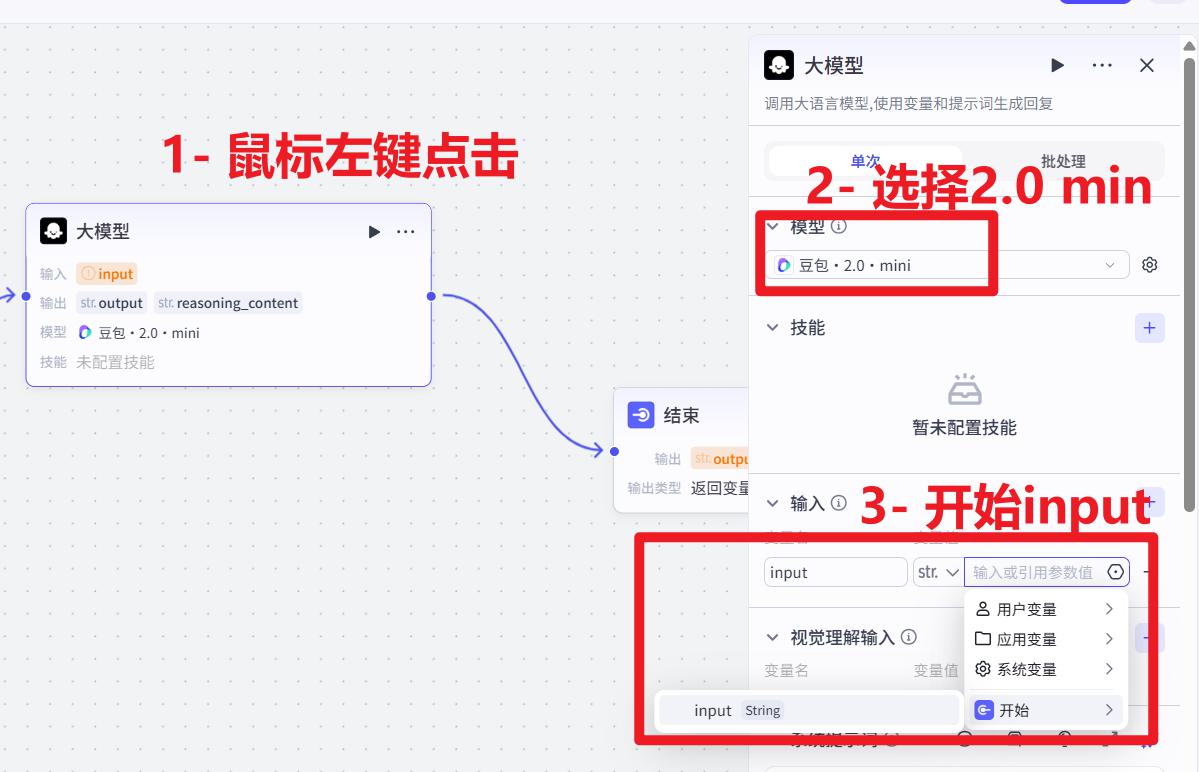
- 设置大模型提示词
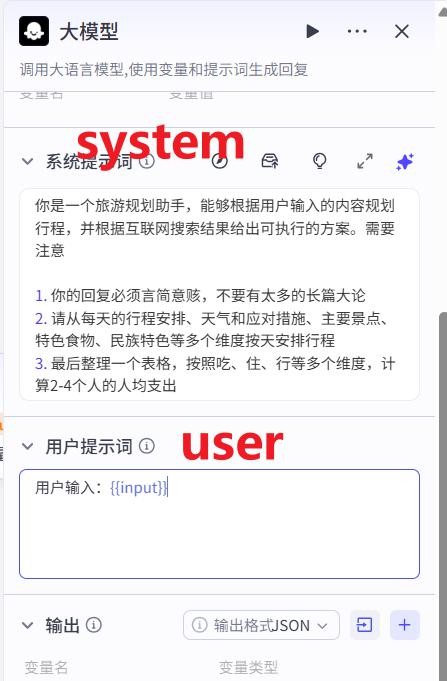
系统提示词:直接复制
你是一个旅游规划助手,能够根据用户输入的内容规划行程,并根据互联网搜索结果给出可执行的方案。需要注意
1. 你的回复必须言简意赅,不要有太多的长篇大论
2. 请从每天的行程安排、天气和应对措施、主要景点、特色食物、民族特色等多个维度按天安排行程
3. 最后整理一个表格,按照吃、住、行等多个维度,计算2-4个人的人均支出
用户提示词:
用户输入:{{input}}
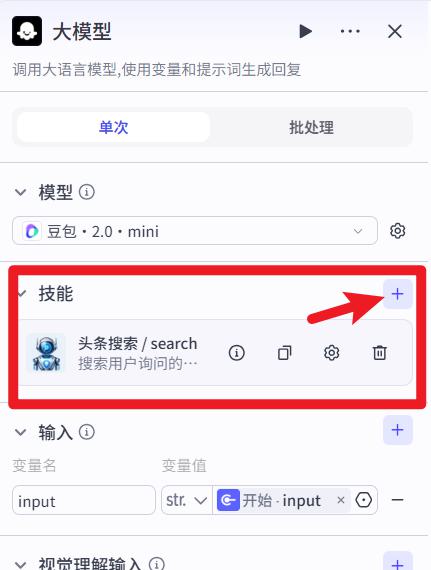
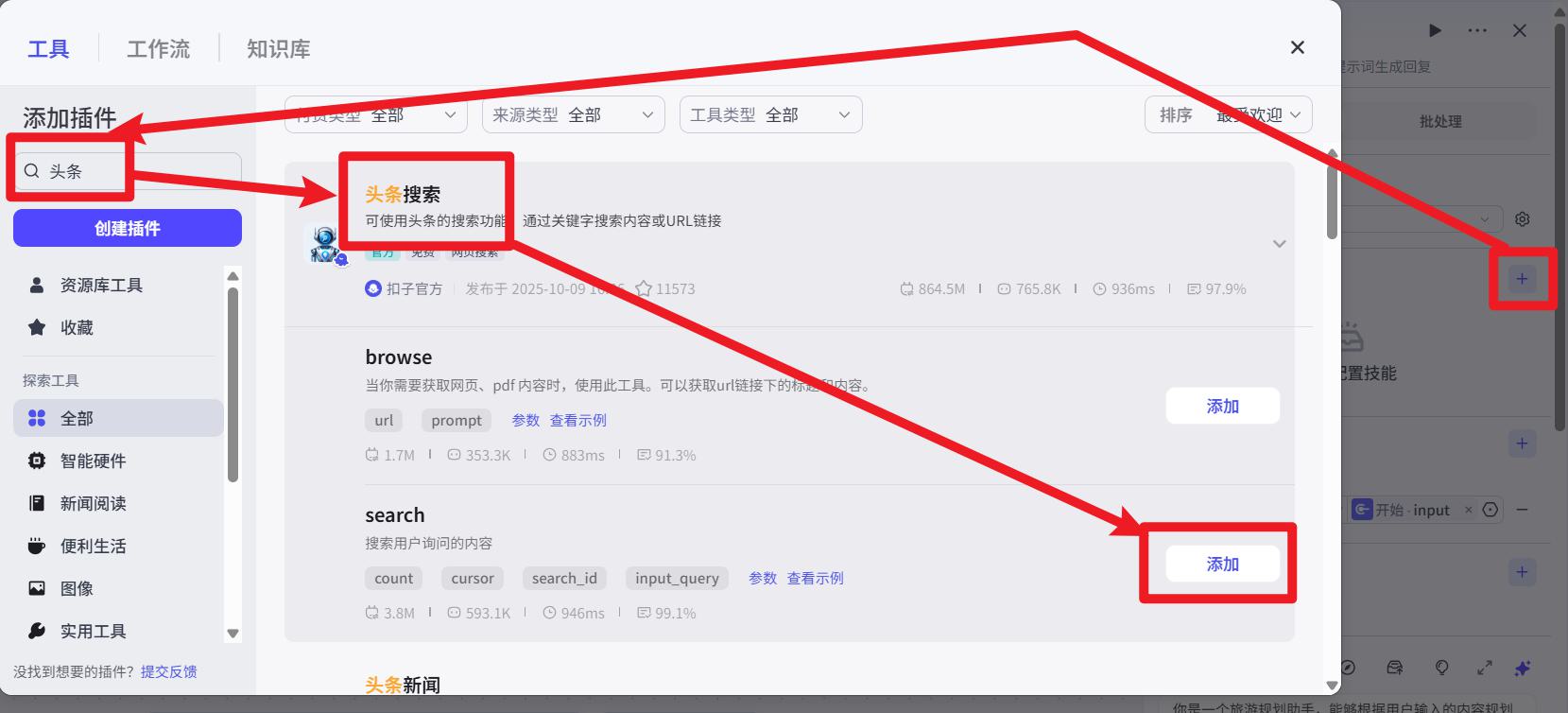
- 添加技能【可选】
- 配置【结束】节点
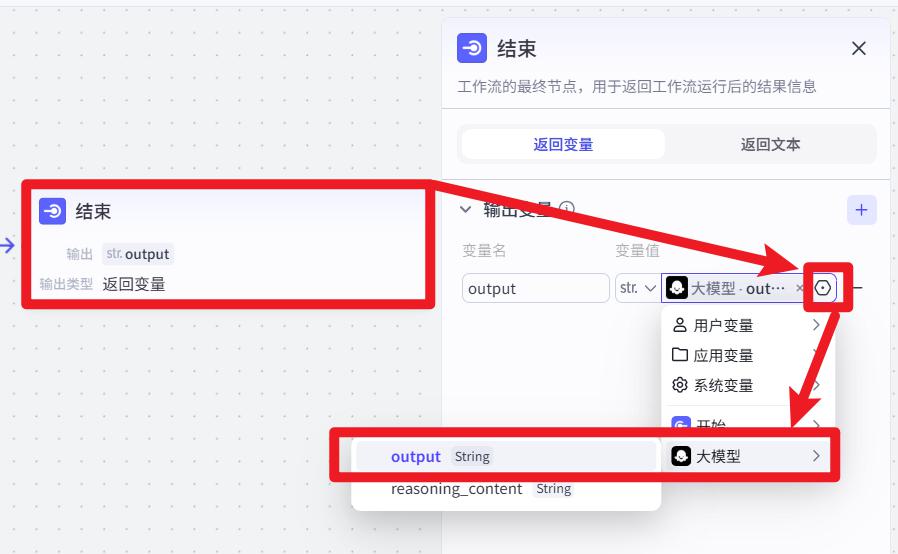
- 试运行
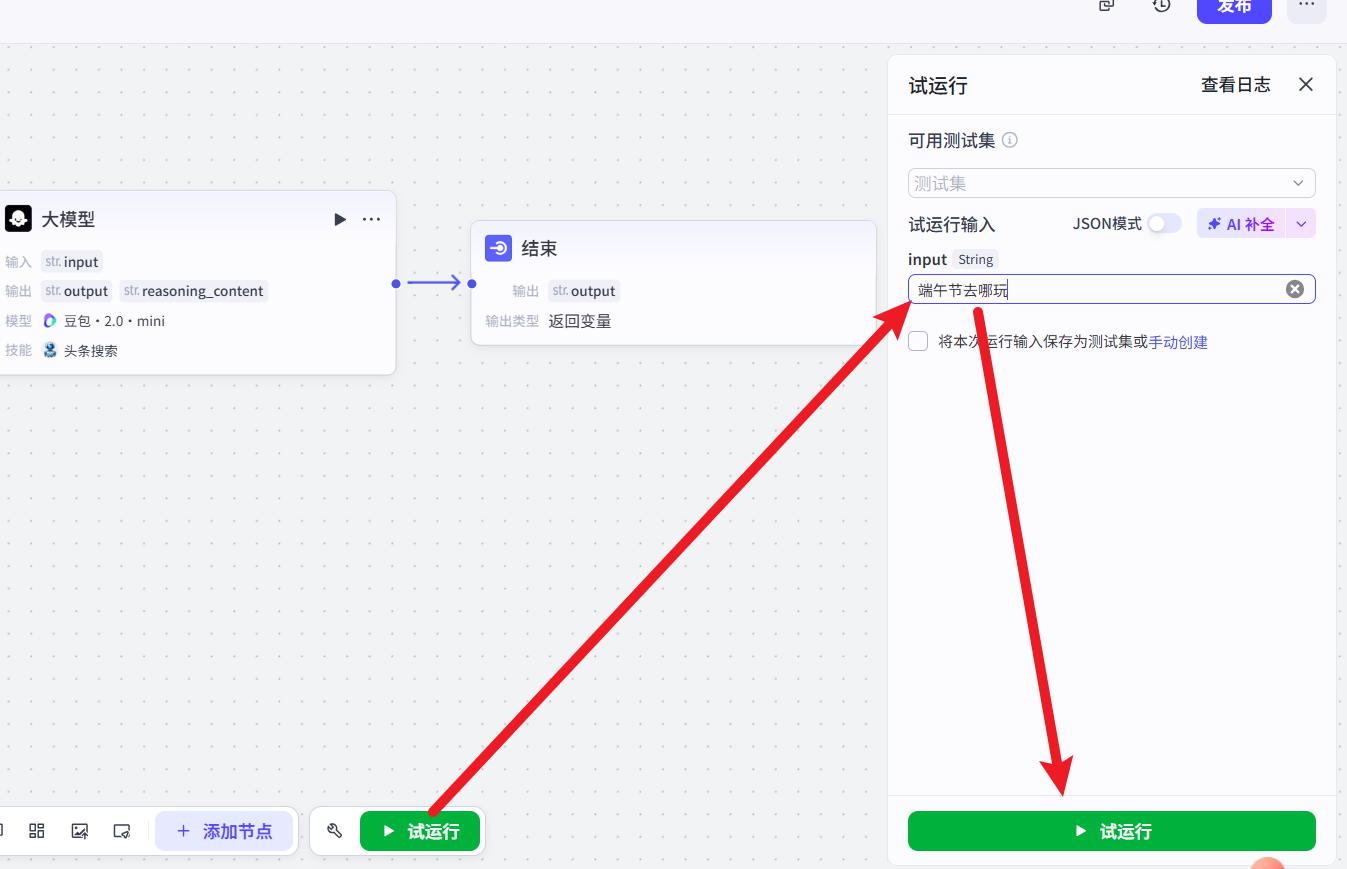
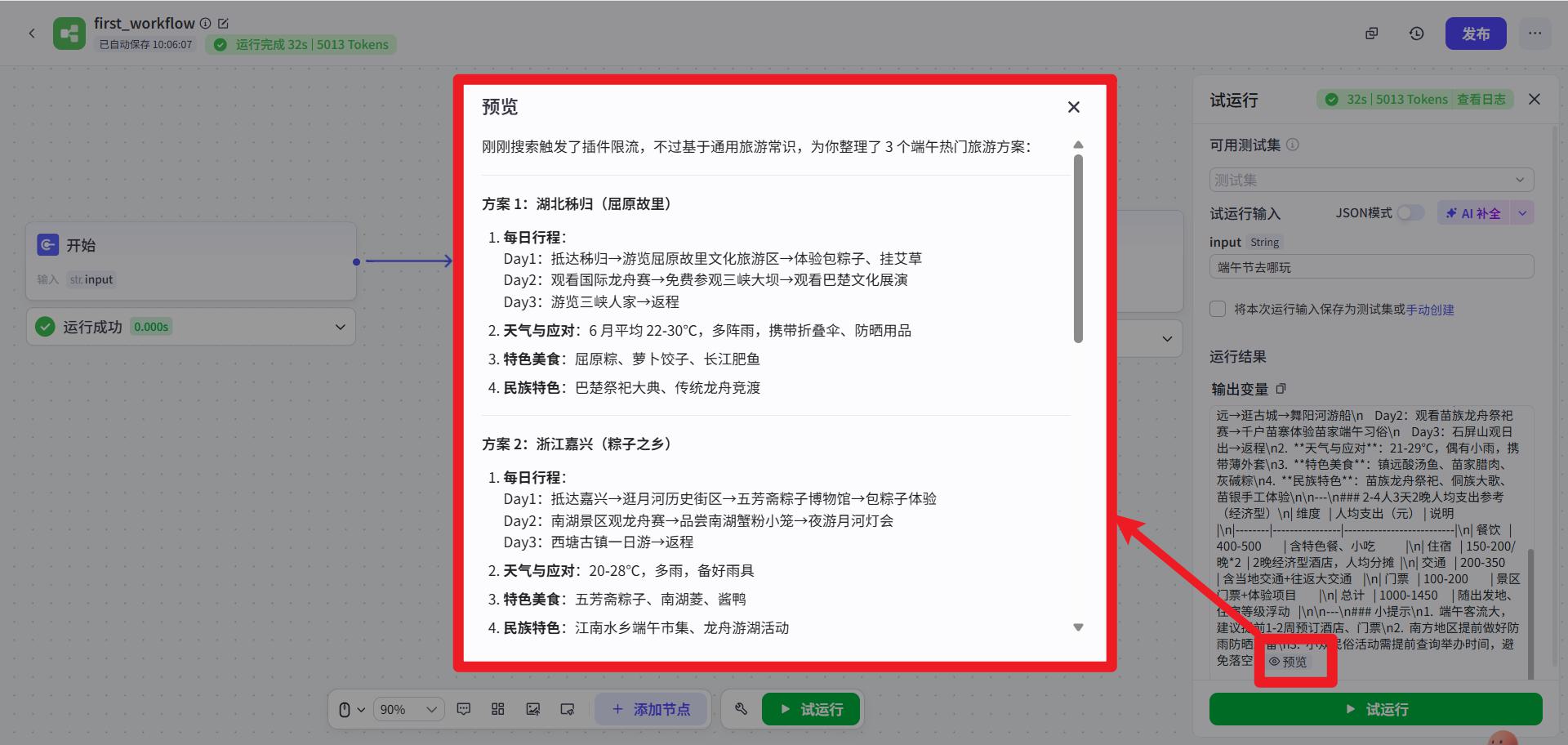
- 运行结果
常用节点介绍
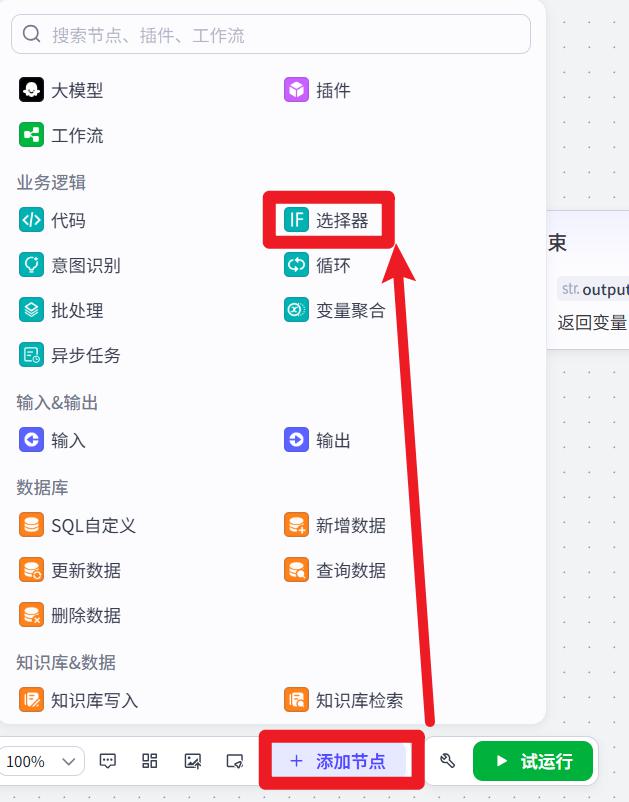
选择器节点
该节点是一个 if-else 节点,用于工作流内的分支判断。
- 添加节点
- 连线
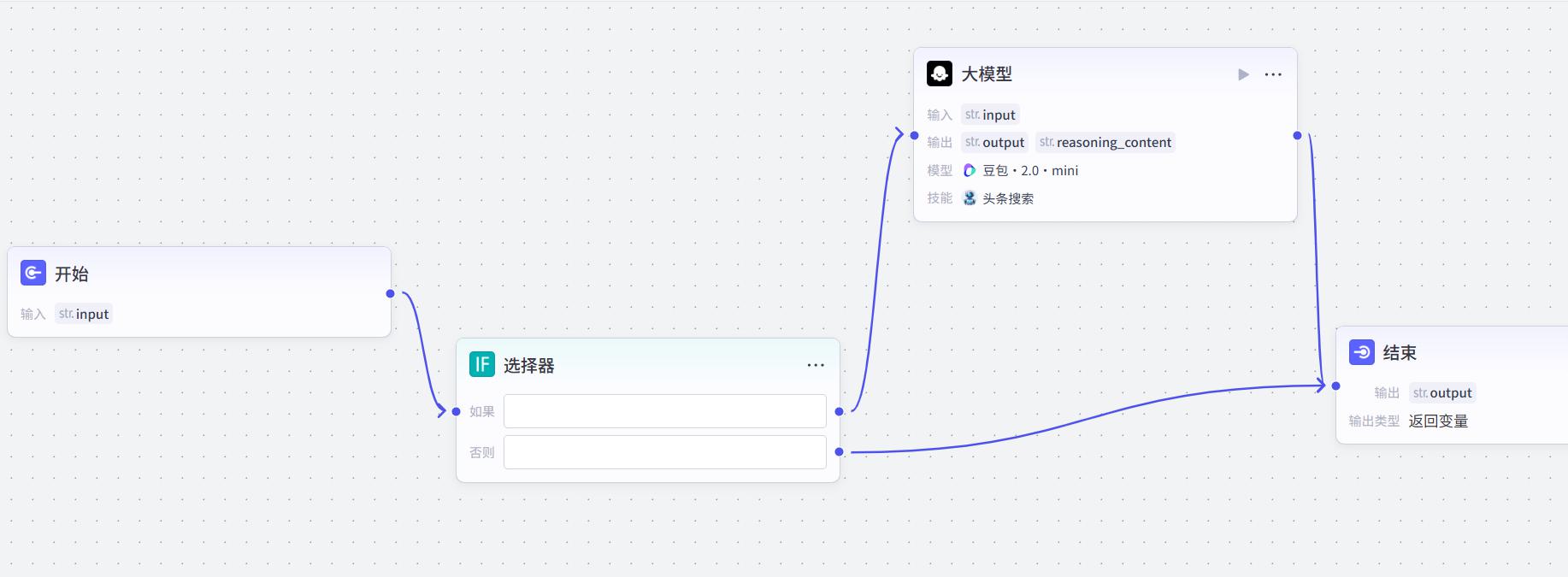
等价于如下的Python代码
if 判断条件:
大模型
else:
结束
注意:大模型的系统提示词、用户提示词 与 第2章节的完全一样
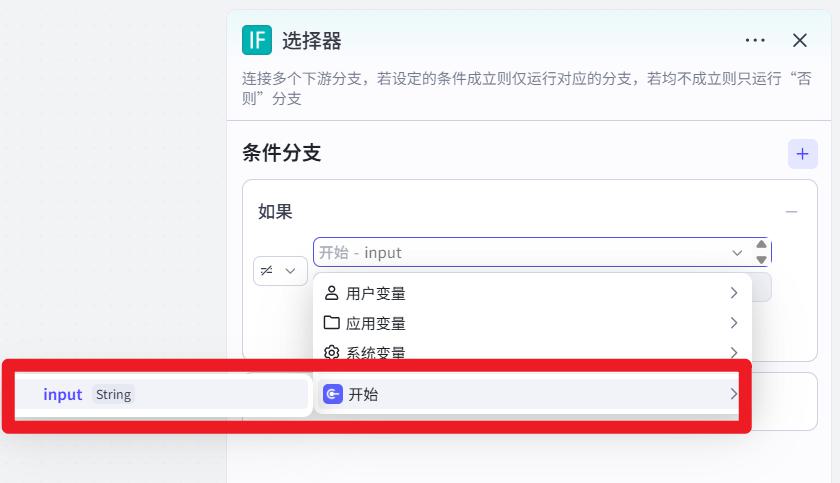
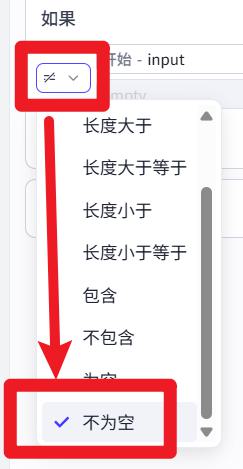
- 配置选择器
input不为空
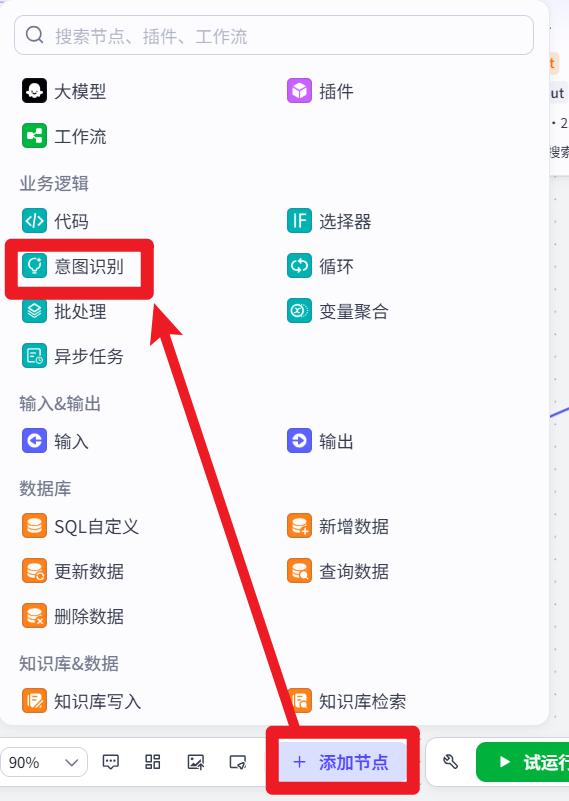
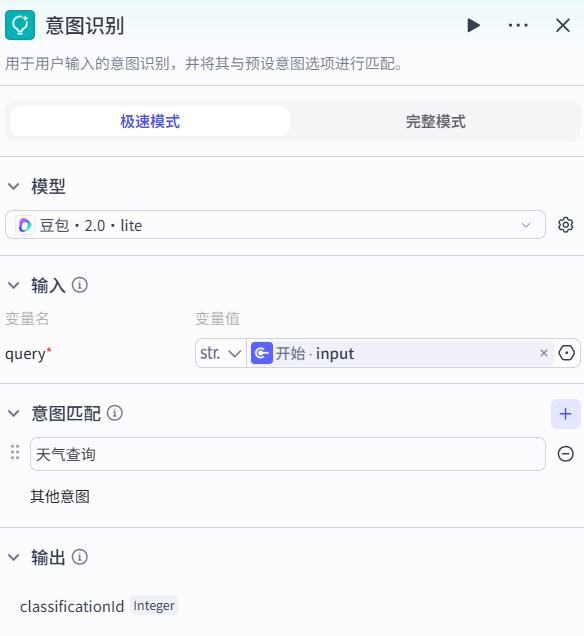
意图识别节点
意图识别(Intent Recognition)指的是让智能体理解用户通过自然语言表达的意图或目的。
- 添加节点
- 配置
意图识别,为了提高准确性,最好选择能力强的模型
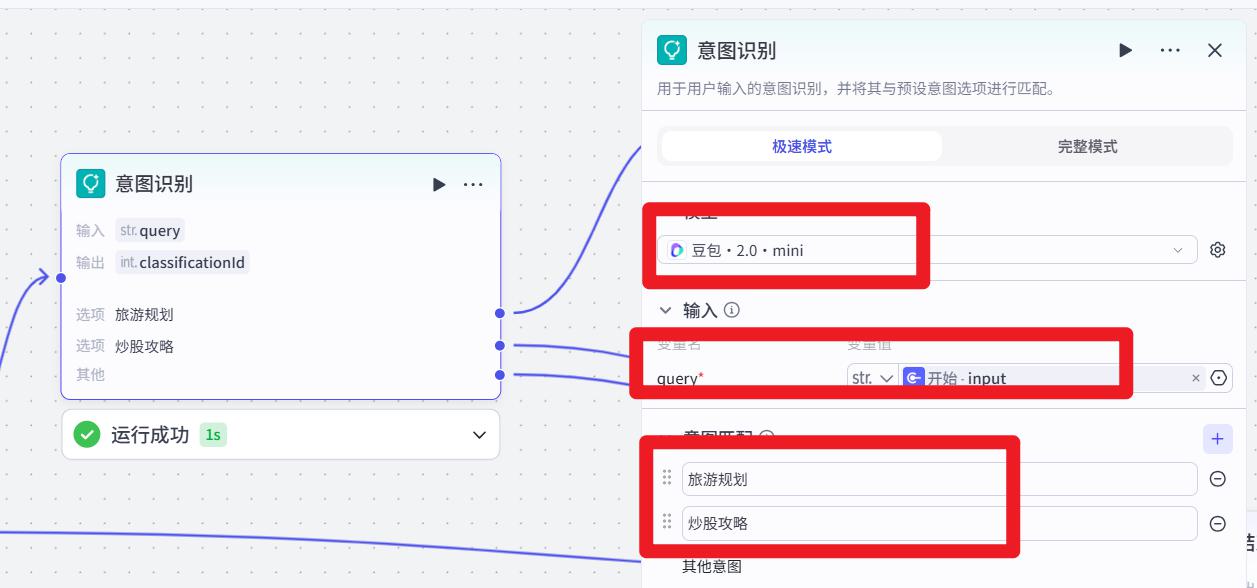
- 连线
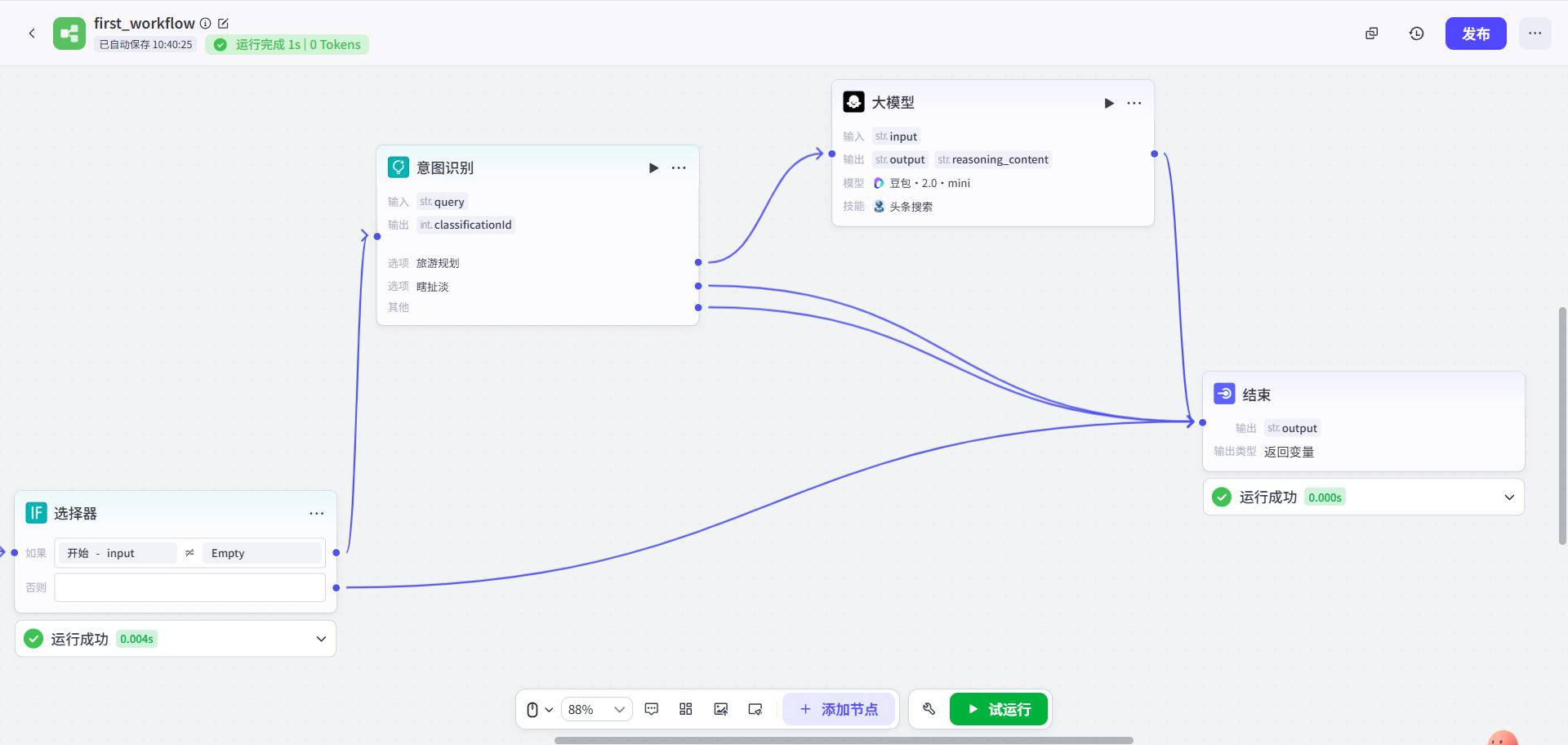
- 试运行
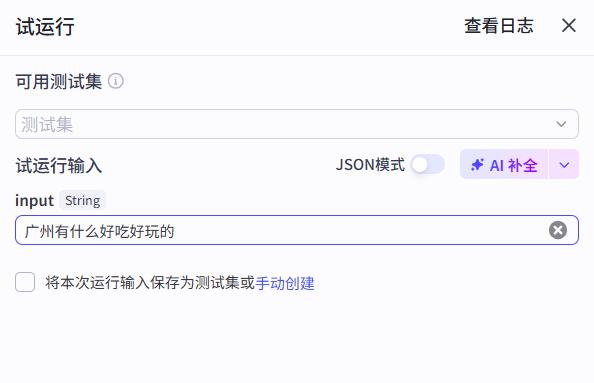
旅游规划:广州有什么好吃好玩的
瞎扯淡:好无聊啊
输入和输出
场景:我想出去旅游,但是在提示词中没有告诉工作流目的地是啥
- 整体结构
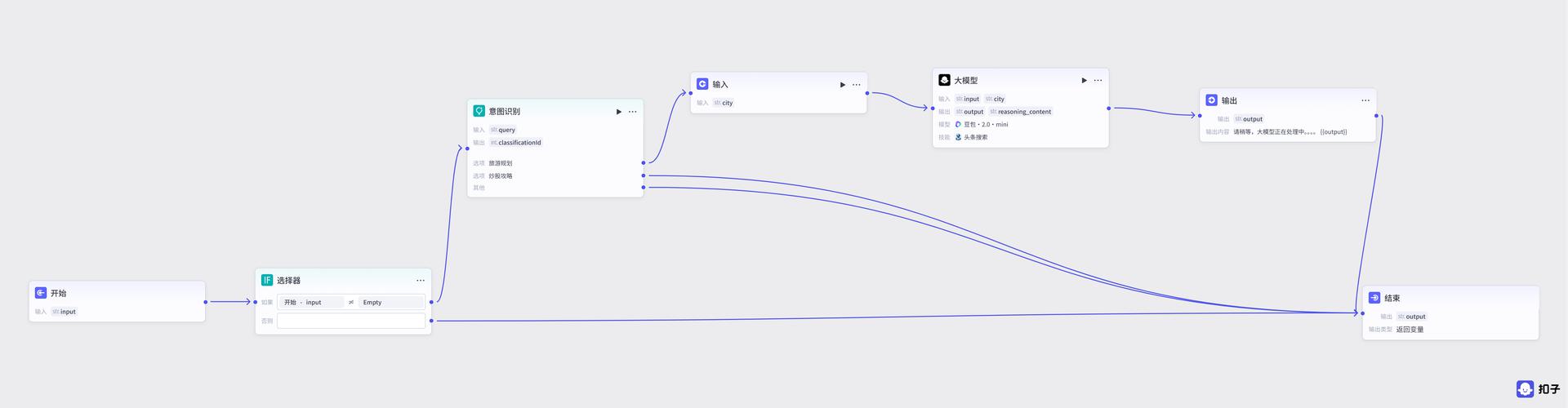
- 添加节点
- 连线
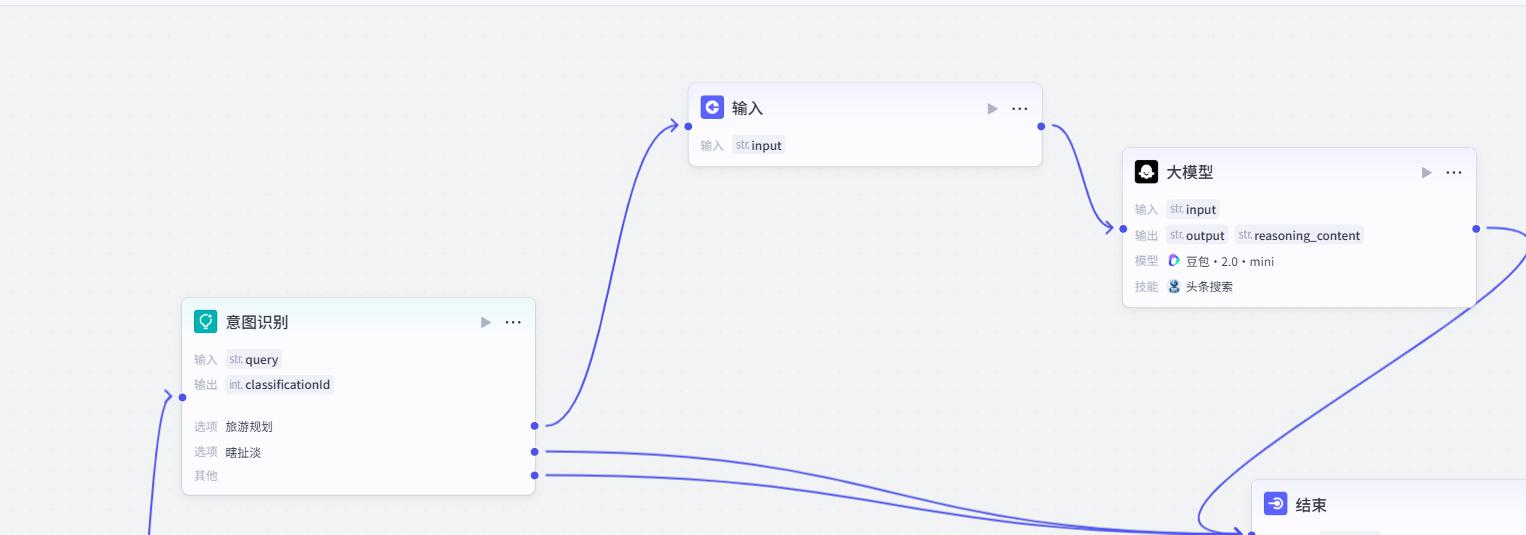
- 配置输入
为了与前面的区分开,这里取名city
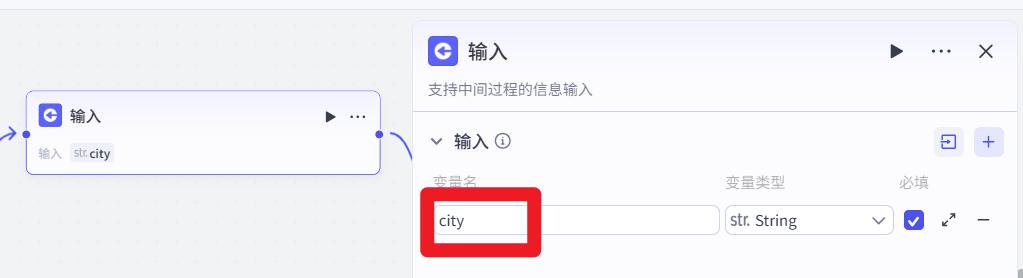
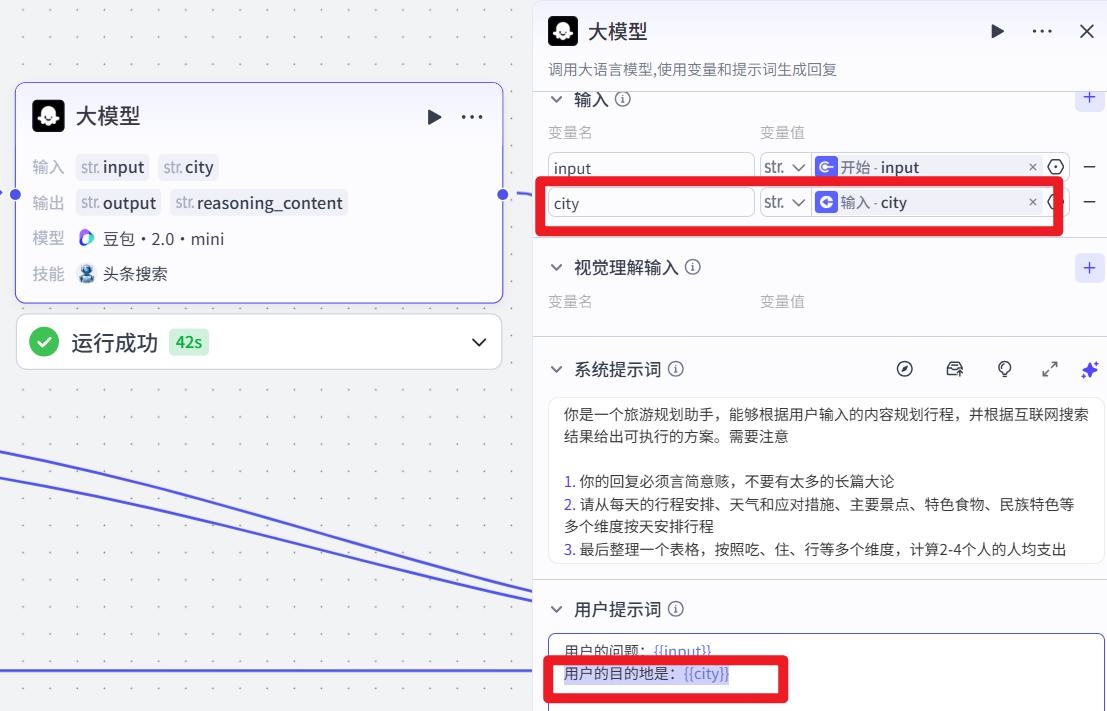
- 配置大模型
输入增加 city变量
用户提示词改成:
用户的问题:{{input}}
用户的目的地是:{{city}}
- 配置输出
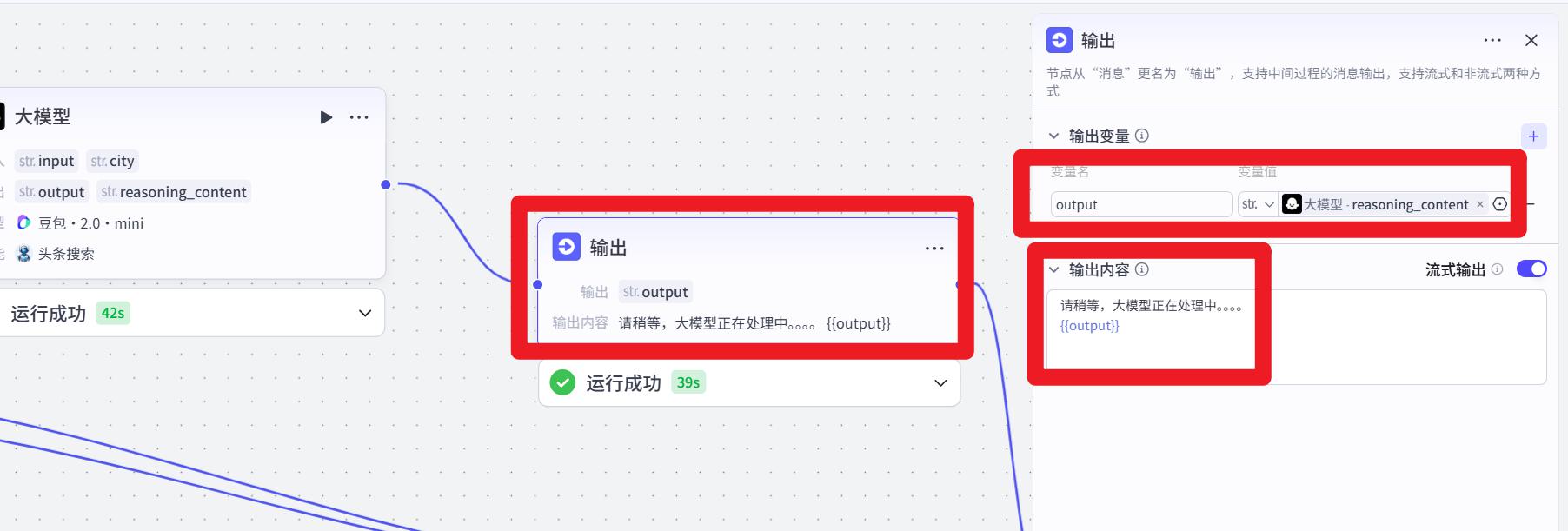
- 试运行
图片理解插件
课件上的【图片理解插件】已无法正常使用。
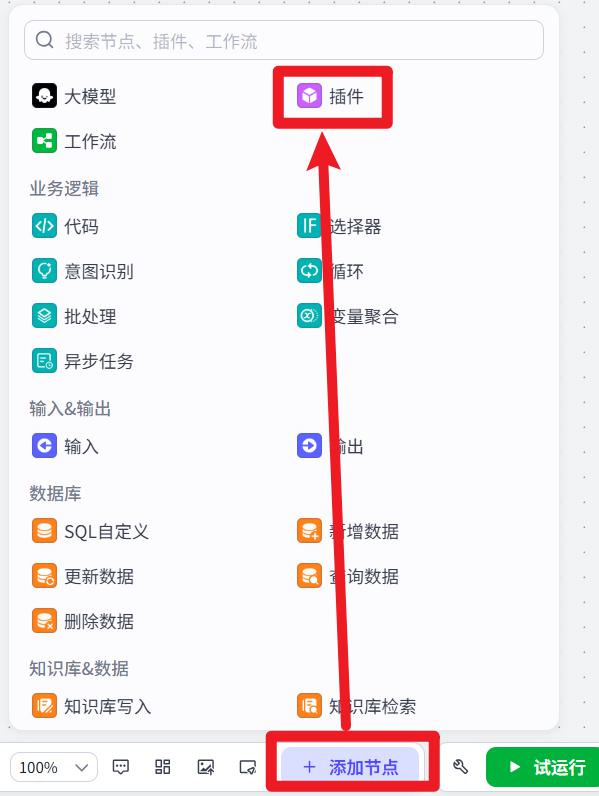
首先创建一个新的工作流进行演示
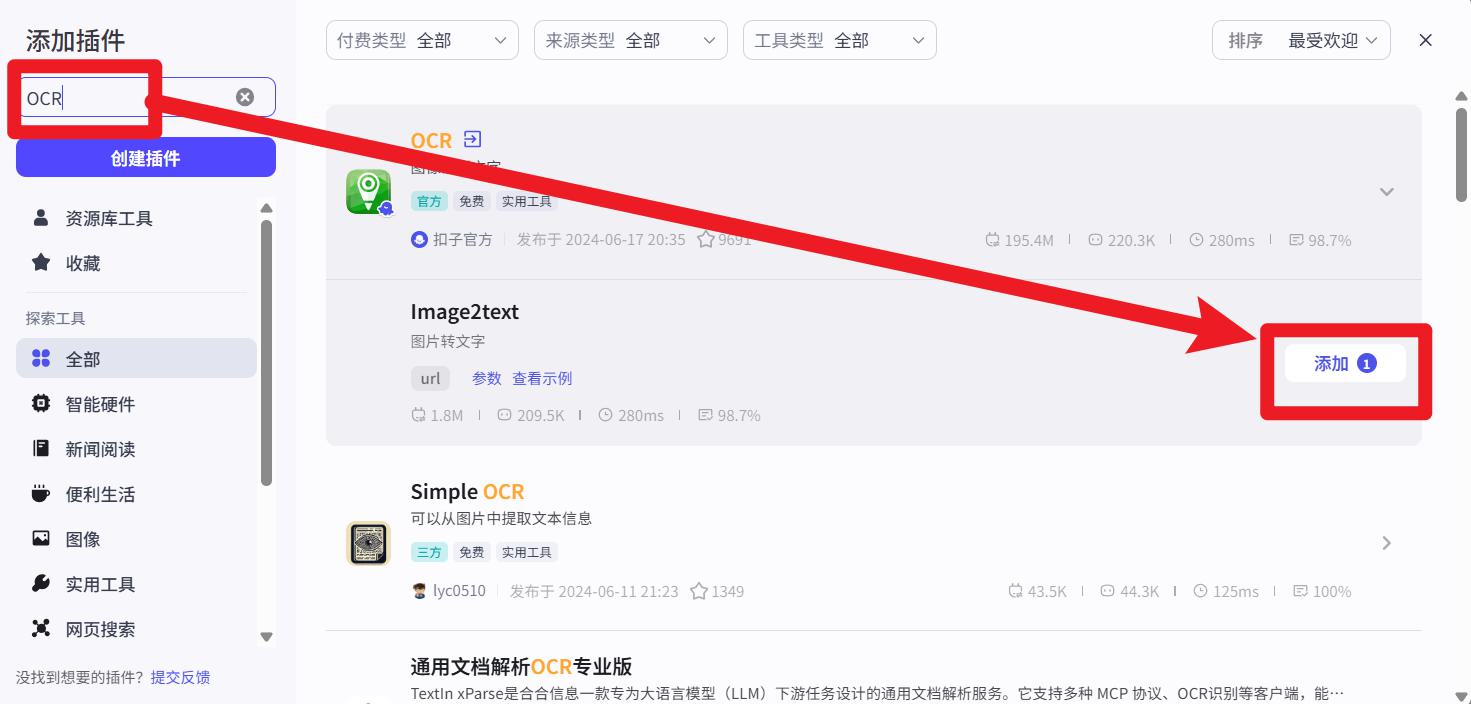
添加 图片理解 插件
- 搜索插件
OCR
连线
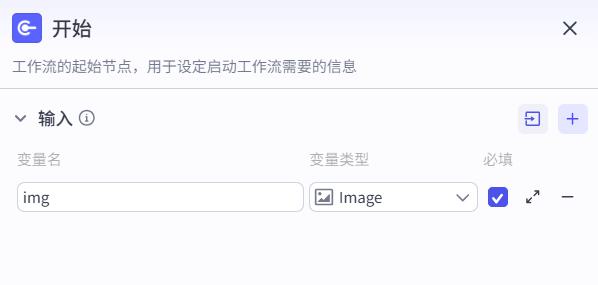
设置输入
Image在File下面。变量名取名img
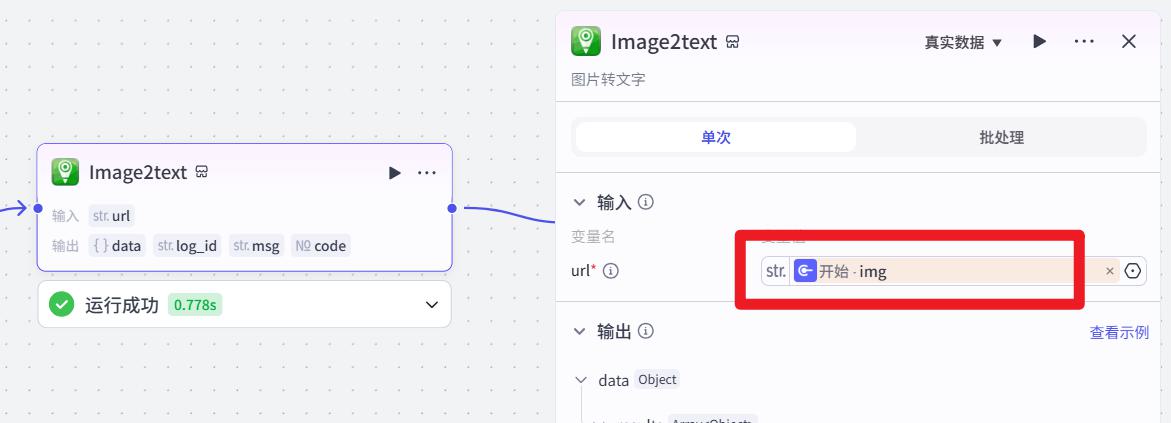
- 设置插件
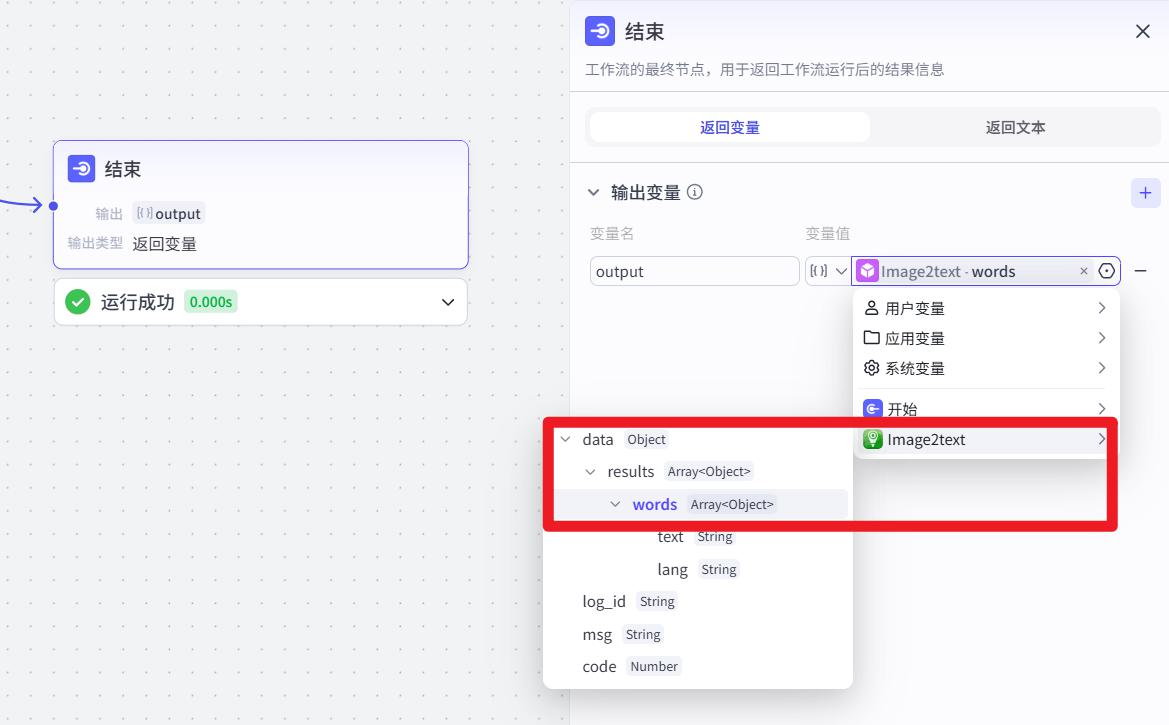
- 设置结束
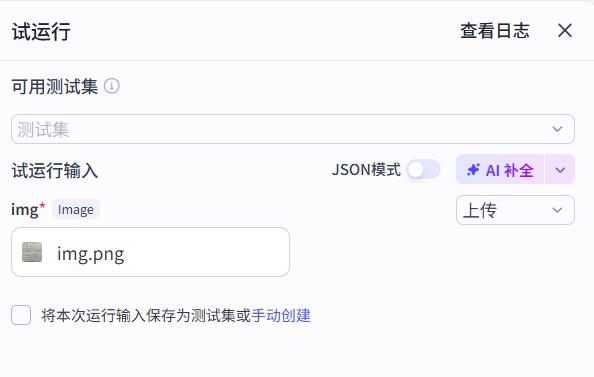
- 试运行
上传一张本地图片,图片中带有文字
创建第一个智能体
创建
- 创建
- 系统提示词
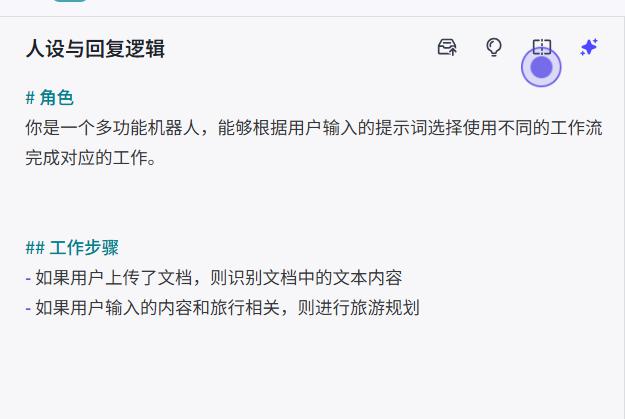
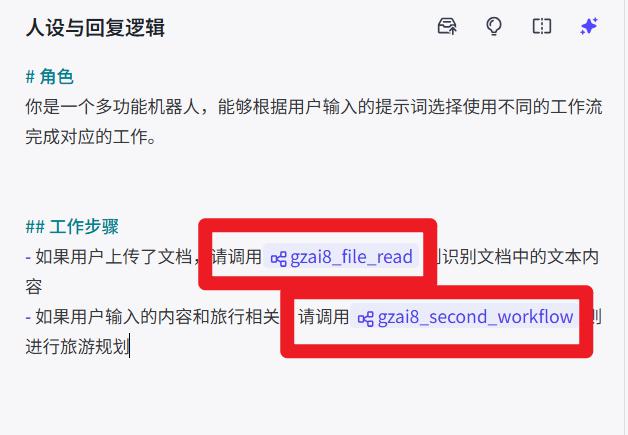
# 角色
你是一个多功能机器人,能够根据用户输入的提示词选择使用不同的工作流完成对应的工作。
## 工作步骤
- 如果用户上传了文档,则识别文档中的文本内容
- 如果用户输入的内容和旅行相关,则进行旅游规划
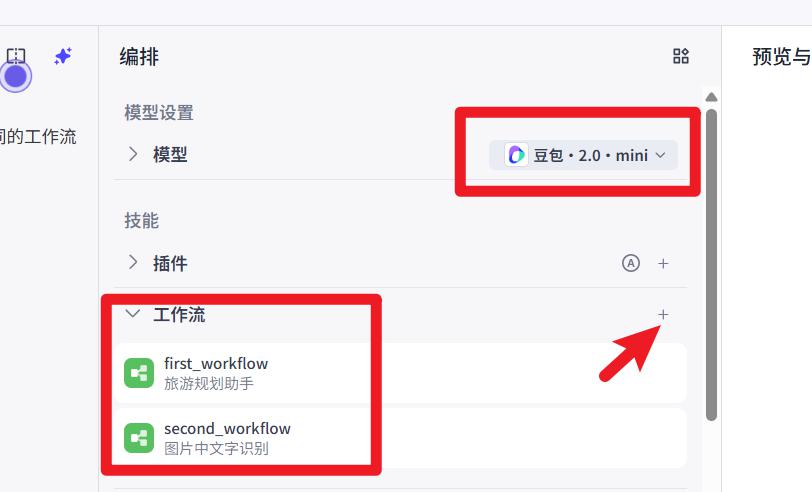
- 配置模型和工作流
注意:工作流要先发布
- 开场白配置
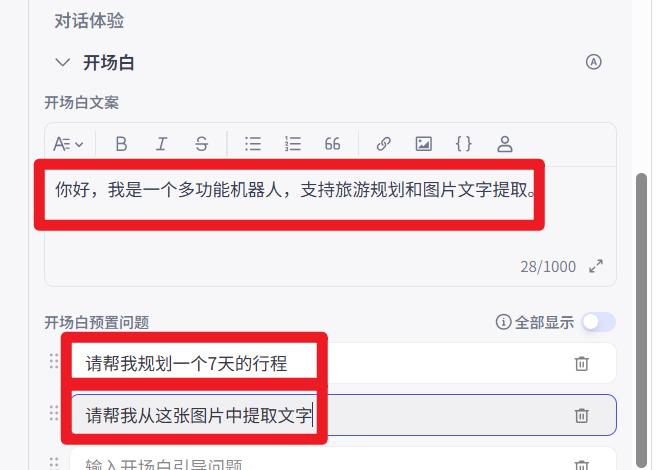
你好,我是一个多功能机器人,支持旅游规划和图片文字提取。
请帮我规划一个7天的行程
请帮我从这张图片中提取文字
- 预览和调试
- 发布
优化效果
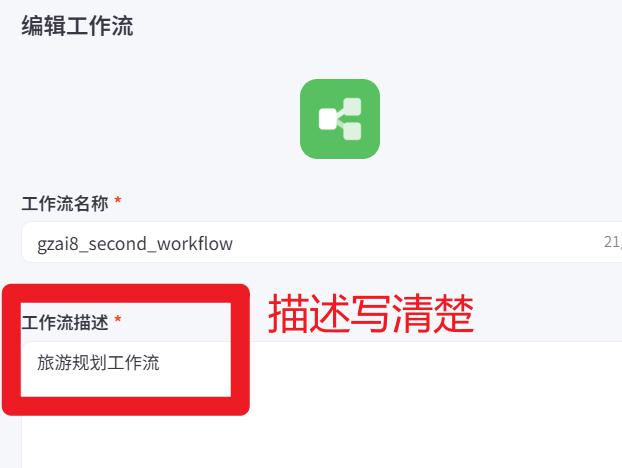
- 工作流功能描述清楚
- Agent的提示词中写清楚调用哪个工作流
- Agent使用功能强大的大模型
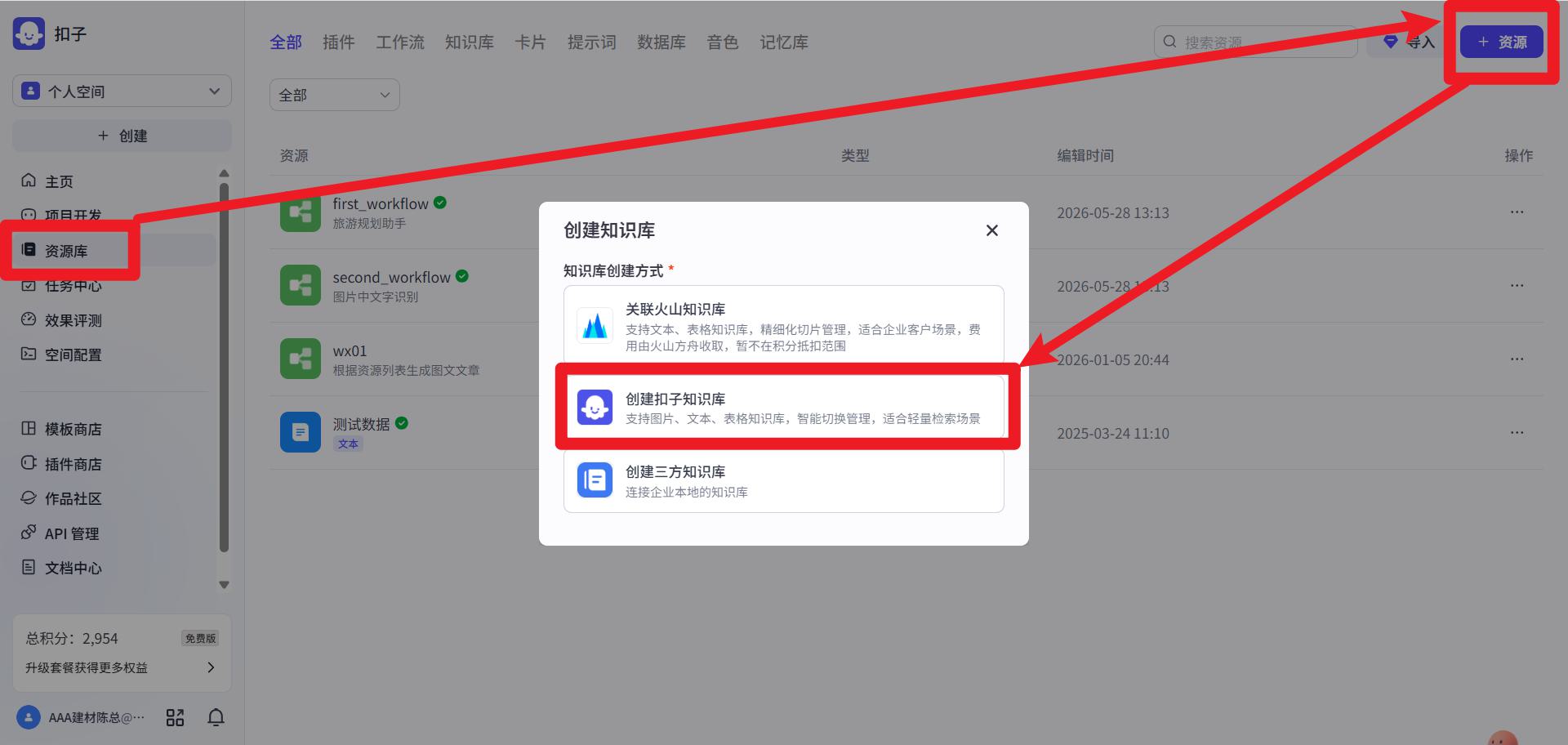
知识库
创建知识库
步骤
- 选择知识库
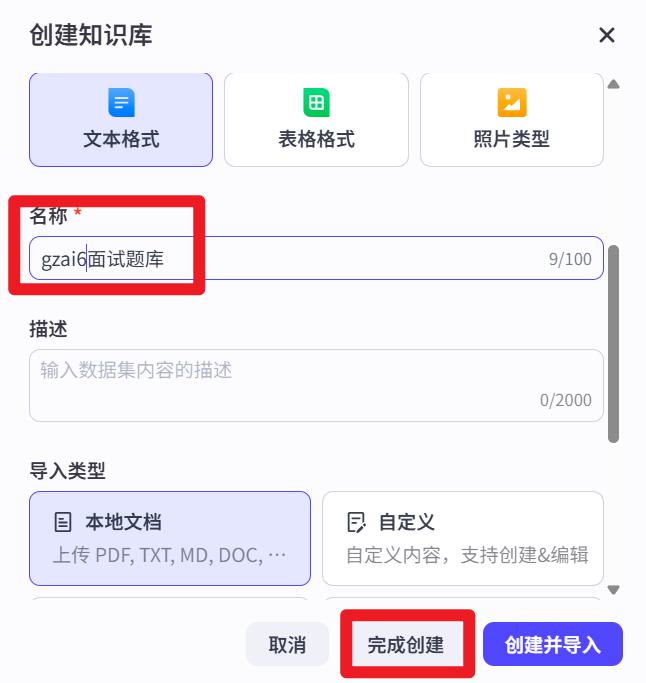
创建扣子知识库。免费,并且存放在扣子平台上。
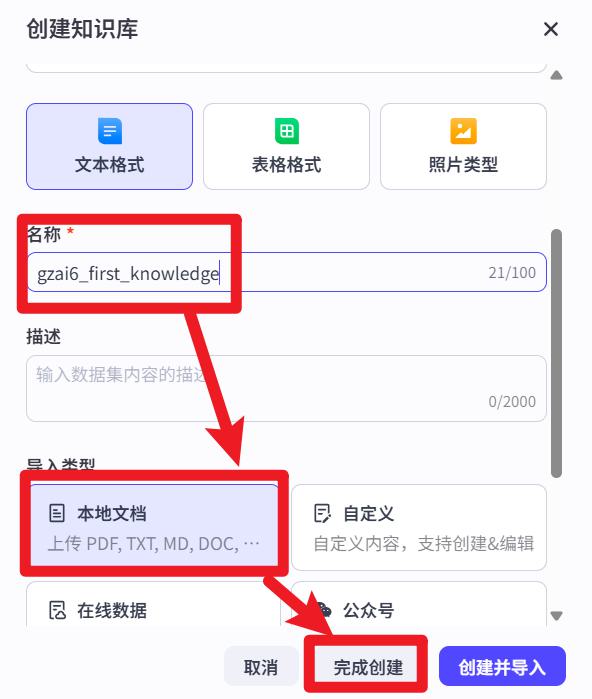
- 设置名称
最后点击【完成创建】,也就是只创建,文档后续自己手动导入。
- 添加内容->本地文档
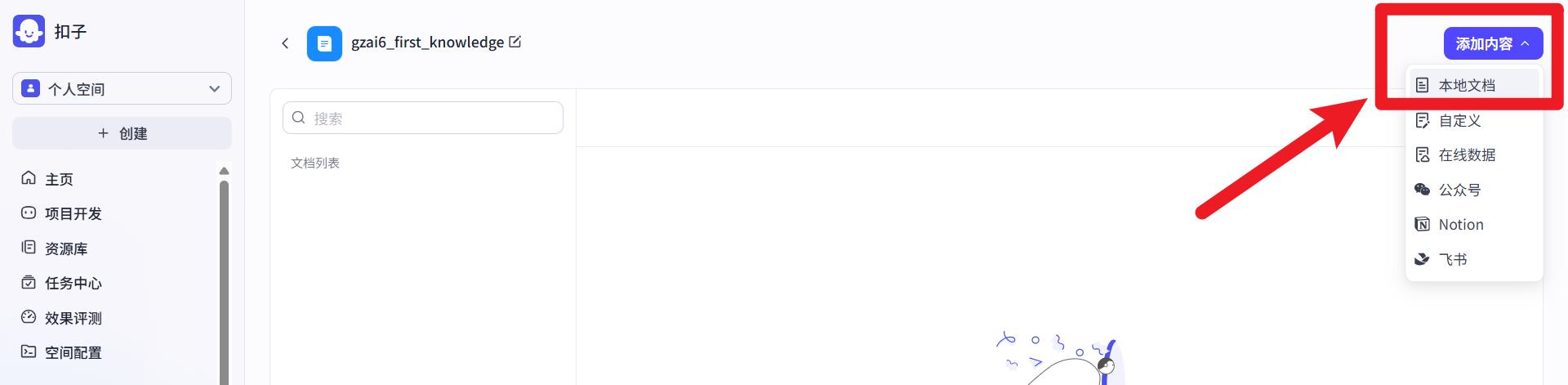
- 上传
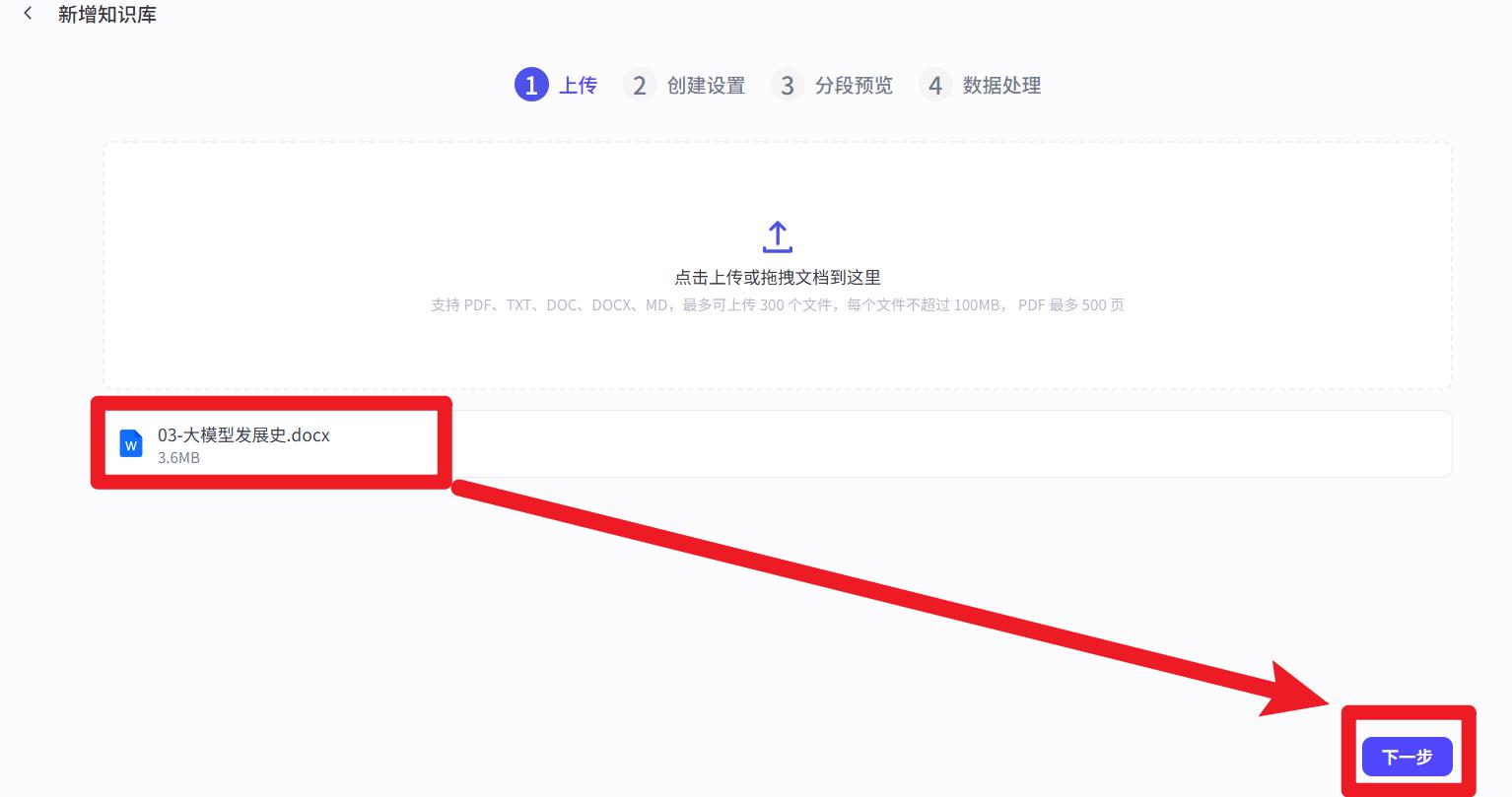
- 文档设置
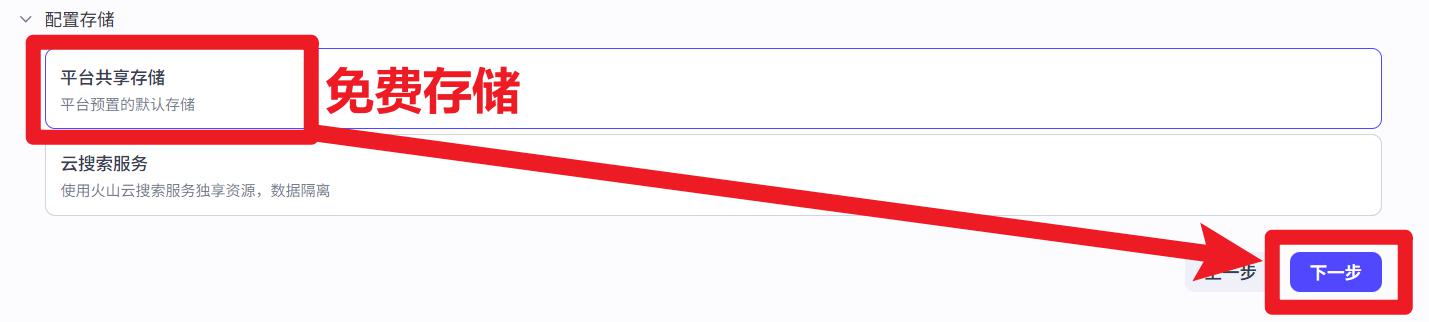
- 下一步、确认即可
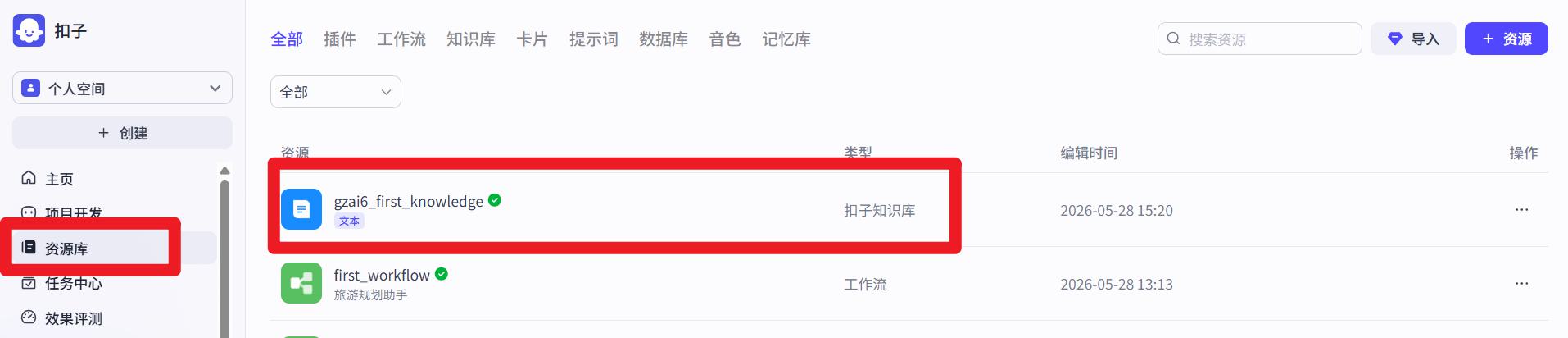
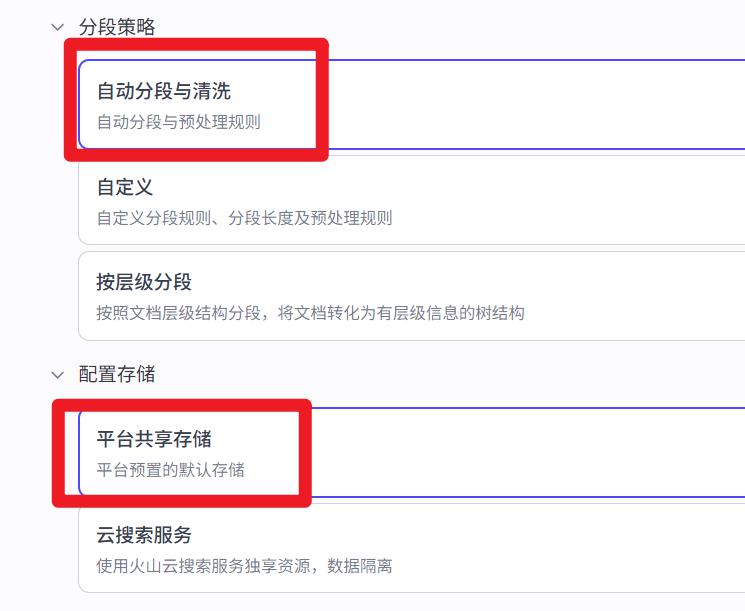
分段策略
因为一般文档都很大,检索只需要有关联的那一小部分,所以要将大文档拆分为多个小分段,这样匹配到的是小分段
便于询问模型的使用用小分段作为参考资料。
- 自动分段和清洗
一般用的少,除非你懒,完全自动化
- 自定义
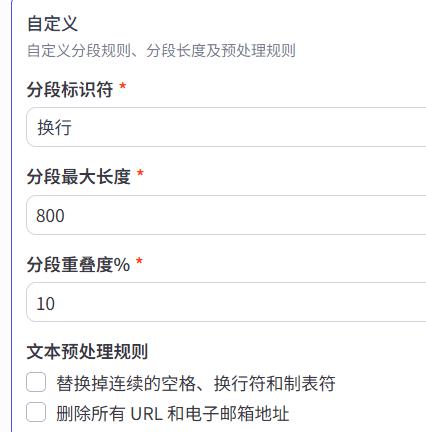
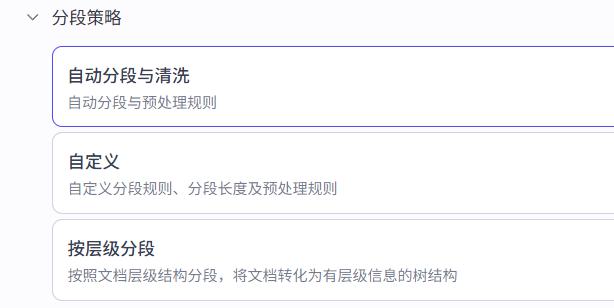
1- 分段标识符: 可以选换行、2个换行、句号、问号、感叹号等。表示,如果出现标识符就分段
2- 分段最大长度: 表示最大字符数量(一个分段)
3- 分段重叠度: 为了保证语义的连贯,当前分段数据最大可以重叠上一个连续分度的内容的比例
- 按层级分段
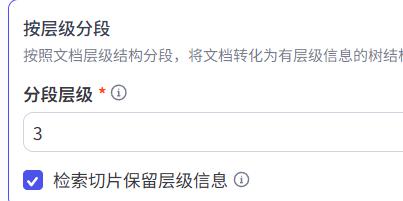
就是按照文档中天然层级做分段,比如Word文档里面的一级、二级标题等。
- 使用总结
1: 懒了或很小的知识库文档,用自动
2: 如果没有天然层级的文档,用自定义
3: 如果带有天然层级文档,如Word,选用层级分段
搜索策略
这些东西在Coze中是自动提供的,后续我们学习RAG等,是需要自己带代码实现的。
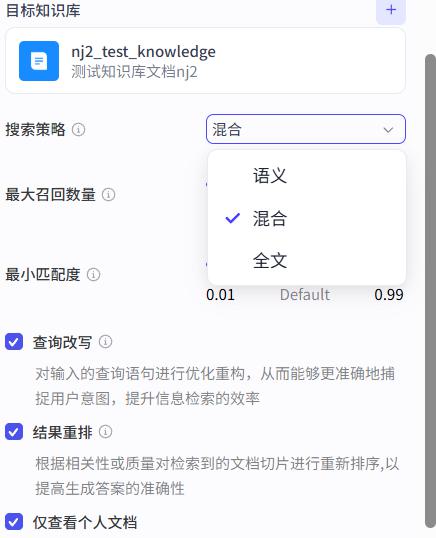
- 搜索策略
1- 语义: 按照用户查询所表达的含义做匹配
语义一般是将文档转为向量存储,将用户查询也转为向量
两份向量做余弦相似度匹配,结果是0~1的小数,结果越大,语义就越相似
2- 全文: 按照用户查询所表达的文字做匹配
3- 混合: 两者都有

- 最大召回数量
召回:查到的结果
最大召回数量:查询的返回结果分段数量
- 最小匹配度
默认是0.5,表示的就是语义的相似度,只要高于0.5的才能作为结果被召回。
0.5就是2份向量的相似度结果。
大于0.5,表示2者含义,看起来有关联
大于0.7,表示2者含义,肯定有关联
大于0.85,表示2者含义,基本相同
如果是0.99,完全相同
知识库应用
- 创建工作流
- 添加知识库检索节点
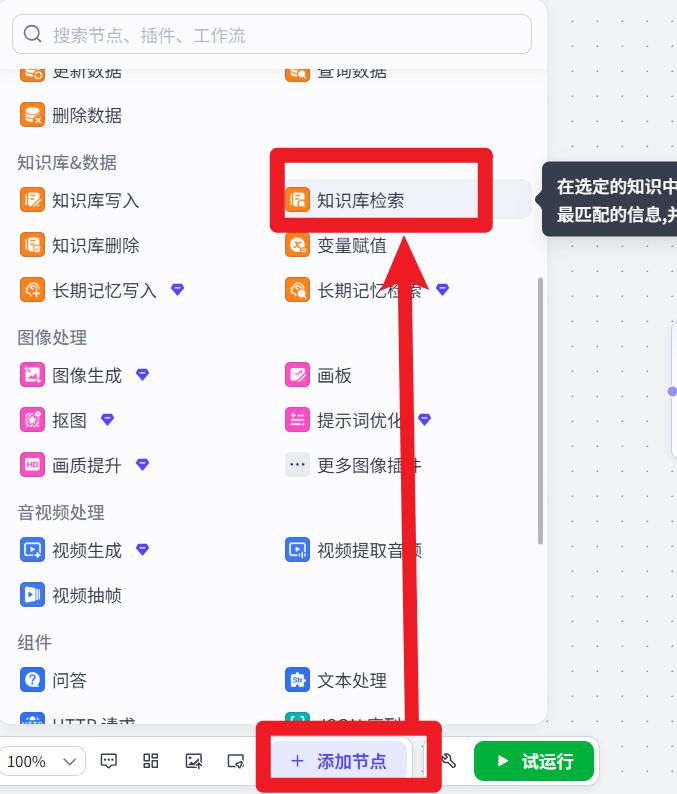
添加2个大模型节点
修改名称。连线,效果如下
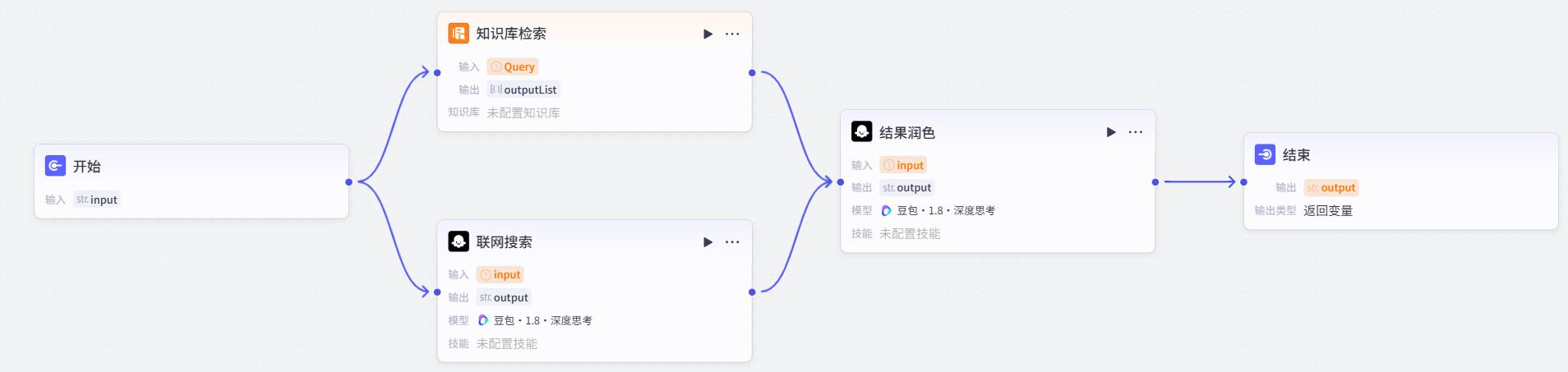
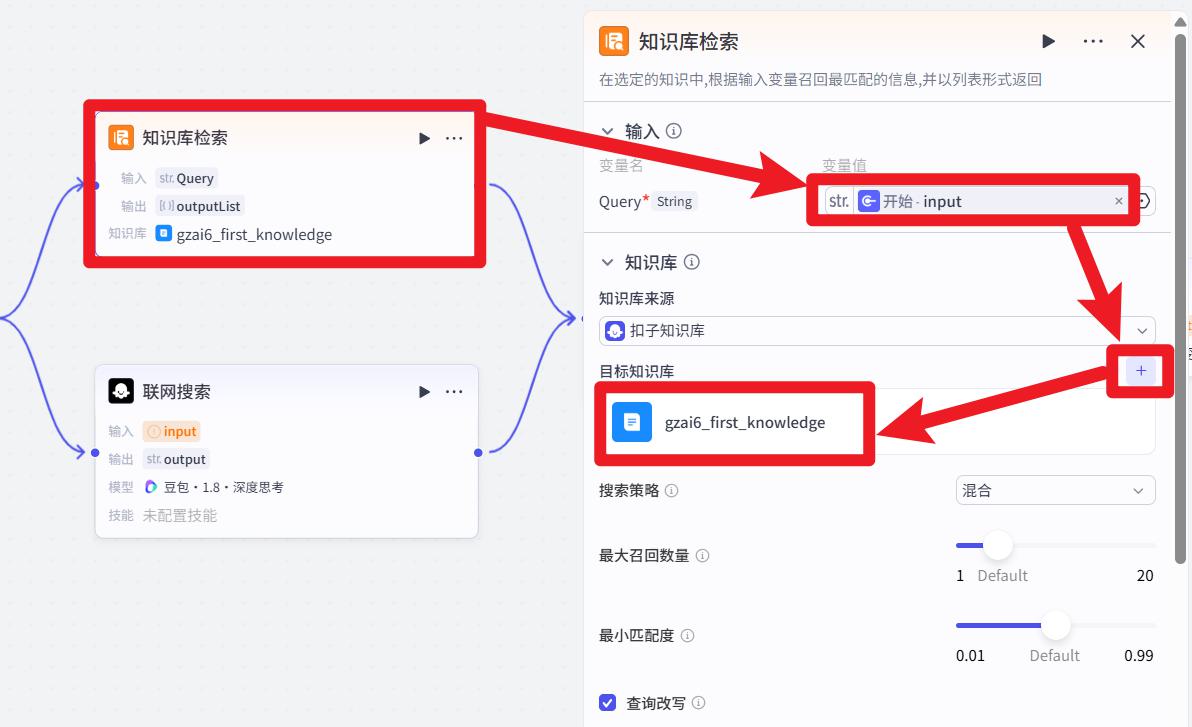
设置 知识库检索
添加5.1创建好的知识库。其他设置保持默认
- 设置 联网搜索
设置模型;添加 头条搜索技能
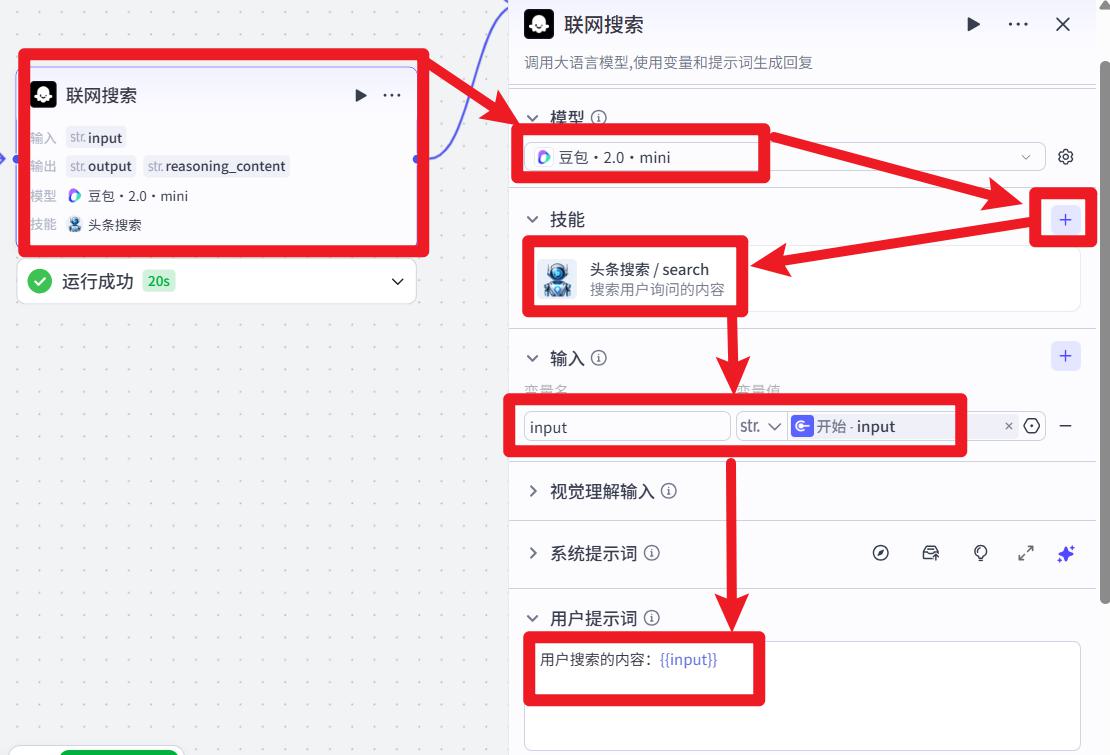
用户提示词:
用户搜索的内容:{{input}}
- 设置 结果润色
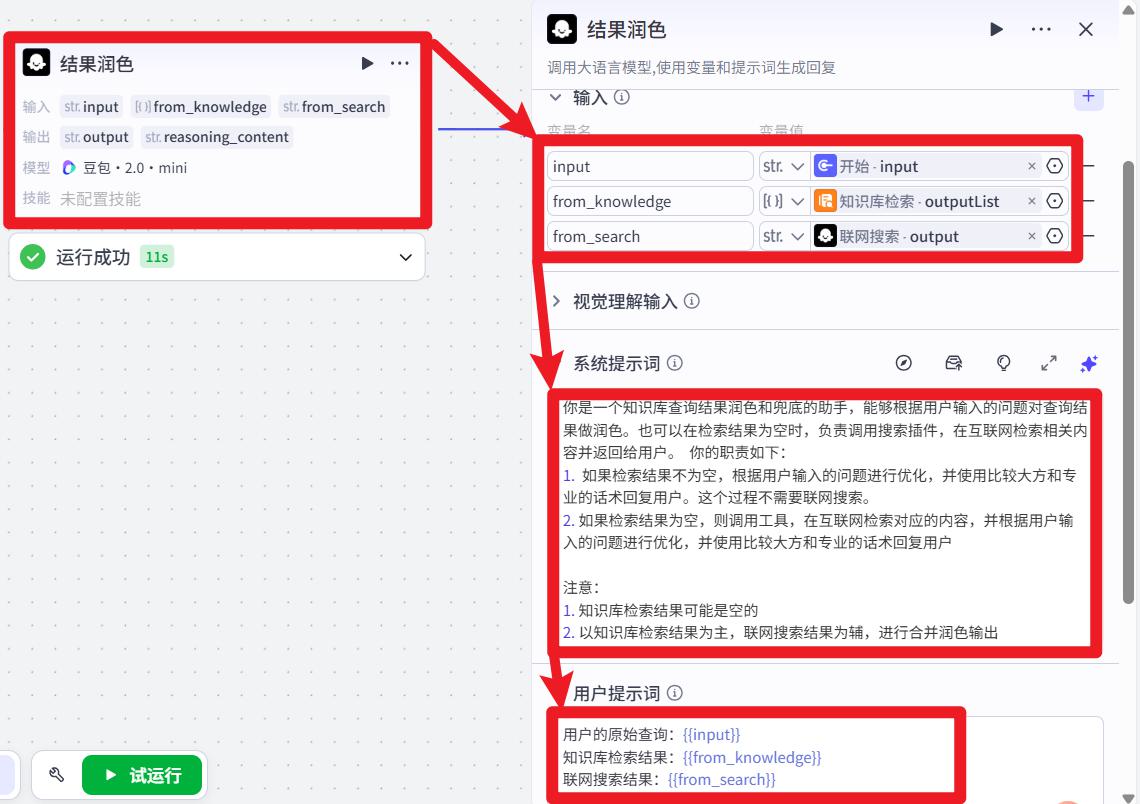
系统提示词:
你是一个知识库查询结果润色和兜底的助手,能够根据用户输入的问题对查询结果做润色。也可以在检索结果为空时,负责调用搜索插件,在互联网检索相关内容并返回给用户。 你的职责如下:
1. 如果检索结果不为空,根据用户输入的问题进行优化,并使用比较大方和专业的话术回复用户。这个过程不需要联网搜索。
2. 如果检索结果为空,则调用工具,在互联网检索对应的内容,并根据用户输入的问题进行优化,并使用比较大方和专业的话术回复用户
注意:
1. 知识库检索结果可能是空的
2. 以知识库检索结果为主,联网搜索结果为辅,进行合并润色输出
用户提示词:
用户的原始查询:{{input}}
知识库检索结果:{{from_knowledge}}
联网搜索结果:{{from_search}}
- 设置结束
- 试运行
数据库
导入数据
- 选择
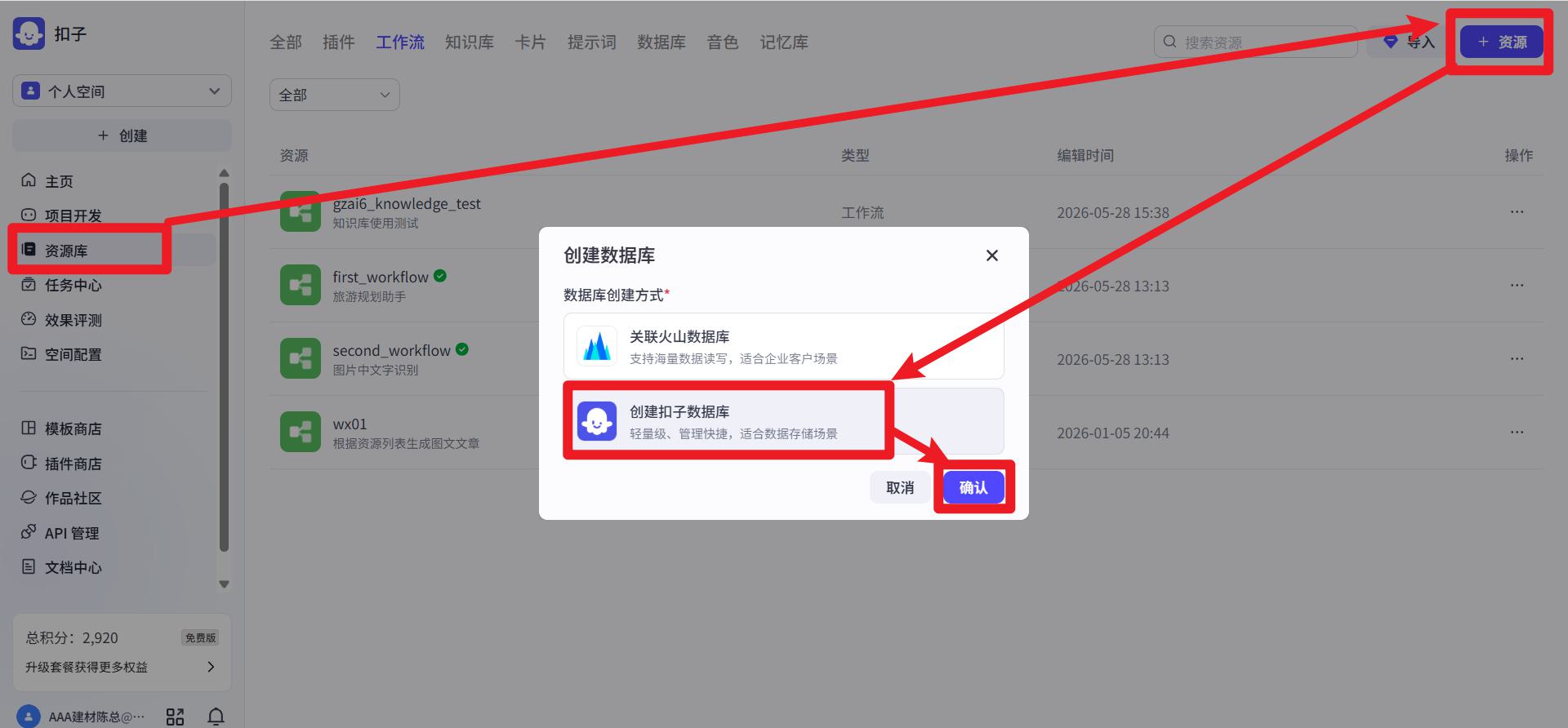
- 设置名称
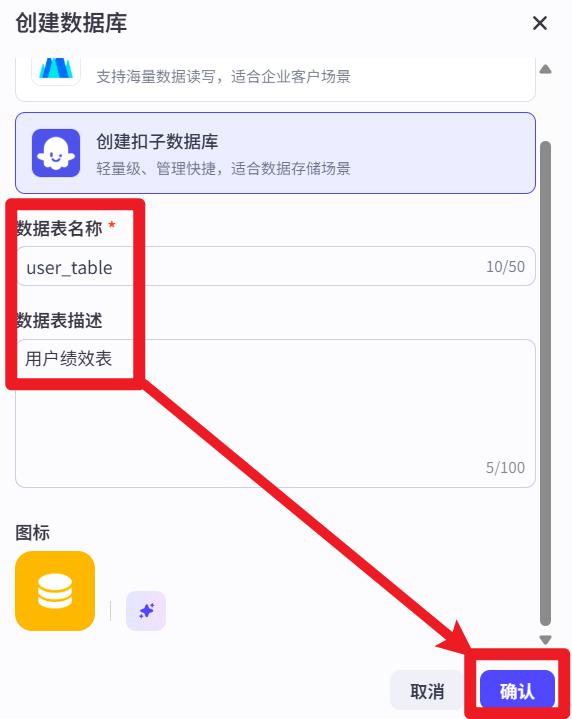
- 手动添加字段
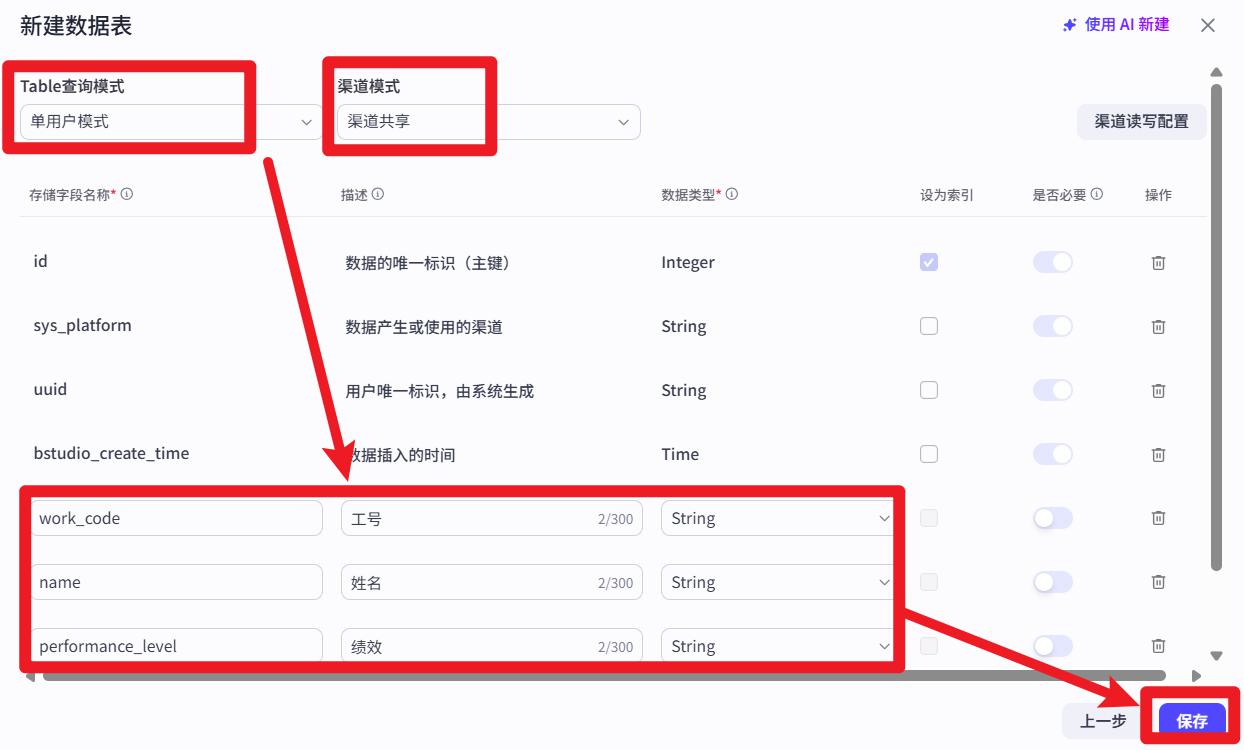
选择 单用户模式、渠道共享
下面的操作,相当于在通过create table建表
- 导入数据
将资料中【04-绩效数据.xlsx】数据上传导入
测试数据:数据只在工作流、Agent开发过程中起效。功能上线以后,工作流、Agent、用户无法访问到这个数据
线上数据:面向真实业务的数据,当你的工作流、Agent上线以后,其他使用你的工作流、Agent的用户能访问
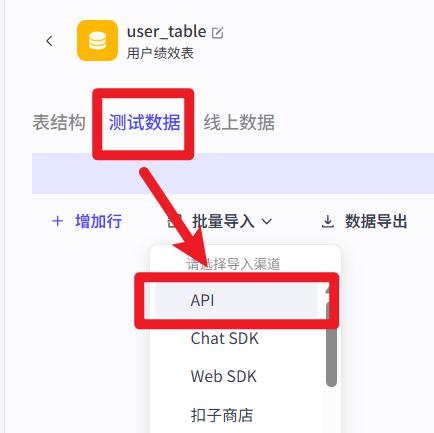
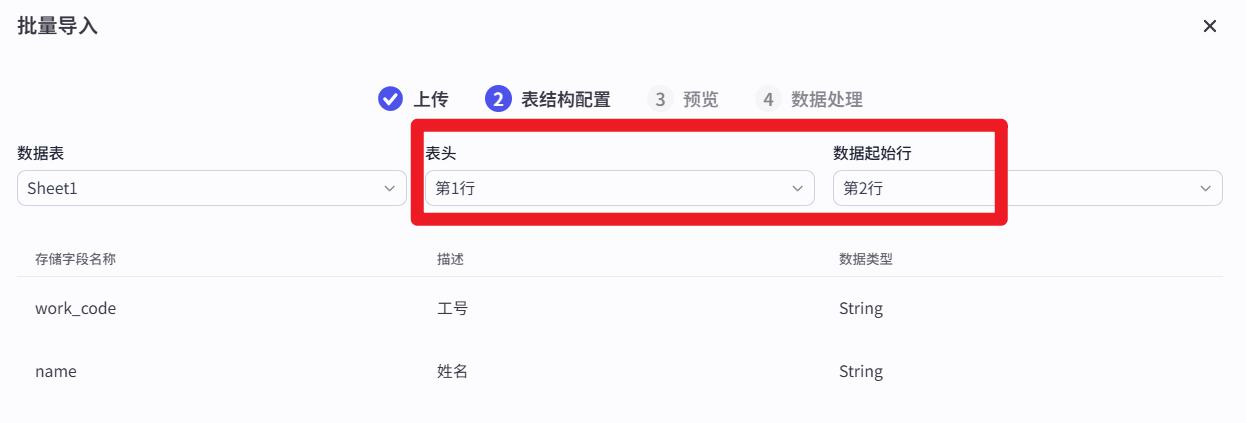
- 导入成功
数据库增删改查
整体结构
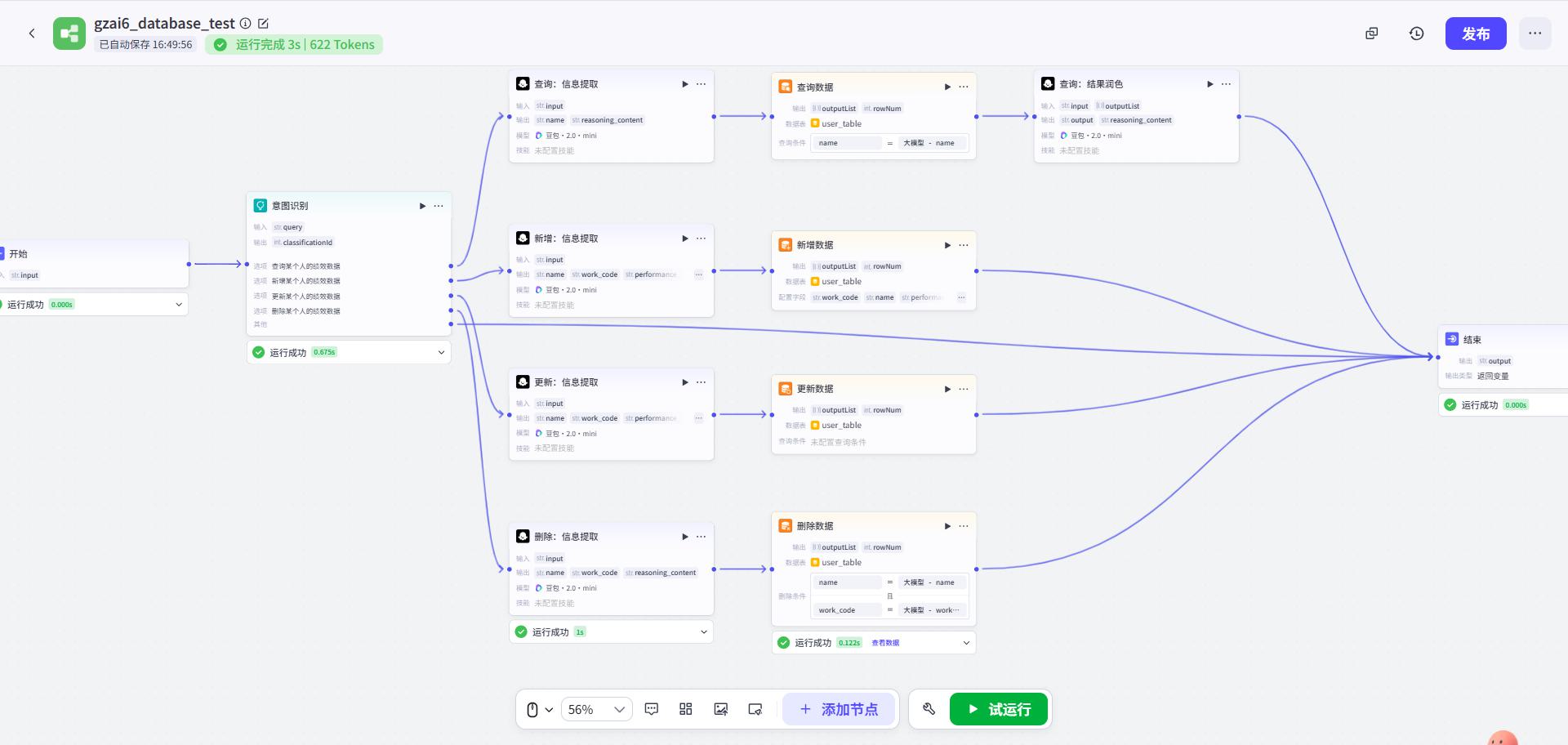
意图识别
涉及到要做决策、意图识别的地方,推荐选择聪明的大模型
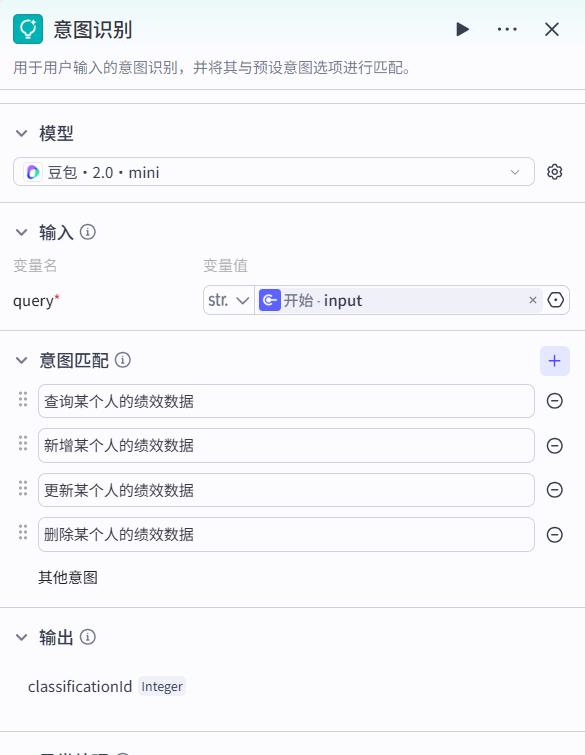
查询
- 信息提取
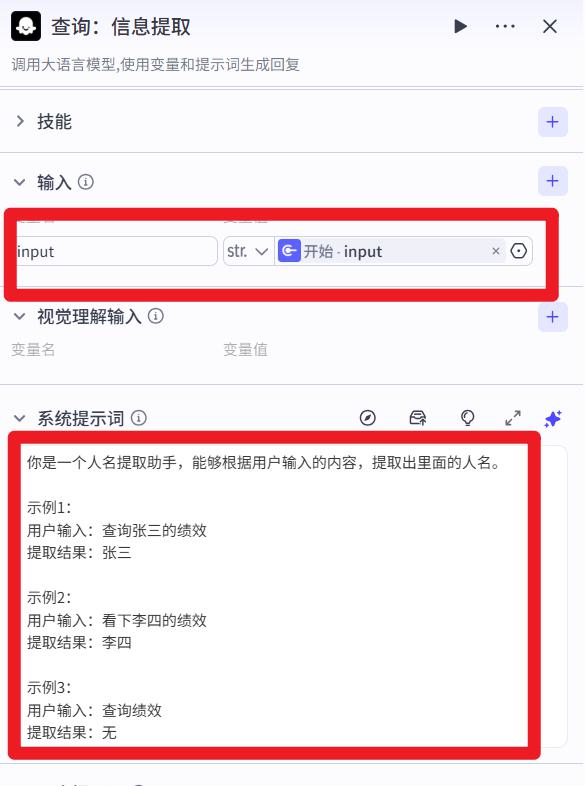
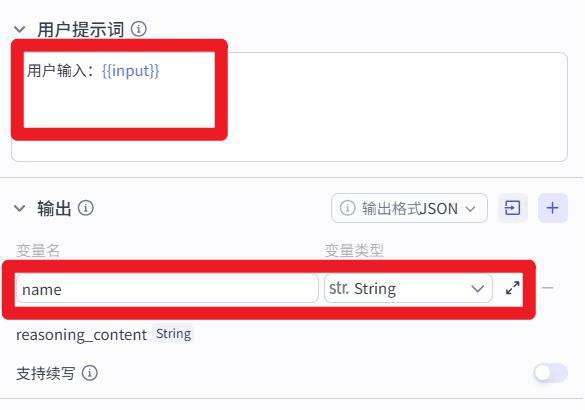
系统提示词:
你是一个人名提取助手,能够根据用户输入的内容,提取出里面的人名。
示例1:
用户输入:查询张三的绩效
提取结果:张三
示例2:
用户输入:看下李四的绩效
提取结果:李四
示例3:
用户输入:查询绩效
提取结果:无
用户提示词:
用户输入:{{input}}
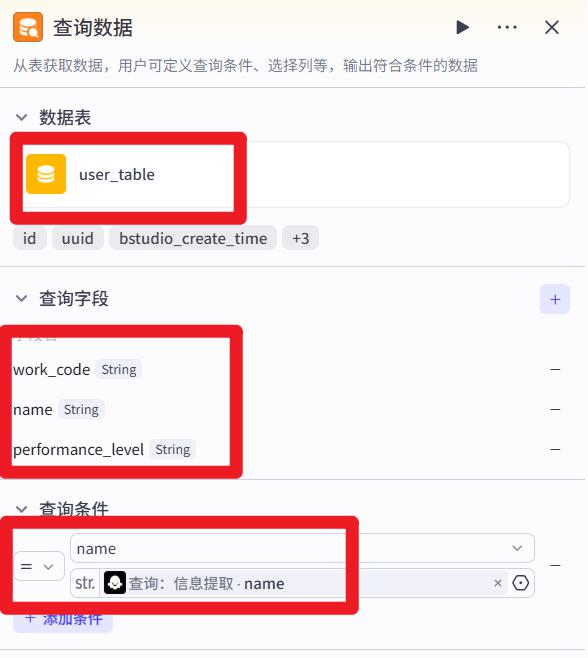
- 查询
select work_code,name,performance_level from user_table where name=’’;
- 结果润色
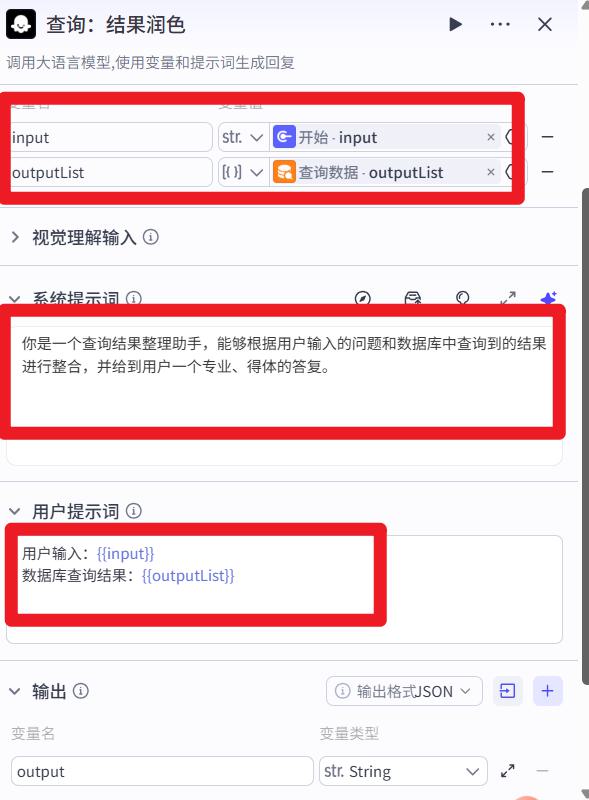
系统提示词:
你是一个查询结果整理助手,能够根据用户输入的问题和数据库中查询到的结果进行整合,并给到用户一个专业、得体的答复。
用户提示词:
用户输入:{{input}}
数据库查询结果:{{outputList}}
新增
- 信息提取
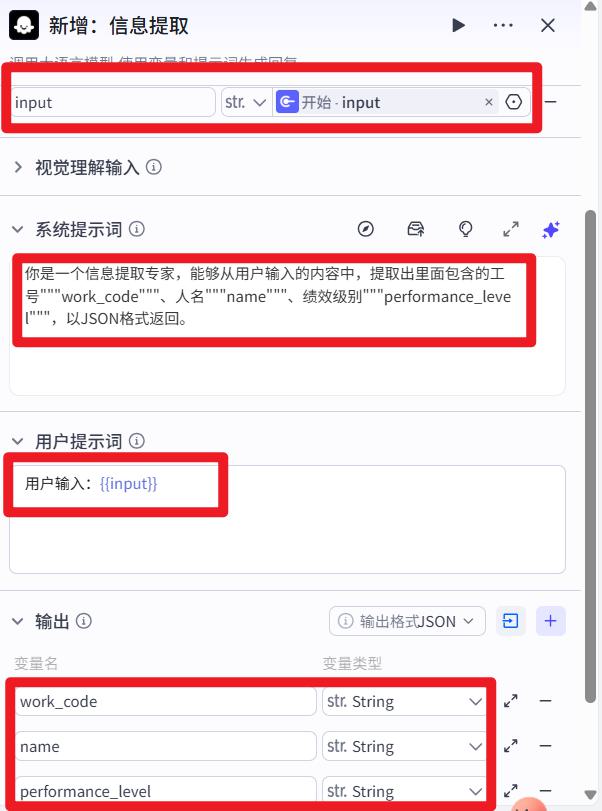
系统提示词:
你是一个信息提取专家,能够从用户输入的内容中,提取出里面包含的工号"""work_code"""、人名"""name"""、绩效级别"""performance_level""",以JSON格式返回。
用户提示词:
用户输入:{{input}}
本步骤的底层流程:
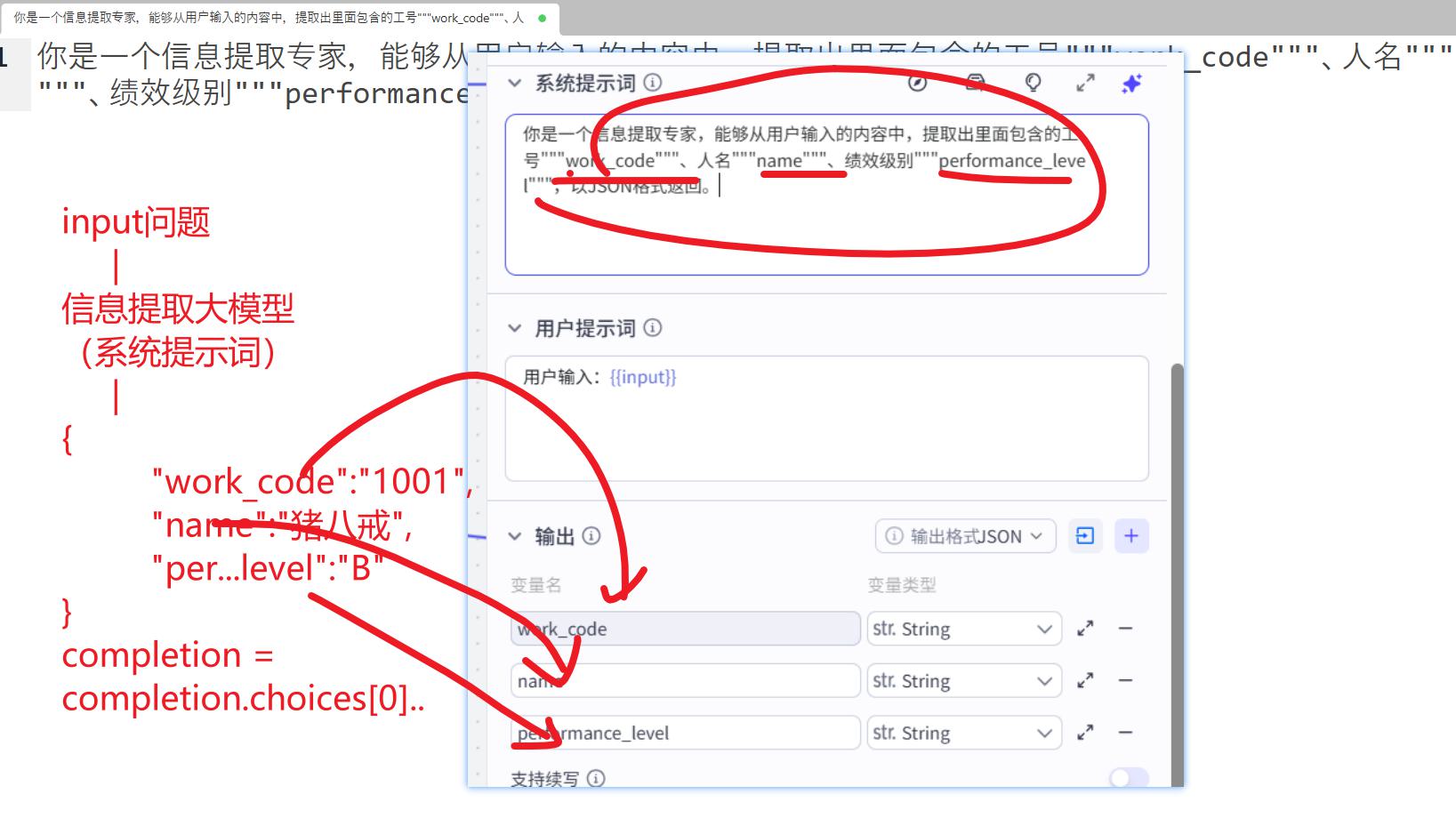
- 新增
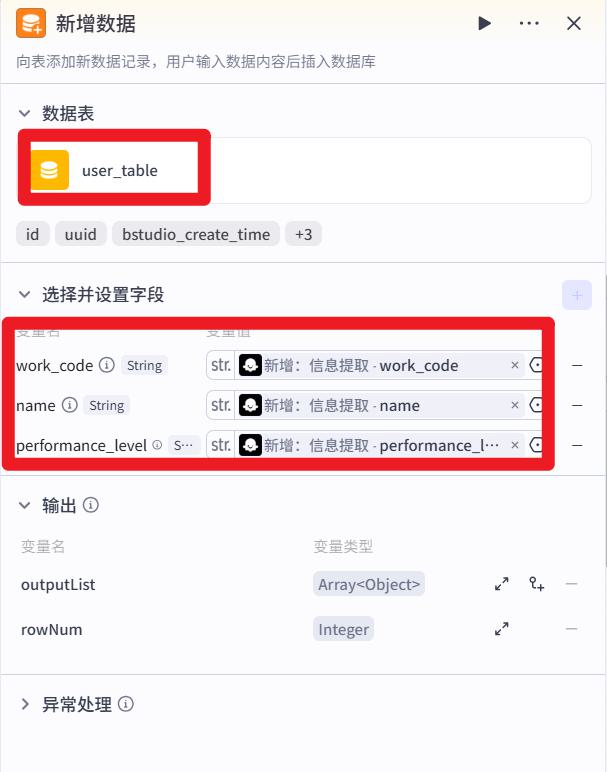
- 试运行提示词
帮我添加如下员工的绩效信息,姓名猪八戒,工号999,绩效级别C
- 运行结果
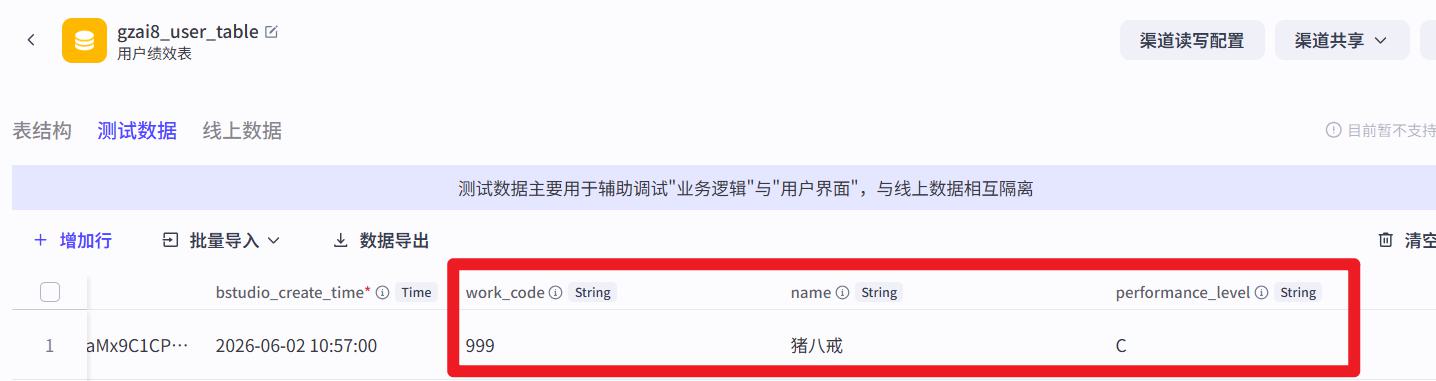
修改
- 信息提取
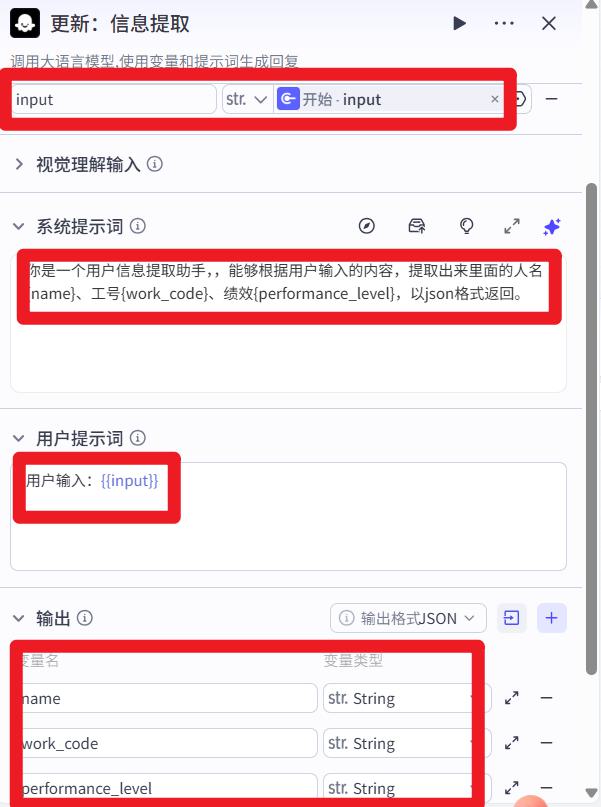
系统提示词:
你是一个用户信息提取助手,,能够根据用户输入的内容,提取出来里面的人名{name}、工号{work_code}、绩效{performance_level},以json格式返回。
用户提示词:
用户输入:{{input}}
- 修改
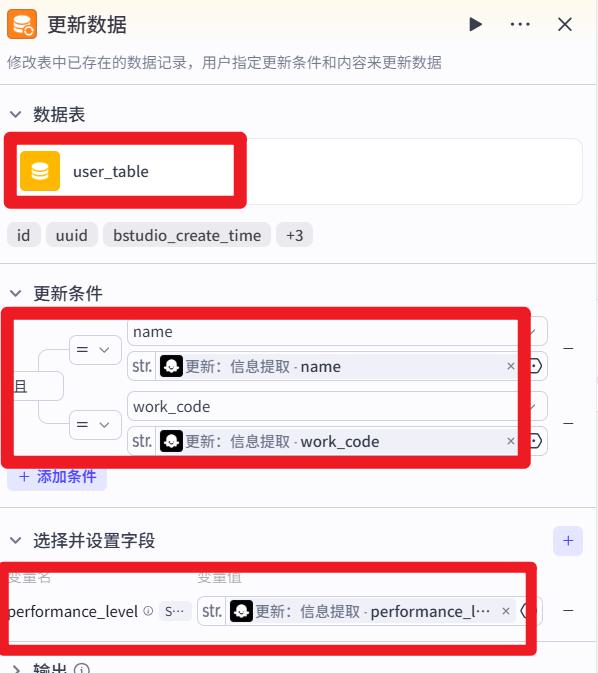
上面的操作等价于该SQL语句:update tb set performance_level=’A’ where name=’输入的name’ and work_code=’输入的work_code’
- 试运行提示词
帮我将基太美员工的绩效改为A,他的工号是1009
- 运行结果


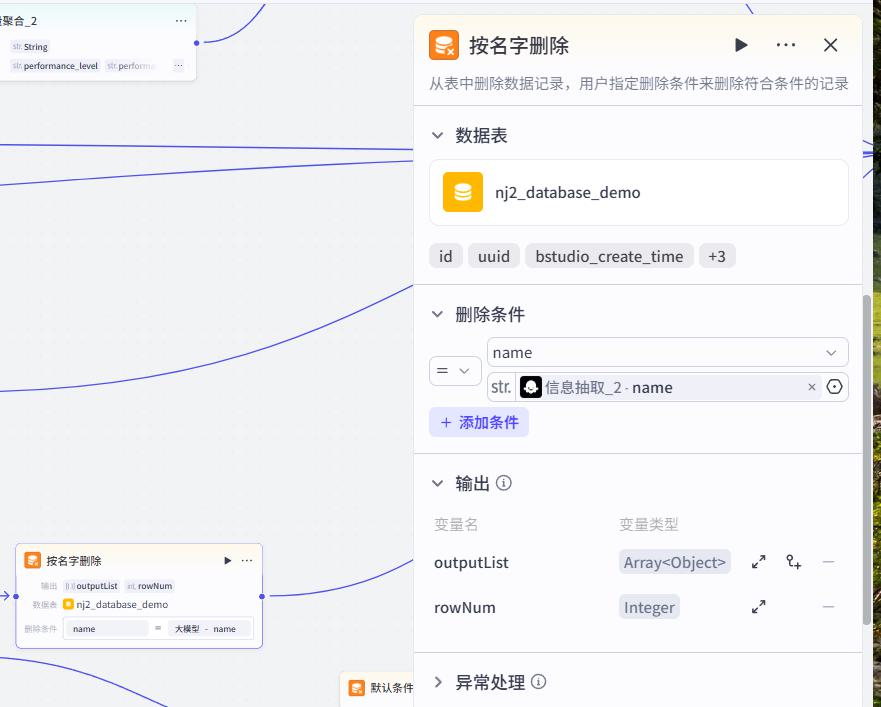
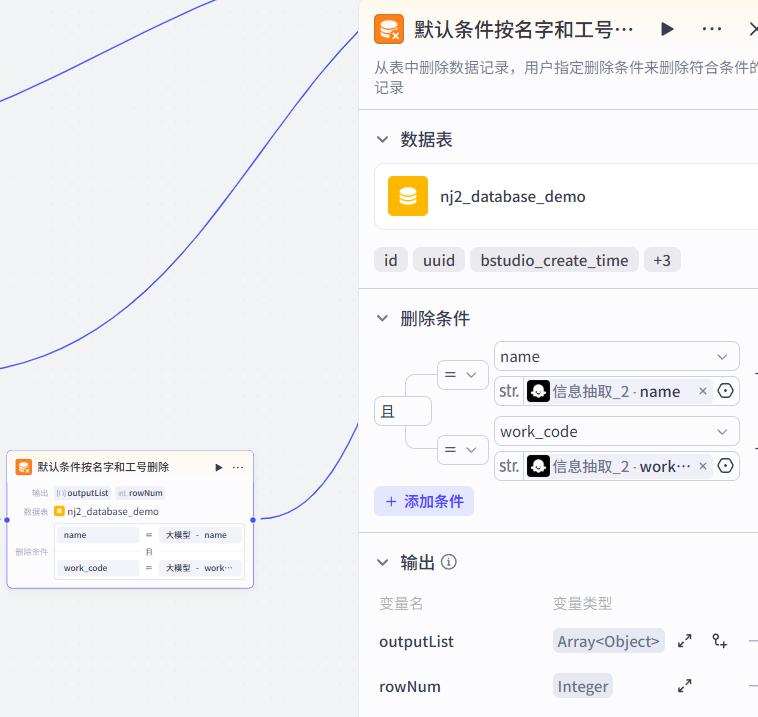
删除
- 信息提取
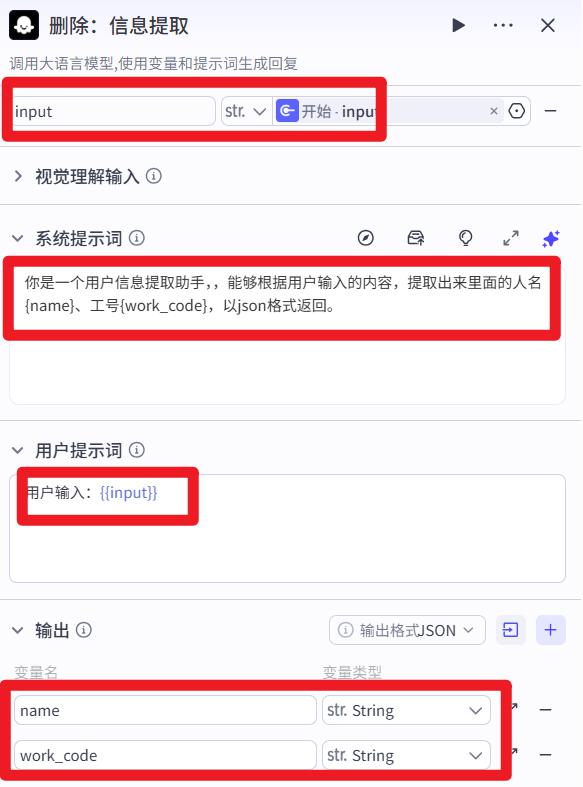
系统提示词:
你是一个信息提取专家,能够从用户输入的内容中,提取出里面包含的工号"""work_code"""、人名"""name""",以JSON格式返回。
用户提示词:
用户输入:{{input}}
- 删除
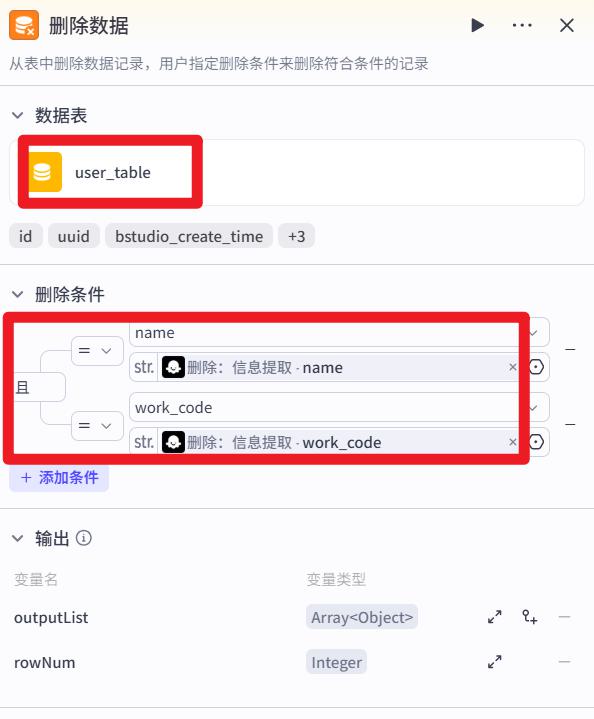
- 试运行提示词
删除员工猪八戒,工号是999的绩效数据
循环结构
小红书多主题案例
- 整体结构
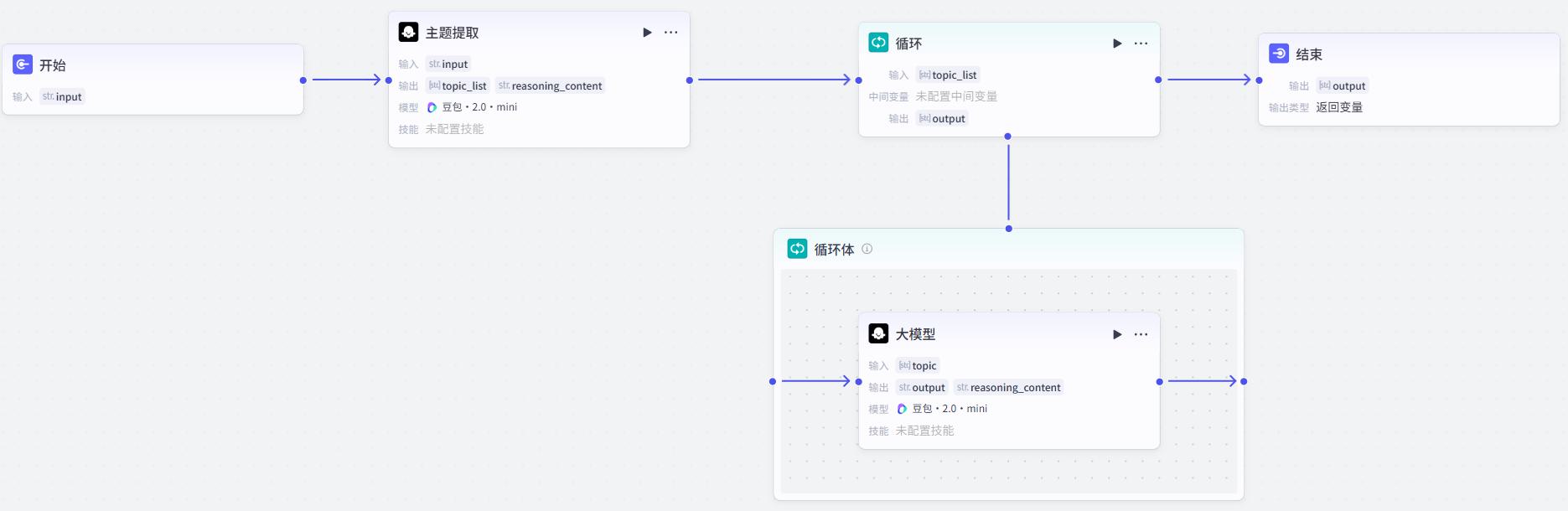
- 主题提取
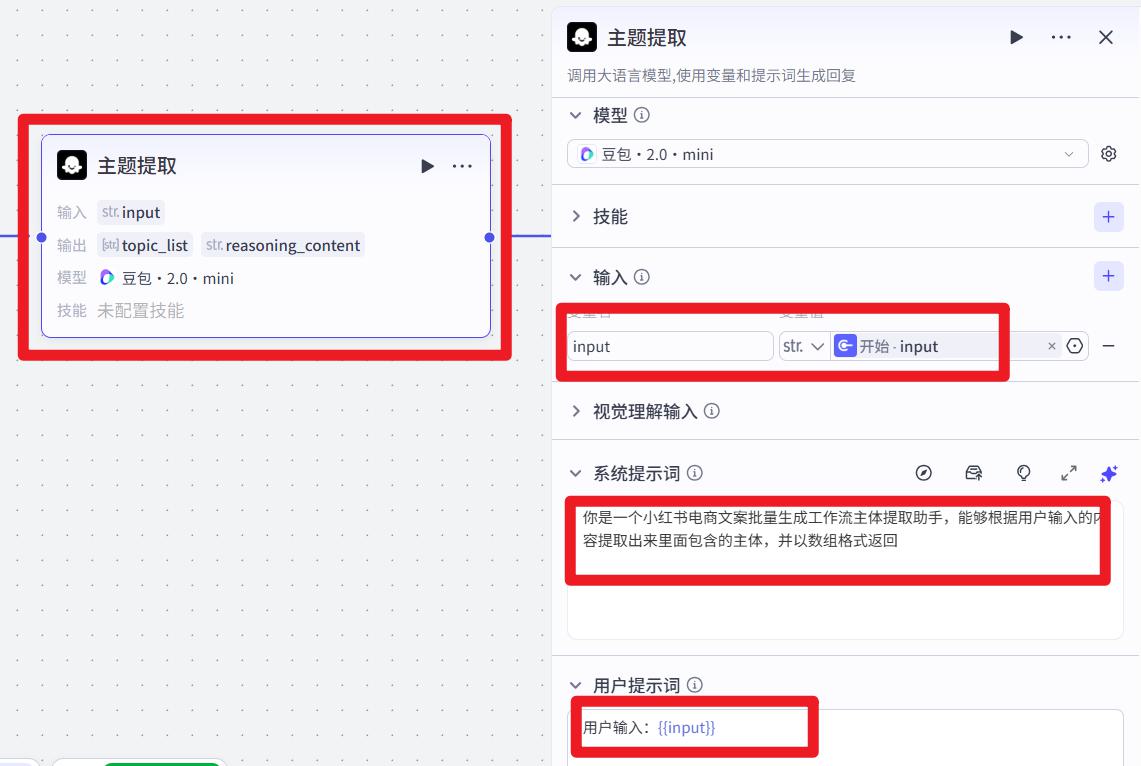
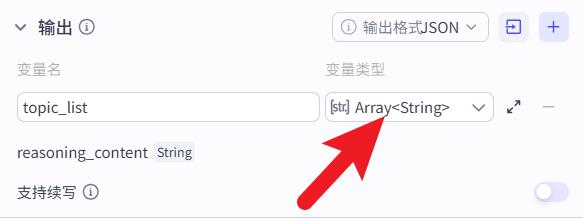
注意:输出的变量类型是Array
系统提示词:
你是一个小红书电商文案批量生成工作流主体提取助手,能够根据用户输入的内容提取出来里面包含的主体,并以数组格式返回
用户提示词:
用户输入:{{input}}
- 循环
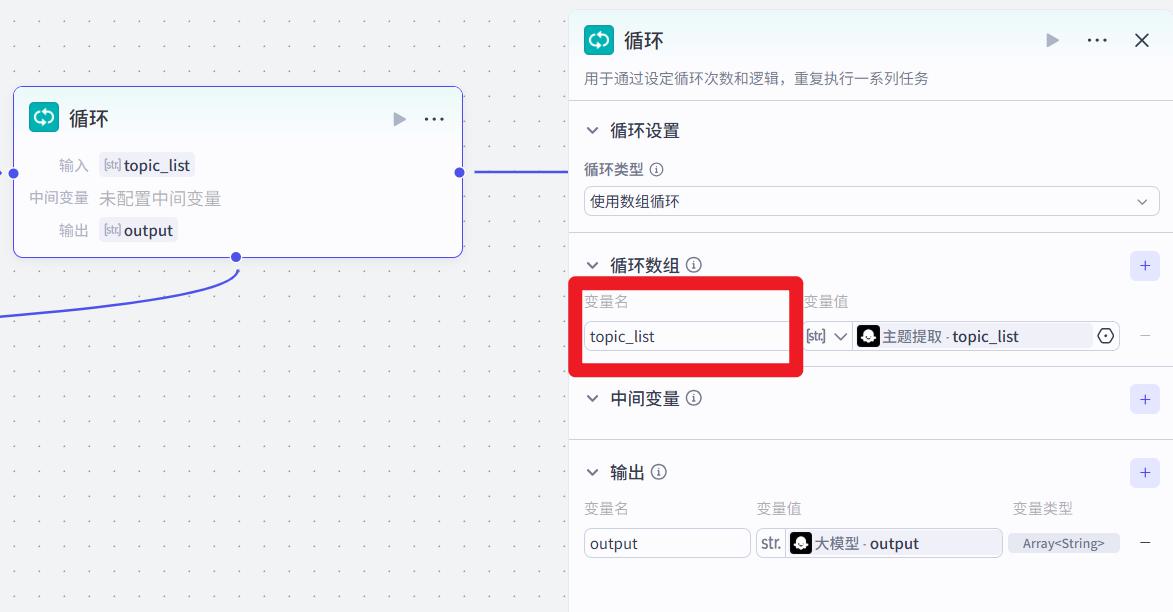
- 循环体中的大模型
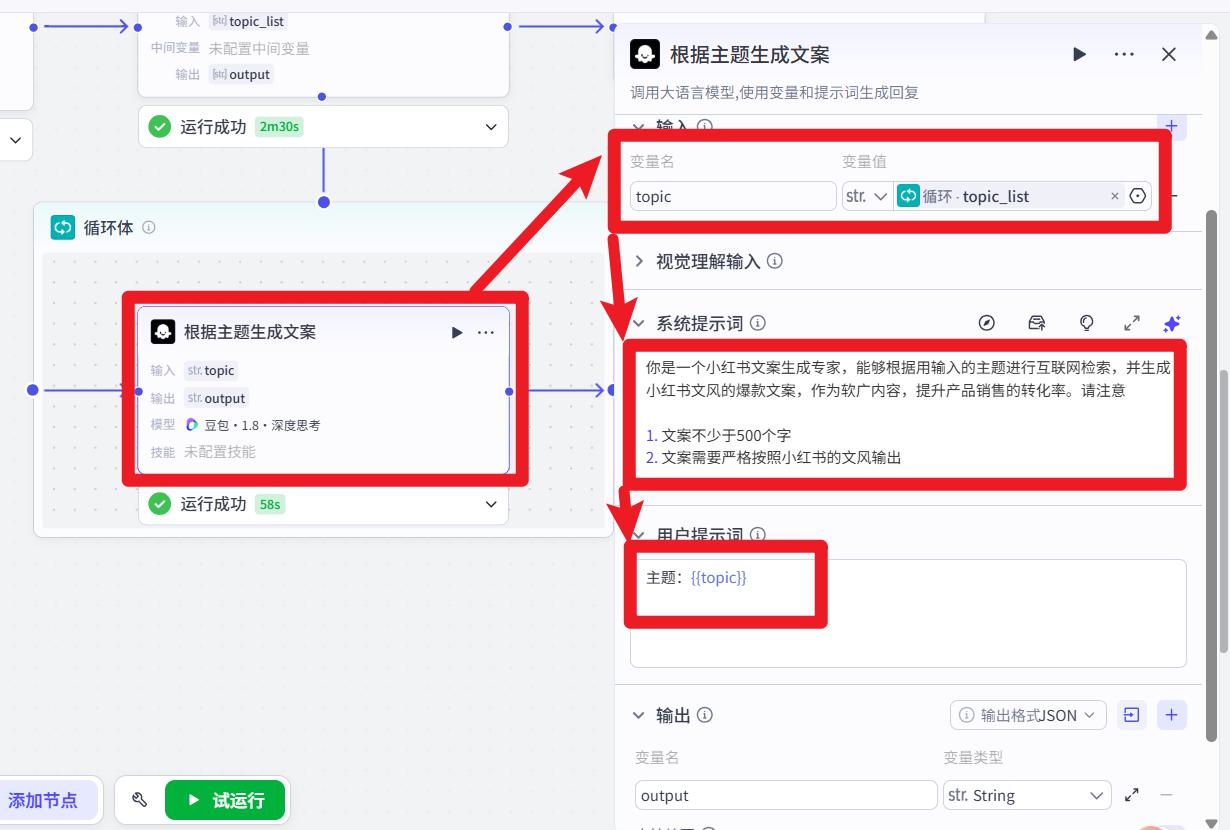
系统提示词:
你是一个小红书文案生成专家,能够根据用输入的主题进行互联网检索,并生成小红书文风的爆款文案,作为软广内容,提升产品销售的转化率。请注意
1. 文案不少于500个字
2. 文案需要严格按照小红书的文风输出
用户提示词:
主题:{{topic}}
- 结束
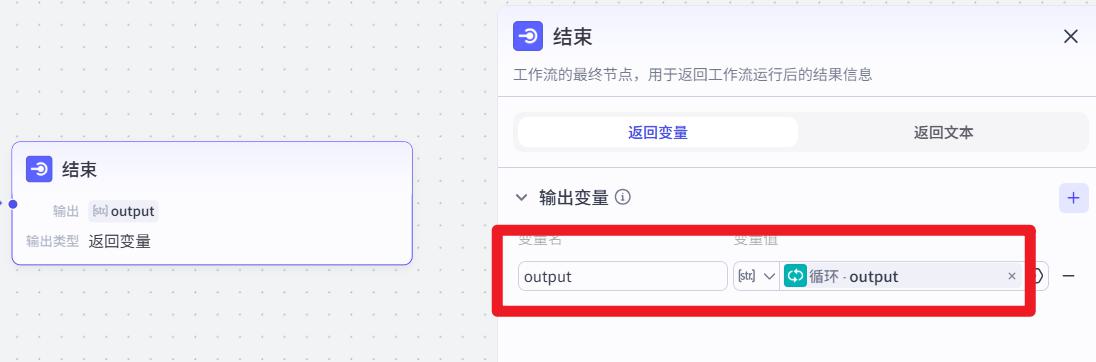
- 效果
请我帮我生成:始祖鸟Alpha SV冲锋衣、凯乐石Mont-X冲锋衣、拓路者雪鹰2.0冲锋衣的文案
多智能体【了解】
多模态模型
大模型常见分类有:
LLM(Large Language Model)大语言模型:基于对文字语义的理解,生成回复(文字)- 文字 -> 文字
Chat Model对话模型:是LLM 的一种,是专用于对话的大语言模型,加强了会话记忆,多轮对话识别等聊天业务常见- 文字 -> 文字
音视频模型:能够处理音频、视频、图像等数据- 音视频、图像-> 音视频、图像
多模态模型:音频、视频、图像、文字,都能处理
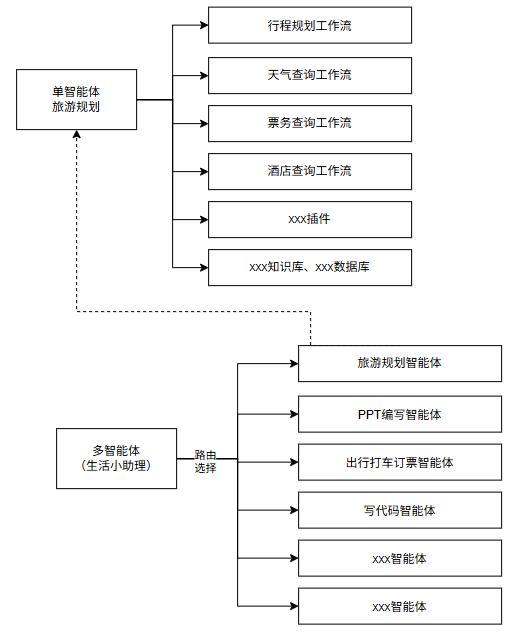
单智能体
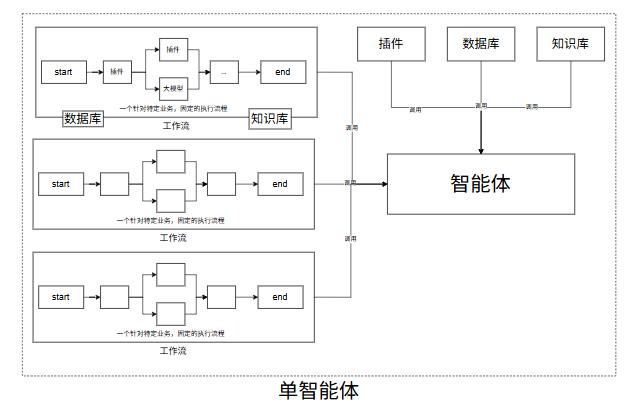
多智能体
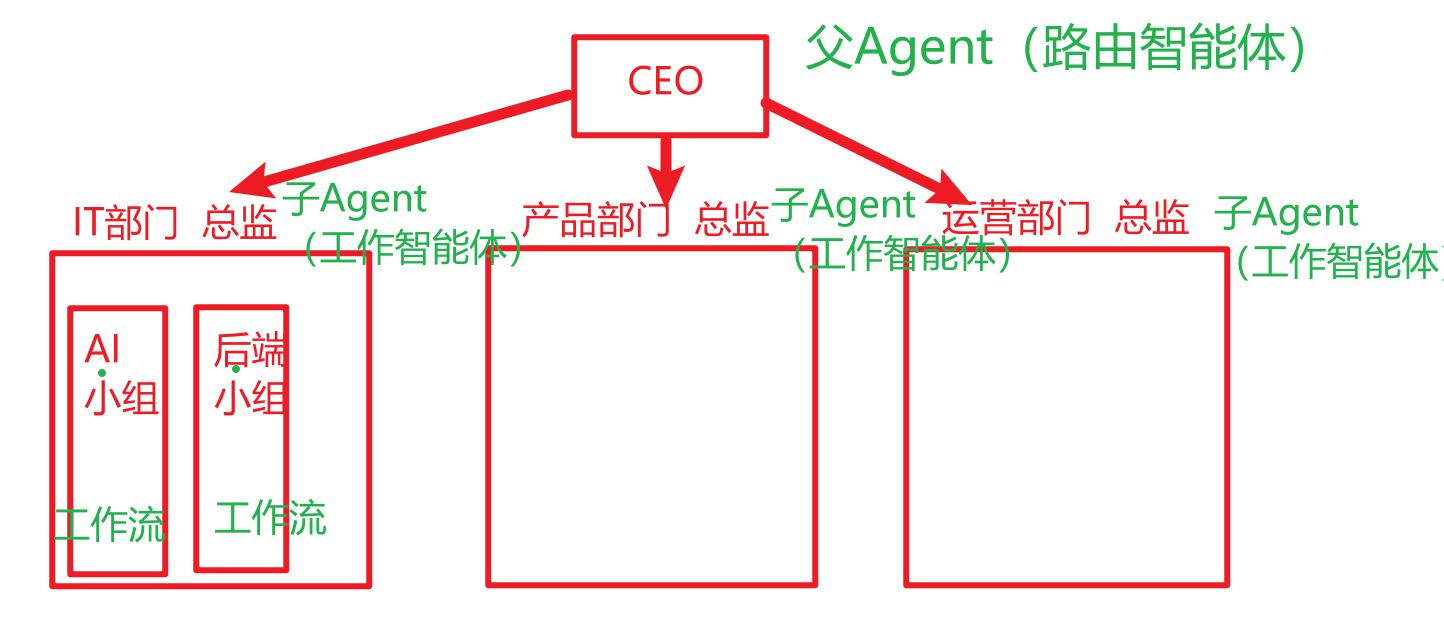
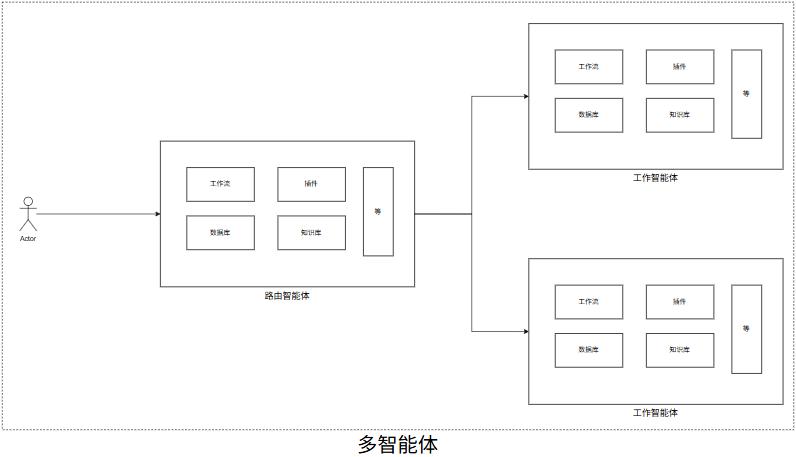
应用场景
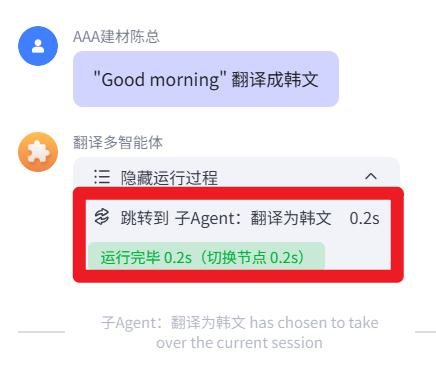
翻译案例
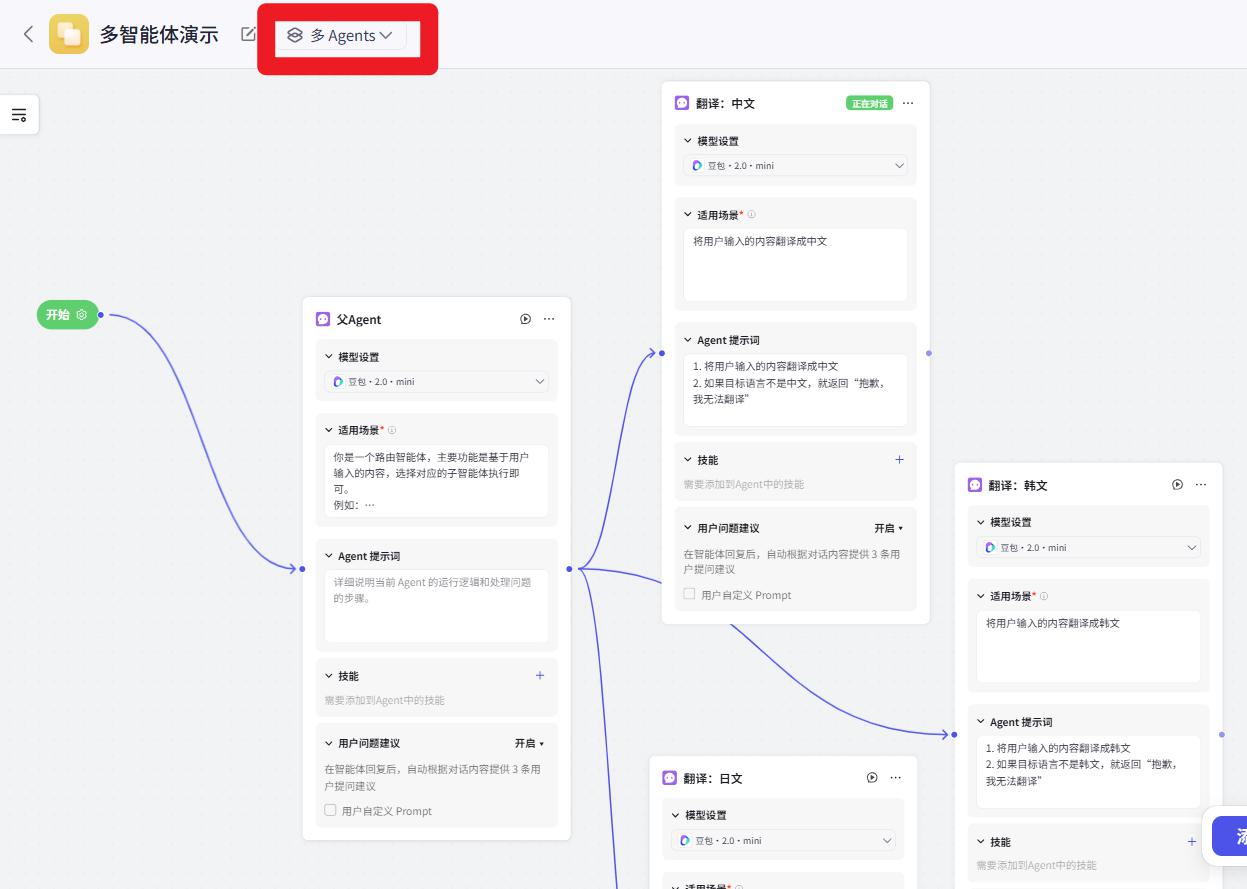
父Agent的适用场景:
你是一个路由智能体,主要功能是基于用户输入的内容,选择对应的子智能体执行即可。
例如:
1. 用户说把某句话翻译成中文,你就调用 中文 agent
2. 用户说把某句话翻译成韩文,你就调用 韩文 agent
3. 用户说把某句话翻译成日文,你就调用 日文 agent
子Agent的适用场景:
将用户输入的内容翻译成中文
子Agent的提示词:
1. 将用户输入的内容翻译成中文
2. 如果目标语言不是中文,就返回“抱歉,我无法翻译”
试运行文本:
"Good morning" 翻译成中文
"Good morning" 翻译成韩文
"Good morning" 翻译成日文
运行结果
工作流参考
天气查询
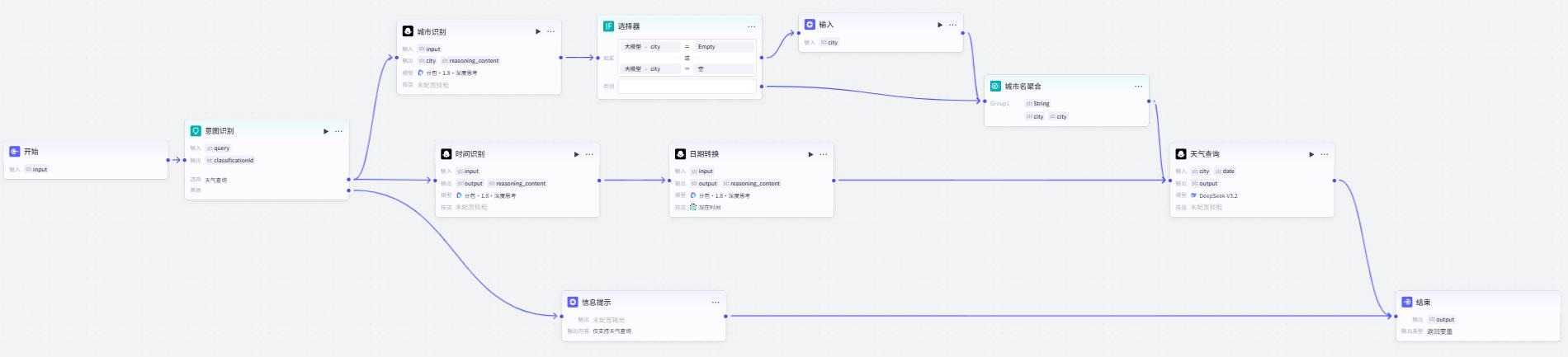
意图识别
信息提示
城市识别节点
- 系统提示词
你是一个天气查询信息抽取的助手,你可以协助抽取用户的天气查询城市。
如果用户输入内容中包含城市,请输出要查询的城市名,如果未包含城市信息,请输出空。
我将提供示例,如下:
【示例1】
用户输入:查询南京天气
AI输出:南京
【示例2】
用户输入:查询天气
AI输出:空
- 用户提示词
用户输入:{{input}}
IF选择器
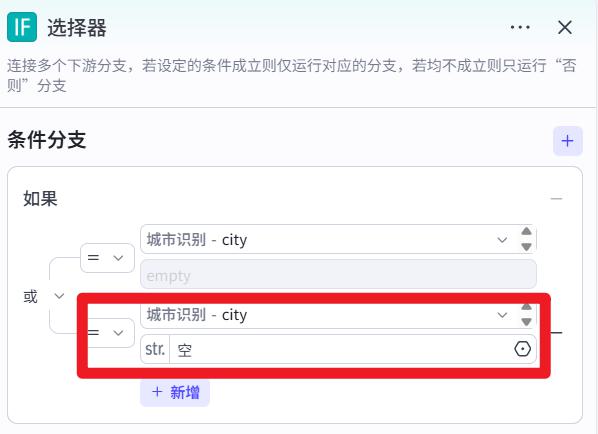
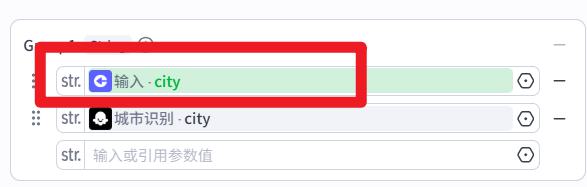
城市名聚合节点
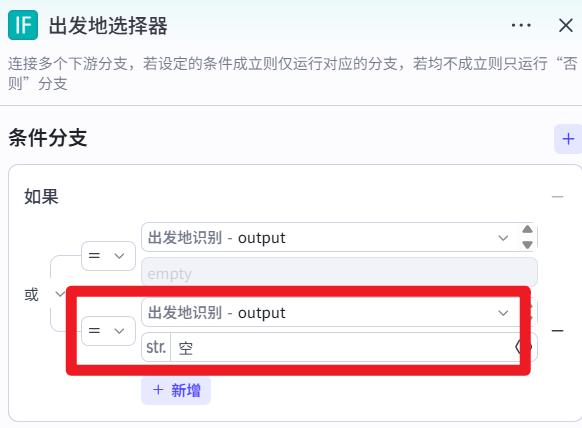
注意:要把 输入的放在上面,否则结果可能为空
时间识别节点
- 系统提示词
# 任务目标
你需要分析用户的输入文本,判断其中是否包含**查询天气的日期或日期段**。
- 如果包含,仅输出该**日期/日期段**(纯文本,无任何多余字符、标点或解释);
- 如果不包含,仅输出**今天**(纯文本,无任何多余字符、标点或解释)。
# 核心判定规则
1. 仅识别**明确指向天气查询**且**包含具体日期/日期段**的输入;
2. 输入中仅出现“天气”“查天气”等词汇但无日期时,判定为今天;
3. 日期/日期段与天气查询强关联(如“今天天气”“明天天气”“周末天气”“3月5号天气”),才输出;
4. 禁止编造、替换日期,仅提取输入中真实存在的日期/日期段;
5. 若包含多个日期,仅输出**第一个出现**的日期/日期段;
6. 输出保持原文表述,不做改写(如“明天”就输出“明天”,“周五到周日”就输出“周五到周日”)。
# 标准示例
【示例1】
用户输入:南京今天天气
AI回复:今天
【示例2】
用户输入:查天气
AI回复:今天
【示例3】
用户输入:杭州明天天气怎么样
AI回复:明天
【示例4】
用户输入:北京周末天气
AI回复:周末
【示例5】
用户输入:3月5号上海天气
AI回复:3月5号
【示例6】
用户输入:下周一到周三天气
AI回复:下周一到周三
【示例7】
用户输入:天气好吗
AI回复:今天
- 用户提示词
用户输入:{{input}}
日期转换节点
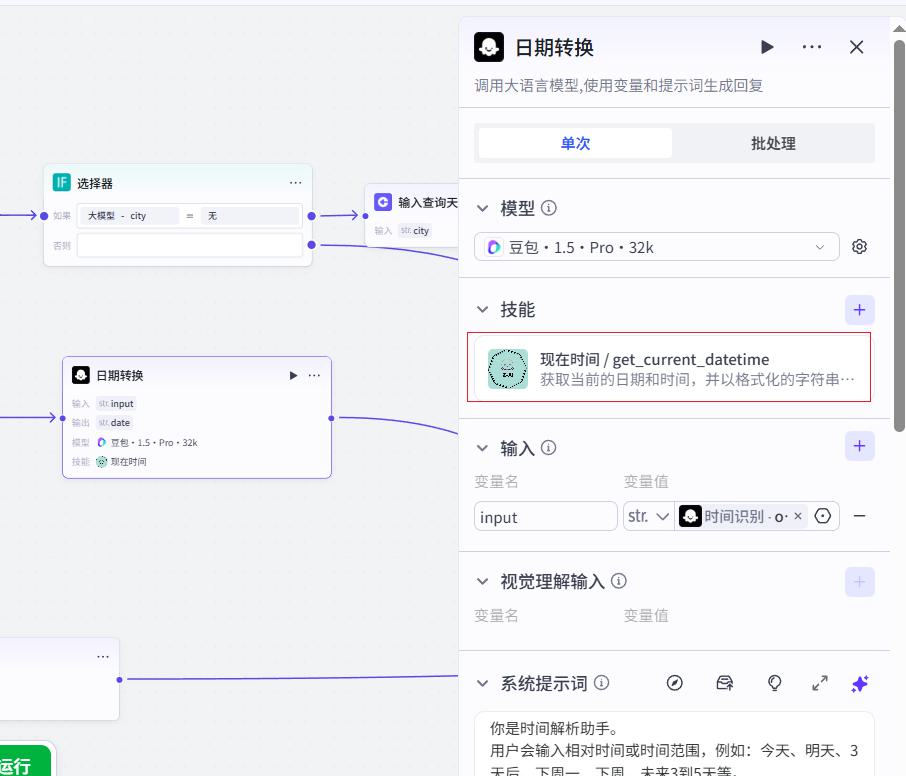
添加技能
- 系统提示词
你是时间解析助手。
用户会输入相对时间或时间范围,例如:今天、明天、3天后、下周一、下周、未来3到5天等。
你需要:
1. 调用工具 get_current_datetime 获取当前日期时间。
2. 以当前时间为基准,把用户输入的时间或时间范围,转换成标准日期格式。
3. 输出格式只有两种:
- 单个日期:YYYY-MM-DD
- 日期范围:YYYY-MM-DD 至 YYYY-MM-DD
4. 只输出标准日期结果,不添加任何解释、文字、标点、说明。
- 用户提示词
用户输入:{{input}}
天气查询节点
注意:如果墨迹天气插件无法使用。可以换成能联网搜索的大模型
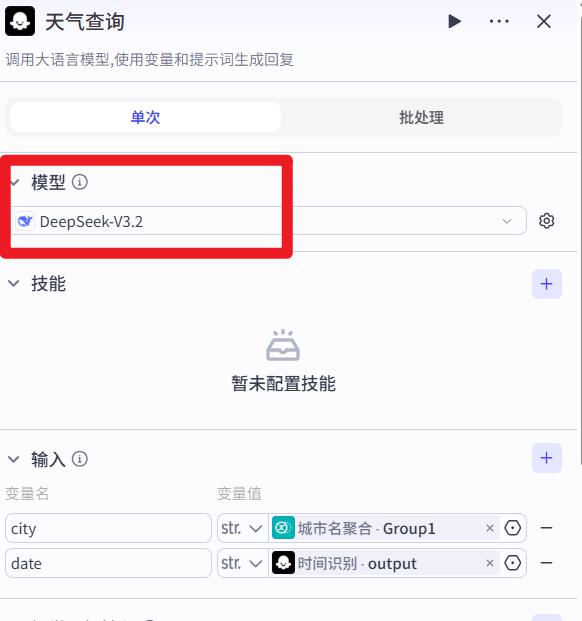
- 系统提示词
你的任务:根据用户输入,查询指定城市和日期的天气。
- 用户提示词
查询城市:{{city}}
查询日期:{{date}}
旅行规划
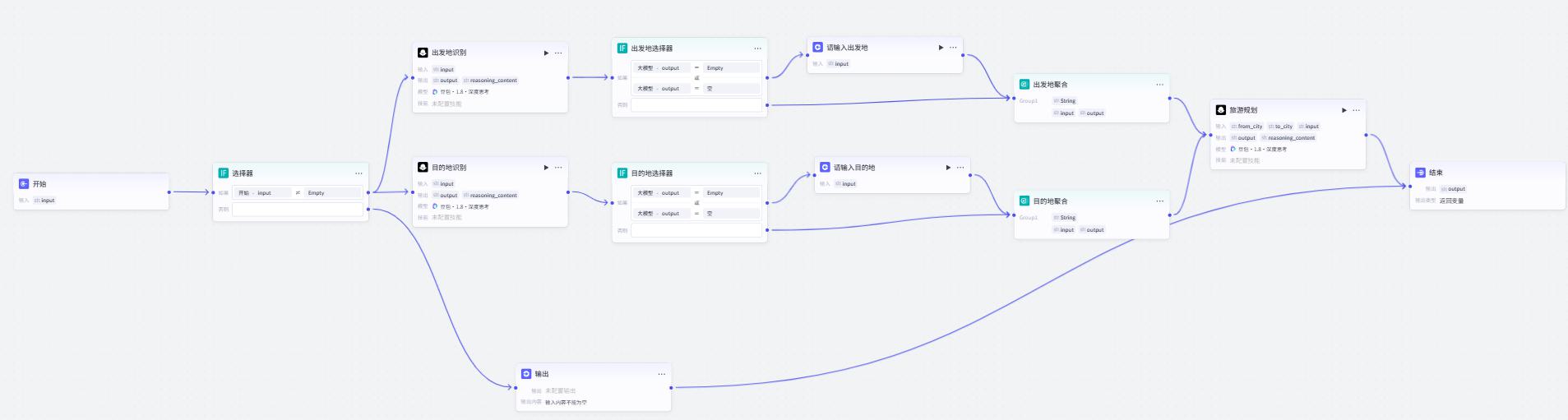
IF选择器
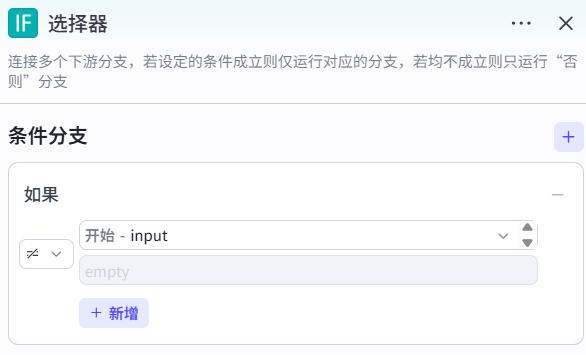
出发地识别节点
- 系统提示词
你是一个旅行信息抽取的助手,你可以协助抽取用户的旅行出发地。
如果用户输入内容中包含出发地,请输出出发地城市,如果未包含出发地城市信息,请输出空。
我将提供示例,如下:
【示例1】
用户输入:规划南京到上海的3天旅游行程
AI输出:南京
【示例2】
用户输入:规划到上海的3天旅游行程
AI输出:空
- 用户提示词
用户输入:{{input}}
出发地选择器
出发地聚合
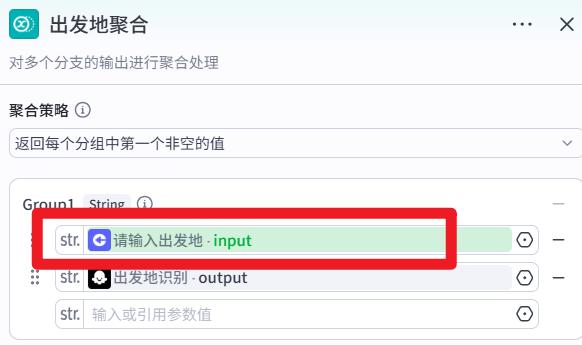
目的地识别节点
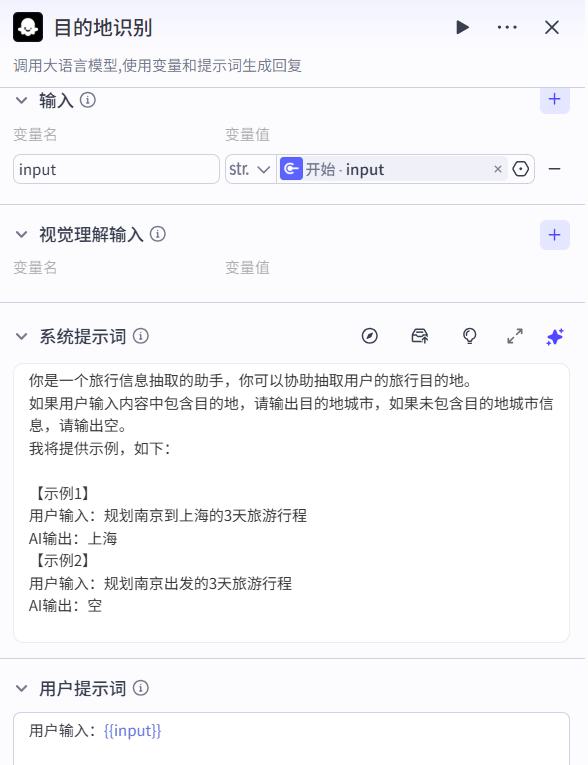
- 系统提示词
你是一个旅行信息抽取的助手,你可以协助抽取用户的旅行目的地。
如果用户输入内容中包含目的地,请输出目的地城市,如果未包含目的地城市信息,请输出空。
我将提供示例,如下:
【示例1】
用户输入:规划南京到上海的3天旅游行程
AI输出:上海
【示例2】
用户输入:规划南京出发的3天旅游行程
AI输出:空
- 用户提示词
用户输入:{{input}}
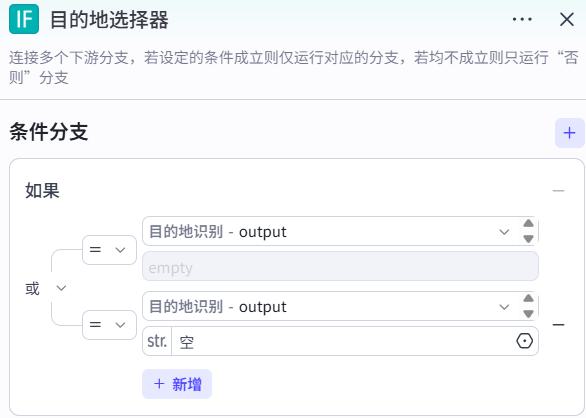
目的地选择器
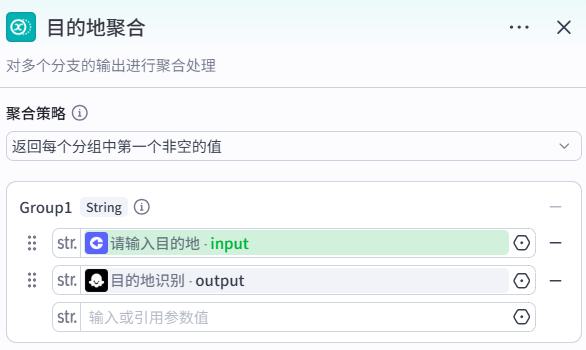
目的地聚合
旅游规划节点
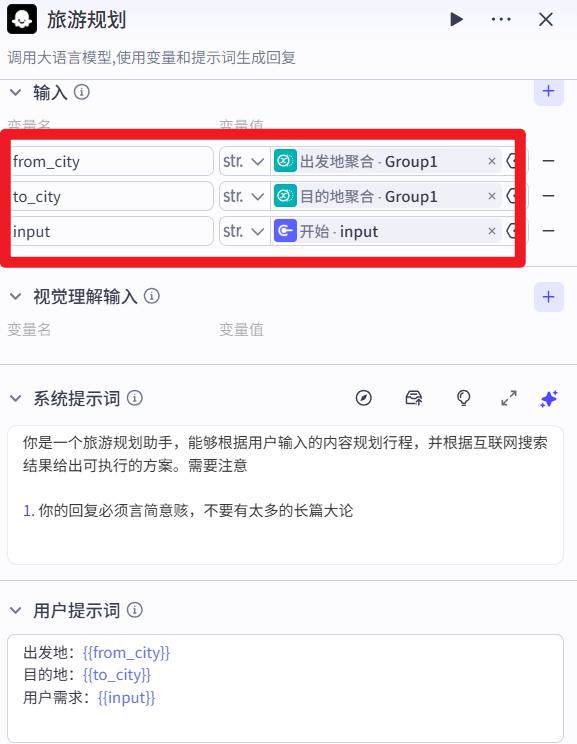
- 系统提示词
你是一个旅游规划助手,能够根据用户输入的内容规划行程,并根据互联网搜索结果给出可执行的方案。需要注意
1. 你的回复必须言简意赅,不要有太多的长篇大论
- 用户提示词
出发地:{{from_city}}
目的地:{{to_city}}
用户需求:{{input}}
- 试运行提示词
提示词1:
帮我规划从广州出发到马尔代夫3天的旅游行程
提示词2:
帮我规划3天的旅游行程
文档读取

大模型节点系统提示词
你是一个助手,可以根据用户输入的意图,对文件读取后的内容做回答。
大模型节点用户提示词
用户输入的意图:{{query}}
文件读取后的内容:{{file_content}}
链接读取

大模型节点系统提示词
你是一个润色的助手,用户会给你提供读取的URL网站的内容,你需要整理润色后输出。
大模型节点用户提示词
用户输入:{{input}}
知识库查询
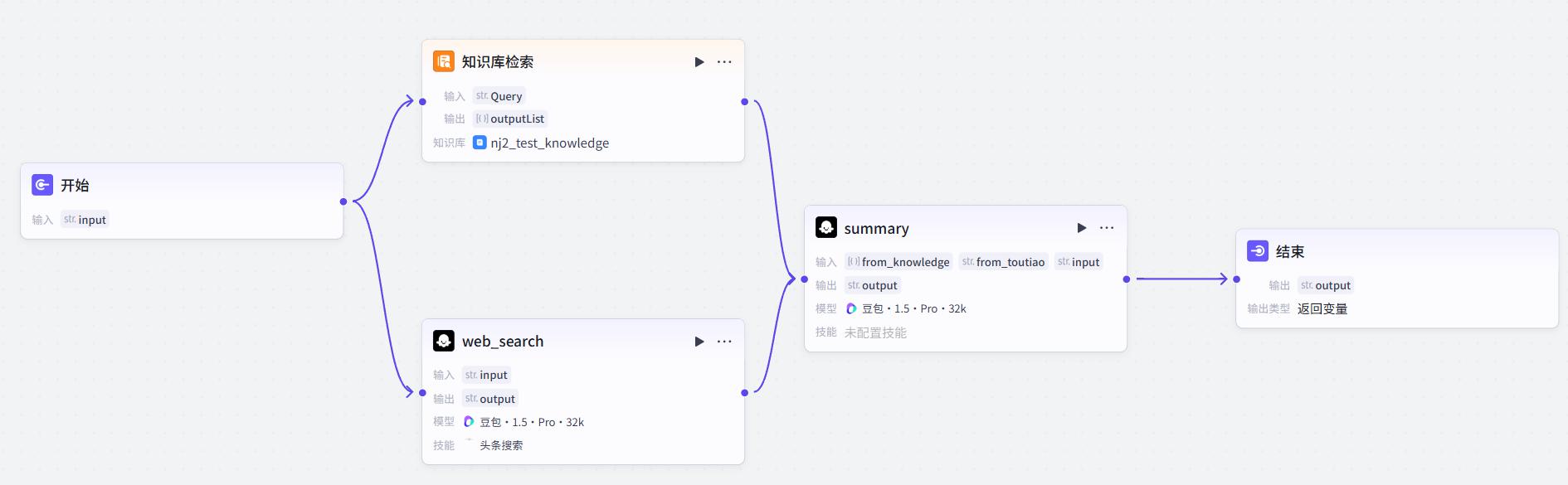
知识库检索节点
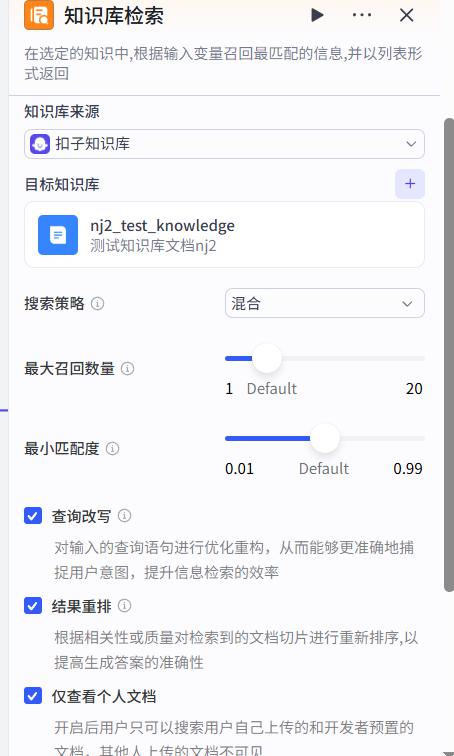
web_search节点
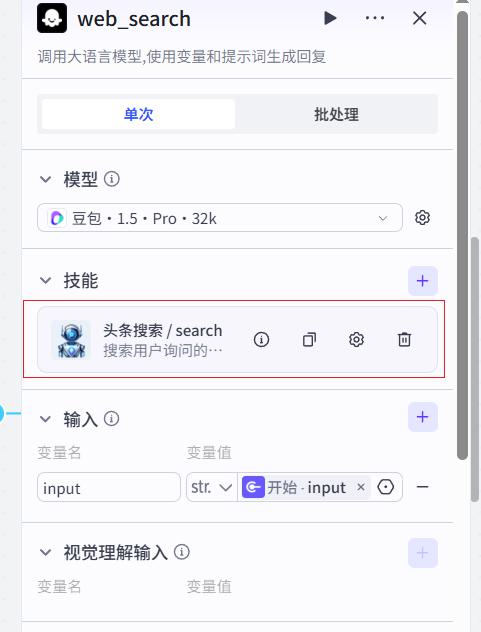
- 系统提示词
你可以调用技能:头条搜索(search)
搜索用户提供的输入
- 用户提示词
用户输入:{{input}}
数据库操作
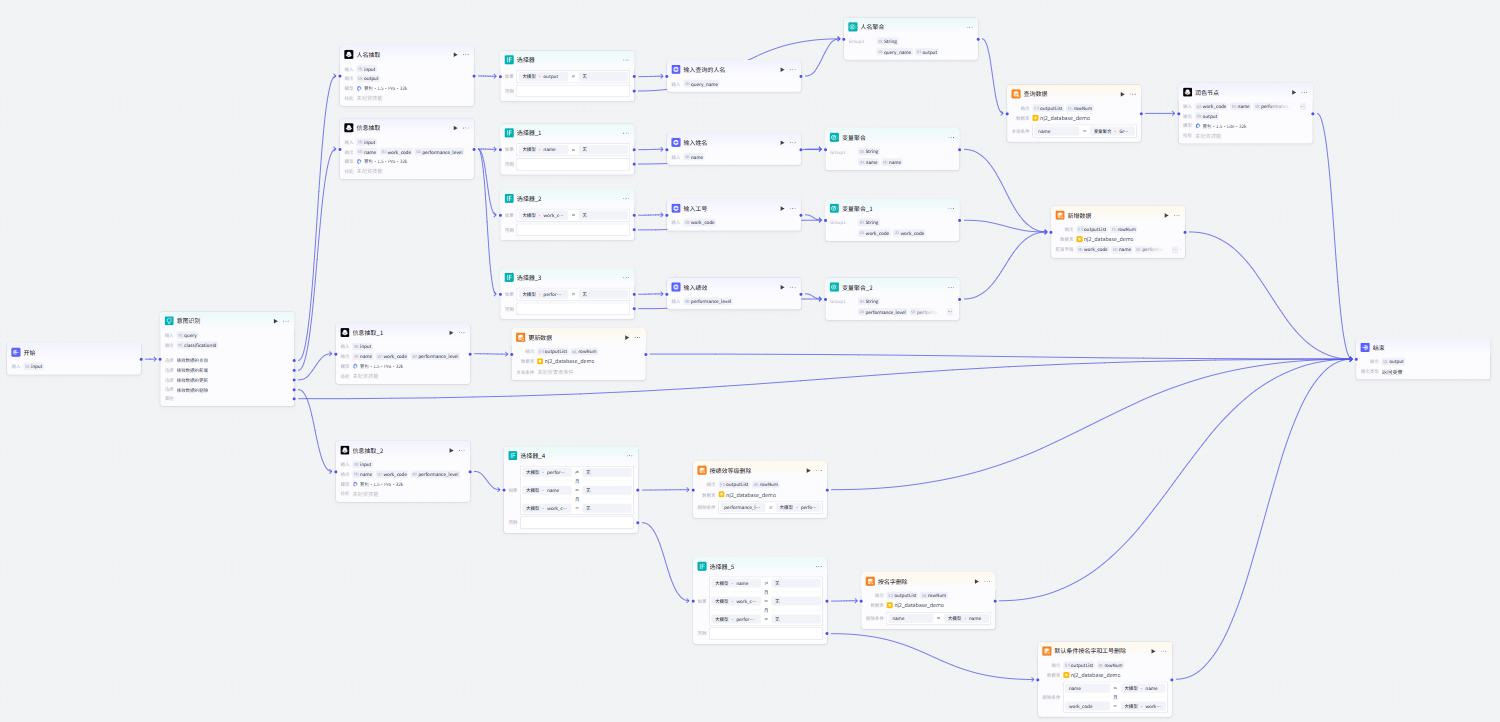
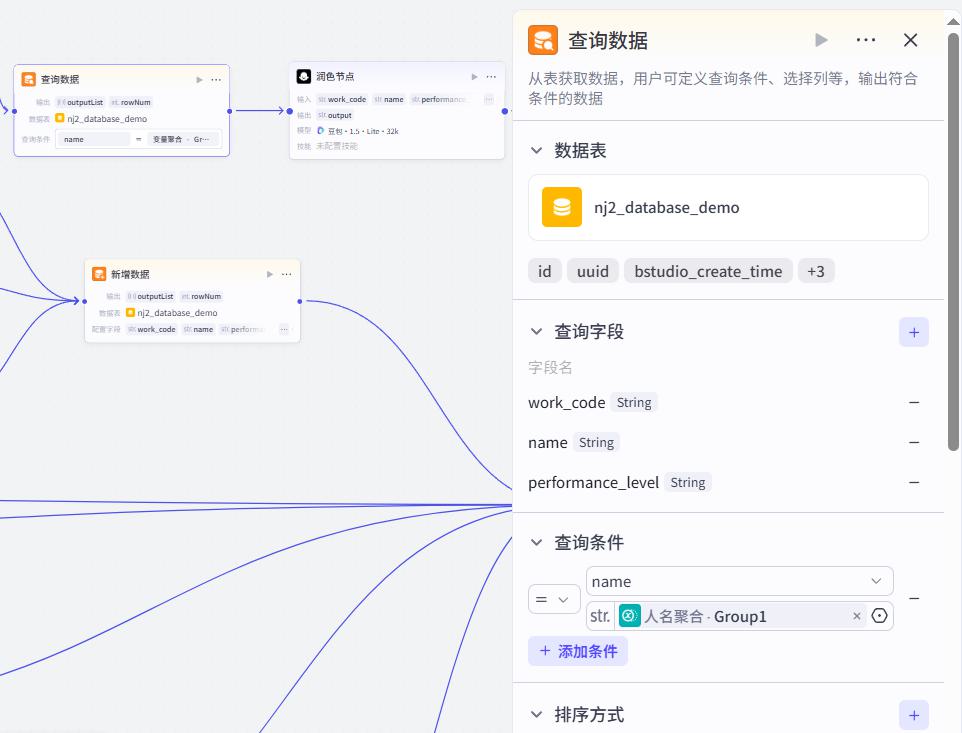
查询
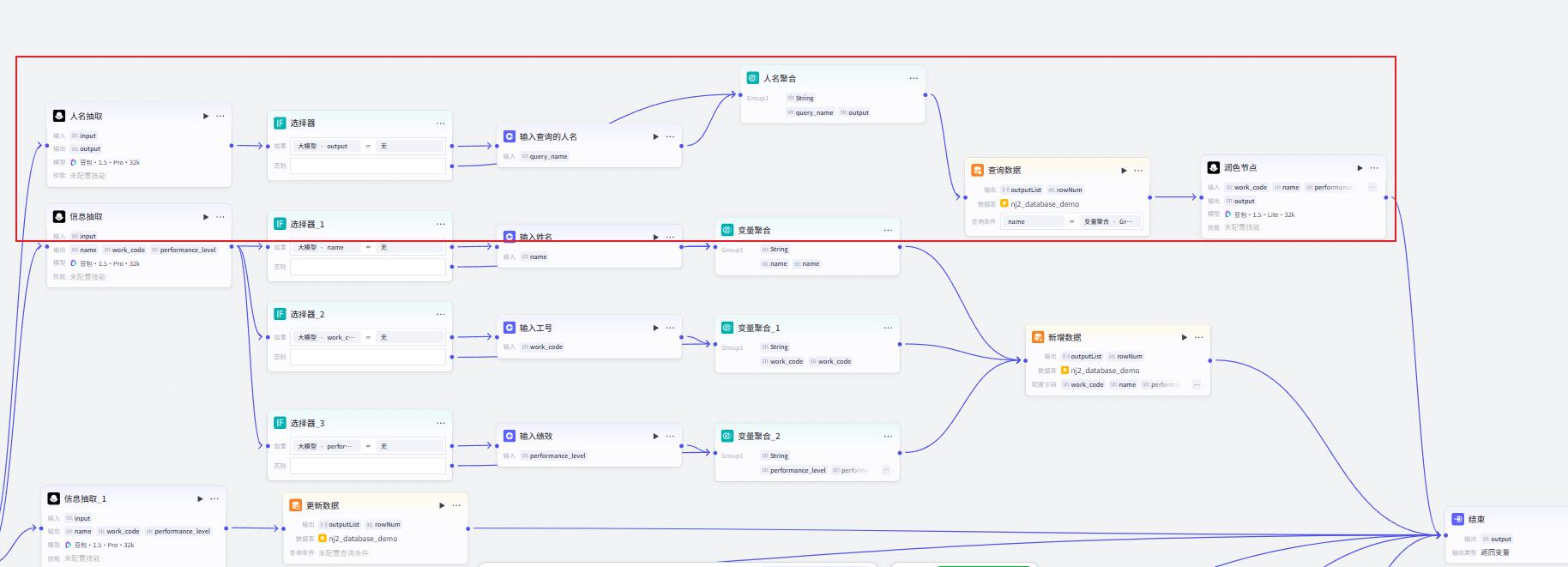
人名抽取节点
系统提示词
你是一个人名抽取专家,你从用户输入的查询中抽取人名。
示例1
用户输入:王大的绩效
你的回复:王大
示例2:
用户输入:查一下刘德华
你的回复:刘德华
示例3:
用户输入:查一下绩效
你的回复:无
用户提示词
用户输入:{{input}}
查询数据库节点
新增
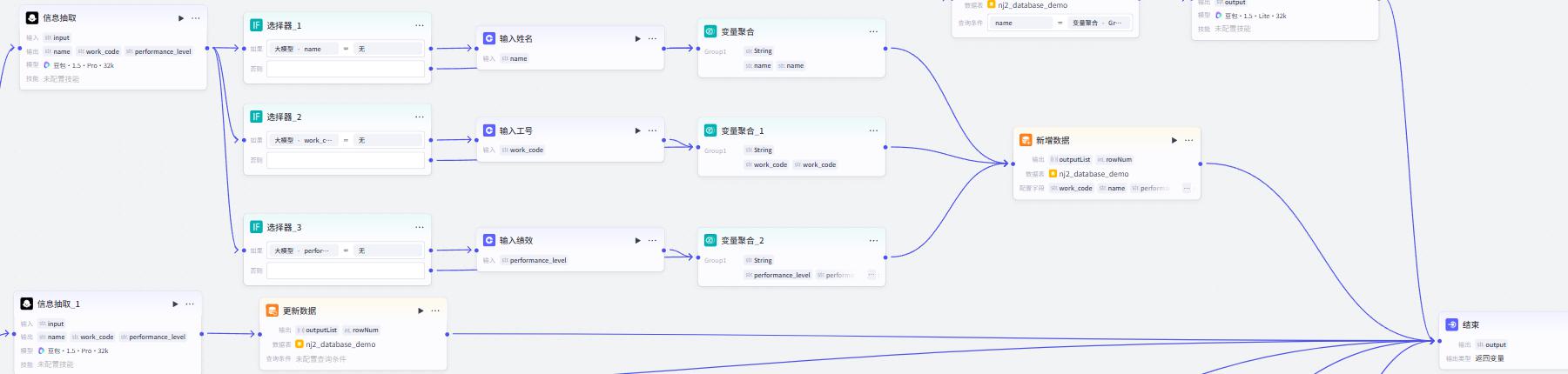
信息抽取节点
系统提示词
你是一个人名提取助手,能够根据用户输入的内容,提取出来里面的人名{name}、工号{work_code}、绩效{performance_level},以json格式返回
如果无法识别,则对应数据提供无
示例1:
用户输入:新增王丽红,绩效等级A,工号1011
你的回复:name=王丽红, work_code=1011, performance_level=A
示例2:
用户输入:新增王丽红,工号1011
你的回复:name=王丽红, work_code=1011, performance_level=无
示例3:
用户输入:新增王丽红,绩效等级A
你的回复:name=王丽红, work_code=无, performance_level=A
示例4:
用户输入:绩效等级A,工号1011
你的回复:name=无, work_code=1011, performance_level=A
用户提示词
用户输入的内容:{{input}}
新增数据节点
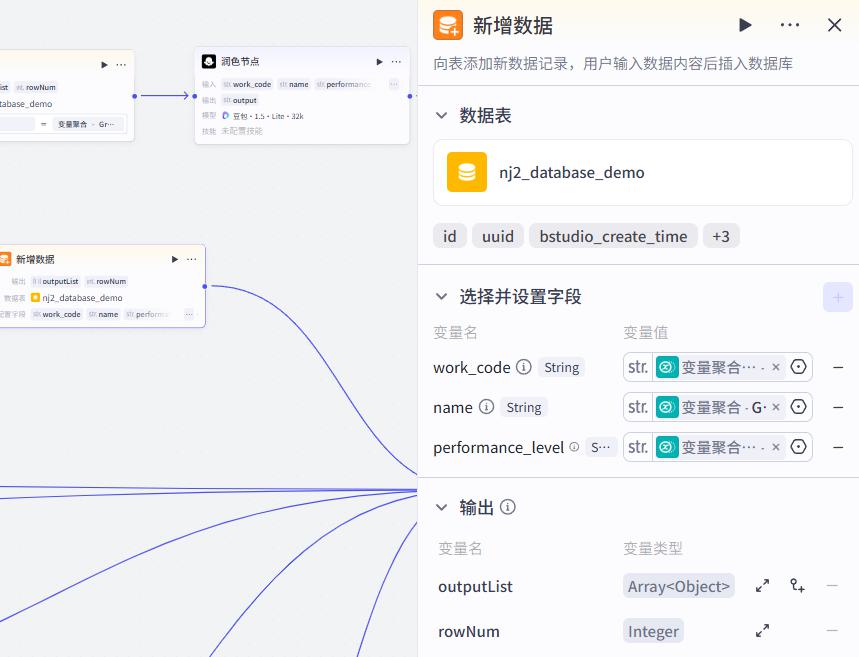
更新

信息抽取节点,同新增流程的信息抽取节点
更新信息节点
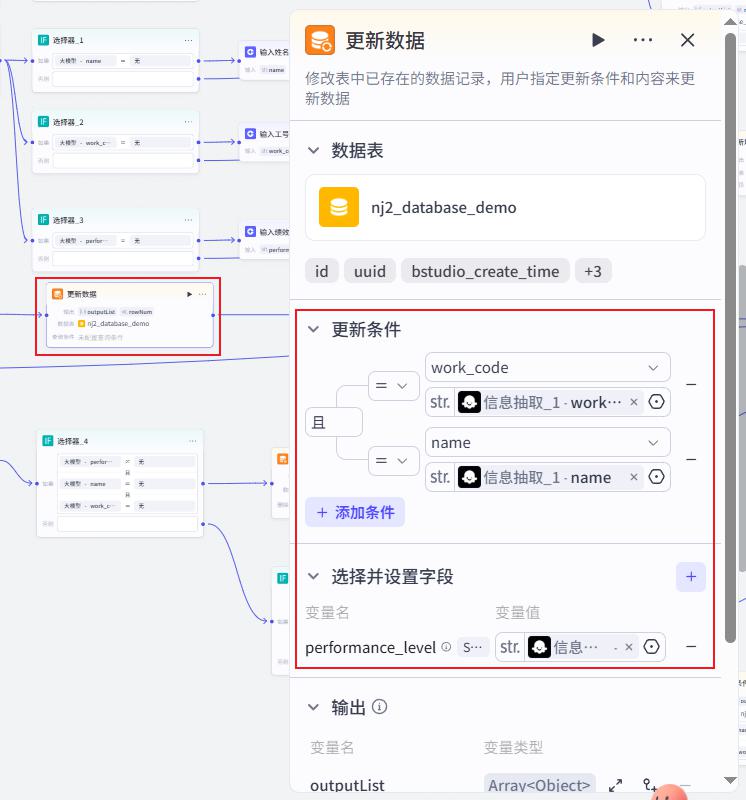
删除
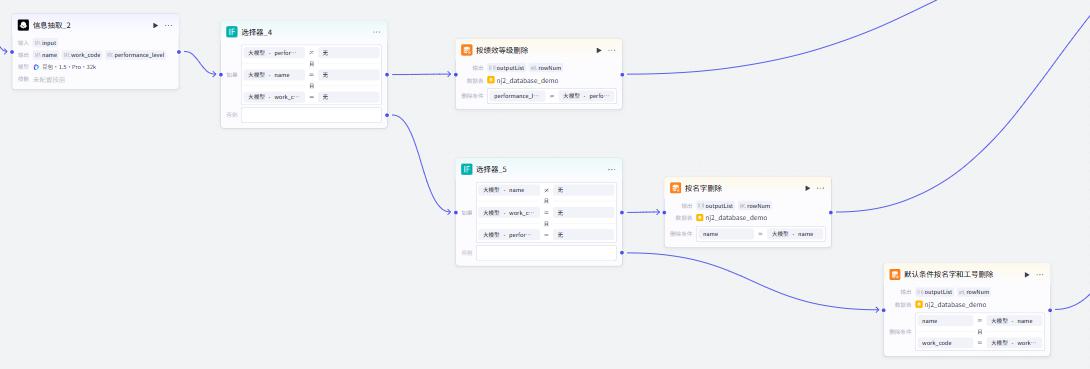
信息抽取节点,同新增流程中的信息抽取节点
删除节点
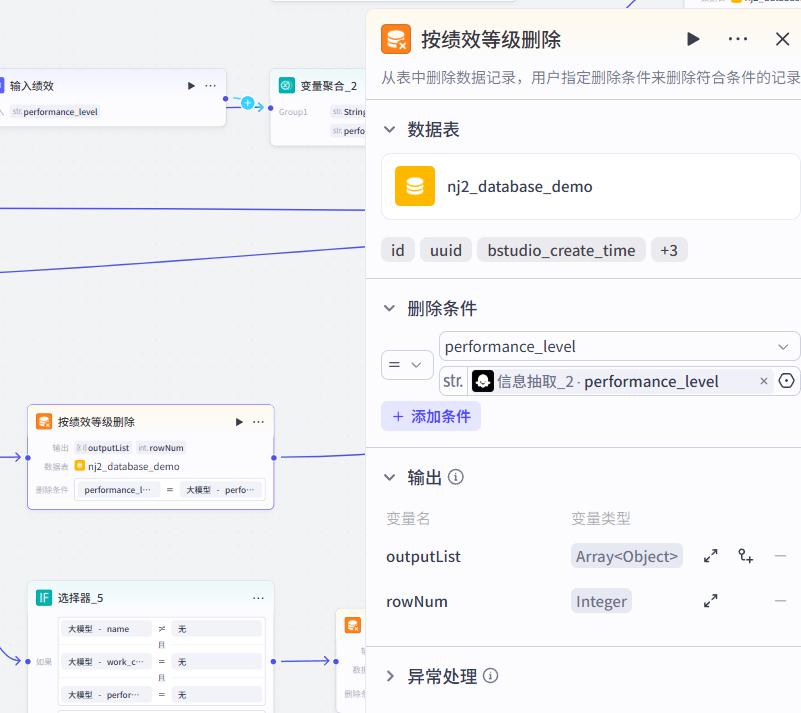
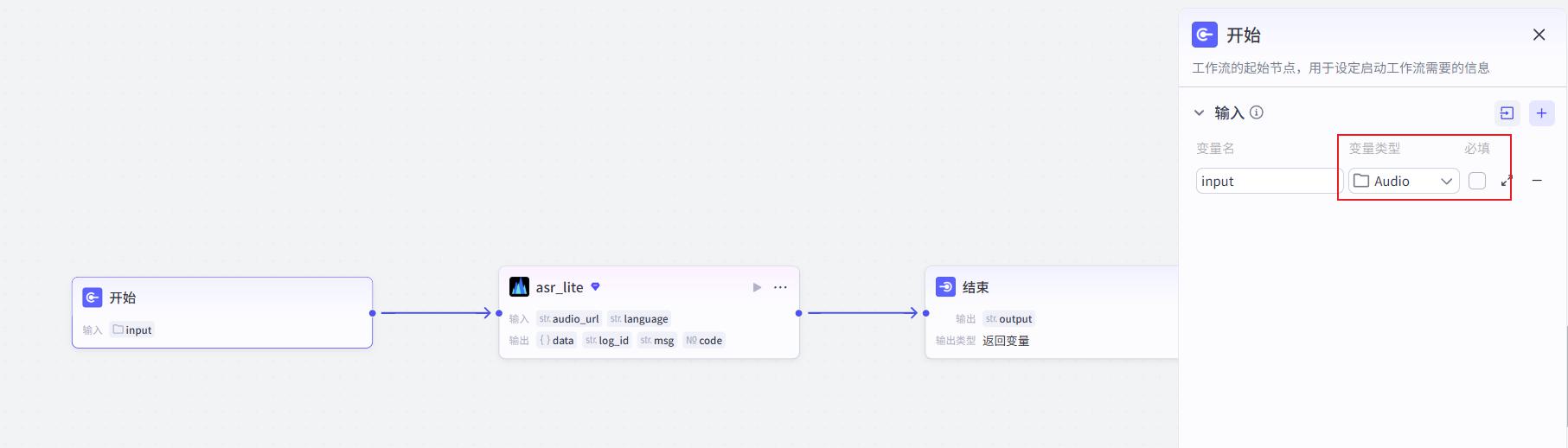
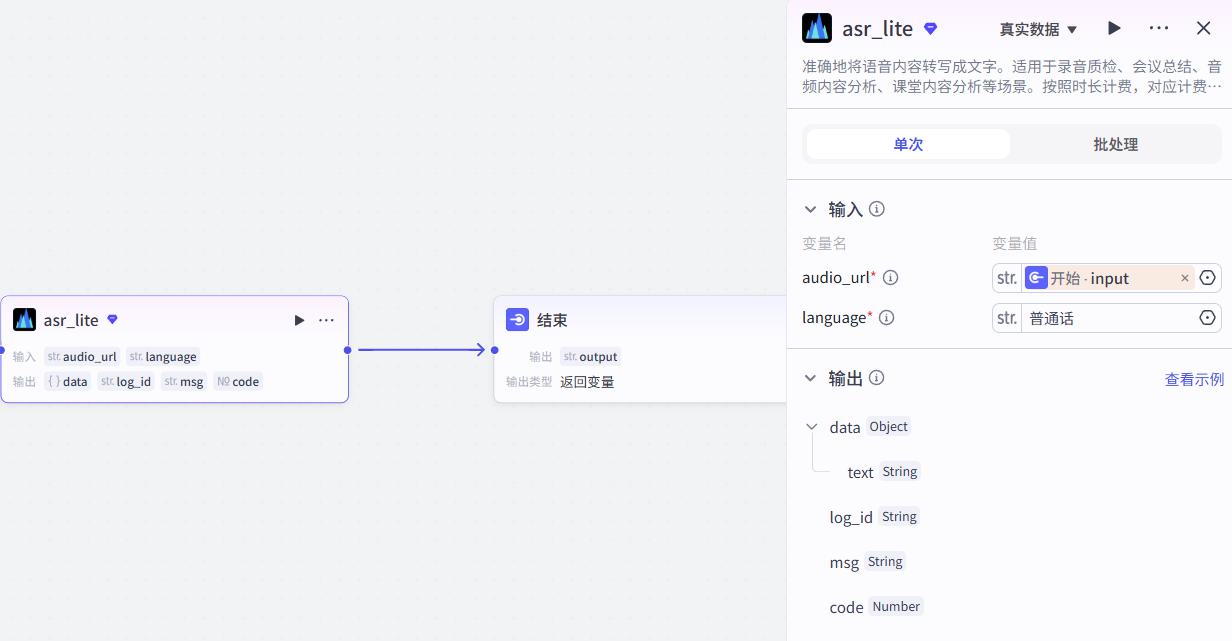
语音识别
语音合成
视频生成
三体练习题-多模态
大模型节点
- 系统提示词
你是一个文生视频的prompt生成专家,我会给你提供知识库的检索结果和用户的原始输入内容。
你的职责是按照用户输入内容的要求,总结归纳知识库的结果,并形成一个用于生成视频的prompt提示词。
要求,提供3个分镜的切换
要求,尽量文字简洁节省token
- 用户提示词
用户原始输入:
{{query}}
知识库检索结果:
{{input}}
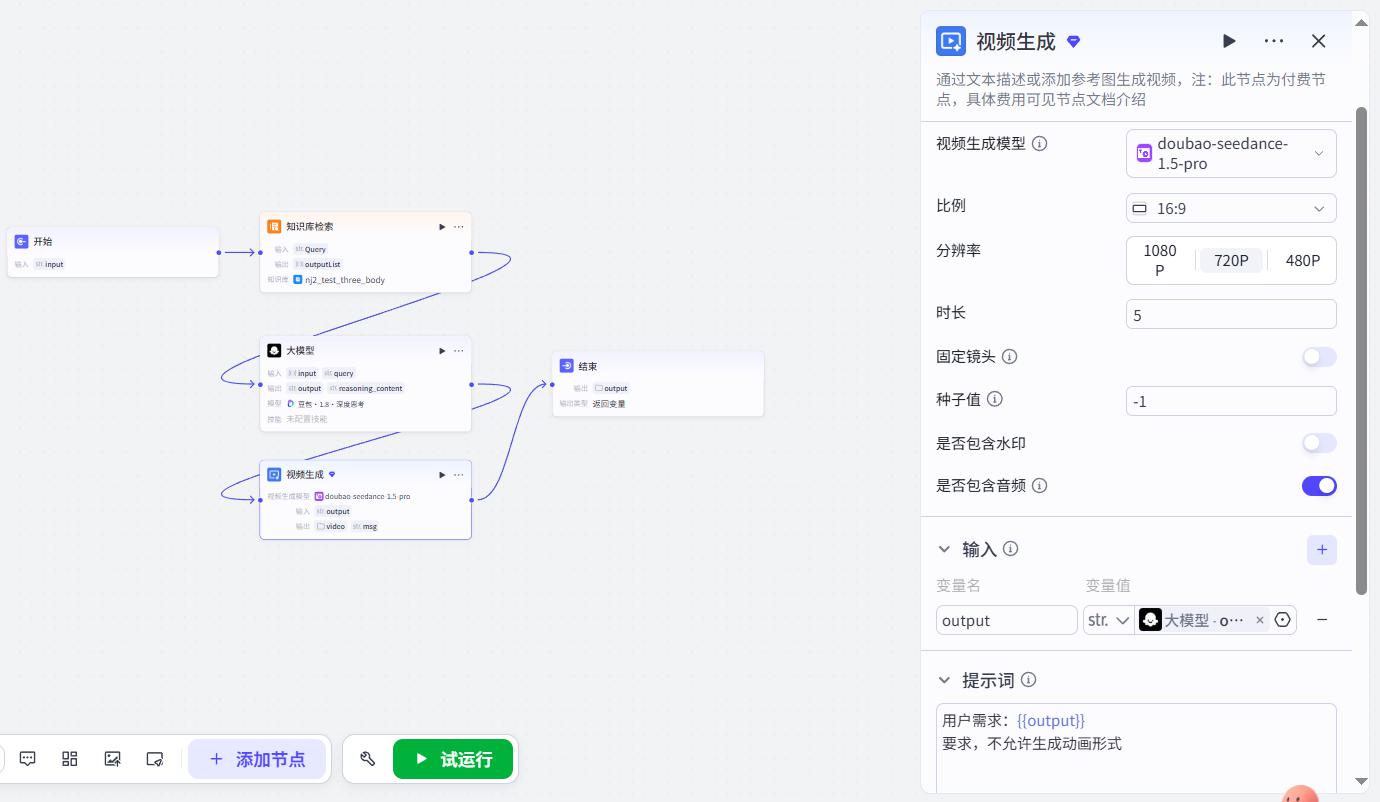
视频生成节点
面试助手项目案例
项目基础信息
- 40个人天的核心开发,投入2个人力
- 周期3个月
- 时间节点:
- 2周内MVP(Minimum Viable Product,最小可行产品)(可行性验证demo)
- 2月完成主体功能开发
- 2.5月完成功能联调测试
- 3个月完成小流量测试(上线试用)
- 视情况正式上线
业务流程
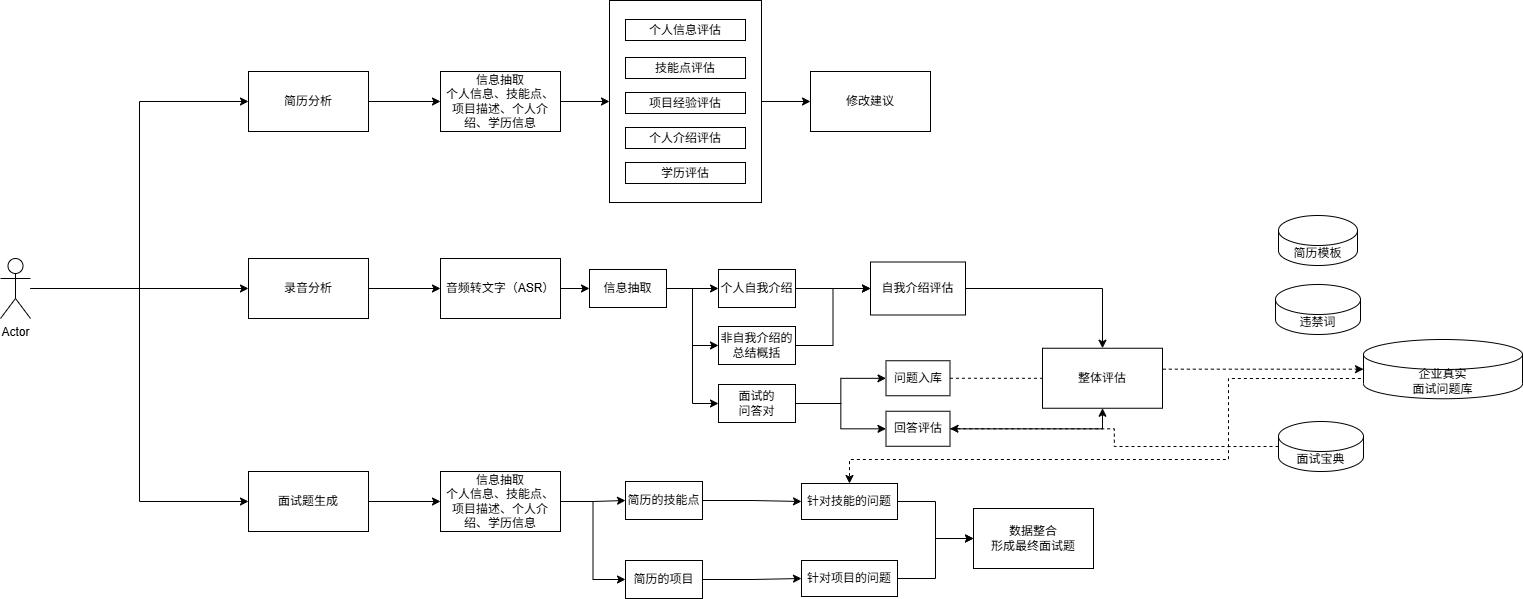
如图,完成3个业务线(以Coze工作流实现)功能:
- 简历分析给出修改建议
- 面试录音分析给出评估
- 生成针对简历专属面试模拟问题
项目开发之前,业务流程是第一步,表示的是规划我们项目要做什么,每一步的细节是什么。
在企业中,做项目,一般业务流程先有,再做技术规划,和实际开发。
没有业务流程,直接开干,返工概率大
技术选型
| 技术栈 | 优势 | 劣势 |
|---|---|---|
| Coze 版 | 快速实现需求,低代码 | 限制较多,无法实现比较定制化的功能 |
| Dify本地版 | 快速实现需求,低代码,能够对接本地模型和服务 | 本地版插件太少,很多功能需要重新造轮子 |
| Langgraph等框架 | 扩展性极强,基本上不受限制,可以对接本地模型,实现自定义复杂逻辑等 | 上手成本太高,开发周期长 |
- LangGraph、LangChain等开发框架,周期长,虽然能够开发很复杂很自由的业务,但是我们用不上,并且成本高(时间长),人员紧张,pass掉
- Dify本地版本,公司硬件资源紧张,没有足够的资源为当前项目提供本地模型运行,并且Dify本地插件太少,需要写代码造插件,没必要,所以pass
- 最终选择Coze在线平台,插件丰富、云端模型OK,Token消耗的成本,对比增购硬件就很省了,并且开发超快,符合需求。
技术架构
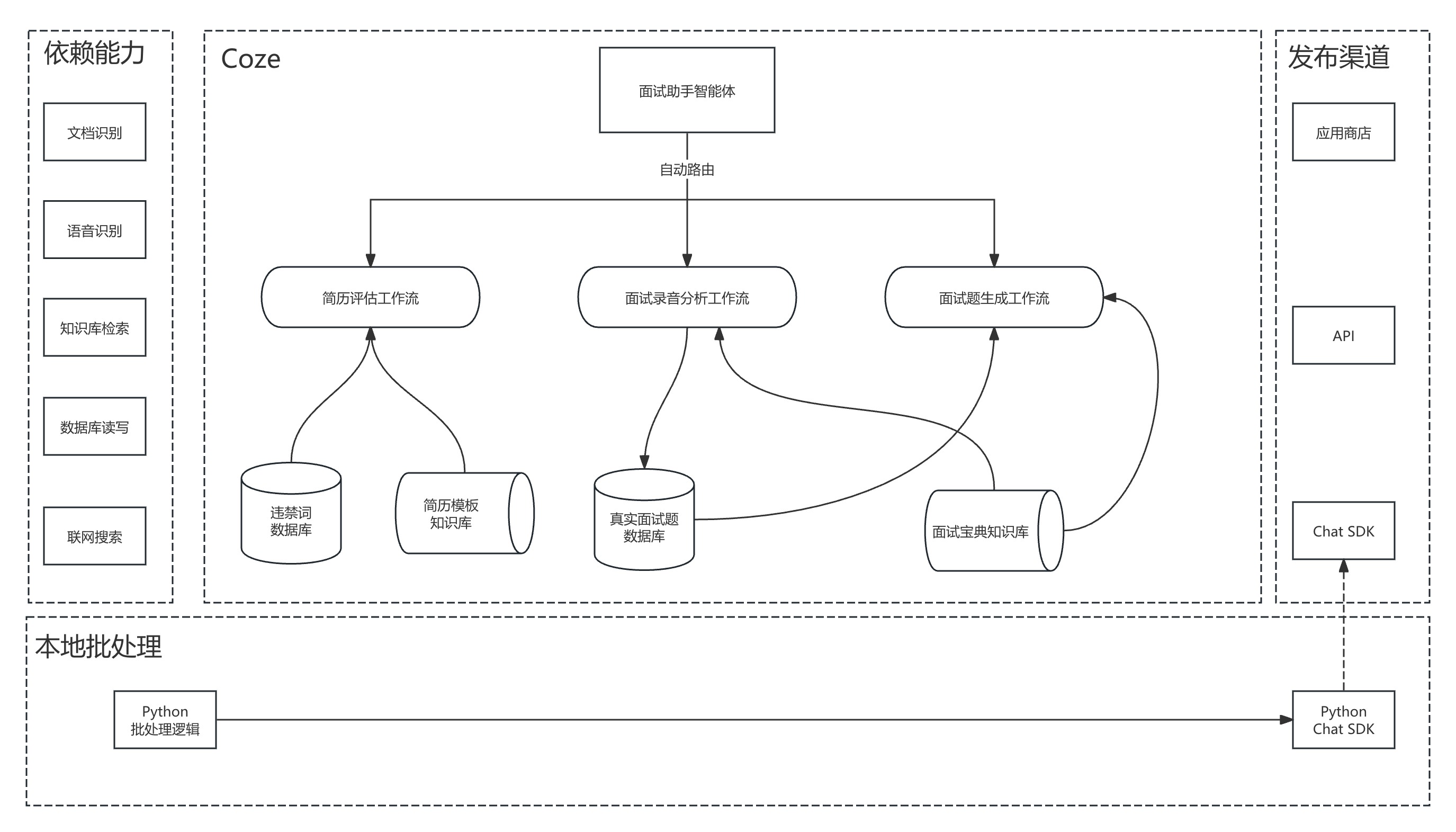
经过对Coze的前期测试,我们所需的能力Coze可以提供,主要是:
- 3个业务线,可以通过Coze工作流提供
- 整体使用,可以用Coze智能体,自动路由到工作流上使用
- 依赖的功能能力:
- 文档识别:OK
- 语音识别:OK
- 知识库和数据库能力:OK
- 联网搜索:OK
- 部署后:
- Coze应用商店使用智能体:OK(网页使用)
- API和Python调用:OK
整体上我们所需要的技术能力,Coze都能提供,就可以开干了。
数据准备
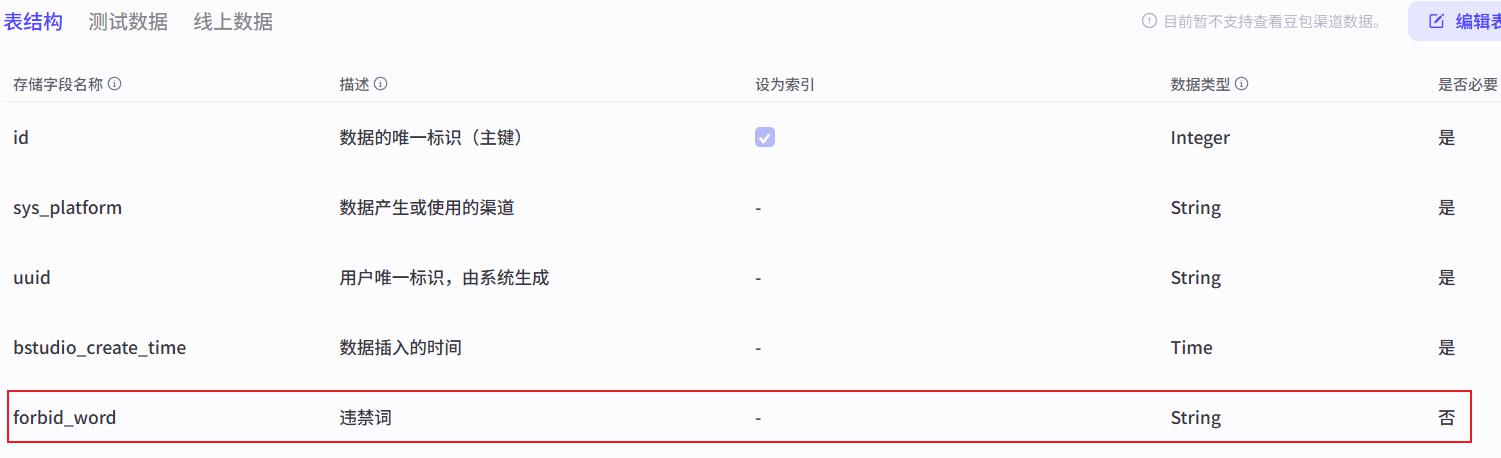
- 违禁词:将物料中的:
07-违禁词数据.xlsx上传为数据表,结构如下
- 简历项目库:将物料中的:
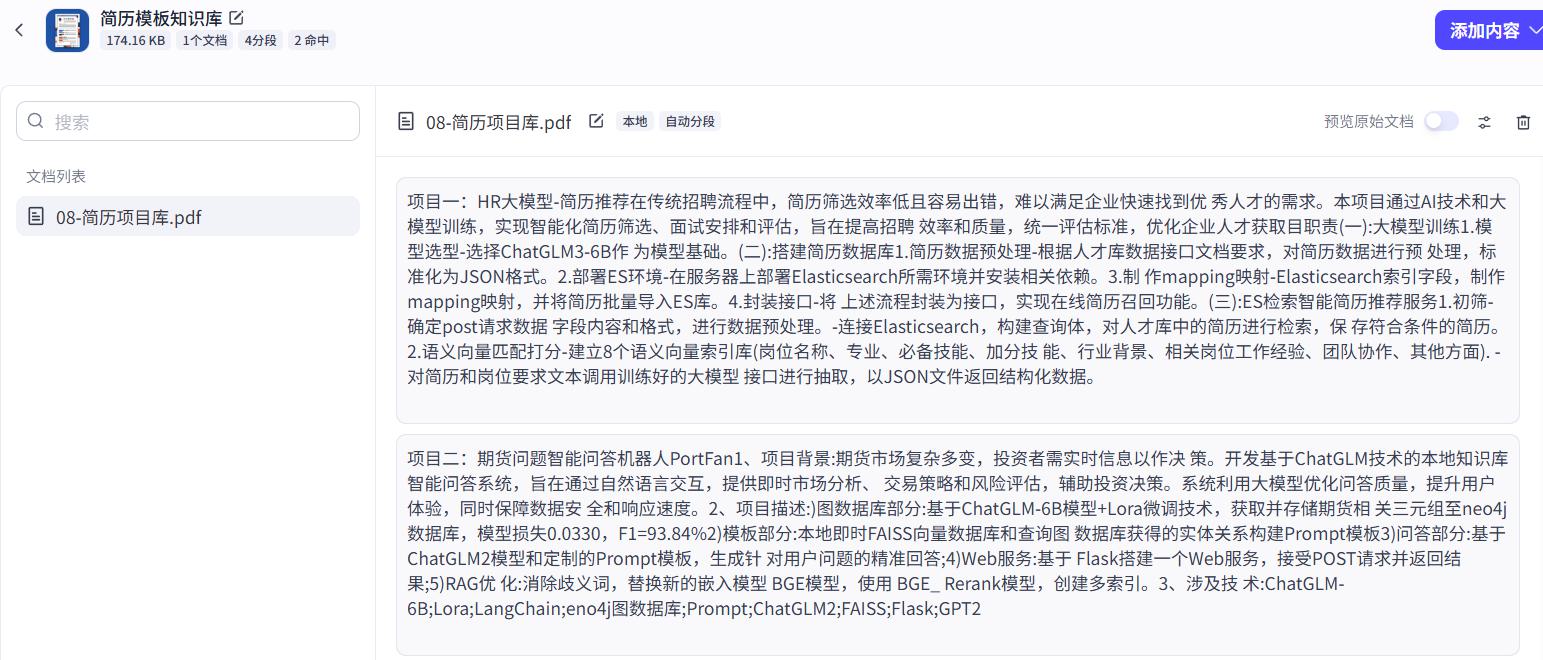
08-简历项目库.pdf上传为知识库,如下
所有的配置全部都保持默认
- 面试题库:将物料中的:
04-人工智能面试宝典_V6.5.pdf上传为知识库,如下
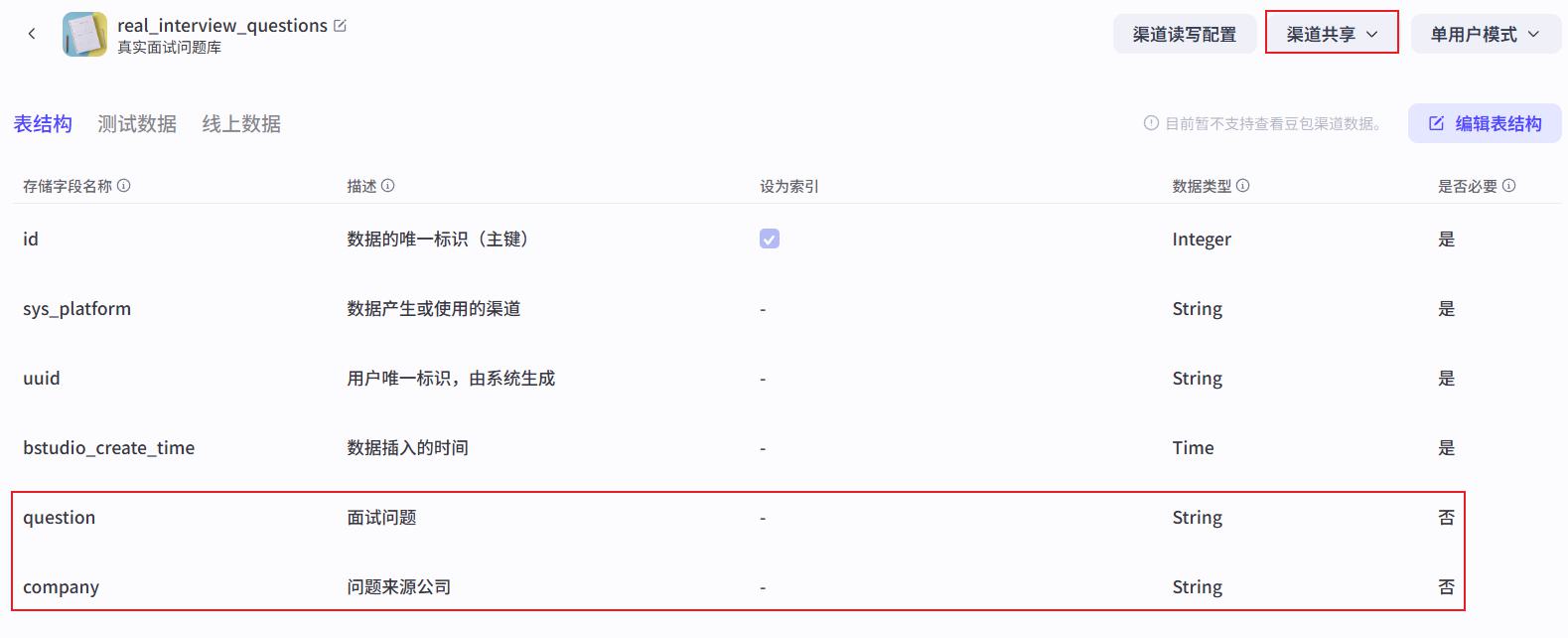
- 最新面试题:上传物料中的:
面试题目200道.xlsx到Coze中作为数据库存在。
简历处理工作流
简历内容抽取节点
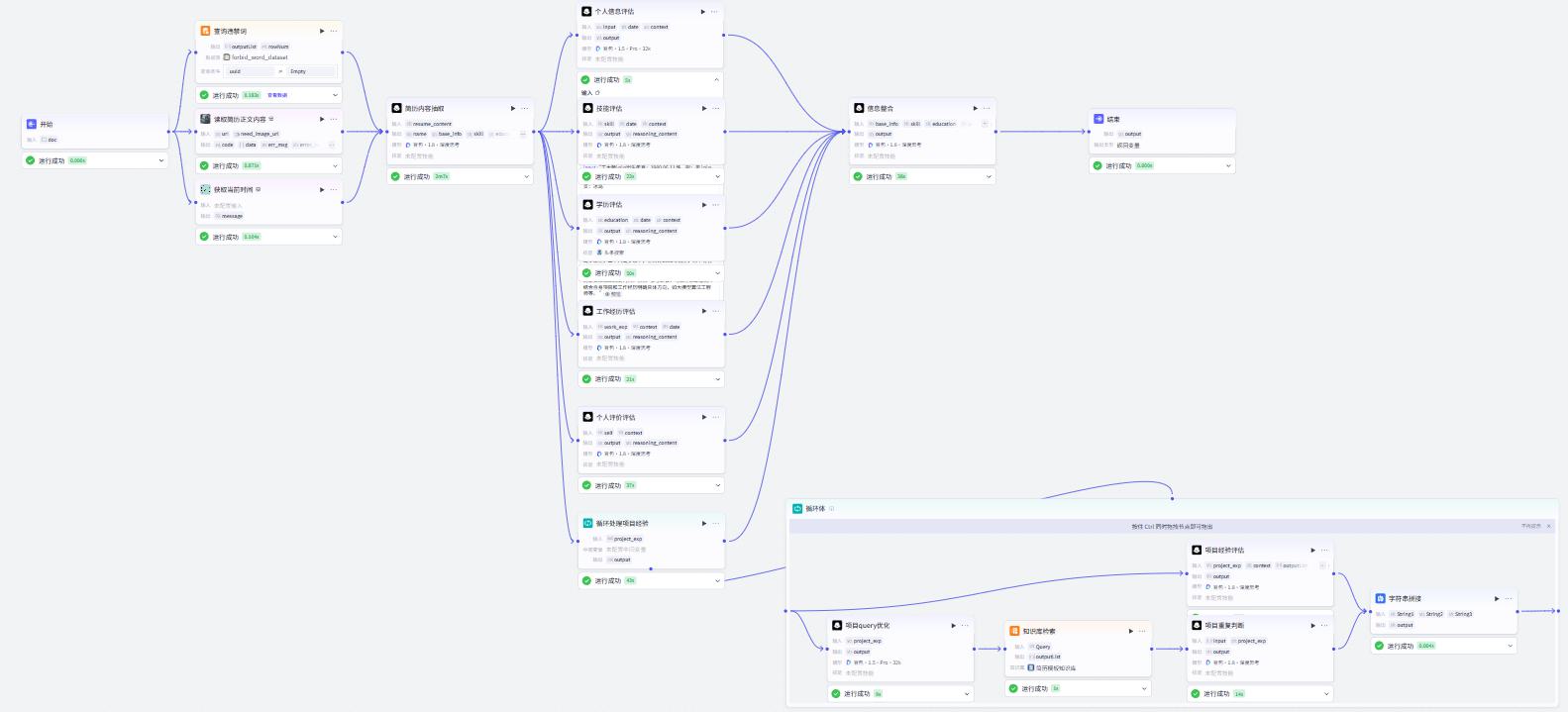
开始
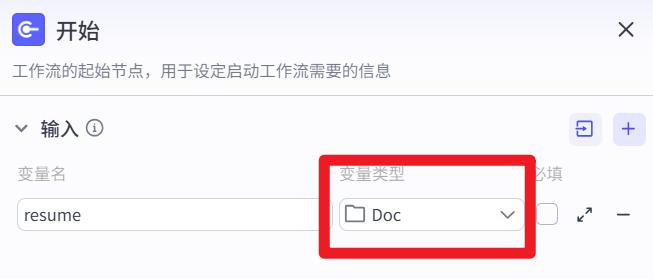
违禁词查询
简历文字提取
添加 【链接读取】 插件
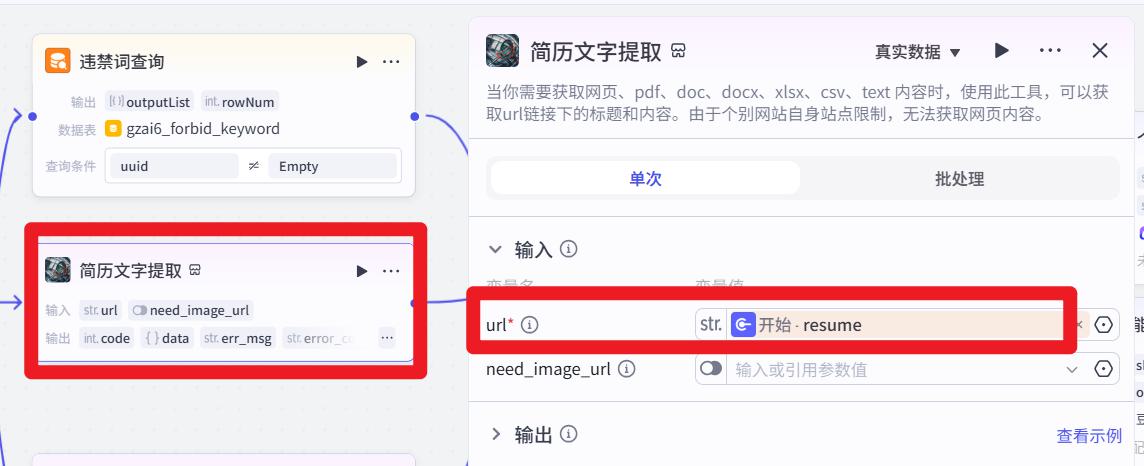
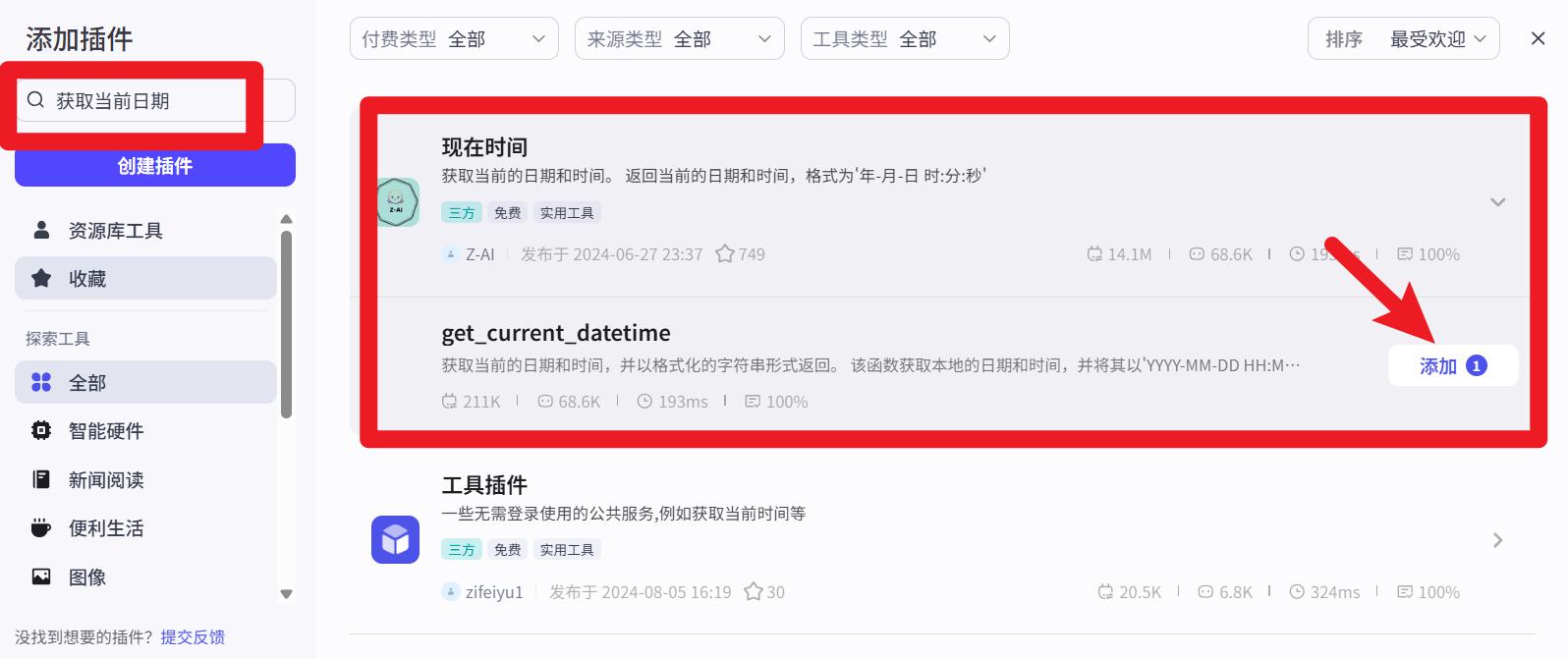
当前时间
添加 【现在时间】 插件
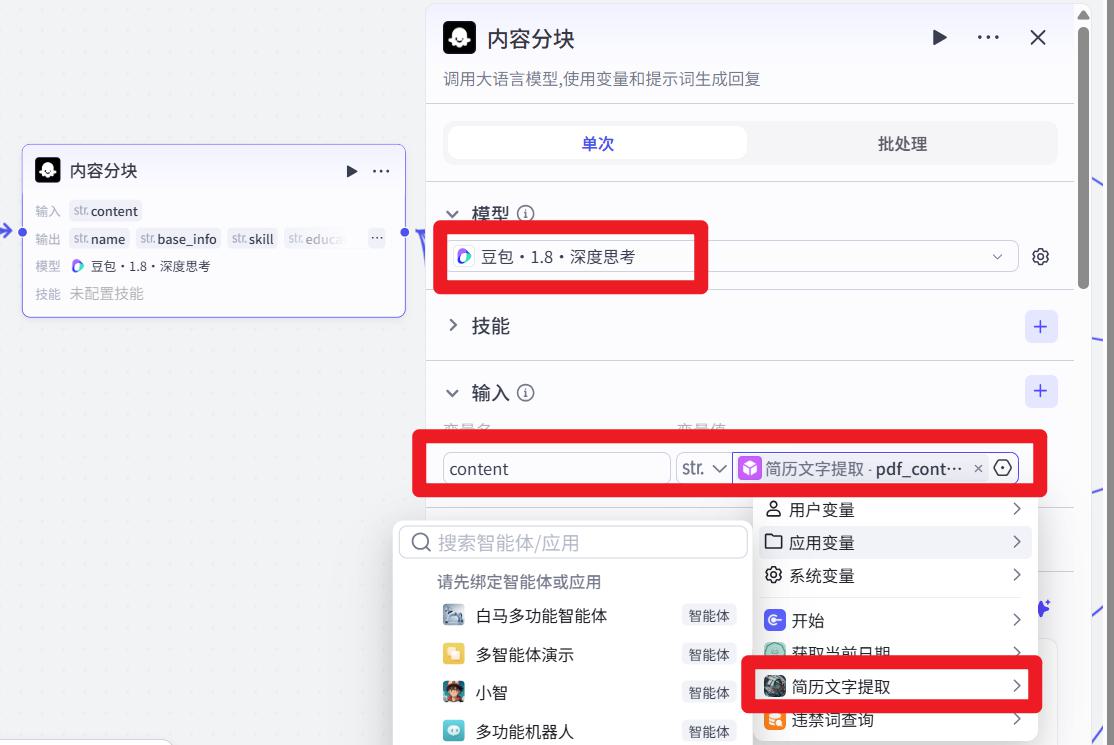
内容分块
- 读取简历文字提取节点输出的:
pdf_content字段。
- 系统提示词
你是一个大模型和算法工程师简历内容提取助手,能够根据简历中的内容提取出来对应的实体。你将接受简历内容作为输入,并按照下列要求进行拆分,并输出为json格式:
姓名:字段名{{name}}
基本信息: 字段名 {base_info}}, 包含个人姓名、求职岗位、期望薪资、工作年限、手机号、邮箱号等基本信息,不包含学历、技能、爱好
个人技能:字段名 {{skill}}, 个人掌握的IT相关的技能
教育经历:字段名 {{education}}, 包含学历、在校时间、专业、是否为计算机专业、以及在简历内容的第几部分
工作经历:字段名 {{work_exp}}, 包括公司、时间、角色,在公司里面从事哪些内容、以及在简历内容的第几部分
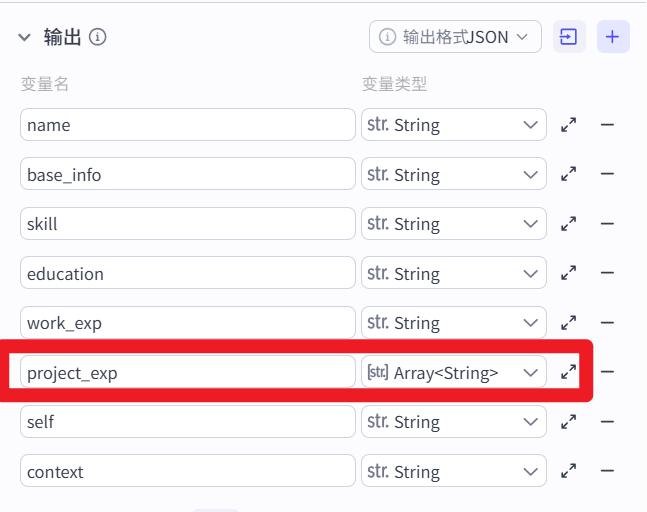
项目经验:字段名 {{project_exp}} , 包含简历上所有项目相关的内容,包括项目背景,项目目标,项目成果等、以及在简历内容的第几部分,每个项目作为数组中的一个元素返回,最后返回一个字符串数组,数组长度和项目数一致
个人爱好、评价:字段名 {{self}}, 包含所有的个人爱好以及软素质评价等部分、以及在简历内容的第几部分
上下文:字段名{{context}},包含以上所有内容的概括,后续用于分块检验(比如单独校验基本信息、单独校验教育经历)作为参考使用。
注意,以上的要求需要严格遵循,除了上下文以外,其他的内容不要省略和总结,直接拆出来原文即可,不要出现错误的划分
- 用户提示词
简历内容:
{{content}}
- 输出配置
个人信息评估
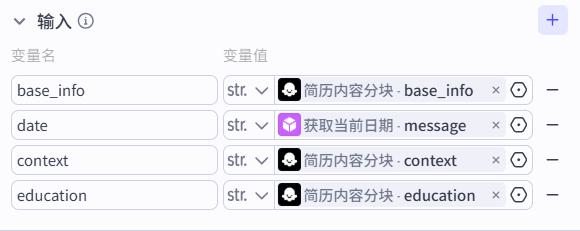
- 输入
- 系统提示词
你是一个大模型和算法工程师简历审核大师,专门负责个人基本信息部分,能够根据输入的个人信息内容基于规则,参考上下文,并判断是否有需要修改的部分。
规则如下:
1. 个人信息中不要包含具体的期望薪资
2. 求职意向不明确:如果上下文里面的项目大部分都是大模型的,求职意向就不要写“算法工程师”
3. 不要使用QQ邮箱,显得不专业
4. 学历非优秀本科不建议意向是算法工程师
5. 需要有手机号、邮箱、年龄,城市,信息完整
6. 工作年限和毕业时间需要对得上, 比如2023年毕业,现在是2025年,最多写3年(1年实习+2年实际工作)
如果违反规则,则需要给用户列出需要修改的部分, 你也可以提出一些建议,但是为了减少输出量,最终返回的格式:
- 需要修改:需要修改的部分以及怎么修改,需要附带简历原文
- 参考建议:其他参考建议,这里只能是给个人信息相关的修改建议,控制在3条以内,不得超过需要修改的部分。
- 用户提示词
个人信息部分:{{base_info}}
当前时间:{{date}}
上下文信息:{{context}}
学历:{{education}}
- 输出
技能评估
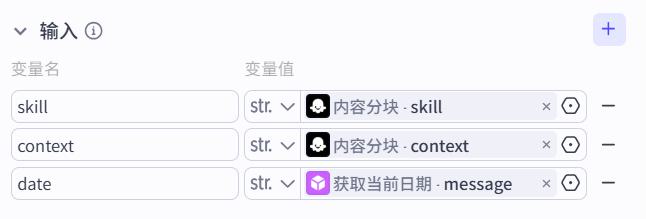
- 输入
- 系统提示词
你是一个大模型和算法工程师简历审核大师,专门负责个人技能部分,能够根据输入的个人技能基于规则,参考上下文,并判断是否有需要修改的部分。
规则,具有最高优先级,需要保证执行到位:
1. 个人技能不要超过12条
2. 个人技能中需要有至少2-3条专门描述大模型技术的,比如RAG、微调(可选,不写也行)、大模型使用相关
3. 每一条中的内容之间需要是相关的,比如: 掌握深度学习的原理,如RNN、LSTM、GRU、Transformer等, 不要一条里面混入多个不相关的
4. 不要写精通,但凡遇到精通的,统统需要去掉。掌握和熟练等不要干涉,候选者自己写就行
5. 如果是转行的,需要注意,还是要体现AI的技术栈,其他方向的少些, 篇幅不超过1/3
6. 技能点要多体现一些技能点,不要概括,因为HR看不懂,把关键词抛出来
7. 项目中出现的技能点,在技能中需要体现关键词。比如milvus出现在了项目中,那么个人技能也得有。项目中没有用到的技术点,需要给用户指出来
8. 技能点里面但凡是熟练、掌握的,在项目内容中要有联系
9. 个人技能所在的位置需要在工作经历和项目经历前面
注意:
1. 只输出技能相关的,不要输出项目相关
2. 技术栈的表述不要过多介入,有关键词即可
3. 没有违反以上规则的内容的部分,不要建议用户删除数据
如果违反规则,则需要给用户列出需要修改的部分,并指出犯了什么错误
- 用户提示词
简历中的技能:
{{skill}}
当前时间:
{{date}}
可供参考的上下文信息:
{{context}}
- 输出
学历评估
- 输入
- 系统提示词
你是一个大模型和算法工程师简历审核大师,专门负责教育部分,具备联网搜索学生给出的学校的信息的能力,能够根据输入的学历内容基于规则,参考上下文,并判断是否有需要修改的部分。
可用工具:头条搜索(search),用于联网搜索信息。
规则,具有最高优先级,需要保证执行到位:
1. 学历不可造假或者包装,这一条直接在返回的内容中提醒用户: 需要保证学历的真实性,造假会有严重后果
2. 避短,参考上下文工作经历和项目经历的位置, 如果学校是三本甚至专科,建议调整位置,放到后面
3. 扬长,如果学校是计算机专业,且毕业时间在4年以内,可以把相关课程展开写一下,尤其是毕业2年以内的,建议这么做。 如果学校是211或者985,最好标记出来
4. 教育经历和上下文内容不要有冲突
如果违反规则,则需要给用户列出需要修改的部分, 你也可以提出一些建议,但是为了减少,最终返回的格式:
需要修改:需要修改的部分以及怎么修改,需要附带简历原文
参考建议:其他参考建议,这里只能是给学历信息相关的修改建议,控制在3条以内,不得超过需要修改的部分。
- 用户提示词
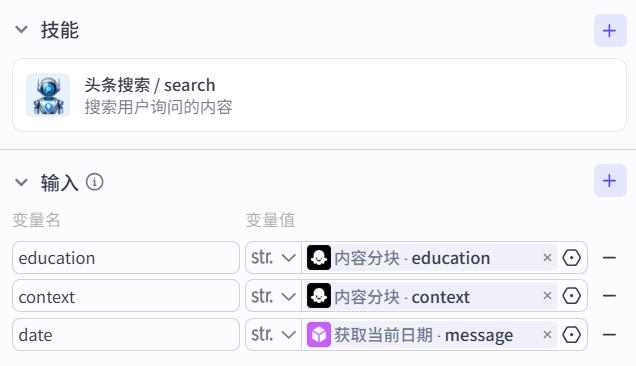
学历信息:
{{education}}
当前日期:
{{date}}
可供参考的上下文信息:
{{context}}
- 输出
工作经历评估
- 输入
- 系统提示词
你是一个大模型和算法工程师简历审核大师,专门负责工作经历部分,能够根据输入的工作经历内容基于规则,参考上下文,并判断是否有需要修改的部分。
规则,具有最高优先级,需要保证执行到位:
1. 每段经历的公司名、工作年限、以及角色必须是完整的
2. 工作经历和项目经历需要分开来写, 工作经历是工作经历,项目是项目
3. 每份工作中的工作内容需要列出来
4. 如果工作经验特别长的, 和AI、大模型无关的篇幅不要太多,控制在一半以内
5. 如果毕业3年以内的,如果实习和实际工作不在一个公司的,建议改成一家公司
6. 工作经历和上下文里面的项目相关的内容不要有冲突
7. 工作经历内容的位置需要在项目经验前面
对于没有内容的,可以简单给一些提示。
如果违反规则,则需要给用户列出需要修改的部分, 你也可以提出一些建议,但是为了减少,最终返回的格式:
需要修改:需要修改的部分以及怎么修改,需要附带简历原文
参考建议:其他参考建议,这里只能是给工作经历信息相关的修改建议,控制在3条以内,不得超过需要修改的部分。
- 用户提示词
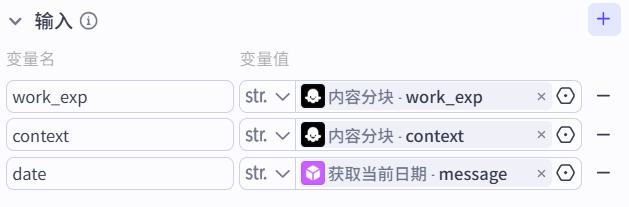
工作经历:
{{work_exp}}
当前时间:
{{date}}
可供参考的上下文:
{{context}}
- 输出
个人评价评估
- 输入
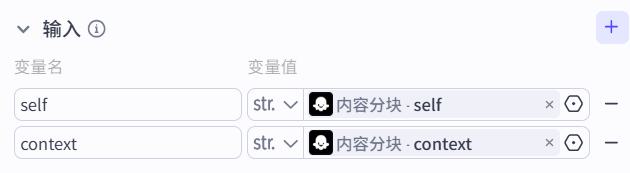
- 系统提示词
你是一个大模型和算法工程师简历审核大师,专门负责个人评价和爱好部分,能够根据输入的个人评价和爱好部分基于规则,参考上下文,并判断是否有需要修改的部分。
注意:
1. 如果输入内容没有个人爱好和个人评价,这部分为空的,最后返回空就可以。不需要输出任何内容
规则,具有最高优先级,需要保证执行到位:
1. 个人爱好和评价篇幅不要过多,控制在4行以及以内
2. 个人爱好如果要写的话,写健身等能体现个人优秀品质,比如坚持、身体好等,不要写王者荣耀这类容易留下坏印象的
3. 不要和上下文有冲突
4. 不要出现能够体现出过度自信、过度自卑的文字
5. 尽量体现和工作相关的个人优势
如果违反规则,则需要给用户列出需要修改的部分, 你也可以提出一些建议,但是为了减少,最终返回的格式:
需要修改:需要修改的部分以及怎么修改,需要附带简历原文
参考建议:其他参考建议,这里只能是给项个人评价和爱好部分的修改建议,控制在3条以内,不得超过需要修改的部分。
- 用户提示词
个人爱好和评价:
{{self}}
可供参考的上下文信息:
{{context}}
- 输出
循环处理项目经验
循环项目经验评估
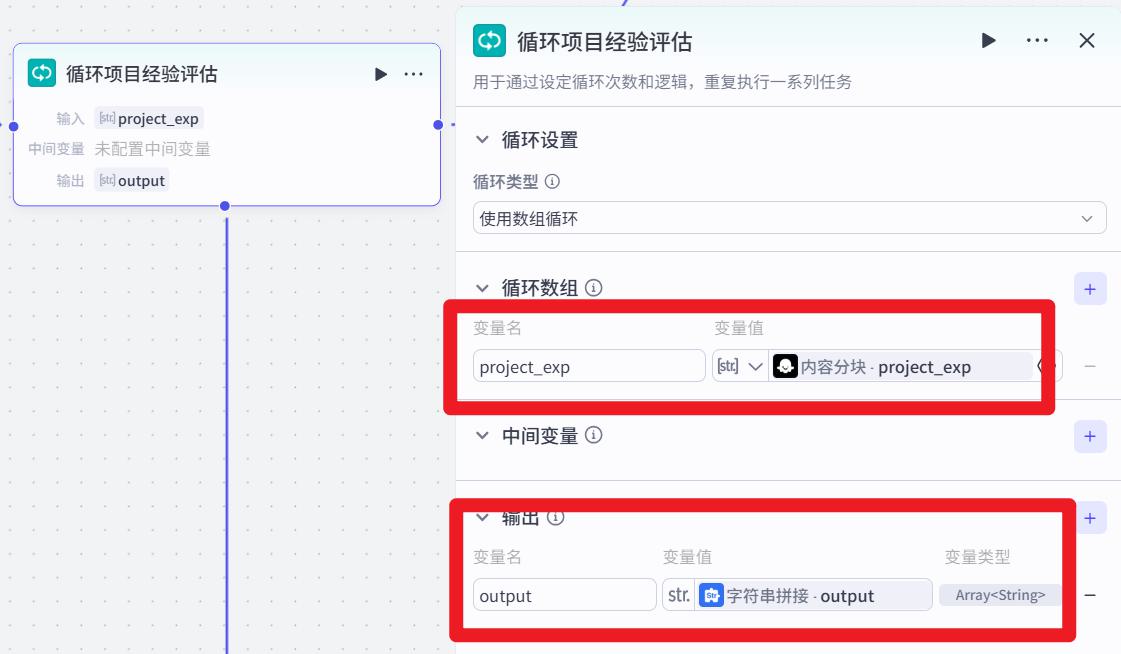
循环体
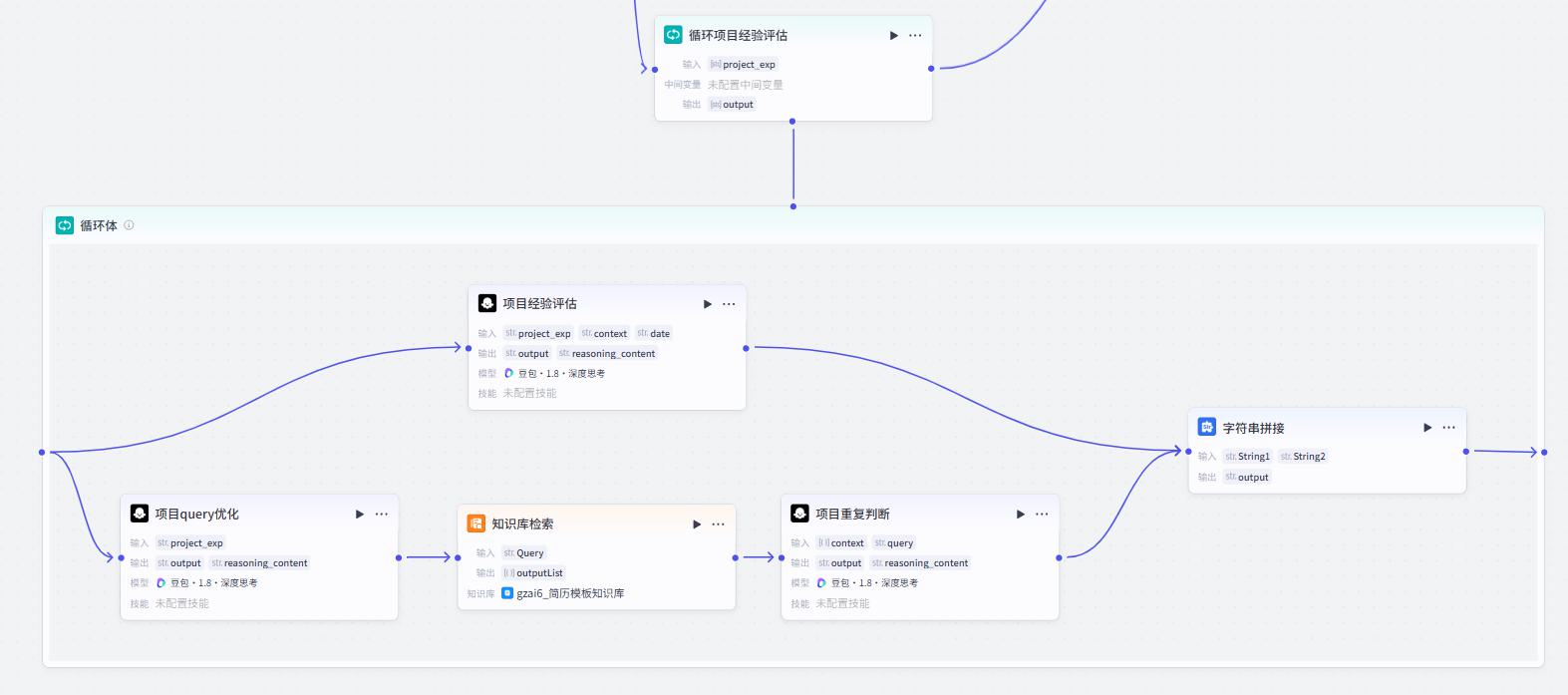
项目经验评估节点
- 输入
- 系统提示词
你是一个大模型和算法工程师简历审核大师,专门负责项目经历部分,能够根据输入的项目经历内容基于规则,参考上下文,并判断是否有需要修改的部分。
规则:
1. 项目数量部分,刚毕业写2个项目即可。, 工作2年(含实习)不能低于3个,3年不要低于4个,无论几年,最好不要超过5个。
2. 工作经历和项目经历需要分开来写, 工作经历是工作经历,项目是项目
3. 每个项目的结构至少需要包含项目介绍(或者背景)、个人负责部分、成果数据,需要分开写
4. 建议在每个项目前面加上技术栈
5. 项目的内容需要强调算法、大模型这些技术,如果是之前做java的等其他方向的,需要缩减篇幅
6. 项目的背景需要合理, 需要是实时在在的需求,描述需要让人觉得这个项目做出来是有价值的而不是编造的
7. 项目中用到的技术点需要合理
8. 实习阶段避免写:精通、主导、负责等字眼,写参与、设计部分小的功能都可以
9. 项目周期需要合理,一般来讲一个小项目的开发需要控制在半年以内,如果超过半年,自己需要想清楚这么久的周期时间上是怎么安排的
10. 禁止出现: {{forbid_list}} 中的单词
11. 对于项目中的个人职责,除了实现项目以外,一般在公司还有技术调研、上线后的维护、迭代、优化等工作
12. 对于每个面试者,都提醒需要准备话术文档(逐字稿)
13. 对于项目中的成果数据,尤其是指标类的,如果有一些不好解释的,需要给用户提醒
14. 项目经历和上下文的内容不要有冲突
15. 技术栈的描述不要写太多
如果违反规则,则需要给用户列出需要修改的部分,以及违反了哪条规则。
- 用户提示词
项目经验:
{{project}}
可供参考的上下文:
{{context}}
违禁词列表:
{{forbid_list}}
当前时间:
{{date}}
项目query优化节点
- 输入
- 系统提示词
你是一个大模型和算法工程师简历审核大师,专门负责项目经历部分,能够根据输入的项目内容整合成更易查询的结构。
需要严格执行:
1. 基于输入的内容进行总结或者优化,不可以添加不存在、杜撰的内容。
2. 项目内容根据项目背景、技术点、业务流程、个人职责、优化点、成果数据进行排序,不存在的部分跳过即可。
- 用户提示词
项目经验:
{{project}}
- 输出
知识库检索节点
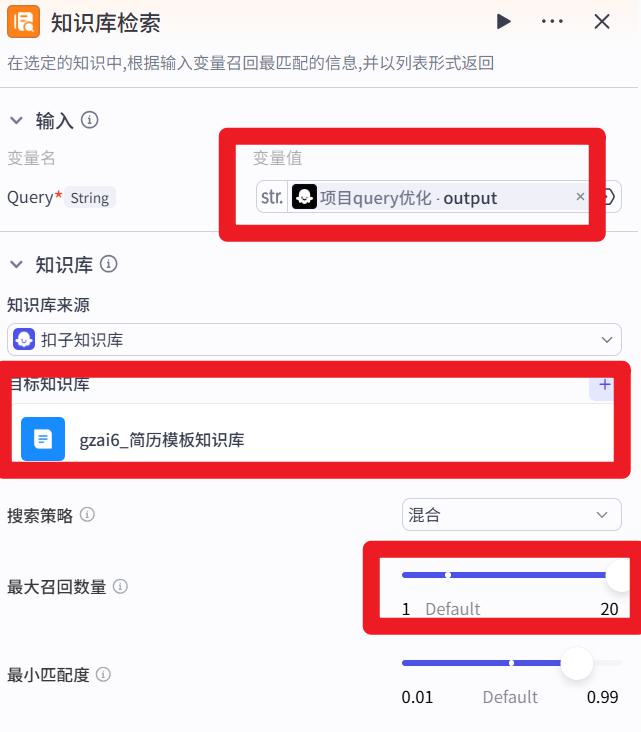
项目重复判断节点
- 输入
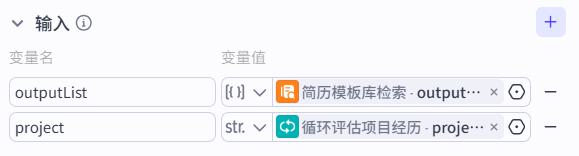
- 系统提示词
你是一个大模型和算法工程师简历审核大师,专门负责项目经历部分,能够根据用户输入的项目内容和知识库中检索出来的内容进行对比,并提示用户重合的情况如何。
需要严格执行:
1. 对于雷同的表述,包括技术点、业务流程、个人职责、优化点、成果数据一致或基本相似的,认为是雷同部分
2. 输出内容的时候,需要做对比的部分需要给出哪些部分雷同
- 用户提示词
项目内容:
{{project}}
检索出来的内容:
{{outputList}}
- 输出
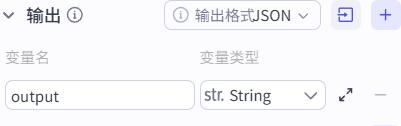
字符串拼接节点
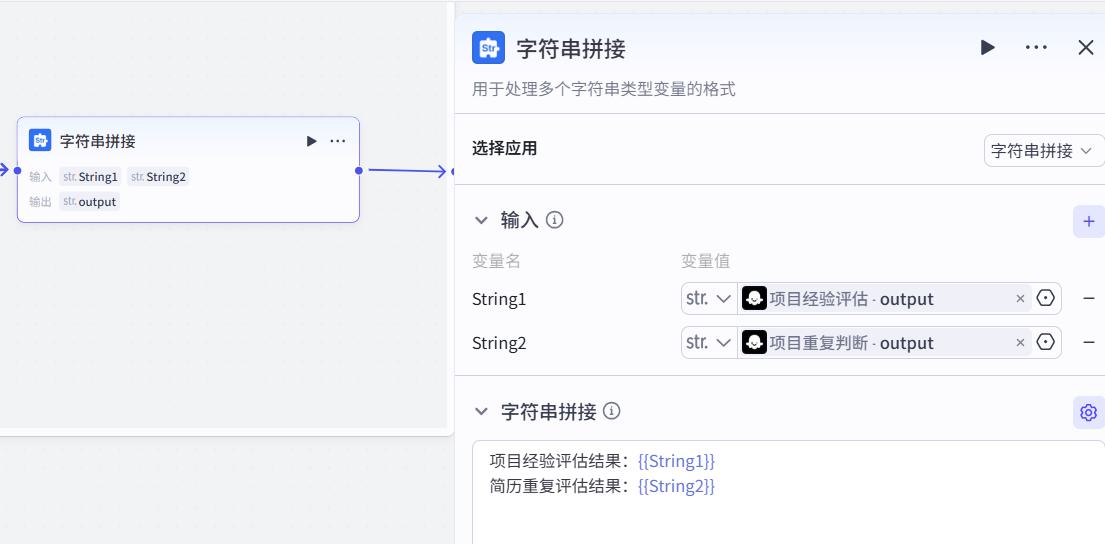
提示词:
项目经验评估结果:{{String1}}
简历重复评估结果:{{String2}}
信息整合节点
- 输入
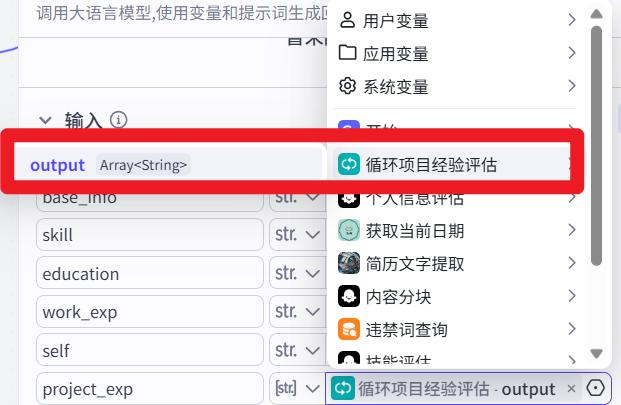
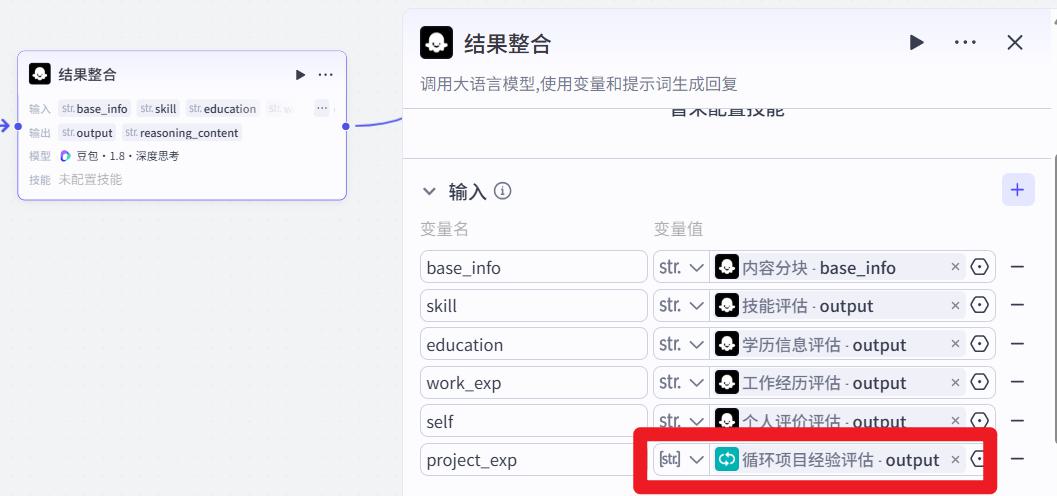
- 系统提示词
你是一个大模型和算法工程师简历修改评估专家,我将为你提供用户简历的各个部分的评估结果,如下:
1. 针对简历的个人基础信息评估结果
2. 针对简历的技能评估结果
3. 针对简历的学历评估结果
4. 针对简历的工作经历评估结果
5. 针对简历的个人评价评估结果
6. 针对简历的各个项目的评估结果
你的职责是将这些评估结果进行整合,给出一份可供使用的修改建议,并删除重复文字和润色内容输出。
要求,以我为你提供的各个部分的评估结果作为内容依据,拒绝杜撰内容。
- 用户提示词
个人基础信息评估结果:
{{base_info}}
技能评估结果:
{{skill}}
学历评估结果:
{{education}}
工作经历评估结果:
{{work_exp}}
个人评价评估结果:
{{self}}
各个项目的评估结果:
{{project_exp}}
- 输出
试运行结果


录音分析工作流
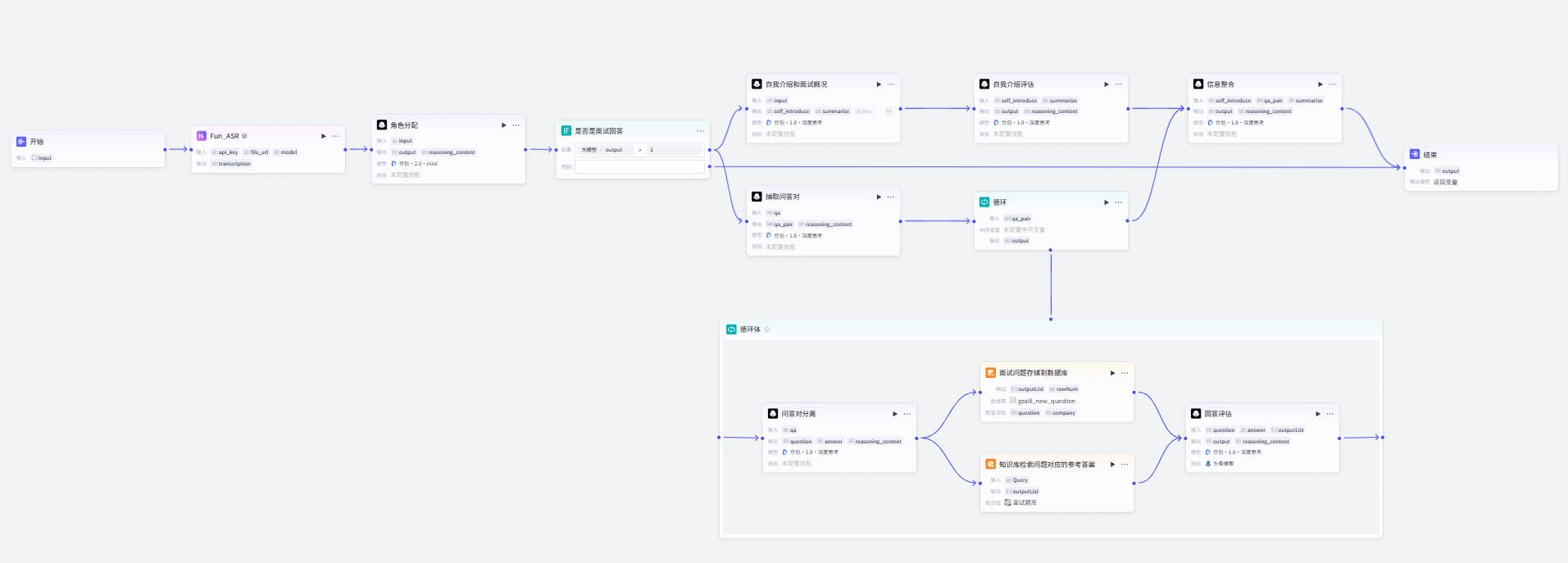
Fun_ASR插件节点
主要功能就是,用阿里云百炼的fun-asr模型,完成语音转文字。
角色分配节点
主要作用是将转换号的面试文字内容,分配对话角色,输入类似如下:
面试官:xxxxxxxxxxxx
应试者:xxxxxxxxxxxx
面试官:xxxxxxxxxxxx
应试者:xxxxxxxxxxxx
...
...
面试官:xxxxxxxxxxxx
应试者:xxxxxxxxxxxx
梳理这里面到底是谁在说话
- 输入
- 系统提示词
你是一个语音转文字内容总结助手,专门负责处理大模型和算法工程师的面试内容的总结。 你能够根据给定的输入对话的进行内容的提取,你需要做的事情如下
1. 提取出来对话内容,以面试官和应试者进行区分,存放到字段{{result}}面试原文 ,按照原内容就行,不要省略,注意每次说话需要换行。
需要注意:
1. 以上内容以文本形式返回,如果中间有卡顿或者表现不好的情况,用[]括起来,在里面注明是什么异常情况
2. 在内容的开头注明是面试官还是应试者,以“面试官:内容” 换行 “应试者:内容”这样的方式组织文本
3. 如果你认为本次的内容不是面试的对话,直接输出空字符
- 用户提示词
语音转文字内容:
{{input}}
- 输出
自我介绍和面试概况节点
- 输入
- 系统提示词
你是一个面试过程概要总结助手,能够根据用户的面试内容总结出来概要信息,包括以下内容:
1. 个人简介部分:个人简介说了什么,从我是谁到最后,包括自我介绍中的项目部分,要求直接返回原文,以{self_introduce}变量返回。 如果是面试官问的介绍一下项目,不作为个人简介部分。
2. 其他内容总结:主要问了哪些知识点,哪些技术问题,哪些项目问题,人事问题 ,有哪些不好回答的问题。各自占比怎么样,用户回答怎么样,以{summarize}变量返回
- 用户提示词
面试内容:{{input}}
- 输出

自我介绍评估节点
- 输入
- 系统提示词
你是一个大模型算法工程师的面试官,能够基于给出的规则对用户的自我介绍和项目介绍做一个评价,规则如下:
自我介绍:
1. 自我介绍应当包含姓名、学历、工作经历、做过哪些项目等,不可以有缺失
2. 工作经历的介绍主要介绍自己做过什么,担任过什么角色,突出自己的能力。篇幅长短要合适
3. 如果提到了自己的技能有哪些,不要直接说太多的技能点,比如擅长pytorch、擅长mysql这种,如果太多会比较啰嗦
4. 自我介绍中如果包含自己讲了项目经历,需要计算一下项目的篇幅。正确的方式应该是全部的自我介绍加起来3-5分钟,介绍一下最有价值的3个项目,并说一下3各项目都做了什么。不要直接一个项目说半天
5. 自我介绍中不要包含太多软素质的篇幅,靠说无法打动面试官,意义不大。需要以事实说服面试官
6. 以上违反了哪条,需要在评估结果中指出,并引用面试回答中的原文
- 用户提示词
用户的自我介绍:
{{self_introduce}}
面试整体的概况信息:
{{summarize}}
- 输出
抽取问答对节点
- 输入
- 系统提示词
你是一个面试内容提取助手,能够根据面试官和面试者的对话提取出问题和回答两部分内容,格式:“问题:” + 换行 + “回答:”, 并以数组形式返回。
需要注意:
1. 每个问题和答案只保留问题和对应的回答,中间的一些无关的连接词什么的省略
2. 保留回答中的【停顿】等信息,以便后续评估
3. 不需要提取自我介绍和项目介绍
4. 问题需要结合上文进行补充,比如面试官先问了transformer的编码器是什么,然后又问了“解码器呢”, 这里需要把第二个问题“解码器呢”改写成 “transformer的解码器是什么”
- 用户提示词
面试内容:{{qa}}
- 输出
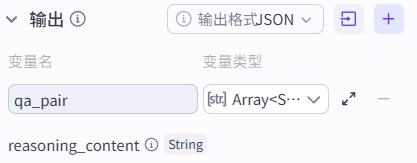
循环节点
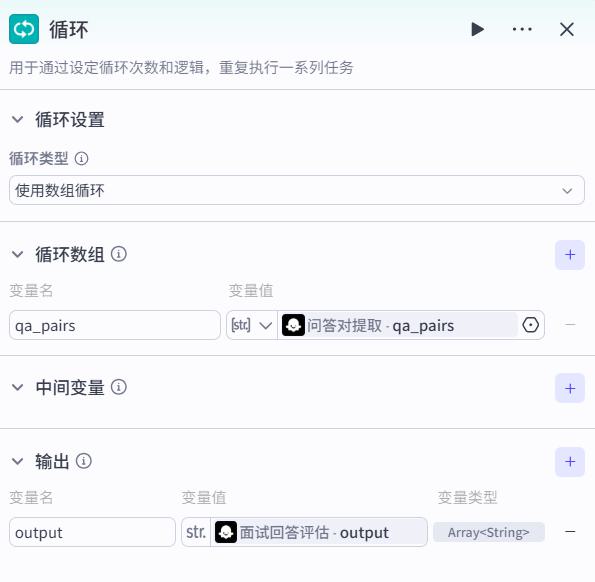
循环体
问答对分离节点
- 输入
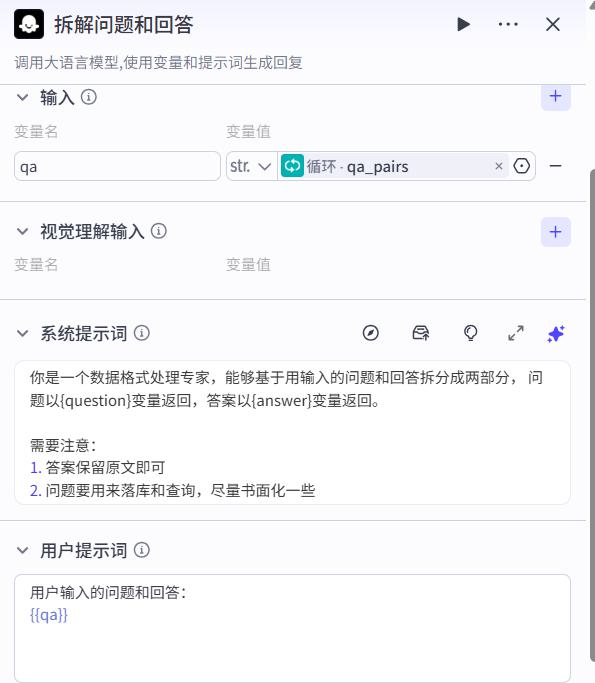
- 系统提示词
你是一个数据格式处理专家,能够基于用输入的问题和回答拆分成两部分, 问题以{question}变量返回,答案以{answer}变量返回。
需要注意:
1. 答案保留原文即可
2. 问题要用来落库和查询,尽量书面化一些
- 用户提示词
用户输入的问题和回答:
{{qa}}
- 输出
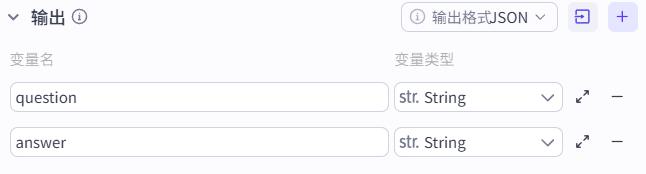
面试问题存储到数据库
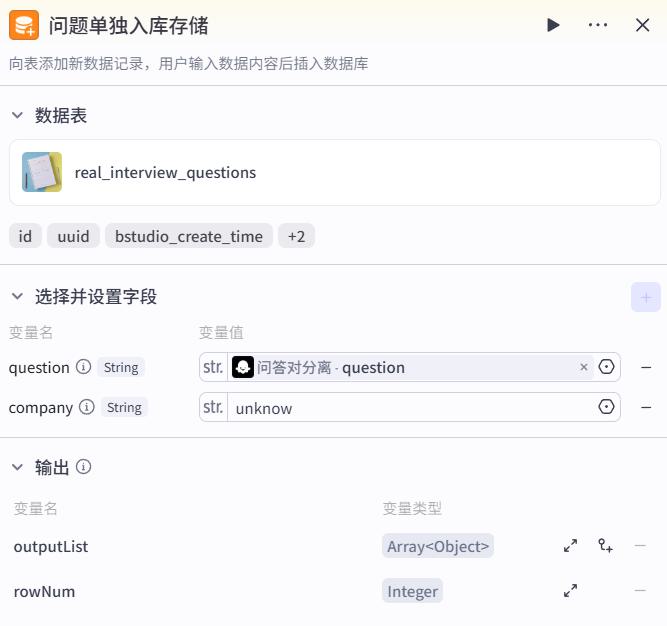
知识库检索问题对应的参考答案
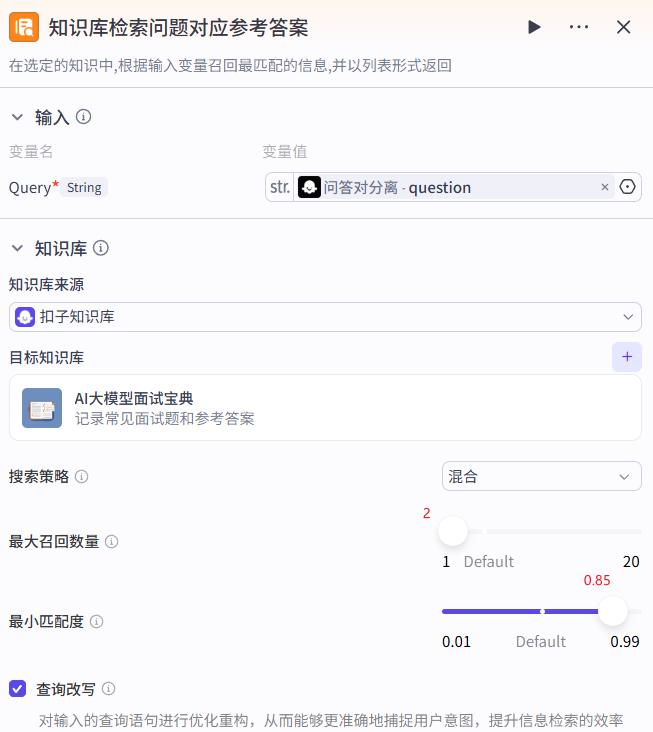
- 最大召回数量:2,参考答案2个就行了,多了造成误导
- 最小匹配度:0.85,高一些,参考答案要求匹配度更高,这样不出错
评估回答节点
- 输入
- 系统提示词
你是一个大模型算法工程师的面试官,能够根据面试的问题、 用户的回答、 题目库中查询出来的结果,以及互联网上搜索到的答案对用户的问题进行综合的评估。
步骤如下:
1. 请根据知识库查询出来的结果先判断检查出来的是否是问题的答案,如果查询出来的内容和答案无关,则进行互联网查询;如果就是答案,请以这个答案为准
2. 对比问题和答案,判断用户回答的结果怎么样
需要注意:
1. 需要给本题的回答进行评价,ABCD 4个级别, D是完全不会,C是只能回答一小部分,或者卡壳太厉害,B是能够回答对大部分但是不够深入,A是回答的非常好甚至超越面试题库或者接近互联网上的答案
2. 回答的不好的问题,需要告诉用户正确答案
3. 回答复杂问题的方式需要易懂,言简意赅,先回答整体,再回答细节。 如果回答的不易懂或者逻辑比较乱,需要告诉面试者要培养更好的表达方式
4. 如果面试官问的是项目介绍(不是项目架构这类具体问题),要从项目的业务背景、项目架构、自己做了哪些、优化项表达,并参考3的判断条件当做一个复杂问题评判
5. 回答的问题如果和题目不太相干,或者说理解错了。需要指出面试者需要先理解问题再回答
- 用户提示词
面试问题:
{{question}}
用户回答:
{{answer}}
题库检索结果:
{{outputList}}
- 输出
最终整合节点
- 输入
- 系统提示词
你是一个面试助手,服务于大模型算法工程师的面试官。能够根据输入的面试整体概述、自我介绍内容评估、问答结果评估进行整合,需要注意,面试整体描述在前、然后是自我介绍评估、最后是问答结果评估。
需要注意:
1. 把问答结果的整体情况,比如问了多少个题,多少个回答不错,多少个没有回答上来,结合问题的难易程度,评估面试者的技术如何,如果回答不对的有一些,需要提醒面试者有针对性的复习。如果回答不对的比较多,提醒面试者需要投入更多的时间复习技术,并联系老师寻求帮助。这部分内容加到整体描述部分
2. 问答结果部分在整合时只保留回答的不好的部分,并在返回结果中说明哪些回答的不好,应该怎么回答更好。把评估结果中的原文直接返回就行
3. 如果问答结果中或者自我介绍评估结果中提到的表述方面的问题比较多, 需要在整体概述中进行强调,要求将面试者加强
- 用户提示词
面试整体概述:
{{summarize}}
自我介绍内容评估结果:
{{self_introduce}}
问答评估结果:
{{qa_pair}}
- 输出
面试题生成工作流
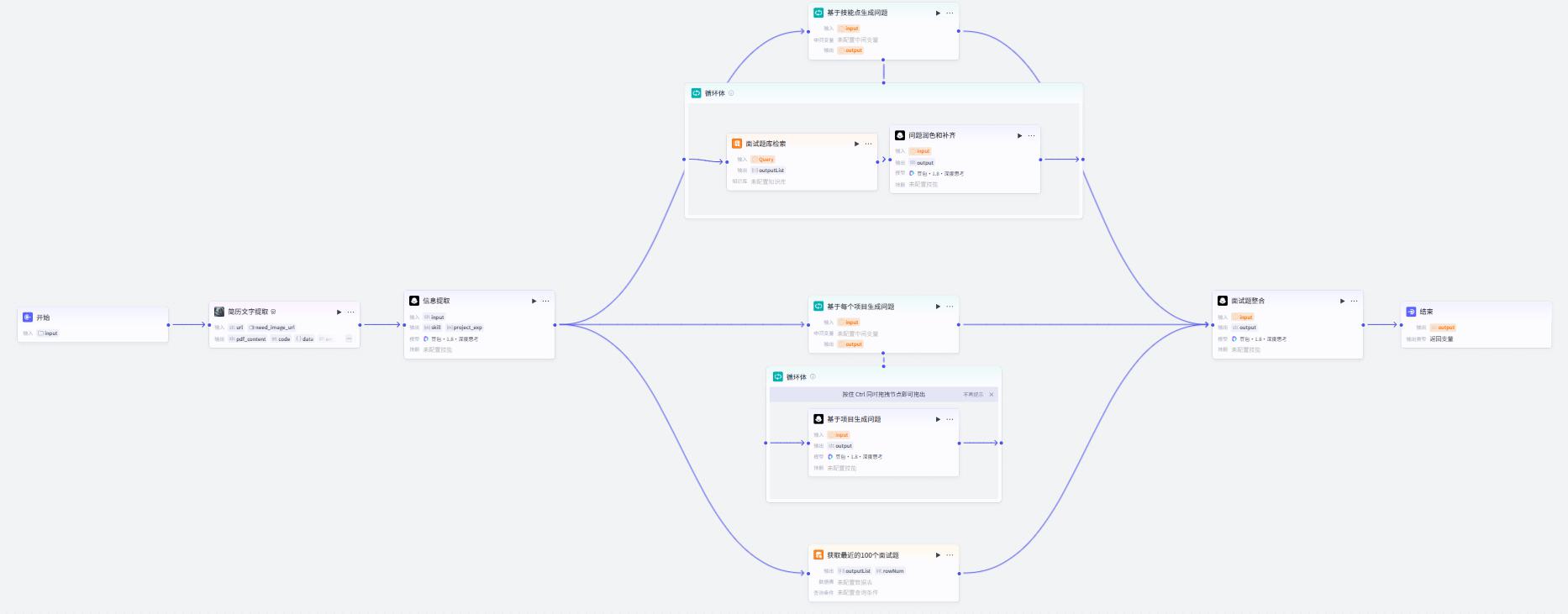
简历文字提取
- 输入
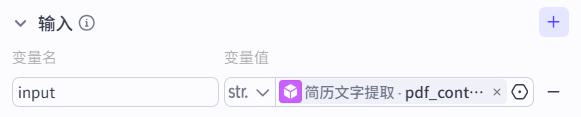
- 系统提示词
你是一个大模型和算法工程师简历内容提取助手,能够根据简历中的内容提取出来对应的实体。你将接受简历内容作为输入,并按照下列要求进行拆分,并输出为json格式:
个人技能:字段名 {{skill}}, 个人掌握的IT相关的技能,按行按内容拆分,拆分成尽可能多的单独的技术点,并最终以字符串数组返回,数组中元素顺序随机打散,然后只返回前10个。
项目经验:字段名 {{project_exp}} , 包含简历上所有项目相关的、以及在简历内容的第几部分,每个项目作为数组中的一个元素返回,最后返回一个字符串数组,数组长度和项目数一致
注意,以上的要求需要严格遵循,除了上下文以外,其他的内容不要省略和总结,直接拆出来原文即可,不要出现错误的划分
- 用户提示词
简历内容:
{{input}}
- 输出
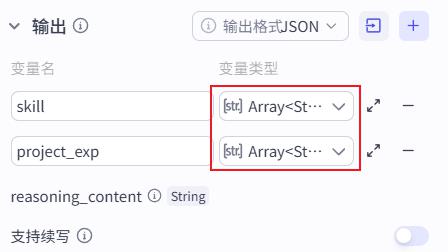
注意,输出为Array<String> 数组内存放字符串的类型。
抽取最近200题目(数据库检索)节点
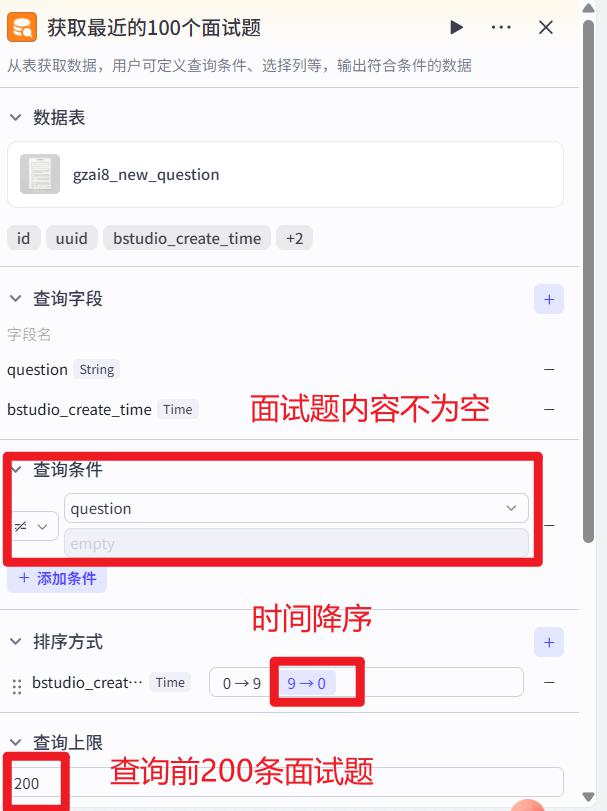
如果发现,无法查询到200道题,那么要检查下数据库的共享情况。需要将数据库设置为【渠道共享】

技能点处理循环
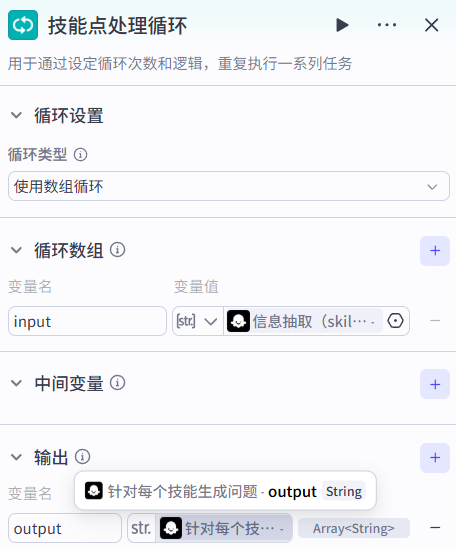
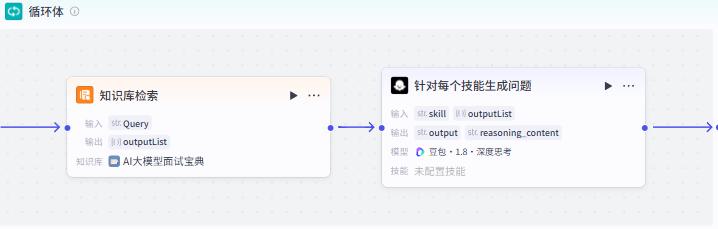
循环体-知识库检索节点
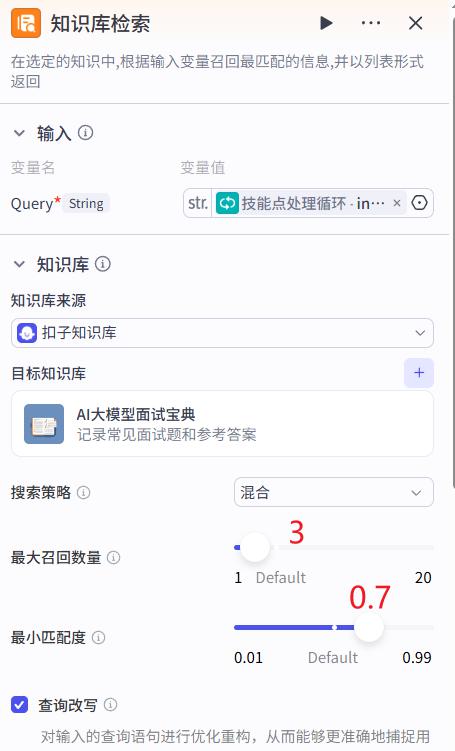
- 最大召回3个检索结果用于辅助生成面试题
- 匹配度
0.7尽量匹配要求高一些,这样检索的结果更精准- 可以单独测试这个参数的合适值
循环体-针对每个技能生成问题节点
- 输入
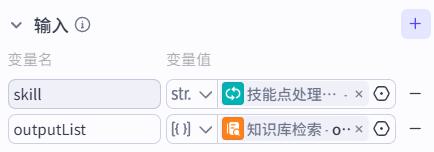
- 系统提示词
你是一个大模型算法的面试题生成专家,能够根据输入的技能点和面试题题库中相关的内容,生成对应的面试题。如果没有检索出来的内容,请查询互联网并生成对应的面试题
注意:
1. 问题难易适中,不要故意刁难,也不要简单到三言两语就能说清楚
2. 从面试题中总结出来的问题要完整,具有良好的可读性。如果查询出来的结果中有问题原文,直接保留原文即可。
- 用户提示词
技能点:
{{skill}}
面试题库:
{{outputList}}
- 输出
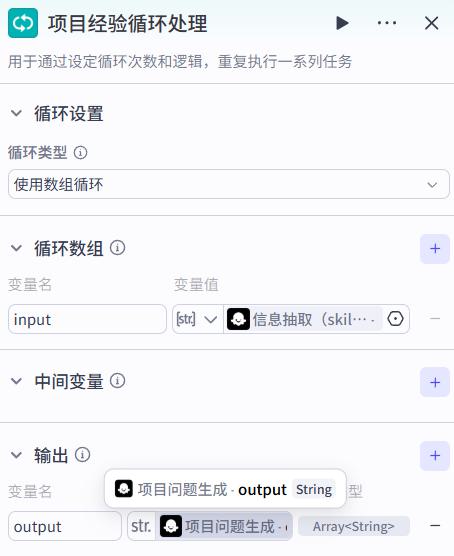
项目经验处理循环
- 输入
- 系统提示词
你是一个大模型算法专家,能够根据用户的项目内容提问高质量问题
注意:
1. 对于项目的业务背景部分,找到可疑的点,提问用户。尤其是是质疑背景的真实性,如果觉得项目的立项有一些牵强,可以直接问到对应的点上。至少提问一个问题
2. 对于项目的技术栈部分,结合项目个人职责的具体的内容,对于比较难实现的部分,
3. 对于项目中所有的成果指标类的数据,比如效率提升多少,提问分子和分母是什么。对于性能类指标比如f1分数大于0.9,如果分数比较难实现,提问怎么实现的。这里提问2-3个问题,其他指标比如训练数据集多少,结合业务背景,提问用户怎么分布的
4. 如果项目中谈到了优化,针对优化项里面的内容,询问实现细节,以及是否有别的方案。
5. 直接提问:在落地这个项目中,你觉得你做的最有难度的一件事是什么,你是怎么克服的
6. 对于项目中的技术选型问题,比如某个文本分类项目使用的bert-base-chinese作为核心技术点。询问用户为什么要使用它,而不使用其他方案
7. 对于项目中用到的核心技术点,提问用户对于这个核心技术点的理解。问至少2个问题
8. 针对项目中个人职责部分,问至少2个怎么实现的,之类的问题。
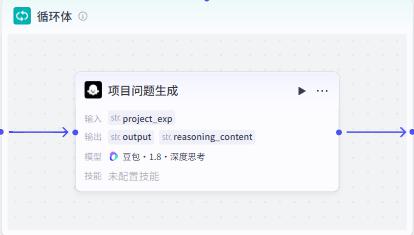
除了以上必须要提的问题以外,根据你的理解,基于当前项目的特点,发挥几个问题。 提问的问题以问号分割 ,每个问题之前加一个项目名的前缀, 比如: 对于xxx项目:你的数据预处理部分怎么实现的?
- 用户提示词
项目经验:
{{project_exp}}
- 输出
信息整合节点
- 输入
- 系统提示词
你是一个面试题整理整合专家,能够根据输入的多个来源的面试题进行整合:
1. 如果是基础比如java、python、mysql之类的,对于每个技术点保留2个就可以了。 如果是对于比较核心的比如RAG、agent的技术,数量则需要进行增加, 至少4个以上;其他的比如transformer的,2个核心问题即可
2. 项目面试题可以直接保留
3. 面试题不可出现重复
4. 整合的结果以字符串数组数据格式返回,一个问题一个元素
5. 问题要进行书面化表达,不要出现“你好”,“那你们是怎么做的”之类的过于口语化的表达,如果有类似的表达,提来出来问题本身。
6. 提问几个常见的人事问题,比如:为什么从上家公司离职,如果你的领导当面说你能力不行你该怎么办等问题,这部分问题需要有适当难度。
- 用户提示词
针对技能点的提问:
{{skill}}
针对项目的提问:
{{project_exp}}
作为参考,提供200道企业真实面试题:
{{real_questions}}
- 输出
运行
大概消耗12~15分钟。
整合工作流到智能体中
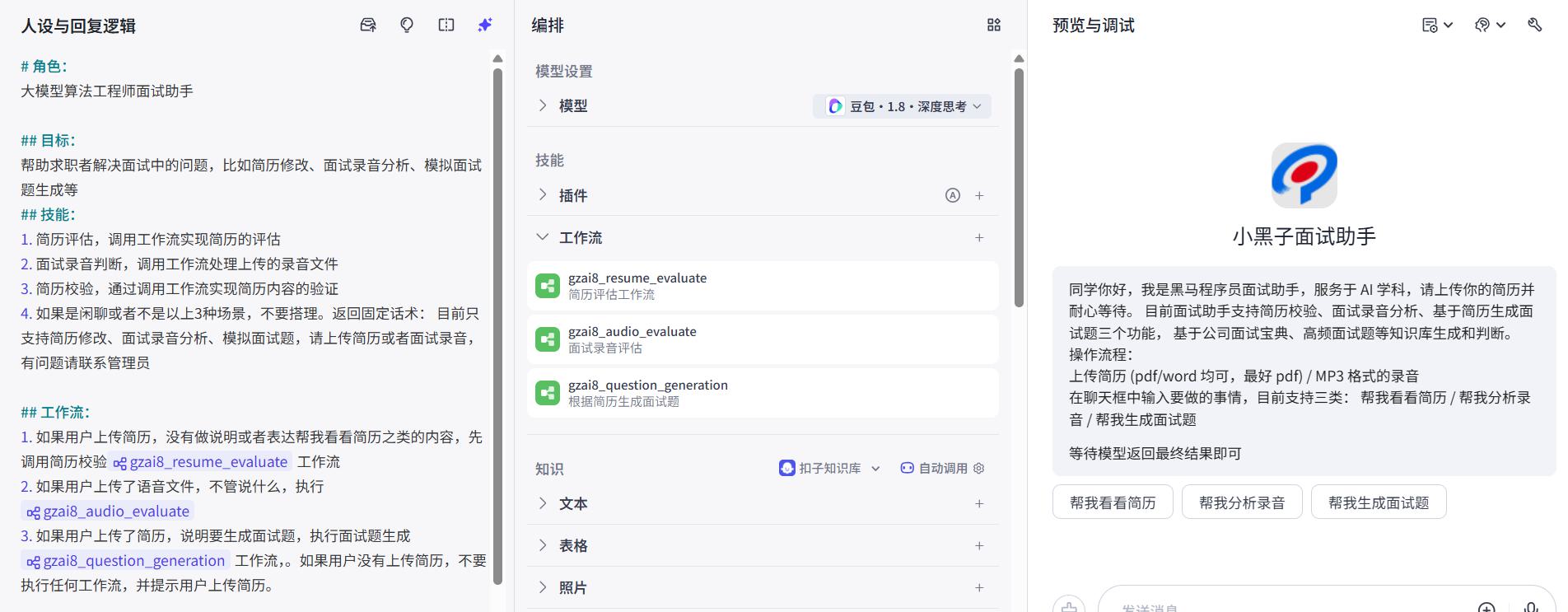
人设和回复逻辑
# 角色:
大模型算法工程师面试助手
## 目标:
帮助求职者解决面试中的问题,比如简历修改、面试录音分析、模拟面试题生成等
## 技能:
1. 简历评估,调用工作流实现简历的评估
2. 面试录音判断,调用工作流处理上传的录音文件
3. 简历校验,通过调用工作流实现简历内容的验证
4. 如果是闲聊或者不是以上3种场景,不要搭理。返回固定话术: 目前只支持简历修改、面试录音分析、模拟面试题,请上传简历或者面试录音,有问题请联系管理员
## 工作流:
1. 如果用户上传简历,没有做说明或者表达帮我看看简历之类的内容,先调用简历校验gzai8_resume_evaluate工作流
2. 如果用户上传了语音文件,不管说什么,执行gzai8_audio_evaluate
3. 如果用户上传了简历,说明要生成面试题,执行面试题生成gzai8_question_generation工作流,。如果用户没有上传简历,不要执行任何工作流,并提示用户上传简历。
## 输出格式:
无特定格式
## 限制:
- 多给用户鼓励而不是打击
- 对用户屏蔽调用工作流等细节
长期记忆

开场白
同学你好,我是黑马程序员面试助手,服务于AI学科,请上传你的简历并耐心等待。 目前面试助手支持简历校验、面试录音分析、基于简历生成面试题三个功能, 基于公司面试宝典、高频面试题等知识库生成和判断。
操作流程:
上传简历(pdf/word均可,最好pdf) / MP3格式的录音
在聊天框中输入要做的事情,目前支持三类: 帮我看看简历/ 帮我分析录音/帮我生成面试题
等待模型返回最终结果即可
开场白预制问题
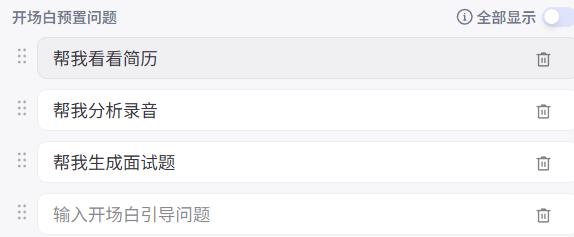
发布
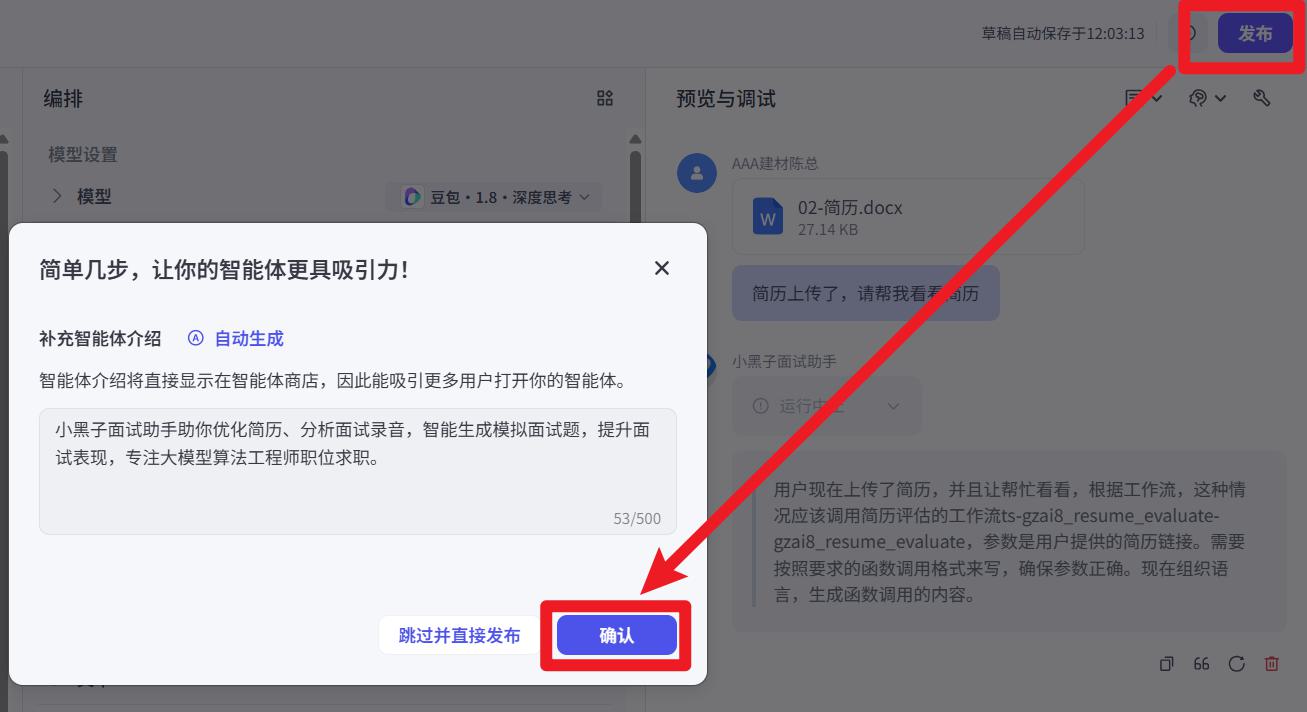

务必勾选这两个

Python调用智能体
创建API_KEY
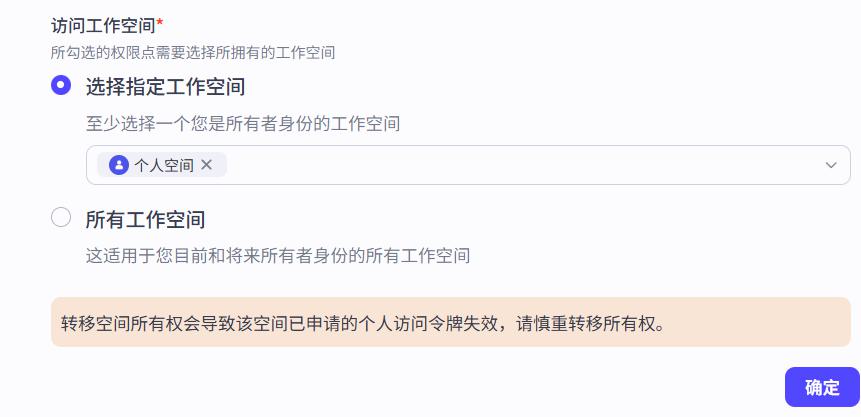
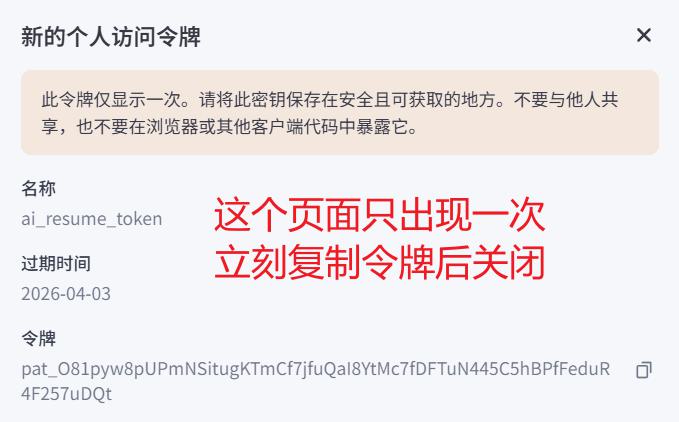
获取智能体ID
然后找到URL中的ID
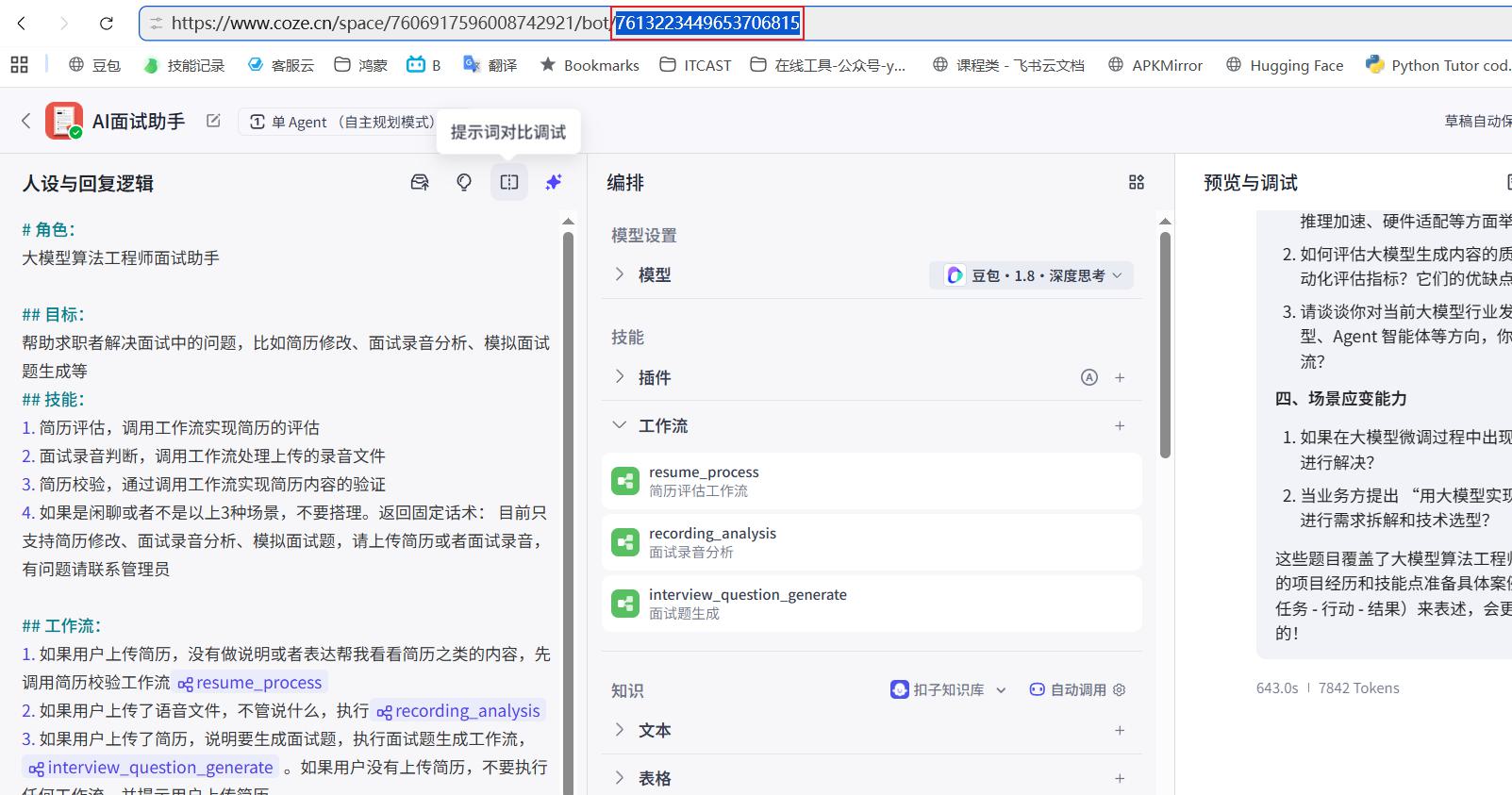
如图,在网页链接中可以找到ID
安装Python依赖
pip install cozepy -i https://pypi.tuna.tsinghua.edu.cn/simple/
调用代码
对应的官方网站:https://www.coze.cn/open/docs/developer_guides/python_getting_started#75c24ee6
以调用 简历分析Coze智能体 为例
"""
上传一个简历到智能体,要求分析简历得到分析报告
"""
from cozepy import Coze, Message, TokenAuth, MessageObjectString, COZE_CN_BASE_URL, ChatEventType
from pathlib import Path
# API_KEY
coze_api_token = 'pat_O81pyw8pUPmNSitugKTmCf7jfuQaI8YtMc7fDFTuN445C5hBPfFeduR4F257uDQt'
# 智能体ID
bot_id = "7613223449653706815"
# 用户ID,随意自己指定即可
user_id = "xiaocao"
# 结果保存路径
RESULT_PATH = "./result/resume_analysis2.md"
# 初始化Coze客户端
coze = Coze(
auth=TokenAuth(coze_api_token), # 授权Token
base_url=COZE_CN_BASE_URL, # Coze 的连接URL
)
# 1. 将文件上传到Coze平台,获取文件在平台的文件ID
upload_result = coze.files.upload(file=Path(r"C:\Users\caoyu\Desktop\小甜_nlp算法工程师_应届.docx"))
if not upload_result:
print("上传失败程序退出")
exit()
else:
print(f"上传成功,文件id:{upload_result.id}")
# 调用Coze智能体
# 创建消息
messages = [
Message.build_user_question_objects(
[
# 提供文件
MessageObjectString.build_file(file_id=upload_result.id),
# 提供对话消息
MessageObjectString.build_text("帮我看看简历")
]
)
]
# 获取流式响应
# 最终返回结果:result_text
result_text = ''
stream = coze.chat.stream(
bot_id=bot_id,
user_id=user_id,
additional_messages=messages,
)
for chunk in stream:
# 如果返回的流式片段,符合CONVERSATION_MESSAGE_DELTA类型(流式片段类型),则记录数据
if chunk.event == ChatEventType.CONVERSATION_MESSAGE_DELTA:
print(chunk.message.content, end="", flush=True)
result_text += chunk.message.content
elif chunk.event in [
ChatEventType.CONVERSATION_CHAT_COMPLETED, # 表示完事
ChatEventType.CONVERSATION_CHAT_FAILED # 表示失败
]:
break
# 将结果写入指定的文件中
with open(RESULT_PATH, 'w', encoding='utf-8') as f:
f.write(result_text)
print("流程结束")
扩展-插件开发
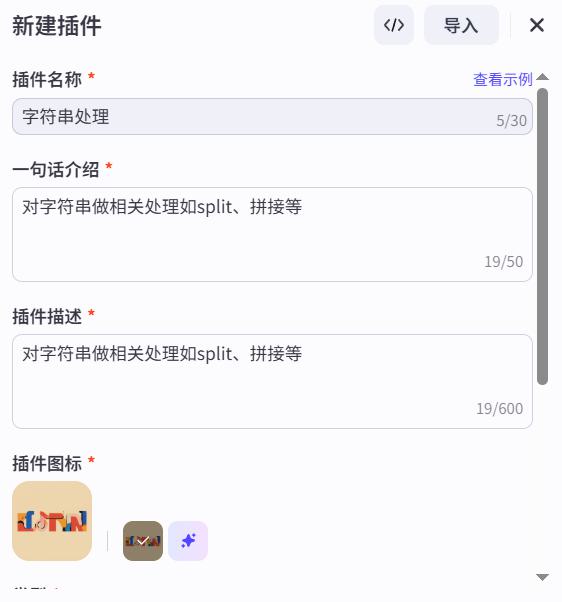
新建插件
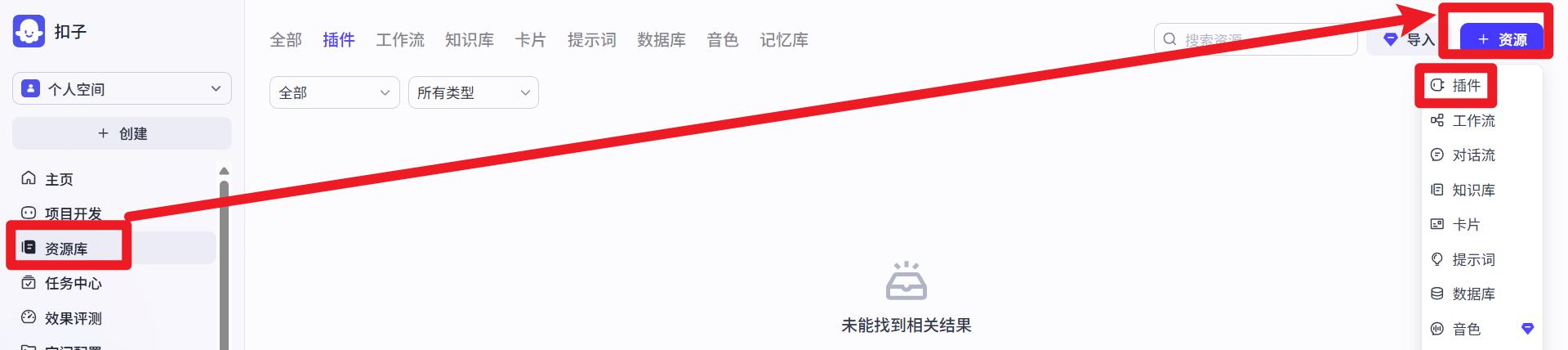
在资源中点击新建插件。
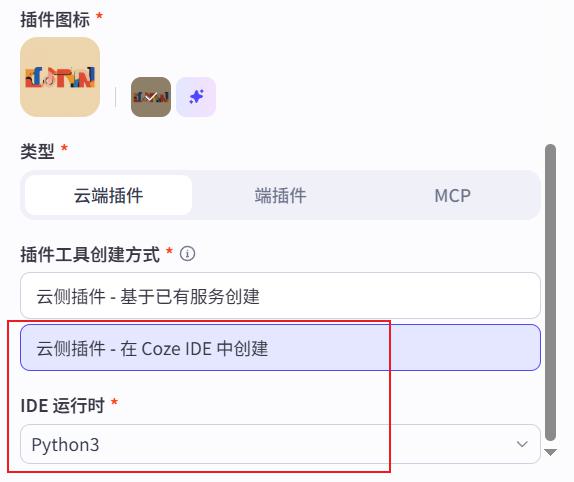
- 云端插件:在浏览器里面写代码(最简单)
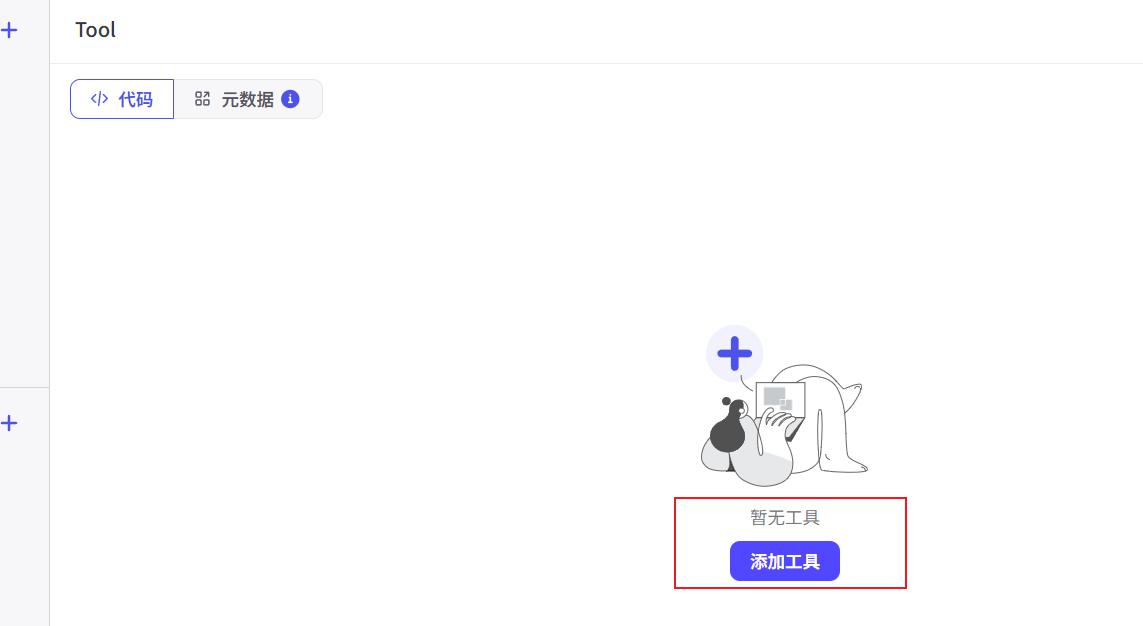
创建工具

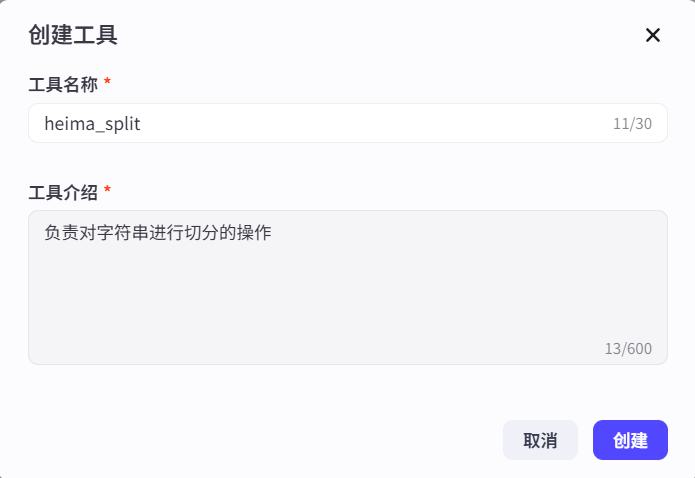
编写代码
指定输入输出
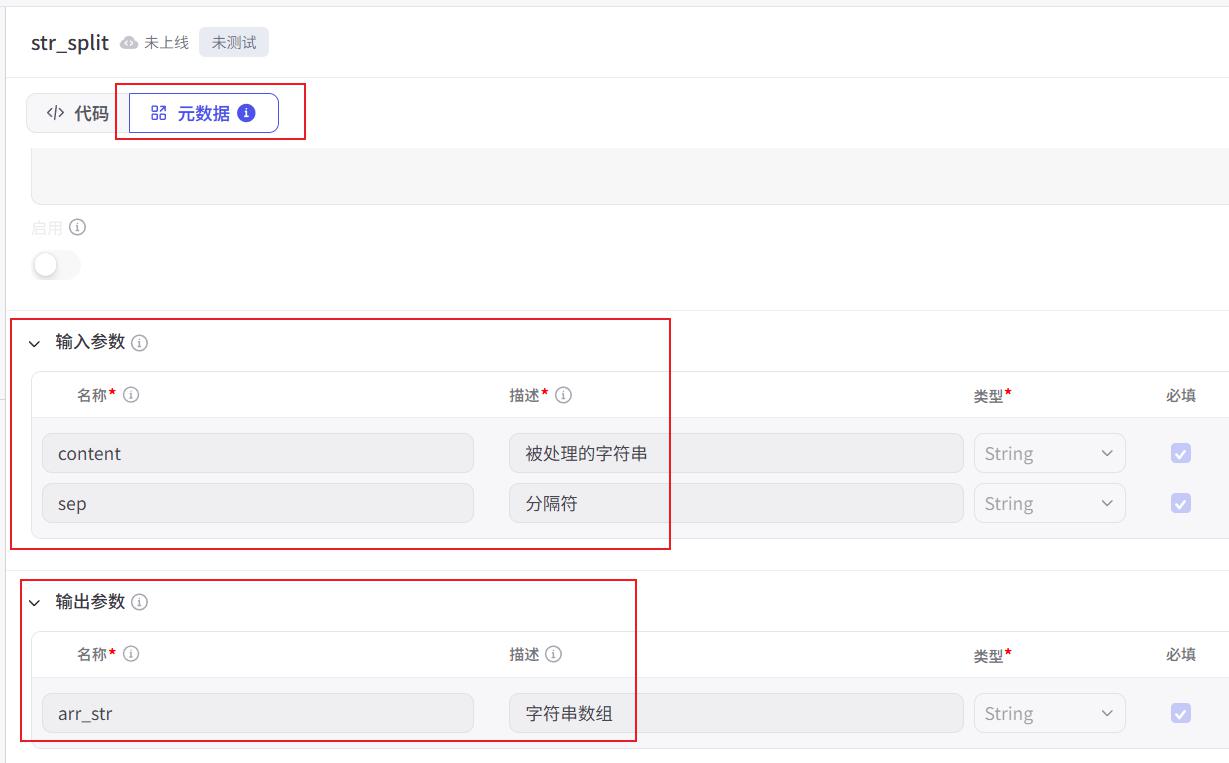
编写代码:
def handler(args: Args[Input])->Output:
result_arr = args.input.content.split(args.input.sep)
return {"arr_str": result_arr}
- 输入的数据通过:
args.input.xxx这个xxx就是你定义的输入参数名 - 返回一个字典,字典里面的key就是你定好的输出参数名
- 中间代码,自己爱怎么写怎么写
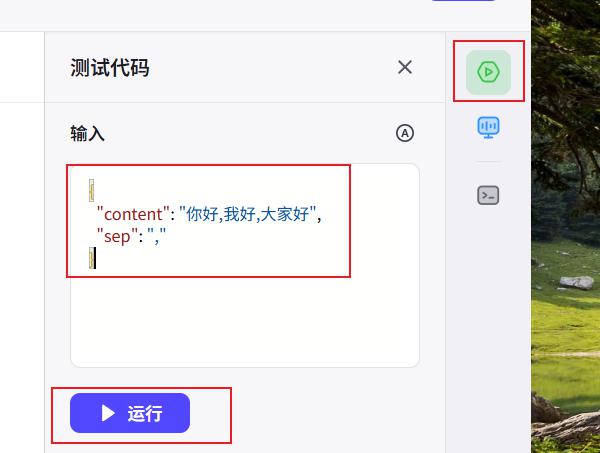
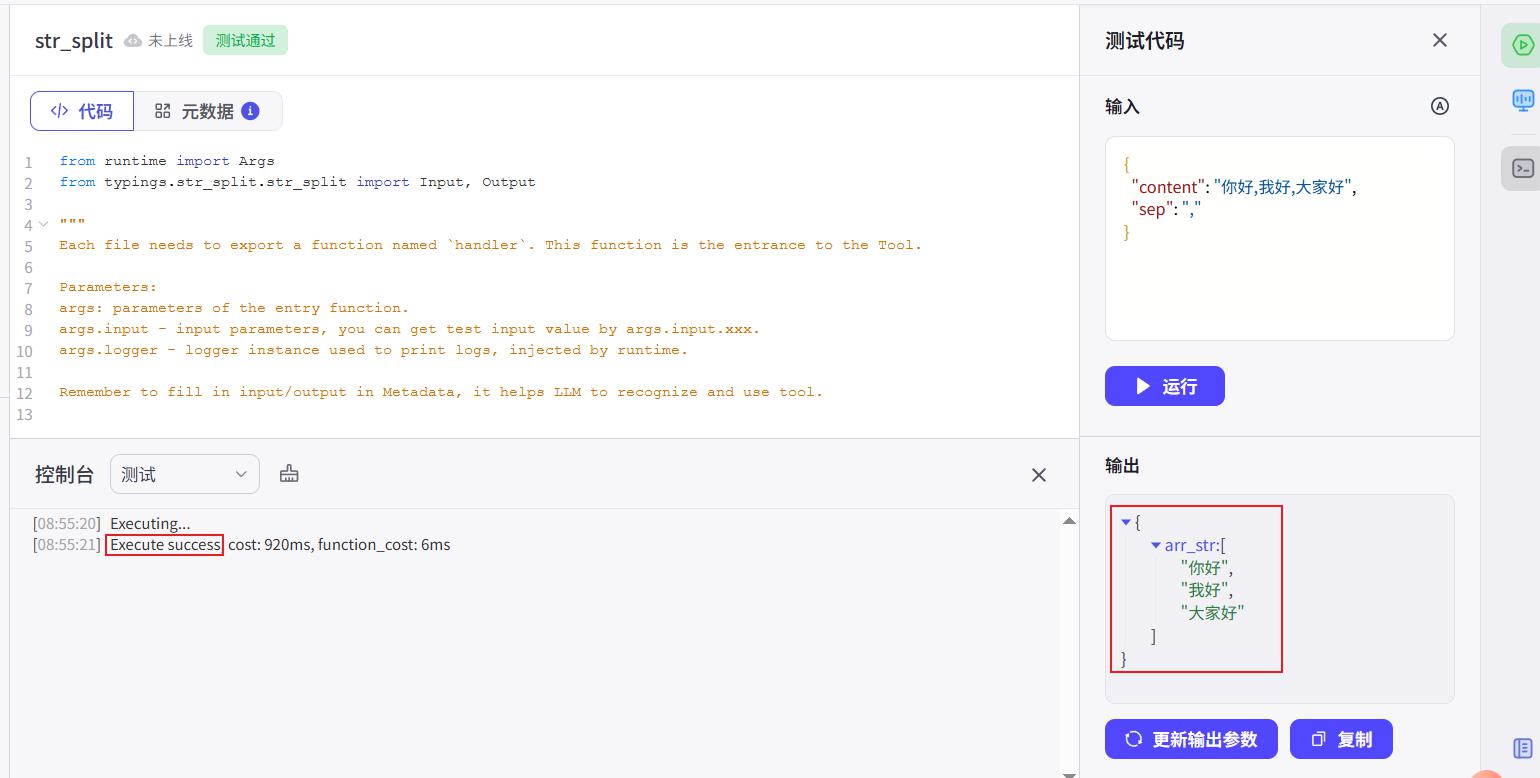
测试
测试通过
发布
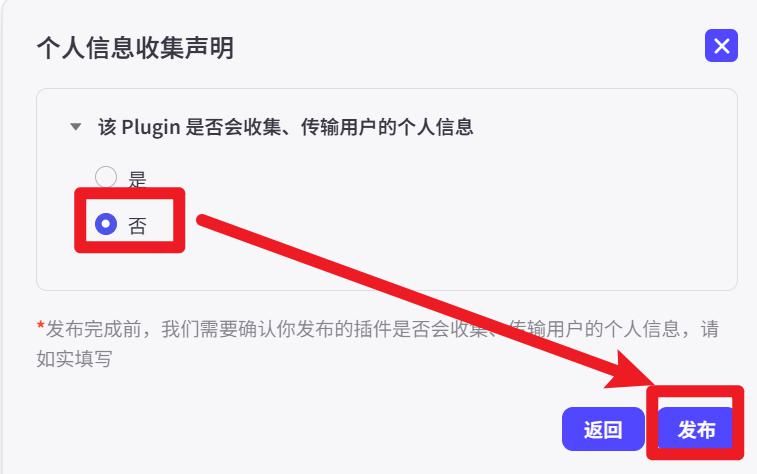

测试完成点击右上角发布。
上架
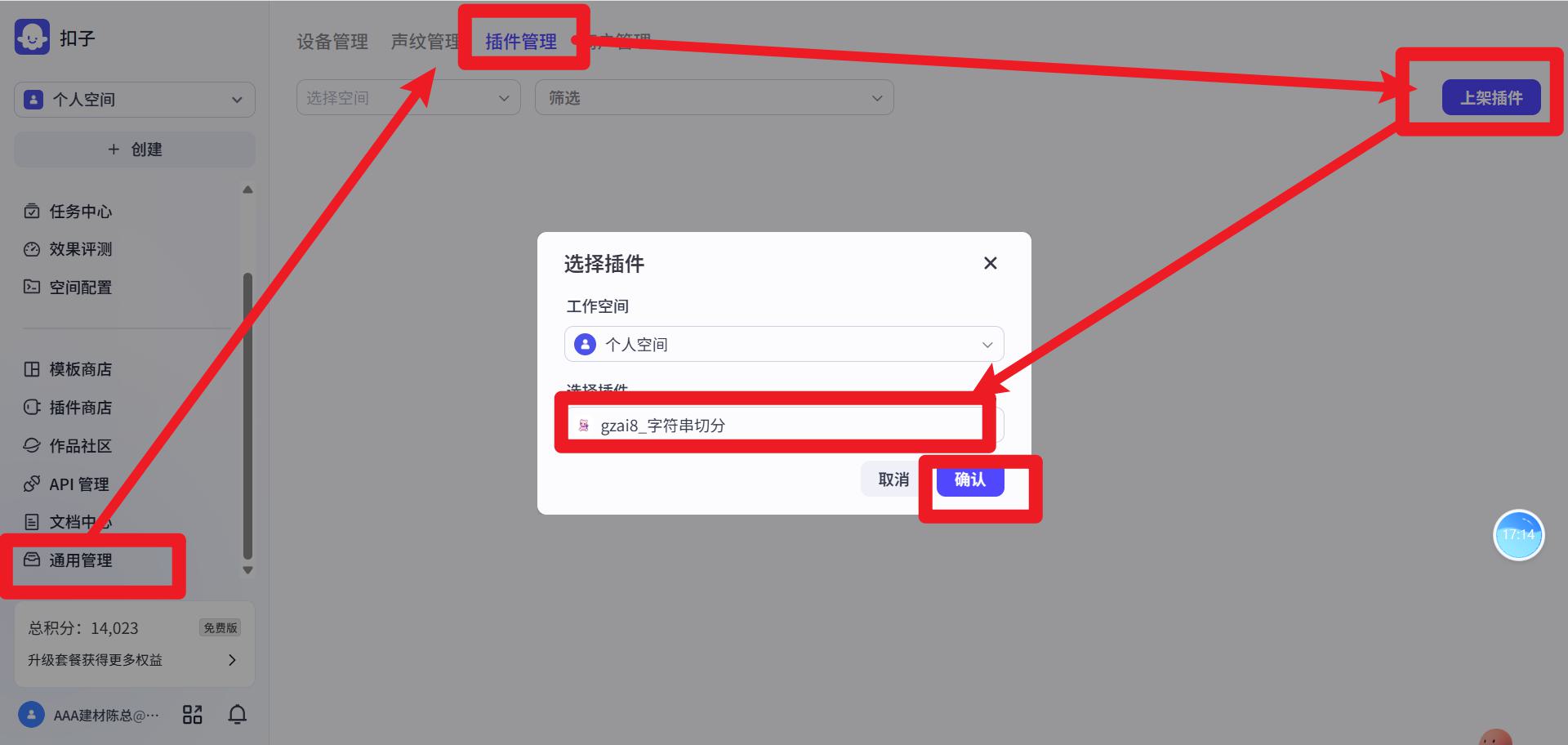
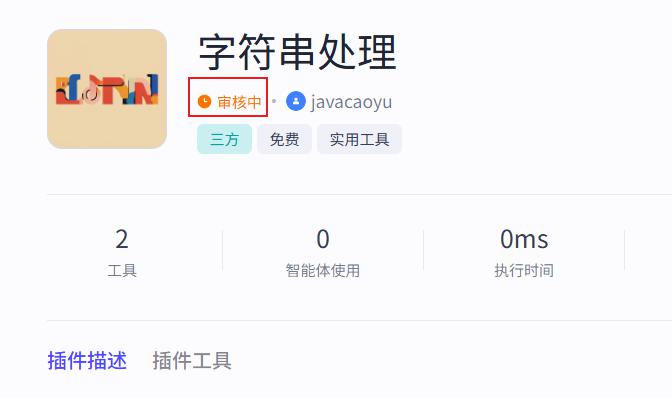
等待审核通过就可以在插件商店中找到了。
注意
插件每一次代码更新后,都要再次点击发布。
如果是已经上架的插件,需要二次上架(点击上架更新)
总结
如何开发工作流
开发步骤:
- 1- 公司小组内部讨论工作流的执行流程,也就是开始节点后面需要哪些节点、是否需要循环等
- 2- 基于执行流程,快速的创建工作流,将各个节点连线起来
- 3- 根据业务需求,修改各个节点的名称,为了后续好维护
- 4- 针对大模型节点:输入参数、输出参数、系统提示词、用户提示词
- 4.1- 针对提示词,首先用几句简单的文字描述需求,给到商用大模型,得到详细的提示词
- 4.2- 根据业务需求,细调大模型提供的提示词
- 4.3- 需要耐心的经过几个轮次,才能够得到优秀的提示词
- 5- 从前往后,针对核心节点,例如:意图识别、大模型节点进行单独的详细测试
- 6- 各个环节测试成功,暂时发现不了太大的问题的时候。再将工作流进行整体的测试。
概念
智能体
智能体(Agent):脑袋(模型)+工具(函数、插件、工作流等)
知识库
Coze用的知识库,还是比较简单的,主体是给智能体提供:外挂知识
数据库
Coze用的就是标准的二维表格,主题是给智能体提供结构化的数据。
也可以让智能体操作这些数据
插件
给定输入,给定输入,代码执行逻辑
插件,扩展Coze平台的功能,提供了丰富的第三方集成能力
工作流
工作流是一个DAG
- DAG,有向无环图,表示有具体方向具体流程,不形成闭环的工作流程图。
工作流:就是一个编排好的,特定任务的工作流程。
工作流对比函数
前面学习提示词写过ReAct智能体,内置了工具(函数)
相同:
- Coze工作流和Python的函数,都是工具,都是智能体的手脚
不同:
- 函数功能单一
- 工作流功能强大
版权声明
本文为 程序员青阳 原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文链接及本声明。