Python高级
面向对象
面向对象它是一种编程思维,讲究万事万物皆对象(一切皆对象)
面向过程: 核心是关注业务实现的过程和步骤
面向对象: 重点分析对象的属性和行为
三大特性
- 封装:把属性和方法封装到类中进行隐藏,对外提供访问接口
- 继承:子承父业 子类继承父类的属性和方法
- 多态:同一个事物,在不同场景下表现出来的不同形态.如:水: 固体,液体,气体
类和对象
类:对现实事物的抽象描述
对象:现实事物的具体体现
# 1.定义类:class 类名:
class Car:
# 1.1.定义方法:跑起来
def run(self):
print('能跑起来...')
# 2.创建对象:对象名 = 类名()
car = Car()
# 3.调用方法:对象.方法名()
car.run()
self关键字
self也是Python内置的关键字之一,其指向了对象实例本身【对象自己】。
谁调用类内部函数,self就是谁
# 1.定义类:class 类名:
class Car:
# 1.1.定义方法:跑起来
def run(self):
print(f'self的结果{self}')
print('能跑起来...')
# 2.创建对象:对象名 = 类名()
car = Car()
print(f'car对象结果{car}')
# 3.调用方法:对象.方法名()
car.run()
print('*' * 30)
# 3.创建对象:对象名 = 类名()
car2 = Car()
print(f'car2对象结果{car2}')
car2.run()
添加和获取属性
添加
# 1.在类外部
对象名.属性名 = 值
# 2.在类内部 __init__() 函数
self.属性 = 值
获取
在类的内部: self.属性
在类的外部: 对象.属性
魔法方法
魔法方法: 与普通方法区别
- 自动调用,特殊情况下
- 前后被双下滑线包围
初始化方法init
当一个实例被创建时调用的初始化方法。
# 1.定义类
class Car:
# 1.1 设置属性:__init__
def __init__(self, color, number):
self.color = color
self.number = number
# 1.2 获取属性: self.属性名
def show(self):
print(f'车身颜色:{self.color}')
print(f'车轮数:{self.number}')
# 2.创建对象:对象名 = 类名()
car = Car('black', 8)
# 2.1 获取属性
# 类内部
car.show()
# 类外部
# print(car.color)
# print(car.number)
字符方法str
当使用print输出对象时,默认打印对象的内存地址值【十六进制】。 若要让输出对象名时,不是内存地址值,应该要在类中定义str方法。如果类定义了__str__方法,那么就会打印从在这个方法中 return的数据。
# 1,定义类
class Car:
# 1.1 属性的设置
def __init__(self):
self.color = '红色'
self.number = 4
# 1.2 str:输出属性信息
def __str__(self):
return f'{self.color}的汽车有{self.number}个车轮'
# 2.创建对象
car = Car()
# 3.打印对象
print(car)
销毁方法del
当一个实例被销毁时调用的方法
# 1.定义类
class Car:
# 1.1 属性赋值
def __init__(self,color):
self.color = color
# 1.2 del魔法
def __del__(self):
print('自动调用了del魔法方法')
# 2.创建对象
car = Car('红色')
# 3.获取属性
# print(car.color)
del car
print(car.color)
案例
"""
需求:
定义一个 地瓜类, 属性为: 被烤的时间(cook_time), 地瓜的生熟状态(cook_state), 添加的调料(condiments).
行为有: cook() 表示烘烤, add_condiment() 表示 添加调料.
请用所学, 用面向对象的思维完成这个事情.
烘烤规则(时间及其对应的状态):
0 ~ 3分钟 生的
3 ~ 7分钟 半生不熟
7 ~ 12分钟 熟了
超过12分钟 已烤焦, 糊了
"""
class Potato:
def __init__(self):
self.cook_time = 0
self.cook_state = '生的'
self.condiments = []
def __str__(self):
return f'时间:{self.cook_time}分钟,状态:{self.cook_state},调料:{self.condiments}'
def cook(self, cook_time):
self.cook_time = cook_time
if 0 <= cook_time <= 3:
self.cook_state = '生的'
elif cook_time <= 7:
self.cook_state = '半生不熟'
elif cook_time <= 12:
self.cook_state = '熟了'
else:
self.cook_state = '已烤焦, 糊了'
def add_condiment(self, condiment):
self.condiments.append(condiment)
if __name__ == '__main__':
p = Potato()
p.add_condiment('辣椒')
p.add_condiment('五香粉')
p.add_condiment('孜然粉')
p.cook(8)
print(p)
继承
单继承
class Master:
def __init__(self):
self.konfu = '古法煎饼技术'
def make_cake(self):
print(f'师傅采用{self.konfu},制作煎饼')
class Prentice(Master): #继承Master
pass
if __name__ == '__main__':
p = Prentice()
print(p.konfu)
p.make_cake()
多继承
class Master:
def __init__(self):
self.konfu = '古法煎饼技术'
def make_cake(self):
print(f'师傅采用{self.konfu},制作煎饼')
class School:
def __init__(self):
self.konfu = '现代煎饼技术'
def make_cake(self):
print(f'黑马采用{self.konfu},制作煎饼')
class Prentice(School,Master): #继承School和Master
pass
if __name__ == '__main__':
p = Prentice()
print(p.konfu)
p.make_cake()
当一个类有多个父类时,默认使用第一个父类的同名属性和方法,可以使用类名**.mro**属性或类名.mro()方法查看调用的先后顺序。
注:MRO(Method Resolution Order):方法解析顺序

print(Tudi.__mro__)
print(Tudi.mro())
方法重写
当子类属性或方法与父类的属性或方法名字相同的时候,从父类继承下来的成员可以重新定义!
# 故事4: 很多顾客都希望吃到 徒弟自研的煎饼果子, 也有 黑马配方的煎饼果子味道. 请用所学, 模拟这个知识点.
# 1. 定义师傅类Master.
class Master(object):
# 1.1 属性, kongfu = '[古法摊煎饼果子技术]'
def __init__(self):
self.kongfu = '[古法摊煎饼果子技术]'
# 1.2 行为, make_cake(), 表示: 摊煎饼.
def make_cake(self):
print(f'采用 {self.kongfu} 制作煎饼果子!')
# 2. 定义黑马学校类School.
class School(object):
# 2.1 属性, kongfu = '[黑马AI摊煎饼果子技术]'
def __init__(self):
self.kongfu = '[黑马AI摊煎饼果子技术]'
# 2.2 行为, make_cake(), 表示: 摊煎饼.
def make_cake(self):
print(f'采用 {self.kongfu} 制作煎饼果子!')
# 3. 定义徒弟类Prentice, 继承自 师傅类.
class Prentice(School,Master): # 多继承, 同名属性和行为, 优先参考第1个父类, 即: 从左往右的顺序.
# 3.1 属性
def __init__(self):
self.kongfu = '[独创(自研) 摊煎饼果子技术]'
# 3.2 行为, make_cake(), 表示: 摊煎饼.
def make_cake(self):
print(f'采用 {self.kongfu} 制作煎饼果子!')
# 3.3 行为, make_master_cake(), 从老师傅继承过来的 煎饼果子配方.
def make_master_cake(self):
Master.__init__(self)
Master.make_cake(self)
# 3.4 行为, make_school_cake(), 从黑马学校继承过来的 煎饼果子配方.
def make_school_cake(self):
School.__init__(self) # 类名.父类方法名() 调用
School.make_cake(self) # 类名.父类方法名() 调用
# 3.5 行为, make_old_cake(), 从 父类(super)继承过来的 煎饼果子配方.
def make_old_cake(self):
super().__init__() # super().父类方法名() 调用 适合单继承
super().make_cake() # super().父类方法名() 调用 适合单继承
# 在main函数中测试.
if __name__ == '__main__':
# 4. 创建徒弟类对象.
p = Prentice()
# 自研的.
p.make_cake()
# 5. 打印 徒弟类对象 从 Master(老师父类)继承过来的 行为.
p.make_master_cake()
# 6. 打印 徒弟类对象 从 School(黑马学校类)继承过来的 行为.
p.make_school_cake()
# 7. 打印 徒弟类对象 从 父类继承过来的 行为. 即: 旧的煎饼果子配方.
p.make_old_cake()
封装
私有属性
在属性名前面加上两个下划线 __
- 只能在类内部访问
- 定义公有方法获取get_xxx或设置set_xxx私有属性值
私有方法
在方法名前面加上两个下划线 __
- 只能在类内部访问
- 定义公有方法调用私有方法
class Master:
def __init__(self):
self.__money = 200 #定义私有属性
def get_money(self):
return self.__money # 获取私有属性
def __make_cake(self): # 定义私有方法
print('制作煎饼技术。。。')
def make_cake2(self):
self.__make_cake() # 获取私有方法
class Prentice(Master):
pass
if __name__ == '__main__':
p = Prentice()
# print(p.money)
print(p.get_money())
p.make_cake2()
多态
同样一个函数在不同的场景下有不同的状态
多态的条件
1、有继承 (定义父类、定义子类,子类继承父类)
2、函数重写 (子类重写父类的函数)
3、父类引用指向子类对象 (子类对象传给父类对象调用者)
多态的好处
1、在不改变框架代码的情况下,通过多态语法轻松的实现模块和模块之间的解耦合;实现了软件系统的可拓展
2、对解耦合的大白话解释:搭建的平台函数def object_play(herofighter:HeroFighter, enemyfighter:EnemyFighter) 相当于任务的调用者;子类、孙子类重写父类的函数,相当于子任务;相当于任务的调用者和任务的编写者进行了解耦合
3、对可拓展的大白话解释: 搭建的平台函数def object_play(herofighter:HeroFighter, enemyfighter:EnemyFighter),在不做任何修改的情况下,可以调用后来人写的代码
4、对“继承和多态对照理解”大白话解释:
继承相当于:孩子可以复用老爹的东西。
多态相当于:老爹框架,不做任何修改的情况下,可以可拓展的使用后来人(孩子)写的东西。
案例:动物类案例
class Animal:
def speek(self):
print('动物在叫。。。')
class Cat(Animal):
def speek(self):
print('猫在叫。。。')
class Dog(Animal):
def speek(self):
print('狗在叫。。。')
# 4. 定义函数 make_noise(动物类对象), 接收动物对象, 实现: 传入什么动物, 就怎么叫.
# 函数: make_noise(an: Animal): # an:Animal 意思是: an "必须" 是Animal类的对象 或者 其子类对象.
def make_noise(an: Animal):
an.speek()
# 在main方法中测试.
if __name__ == '__main__':
# 5. 分别创建猫类, 狗类对象.
cat = Cat()
dog = Dog()
make_noise(cat)
make_noise(dog)
抽象类
概述:在Python中, 抽象类也叫接口, 指的是: 有抽象方法的类, 就叫抽象类.
抽象方法:没有方法体的方法, 即: 空实现的方法, 用pass修饰, 就叫: 抽象方法.
用法: 抽象类一般充当 父类, 即: 制定整个继承体系的 标准(规范)
具体的体现, 实现交由 子类来完成.
案例

类属性和对象属性
对象属性: 属于每个对象的属性, 即: A对象修改了他的属性值, 不会影响B对象的属性值.
类属性: 它是属于该类的所有对象 所共享的, 即: A对象修改了类属性, 则B对象用的是 修改后的属性值.
对象属性 相关格式:
定义格式:
类外: 对象名.属性名 = 属性值
类内: self.属性名 = 属性值
获取属性值的格式:
类外: 对象名.属性名
类内: self.属性名
类属性:
定义格式:
定义在类中, 函数外的 变量, 就叫: 类变量, 它能被该类下所有的对象所共享.
调用格式:
方式1: 类名.类属性名 # 推荐使用.
方式2: 对象名.类属性名 # 可以用, 但是不推荐.
细节: 什么时候定义类变量, 什么时候定义对象变量?
如果1个变量是被该类下所有的对象所共享的, 就考虑定义成: 类变量(类属性), 否则定义成: 对象变量(对象属性).
类方法和静态方法
类方法:
1. 第1个参数必须是 当前类的对象, 一般用 cls当做变量名(即: class)
2. 类方法必须通过 @classmethod 来修饰.
3. 类方法是属于 类的方法, 能被该类下所有的对象所共享.
4. 可以通过 类名. 或者 对象名. 的方式调用, 推荐: 前者.
静态方法:
1. 静态方法没有参数的硬性要求, 可以1个参数都不传.
2. 静态方法必须通过 @staticmethod 来修饰.
3. 类方法是属于 类的方法, 能被该类下所有的对象所共享.
4. 可以通过 类名. 或者 对象名. 的方式调用, 推荐: 前者.
区别:
类方法 和 静态方法的区别: 要不要传参, 即: 第一个参数是写 还是 不写, 再简单点说: 是否需要使用 该类的对象, 用就定义成 类方法, 不用就定义成 静态方法.
案例
class Student(object):
# 1.1 老师名字.
teacher_name = '王宝强'
# 1.2 name属性, 每个学生的名字都不一样, 所以定义成: 对象属性.
def __init__(self, name):
self.name = name
# 1.3 定义静态方法, 访问: teacher_name 这个类变量.
@staticmethod
def get_static_name():
print(f'teacher_name={Student.teacher_name}')
# 1.4 定义类方法, 访问: teacher_name 这个类变量.
@classmethod
def get_class_name(cls):
print(f'teacher_name={cls.teacher_name}')
if __name__ == '__main__':
# 2. 创建学生对象.
Student.get_class_name()
Student.get_static_name()
虚拟环境
创建和切换
conda create -n ollama_env python=3.10 -y # 创建名为ollama_env的虚拟环境
conda activate ollama_env # 切换到ollama_env环境
conda remove -n ollama_env --all #删除虚拟环境
conda env list # 查看当前已经创建的虚拟环境列表
批量安装依赖
requirements.txt
streamlit>=1.35.0
ollama>=0.2.1
安装
pip install -r D:\requirements.txt
PyCharm加载虚拟环境
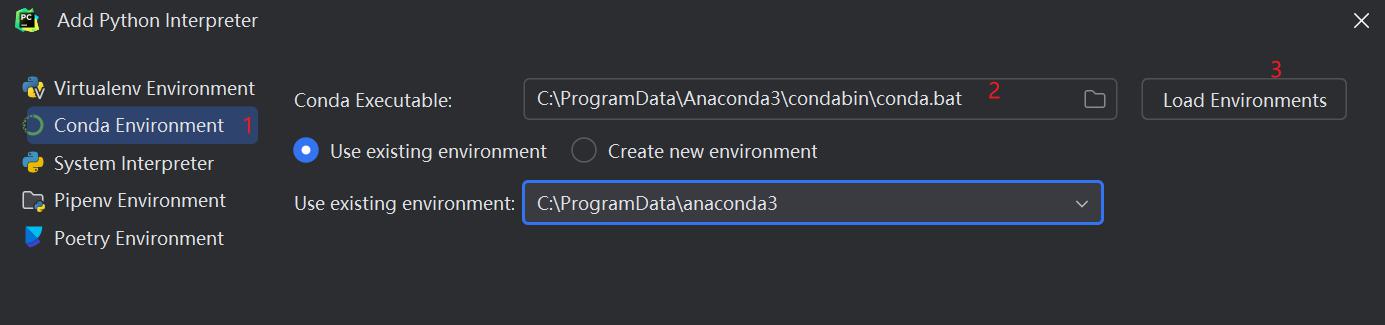
在pycharm右下角的虚拟环境名称中单击:Add New Interpreter - Add Local Interpreter
进入之后按下面三步加载
闭包
1- 函数定义【有嵌套】:外层函数的里面定义了另外一个函数
2- 外层函数【返回内层函数的名称】。注意:内层函数名称的后面不可以有小括号
3- [可选]内层函数可以使用外层函数的变量
案例
# 函数嵌套
def func_outer():
def func_inner():
print("内层函数被执行了")
return func_inner #返回内层函数的名称
def func_outer2(num1):
def func_inner2(num2):
return num1+num2 #内层函数可以使用外层函数的变
return func_inner2
if __name__ == '__main__':
my_fn = func_outer()
my_fn()
print("-"*30)
my_fn2 = func_outer2(10)
print(my_fn2(20))
装饰器
作用:在不改变现有函数源代码以及函数调用方式的前提下,实现对函数的增强。
装饰器的本质就是一个闭包函数(三步:① 有嵌套 ② 有引用 ③ 有返回)
有返回代表外部函数返回内部函数的内存地址(内部函数的名称),不带小括号
装饰器总结:
1- 作用:在不改变原有函数的定义、调用的代码情况下,增强函数的功能
2- 装饰器是一个特殊闭包
3- 装饰器的语法要求:
3.1- 有函数定义的嵌套
3.2- 外层函数返回内层函数的名称
3.3- 外层函数的形参有且只能有一个,用来接收被装饰/被增强的原始函数
案例
"""
需求:统计某个函数运行的耗时
"""
import time
# 定义装饰器
def outer_fn(old_fn):
def inner_fn():
# time.time()获取当前时间戳(从1970-01-01 00:00:00到目前过去的(毫)秒数)
start = time.time()
old_fn()
end = time.time()
print(f"函数运行耗时:{end - start}")
return inner_fn
#使用装饰器
@outer_fn
def my_sum():
total_result = 0
for i in range(1000000):
total_result += i
print(f"求和的结果:{total_result}")
if __name__ == '__main__':
my_sum()
带有参数或返回值的装饰器
import time
# 4- 原始函数有参数,有返回值
def outer_func_4(old_func):
def inner_func_4(start,end,step): #内层函数的形参接受原始函数返回值
start_time = time.time()
result = old_func(start,end,step)
use_time = time.time() - start_time
print(f"运行耗时:{round(use_time, 4)}")
return result #内层函数返回原始函数调用之后的返回值
return inner_func_4
@outer_func_4
def my_sum_4(start,end,step):
result = 0
for i in range(start,end,step):
result += i
return result
if __name__ == '__main__':
print(my_sum_4(0, 10000001, 2))
通用装饰器
import time
# 通用装饰器【掌握】
def outer(old_fn):
def inner(*args, **kwargs):
start = time.time()
"""
注意:传递给原始函数的参数,必须带上星号。
如果不带old_fn(args, kwargs),这样是两个参数,args是一个元组,kwargs是一个字典
带上星号,它会自动的进行拆包
"""
fn_result = old_fn(*args, **kwargs)
print("运行耗时:",time.time() - start)
return fn_result
return inner
# 有多个参数,有返回值
@outer
def my_sum_3(start,end):
total = 0
for i in range(start,end):
total += i
return total
if __name__ == '__main__':
result_3 = my_sum_3(0,1000000)
print("my_sum_3 累加结果是:", result_3)
【了解】多个装饰器修饰同一个函数
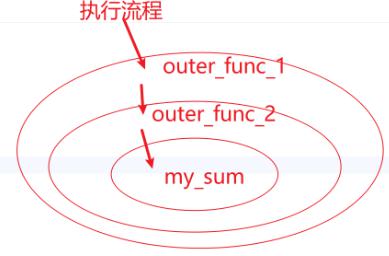
多个装饰器的装饰过程是: 离函数最近的装饰器先装饰,然后外面的装饰器再进行装饰,由内到外的装饰过程
案例
def outer_func_1(old_func):
def inner_func_1(*args,**kwargs):
print("a 第1个装饰器被调用了")
result = old_func(*args,**kwargs)
return result
return inner_func_1
def outer_func_2(old_func):
def inner_func_2(*args,**kwargs):
print("b 第2个装饰器被调用了")
result = old_func(*args,**kwargs)
return result
return inner_func_2
@outer_func_1
@outer_func_2
def my_sum():
result = 0
for i in range(10000001):
result += i
print(f"c 累计求和结果是:{result}")
if __name__ == '__main__':
my_sum()
【了解】装饰器传递参数
带有参数的装饰器语法总结:
1- 装饰器需要3层嵌套
2- 每层的作用如下:
2.1- 最外层:只负责接收装饰器自己需要的参数
2.2- 中间层:只负责接收被增强/被装饰的原始函数
2.3- 最里层:只负责接收被增强/被装饰的原始函数需要的参数
基本语法
def 装饰器(fn):
...
@装饰器('参数')
def 函数():
# 函数代码
案例
import time
def wrapper(num_cnt):
def outer_func(old_func):
def inner_func(*args, **kwargs):
start_time = time.time()
result = old_func(*args, **kwargs)
use_time = time.time() - start_time
print(f"运行耗时:{round(use_time, num_cnt)}")
return result
return inner_func
return outer_func
@wrapper(num_cnt=4)
def my_sum(start, end, step):
result = 0
for i in range(start,end,step):
result += i
return result
@wrapper(num_cnt=10)
def my_func():
result = 0
for i in range(100000):
result += i
return result
if __name__ == '__main__':
final_result = my_sum(1,10000001,3)
print(final_result)
print("-"*30)
final_result2 = my_func()
print(final_result2)
装饰器修饰类中的方法
装饰器既能够在面向过程中去装饰函数,也能够在面向对象中装饰方法
import time
class Funcs:
@staticmethod
def wrapper(num_cnt):
def outer_func(old_func):
def inner_func(*args, **kwargs):
start_time = time.time()
result = old_func(*args, **kwargs)
use_time = time.time() - start_time
print(f"运行耗时:{round(use_time, num_cnt)}")
return result
return inner_func
return outer_func
@wrapper(num_cnt=4)
def my_sum(self, start, end, step):
result = 0
for i in range(start, end, step):
result += i
return result
@wrapper(num_cnt=10)
def my_func(self):
result = 0
for i in range(100000):
result += i
return result
if __name__ == '__main__':
# 创建类的实例对象
obj = Funcs()
# 调用实例方法
final_result = obj.my_sum(1, 10000001, 3)
print(final_result)
print("-" * 30)
final_result2 = obj.my_func()
print(final_result2)
【理解】深浅拷贝
浅拷贝
浅拷贝: 创建新对象,其内容是原对象的引用。
浅拷贝之所以称为浅拷贝,是它仅仅只拷贝了一层,拷贝了最外围的对象本身,内部的元素都只是拷贝了一个引用而已。
案例1:赋值

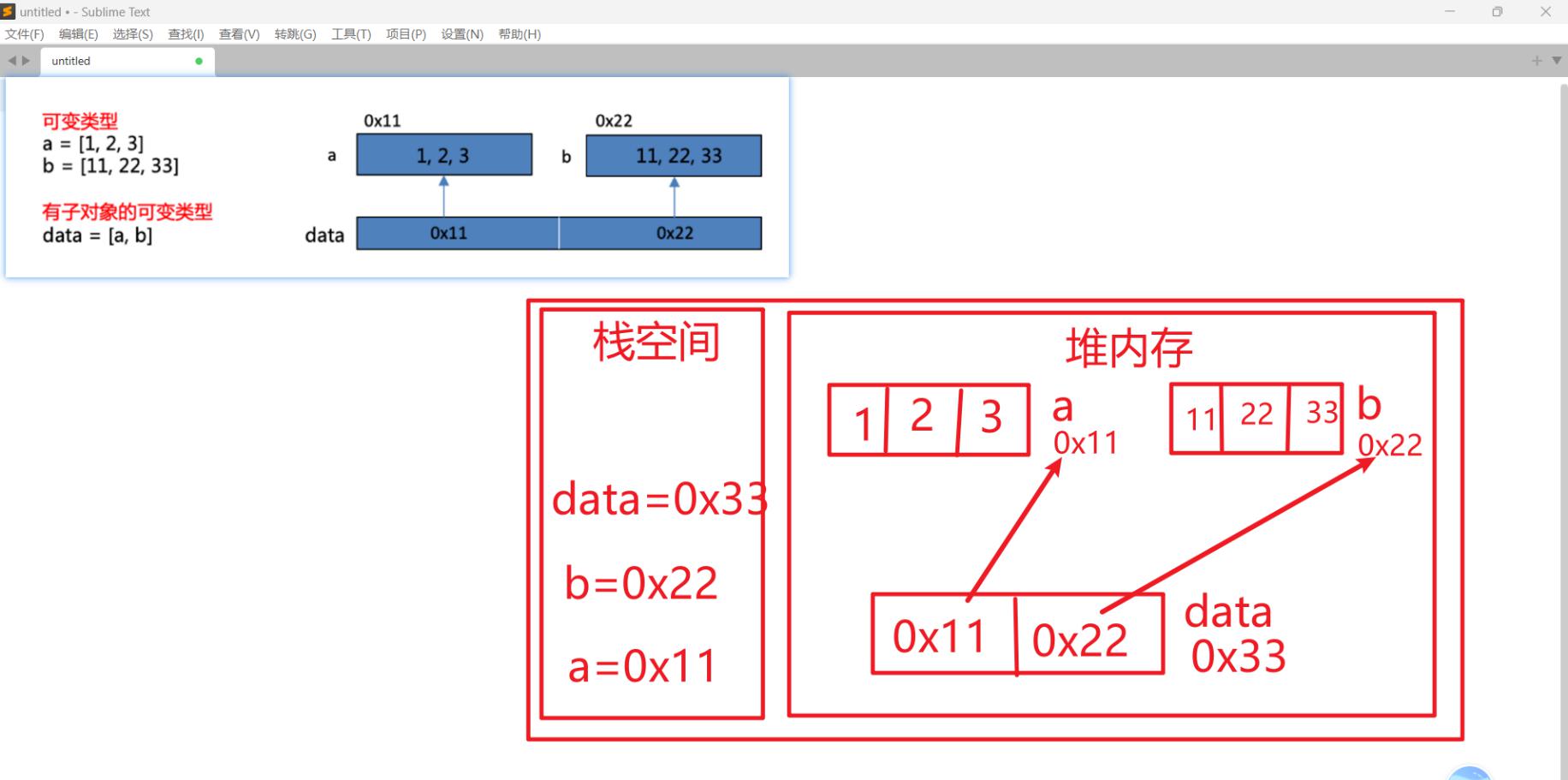
案例2:可变类型浅拷贝
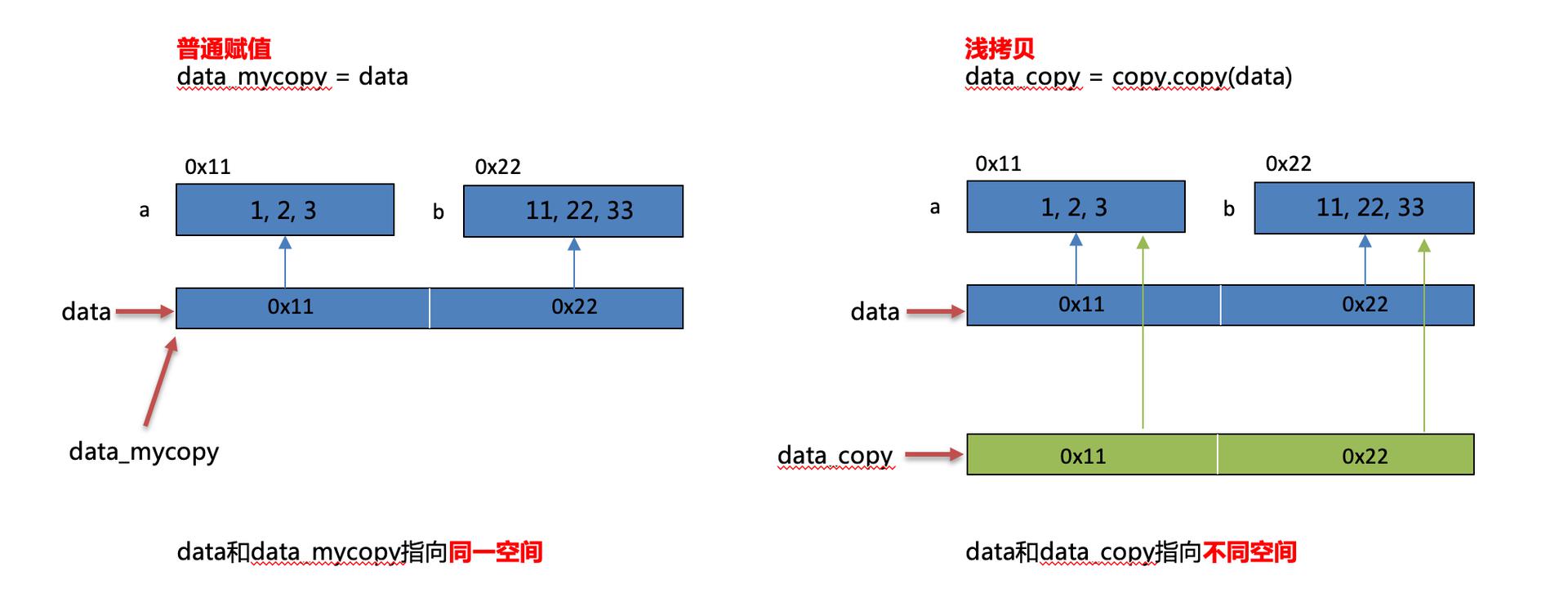
案例3:不可变类型浅拷贝
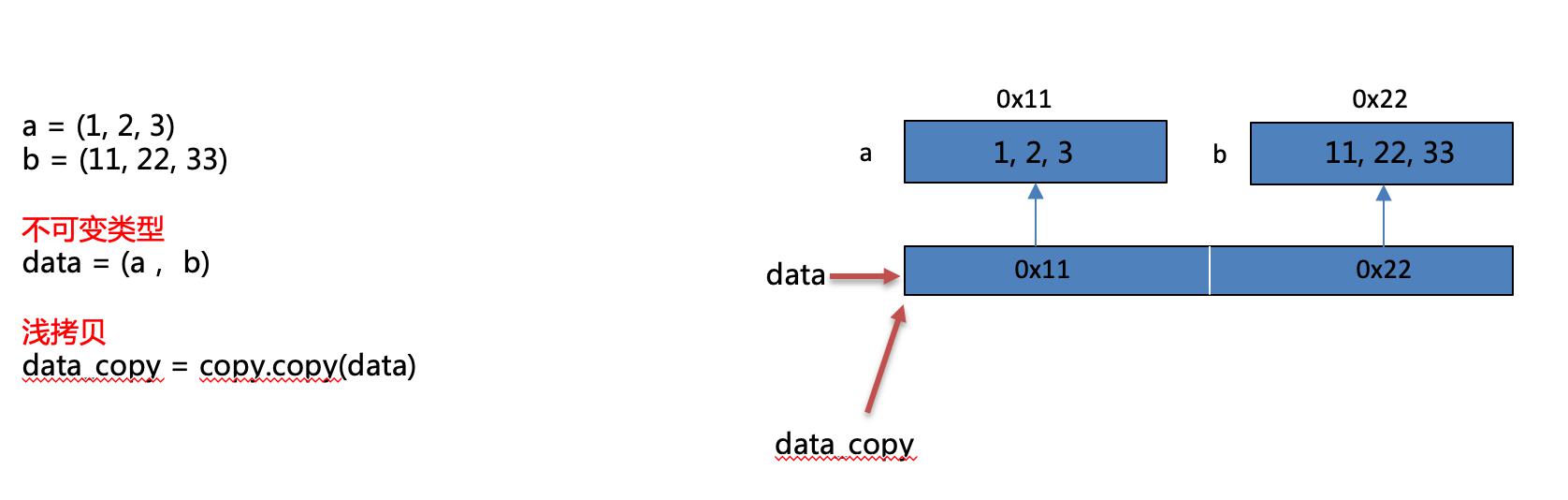
注:不可变类型进行浅拷贝不会给拷贝的对象开辟新的内存空间,而只是拷贝了这个对象的引用
深拷贝
深拷贝:和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。深拷贝出来的对象是一个全新的对象,不再与原来的对象有任何关联。
所以改变原有被复制对象不会对已经复制出来的新对象产生影响。只有一种形式,copy模块中的deepcopy函数。
可变类型深拷贝:
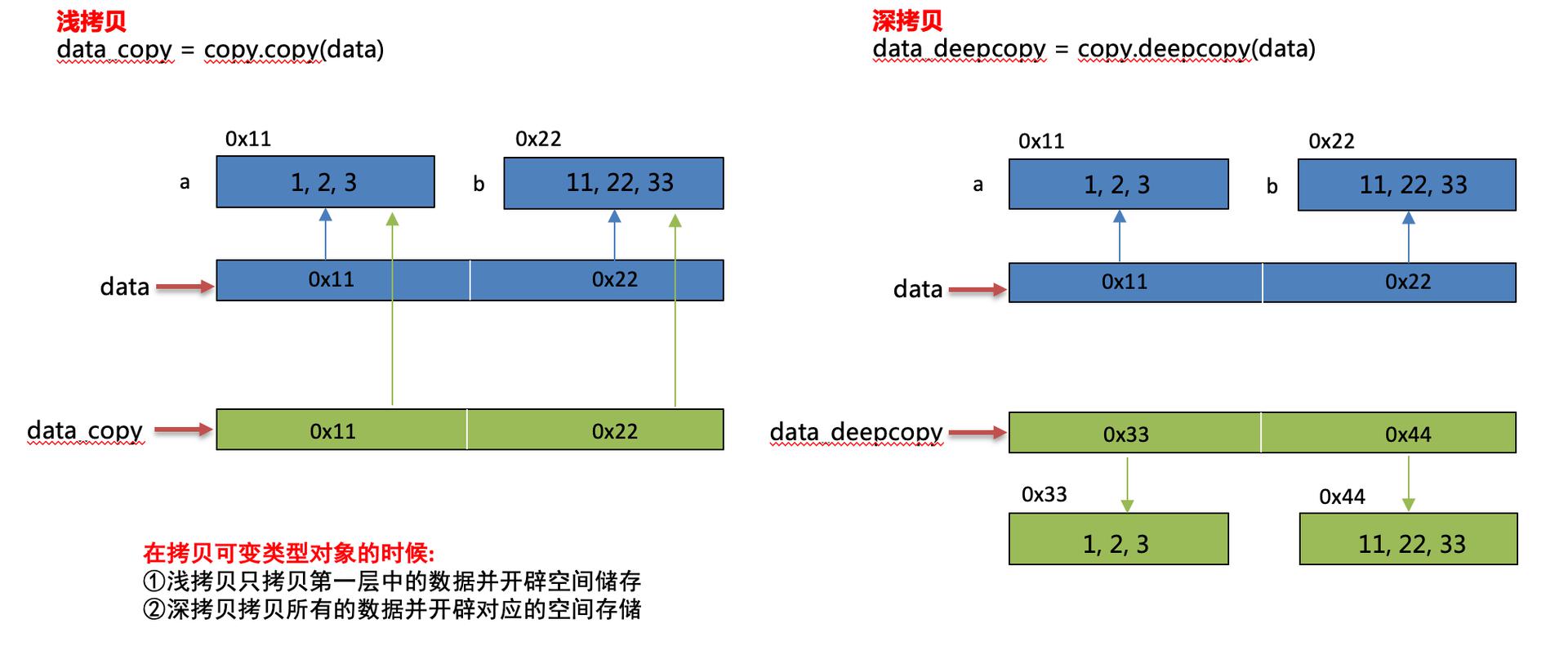
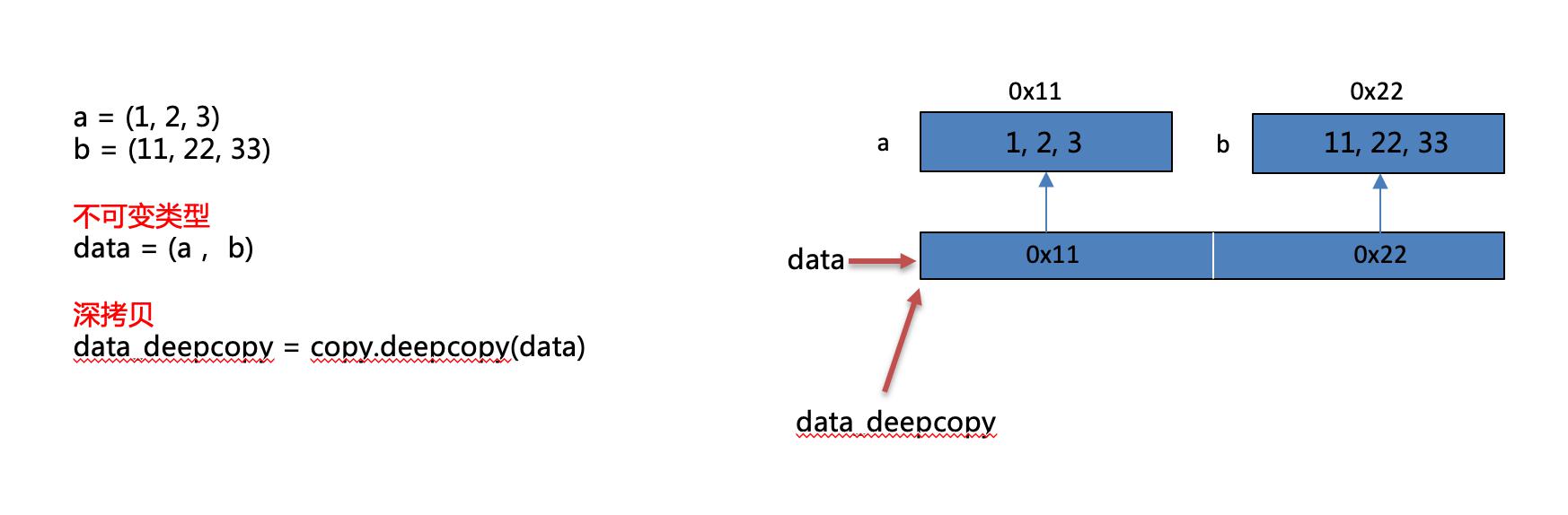
不可变类型深拷贝:不可变类型进行深拷贝不会给拷贝的对象开辟新的内存空间,而只是拷贝了这个对象的引用
总结
深浅拷贝
1- 浅拷贝
可变类型:只会拷贝第一层内容的内存地址,更深层次不受到影响
不可变类型:浅拷贝没有任何变化,没有使用价值
2- 深拷贝
可变类型:不管嵌套多少层,重新开辟新的空间,拷贝前后之间没有任何关系,彻底独立
不可变类型:深拷贝没有任何变化,没有使用价值
总结:可变类型的浅拷贝只拷贝第一层的内存地址,深拷贝无论多少层都会重新开辟空间。不可变类型的深浅拷贝没有任何变化。
案例演示
课堂代码:
import copy
# 1- 可变、不可变类型的浅拷贝
def demo01():
# 可变类型 的 浅拷贝
a = [1, 2, 3]
b = [11, 22, 33]
data = [a, b]
print(f"data的内容:{data}")
print(f"data的内存地址:{id(data)}")
# 执行浅拷贝
data_copy = copy.copy(data)
print(f"data_copy的内容:{data_copy}")
print(f"data_copy的内存地址:{id(data_copy)}")
print("-"*30)
# 修改内容
data[0][1] = 99
print(f"data的内容:{data}")
print(f"data_copy的内容:{data_copy}")
print("="*50)
# 不可变类型 的 浅拷贝
a = (1, 2, 3)
b = (11, 22, 33)
data = (a, b)
print(f"data的内容:{data}")
print(f"data的内存地址:{id(data)}")
# 执行浅拷贝
data_copy = copy.copy(data)
print(f"data_copy的内容:{data_copy}")
print(f"data_copy的内存地址:{id(data_copy)}")
# 2- 可变、不可变类型的深拷贝
def demo02():
# 可变类型 的深拷贝
a = [1, 2, 3]
b = [11, 22, 33]
data = [a,b]
print(f"data的内容:{data}")
print(f"data的内存地址:{id(data)}")
# 执行深拷贝
data_copy = copy.deepcopy(data)
print(f"data_copy的内容:{data_copy}")
print(f"data_copy的内存地址:{id(data_copy)}")
print("-"*30)
# 修改
data[0][1] = 99
data_copy[1][1] = 666
print(f"data的内容:{data}")
print(f"data的内存地址:{id(data)}")
print(f"data_copy的内容:{data_copy}")
print(f"data_copy的内存地址:{id(data_copy)}")
print("="*50)
# 不可变类型 的深拷贝
a = (1, 2, 3)
b = (11, 22, 33)
data = (a, b)
print(f"data的内容:{data}")
print(f"data的内存地址:{id(data)}")
# 执行深拷贝
data_copy = copy.deepcopy(data)
print(f"data_copy的内容:{data_copy}")
print(f"data_copy的内存地址:{id(data_copy)}")
# 3- 可变 嵌套 不可变类型的深拷贝
def demo03():
a = 1 # 不可变类型
print(id(a))
a = 99
print(id(a))
b = 2 # 不可变类型
data = [a, b] # 可变类型
# 浅拷贝
# data_copy = copy.copy(data)
# 深拷贝
data_copy = copy.deepcopy(data)
print(data, id(data))
print(data_copy, id(data_copy))
print("-" * 30)
data[0] = 99
print(data, id(data))
print(data_copy, id(data_copy))
if __name__ == '__main__':
# 1- 可变、不可变类型的浅拷贝
# demo01()
# 2- 可变、不可变类型的深拷贝
# demo02()
# 3- 可变 嵌套 不可变类型的深拷贝
demo03()
demo03的原理图:
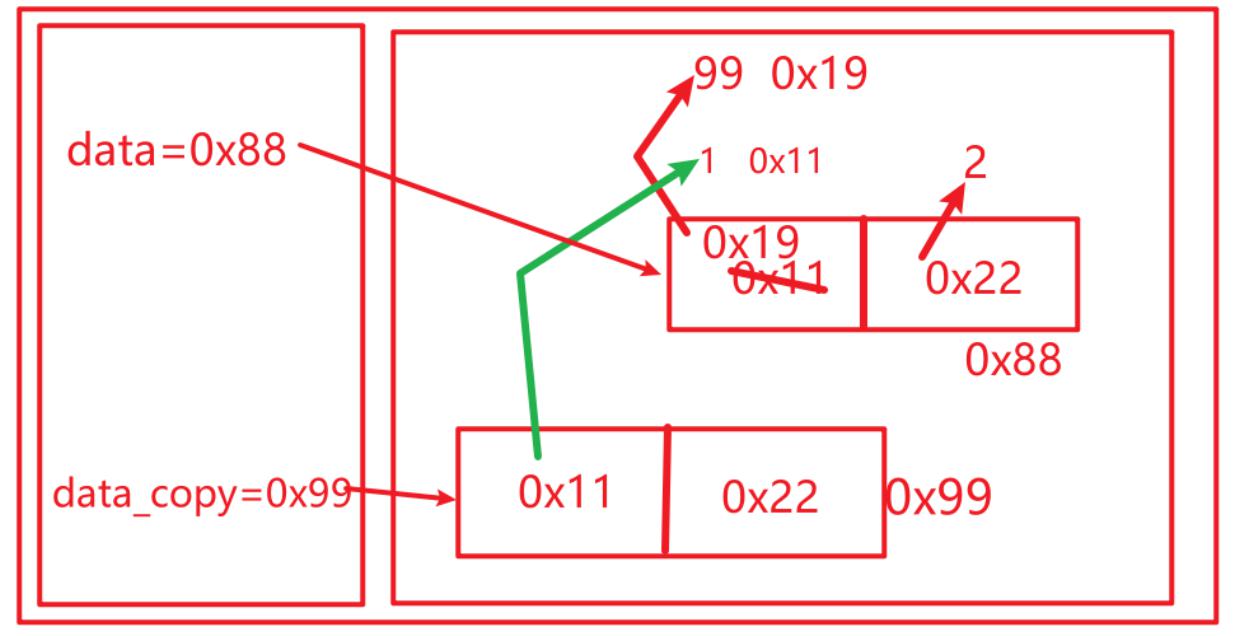
python的编码转换
数据转换方法说明:
| 函数名 | 说明 |
|---|---|
| encode | 编码 将字符串转化为字节码 |
| decode | 解码 将字节码转化为字符串 |
提示:encoed()和decode()函数可以接受参数,encoding是指在编解码过程中使用的编码方案。
字符串编码:
str.encode(encoding=”utf-8”)
二进制解码:
bytes.decode(encoding=“utf-8”)
代码示例:
if __name__ == '__main__':
# 注意:编码、解码需要使用相同的编码集
# 编码:将字符串 转成 二进制
content = "大模型工程师的工资有多少"
bytes_result = content.encode(encoding="UTF-8")
print(bytes_result)
# 解码:将二进制 转成 字符串
decode_result = bytes_result.decode(encoding="UTF-8")
print(decode_result)
tcp客户端和服务器端开发
tcp客户端
import socket
# 查看源代码的快捷键: ctrl+左键 ctrl+q
if __name__ == '__main__':
# 1- 创建Socket工具
"""
参数解释:
family=socket.AF_INET:使用IPv4
type=socket.SOCK_STREAM:数据以二进制流的形式传递
"""
socket_obj = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
# 2- 建立与服务器的连接
# windows中查看端口的占用情况:netstat -ano | findstr "8888"
socket_obj.connect(("127.0.0.1",8888))
# 3- 发送消息给到服务器
msg = "土豆土豆,我是恁爹"
socket_obj.send(msg.encode(encoding="UTF-8"))
# 4- 接收响应结果
# 1024:表示每次最多接收1024字节大小的内容
bytes_result = socket_obj.recv(1024)
str_result = bytes_result.decode(encoding="UTF-8")
print(f"客户端接收到的响应内容:{str_result}")
# 5- 关闭连接
socket_obj.close()
tcp服务器端
import socket
if __name__ == '__main__':
# 1- 创建Socket工具
socket_obj = socket.socket(family=socket.AF_INET, type=socket.SOCK_STREAM)
# 2- 将服务绑定到指定IP和端口
socket_obj.bind(("127.0.0.1",8888))
# 3- 监听客户端
# 10表示服务端同一时刻最多能够为10个客户端服务
socket_obj.listen(10)
# 4- 接收客户端的请求
"""
返回值解释:
client_socket_obj:每来一个新的客户端连接,那么服务端就会新创建一个连接对象,专门为该客户端服务
client_addr_info:连接过来的客户端信息
"""
client_socket_obj, client_addr_info = socket_obj.accept()
# 5- 接收客户端发送过来的数据
recv_msg_bytes = client_socket_obj.recv(1024)
recv_msg_str = recv_msg_bytes.decode(encoding="UTF-8")
print(f"服务端接收到的消息内容:{recv_msg_str}")
# 6- 将响应结果返回给到客户端
client_socket_obj.send("好的,你是我儿".encode(encoding="UTF-8"))
# 7- 关闭连接
client_socket_obj.close()
socket_obj.close()
多任务
多任务是指在同一时间内执行多个任务。
例如: 现在电脑安装的操作系统都是多任务操作系统,可以同时运行着多个软件。
并发
在一段时间内【交替】去执行多个任务。ps:联想发胶,并发是交替执行
并行
在一段时间内【同时】一起执行多个任务
多进程
进程(Process)是CPU资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位,通俗理解:一个正在运行的程序就是一个进程。
例如:正在运行的qq , 微信等 他们都是一个进程。
注: 一个程序运行后至少有一个进程
多进程完成多任务
① 导入进程包
import multiprocessing
② 通过进程类创建进程对象
进程对象 = multiprocessing.Process([group [, target=任务名 [, name]]])
③ 启动进程执行任务
进程对象.start()
Process的参数说明:
| 参数名 | 说明 |
|---|---|
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 进程名,一般不用设置 |
| group | 进程组,目前只能使用None |
进程创建与启动的代码
import time
import multiprocessing
def sing():
for i in range(100):
print(f"唱歌_{i}")
# 休息0.1秒钟
time.sleep(0.1)
def dance():
for i in range(100):
print(f"跳舞_{i}")
time.sleep(0.1)
if __name__ == '__main__':
# 创建子进程
"""
参数解释:
target:子进程需要负责的工作内容。传递的是函数名称,注意不能加小括号
"""
process_1 = multiprocessing.Process(target=sing)
process_2 = multiprocessing.Process(target=dance)
# 启动子进程
process_1.start()
process_2.start()
# 主进程的代码
print("这是主进程的代码")
进程执行带有参数的任务
Process([group [, target [, name [, args [, kwargs]]]]])
参数说明:
| 参数名 | 说明 |
|---|---|
| args | 以元组的方式给执行任务传参,args表示调用对象的位置参数元组,args=(1,2,’anne’,) |
| kwargs | 以字典方式给执行任务传参,kwargs表示调用对象的字典,kwargs={‘name’:’anne’,’age’:18} |
案例:args参数和kwargs参数的使用
参数传递总结。给进程中的函数传递参数,有如下两种写法:
1- 第一种:通过args传递元组,参数值的顺序需要与参数顺序保持一致
2- 第二种:通过kwargs传递字典,字典中key的名称需要与参数名称保持一致
使用推荐:如果参数比较多,推荐使用kwargs的形式;否则推荐用元组。
import time
import multiprocessing
def sing():
for i in range(10):
print(f"唱歌_{i}")
# 休息0.1秒钟
time.sleep(0.1)
def dance():
for i in range(10):
print(f"跳舞_{i}")
time.sleep(0.1)
if __name__ == '__main__':
# 创建子进程
"""
参数解释:
target:子进程需要负责的工作内容。传递的是函数名称,注意不能加小括号
"""
process_1 = multiprocessing.Process(target=sing)
process_2 = multiprocessing.Process(target=dance)
# 启动子进程
process_1.start()
process_2.start()
# 主进程的代码
print("这是主进程的代码")
【熟悉】获取进程编号
进程编号的作用
当程序中进程的数量越来越多时 , 如果没有办法区分主进程和子进程还有不同的子进程 , 那么就无法进行有效的进程管理 , 为了方便管理实际上每个进程都是有自己编号的。
两种进程编号
① 获取当前进程编号
getpid()
② 获取当前进程的父进程ppid = parent pid
getppid()
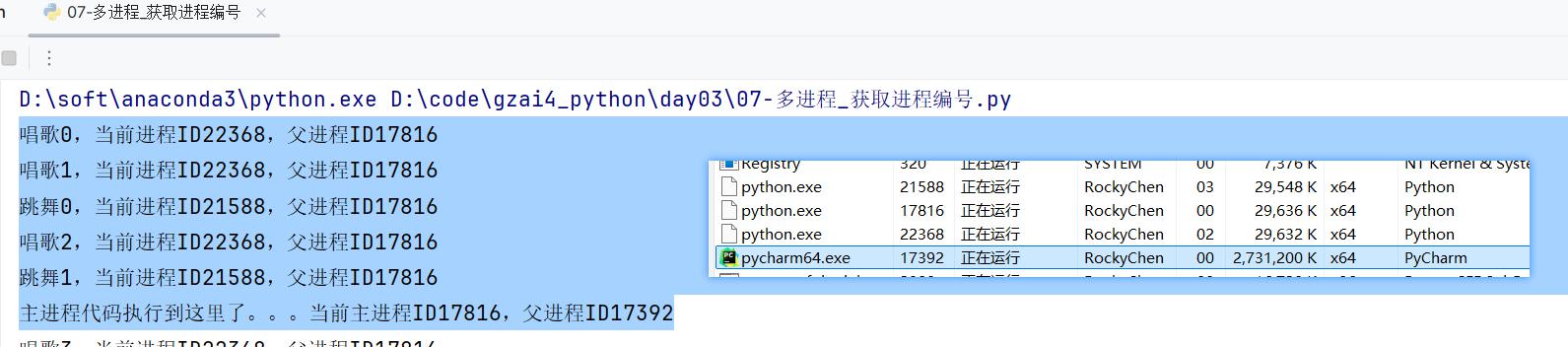
③ 案例:获取父进程与子进程编号
import os
import multiprocessing
import time
def sing():
for i in range(10):
print(f"唱歌_{i},进程编号是{os.getpid()},父进程编号是{os.getppid()}")
time.sleep(1)
def dance():
for i in range(10):
print(f"跳舞_{i},进程编号是{os.getpid()},父进程编号是{os.getppid()}")
time.sleep(1)
if __name__ == '__main__':
# 创建子进程
process_1 = multiprocessing.Process(target=sing)
process_2 = multiprocessing.Process(target=dance)
# 启动子进程
process_1.start()
process_2.start()
print(f"主进程的代码,进程编号是{os.getpid()},父进程编号是{os.getppid()}")
运行效果截图:
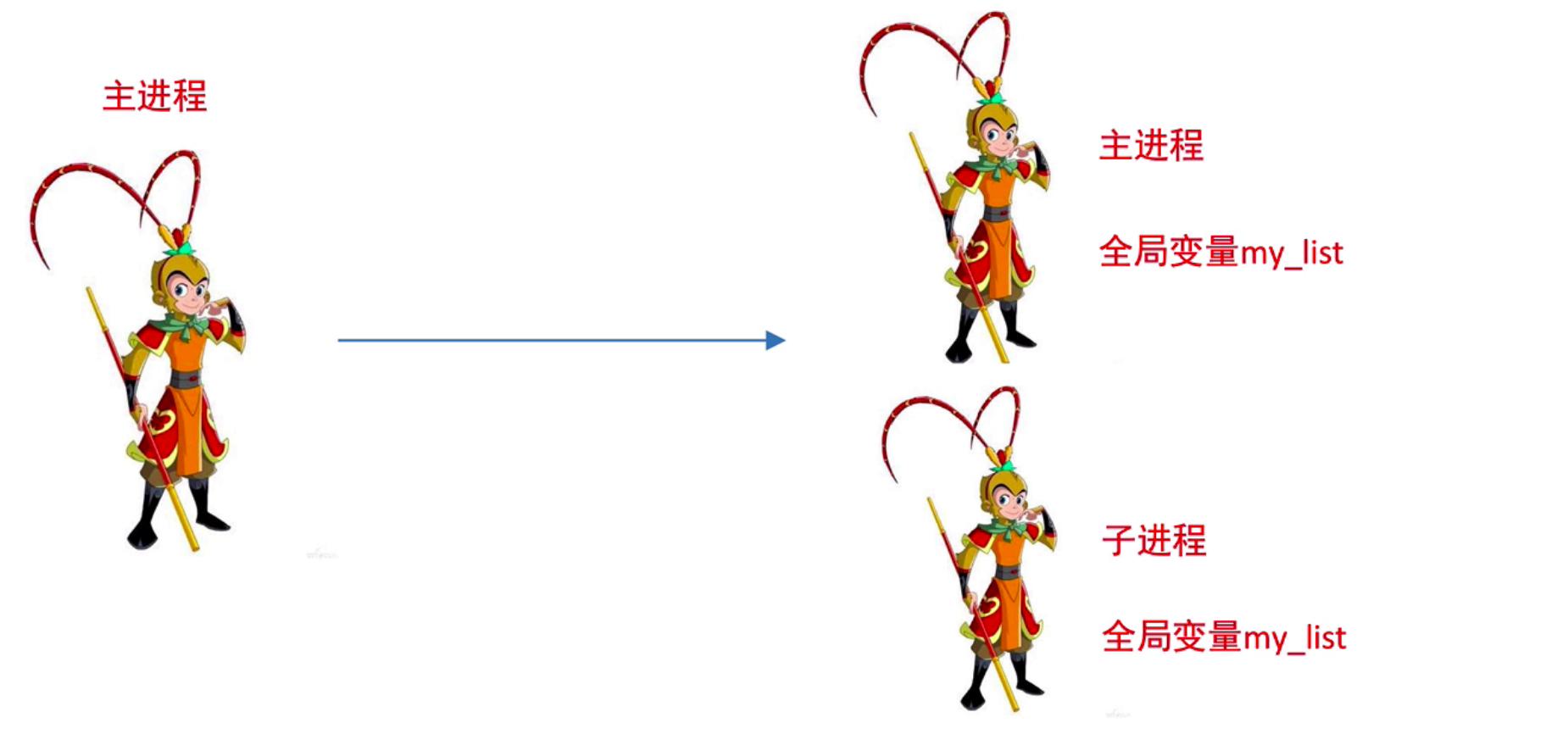
进程间不共享全局变量
实际上创建一个子进程就是把主进程的资源进行拷贝产生了一个新的进程,这里的主进程和子进程是互相独立的。
进程中的全局变量总结:
1- 主进程、各个子进程之间不共享全局变量
2- 如何实现不共享全局变量:各个进程将全局变量全部都深拷贝一份,各自用各自的
案例:
import multiprocessing
import time
"""
进程中的全局变量总结:
1- 主进程、各个子进程之间不共享全局变量
2- 如何实现不共享全局变量:各个进程将全局变量全部都深拷贝一份,各自用各自的
"""
# 定义全局变量
my_list = []
print(f"全局变量:{id(my_list)}")
def sing():
for i in range(10):
if i%2!=0:
# 存放奇数
my_list.append(i)
print(f"奇数:{my_list},变量:{id(my_list)}")
time.sleep(0.1)
def dance():
for i in range(10):
if i%2==0:
# 存放偶数
my_list.append(i)
print(f"偶数:{my_list},变量:{id(my_list)}")
time.sleep(0.1)
if __name__ == '__main__':
# 创建子进程
process_1 = multiprocessing.Process(target=sing)
process_2 = multiprocessing.Process(target=dance)
# 启动子进程
process_1.start()
process_2.start()
# 主进程代码
time.sleep(5)
print(f"主进程执行到这里了,{my_list},变量:{id(my_list)}")
运行结果截图:

知识点小结:
创建子进程会对主进程资源进行拷贝,也就是说子进程是主进程的一个副本,好比是一对双胞胎,之所以进程之间不共享全局变量,是因为操作的不是同一个进程里面的全局变量,只不过不同进程里面的全局变量名字相同而已。
主进程与子进程的结束顺序
代码演示:
进程间的结束顺序:
1- 默认 主进程会等待所有的子进程运行结束以后才会结束
2- 可以通过如下的两种方式调整结束顺序。也就是当主进程运行结束以后,子进程不管有没有运行完成都会被动结束
2.1- 推荐使用。子进程实例对象.daemon = True。注意:需要在启动子进程之前设置好
2.2- 子进程实例对象.terminate() 。注意:需要在启动子进程之后再调用
import multiprocessing
import time
import os
"""
进程间的结束顺序:
1- 默认 主进程会等待所有的子进程运行结束以后才会结束
2- 可以通过如下的两种方式调整结束顺序。也就是当主进程运行结束以后,子进程不管有没有运行完成都会被动结束
2.1- 推荐使用。子进程实例对象.daemon = True。注意:需要在启动子进程之前设置好
2.2- 子进程实例对象.terminate() 。注意:需要在启动子进程之后再调用
"""
def sing():
for i in range(10):
print(f"唱歌_{i},当前进程ID:{os.getpid()},父进程ID:{os.getppid()}")
time.sleep(0.5)
if __name__ == '__main__':
print(f"主进程执行到这里了,当前进程ID:{os.getpid()},父进程ID:{os.getppid()}")
time.sleep(3)
# 创建子进程
process_1 = multiprocessing.Process(target=sing)
# 方式一:设置进程为守护进程。推荐使用该方式,是温柔杀死,会进行资源回收
# 注意:需要在start之前设置好
# process_1.daemon = True
# 启动子进程
process_1.start()
time.sleep(1)
# 方式二:子进程主动的杀死自己。暴力杀死,不会进行资源回收
# 注意:需要在start之后再调用
process_1.terminate()
给进程传递类中的方法
把函数和方法当成同一个东西对待即可
import multiprocessing
import time
class IKun:
# 实例方法
def sing(self):
for i in range(10):
print(f"唱歌_{i}")
time.sleep(1)
# 类方法
@classmethod
def dance(cls,end):
for i in range(end):
print(f"跳舞_{i}")
time.sleep(1)
# 静态方法
@staticmethod
def rap(start,end,step):
for i in range(start,end,step):
print(f"RAP_{i}")
time.sleep(1)
if __name__ == '__main__':
# 创建类的实例对象
ikun_obj = IKun()
# 创建子进程
process_1 = multiprocessing.Process(target=ikun_obj.sing)
process_2 = multiprocessing.Process(target=IKun.dance, args=(10,))
process_3 = multiprocessing.Process(target=IKun.rap, kwargs={"start":1,"end":10,"step":2})
# 启动子进程
process_1.start()
process_2.start()
process_3.start()
多线程
在Python中,想要实现多任务还可以使用多线程来完成。
进程是分配资源的最小单位 , 一旦创建一个进程就会分配一定的资源 , 就像跟两个人聊QQ就需要打开两个QQ软件一样是比较浪费资源的 .
线程是程序执行调度的最小单位 , 实际上进程只负责分配资源 , 而利用这些资源执行程序的是线程 , 也就说进程是线程的容器 , 一个进程中最少有一个线程来负责执行程序 。同时线程自己不拥有系统资源,只需要一点儿在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源 。这就像通过一个QQ软件(一个进程)打开两个窗口(两个线程)跟两个人聊天一样 , 实现多任务的同时也节省了资源。
多线程完成多任务
① 导入线程模块
import threading
② 通过线程类创建线程对象
线程对象 = threading.Thread(target=任务名)
② 启动线程执行任务
线程对象.start()
Thread参数说明:
| 参数名 | 说明 |
|---|---|
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 线程名,一般不用设置 |
| group | 线程组,目前只能使用None |
线程创建与启动代码
单线程案例:
import time
def music():
for i in range(3):
print('听音乐...')
time.sleep(0.2)
def coding():
for i in range(3):
print('敲代码...')
time.sleep(0.2)
if __name__ == '__main__':
music()
coding()
多线程案例:
import threading
import time
def sing():
for i in range(10):
print(f"唱歌_{i}")
time.sleep(0.1)
def dance():
for i in range(10):
print(f"跳舞_{i}")
time.sleep(0.1)
if __name__ == '__main__':
# 创建子线程
thread_1 = threading.Thread(target=sing)
thread_2 = threading.Thread(target=dance)
# 启动子线程
thread_1.start()
thread_2.start()
print("主线程的代码")
线程执行带有参数的任务
多线程传递参数与多进程的使用完全一样
| 参数名 | 说明 |
|---|---|
| args | 以元组的方式给执行任务传参 |
| kwargs | 以字典方式给执行任务传参 |
import threading
import time
def code():
for i in range(10):
print(f"写代码_{i}")
time.sleep(0.1)
def music(end):
for i in range(end):
print(f"听音乐_{i}")
time.sleep(0.1)
def eat(start,end,step):
for i in range(start,end,step):
print(f"吃辣条_{i}")
time.sleep(0.1)
if __name__ == '__main__':
# 创建子线程
thread_1 = threading.Thread(target=code)
# 线程的参数传递方式、注意事项,与多进程中完全一样
thread_2 = threading.Thread(target=music, args=(10,))
thread_3 = threading.Thread(target=eat, kwargs={"start":1,"end":10,"step":3})
# 启动子线程
thread_1.start()
thread_2.start()
thread_3.start()
# 主线程代码
print("主线程代码执行到这里了")
主线程和子线程的结束顺序
设置守护线程
主线程和子线程的结束顺序:
1- 默认:主线程会等待所有的子线程执行完以后才会结束
2- 可以通过如下的两种方式改变结束顺序,也就是主线程运行结束以后,子线程不管有没有运行完成都得结束
2.1- 方式一:threading.Thread(target, daemon=True),将参数daemon设置为True
2.2- 方式二:将属性值daemon设置为True。注意:需要在start线程前设置好
注意:没有 子线程对象.terminate()的方法
import threading
import time
"""
主线程和子线程的结束顺序:
1- 默认:主线程会等待所有的子线程执行完以后才会结束
2- 可以通过如下的两种方式改变结束顺序,也就是主线程运行结束以后,子线程不管有没有运行完成都得结束
2.1- 方式一:threading.Thread(target, daemon=True),将参数daemon设置为True
2.2- 方式二:将属性值daemon设置为True。注意:需要在start线程前设置好
"""
def code():
for i in range(10):
print(f"子线程_写代码_{i}")
time.sleep(1)
if __name__ == '__main__':
# 创建子线程
thread_1 = threading.Thread(target=code)
# 设置守护线程的方式一:将参数daemon设置为True
# thread_1 = threading.Thread(target=code, daemon=True)
# 设置守护线程的方式二:将属性值daemon设置为True
# 注意:需要在start线程前设置好
thread_1.daemon = True
# 启动子线程
thread_1.start()
print("主线程执行到这里了")
线程间的执行顺序
for i in range(5):
sub_thread = threading.Thread(target=task)
sub_thread.start()
思考:当我们在进程中创建了多个线程,其线程之间是如何执行的呢?按顺序执行?一起执行?还是其他的执行方式呢?
答:线程之间的执行是【无序的】
获取当前线程信息
# 通过current_thread方法获取线程对象
current_thread = threading.current_thread()
# 通过current_thread对象可以知道线程的相关信息,例如被创建的顺序
print(current_thread)
线程间的执行顺序
import threading
import time
"""
多线程执行顺序总结:
主线程、子线程之间的执行顺序我们无法控制,具体执行到谁由CPU调度决定。
也就是CPU调度到哪个线程,那么对应的线程就执行
"""
def code():
for i in range(10):
print(f"子线程_写代码_{i},线程名称{threading.current_thread()}")
time.sleep(0.1)
if __name__ == '__main__':
# 创建子线程
thread_1 = threading.Thread(target=code)
# thread_1 = threading.Thread(target=code,name="sub_thread")
# 启动子线程
thread_1.start()
# 主线程代码
for i in range(10):
print(f"主线程_吃辣条_{i},线程名称{threading.current_thread()}")
time.sleep(0.1)
多线程执行顺序总结:
主线程、子线程之间的执行顺序我们无法控制,具体执行到谁由CPU调度决定。
也就是CPU调度到哪个线程,那么对应的线程就执行
线程间共享全局变量
线程间共享全局变量
多个线程都是在同一个进程中 , 多个线程使用的资源都是同一个进程中的资源 ,因此多线程间是共享全局变量
示例代码:
import threading
import time
# 全局变量
my_list = []
def fn1():
for i in range(100):
if i%2!=0:
my_list.append(i)
print(f"奇数线程:{my_list}")
time.sleep(0.01)
def fn2():
for i in range(100):
if i%2==0:
my_list.append(i)
print(f"偶数线程:{my_list}")
time.sleep(0.01)
if __name__ == '__main__':
# 创建子线程
thread_1 = threading.Thread(target=fn1)
thread_2 = threading.Thread(target=fn2)
# 启动子线程
thread_1.start()
thread_2.start()
# 主线程代码
time.sleep(5)
print(f"主线程:{my_list}")
案例2:
import threading
import time
# 全局变量
my_sum = 0
def fn1():
global my_sum
for i in range(1000001):
my_sum = my_sum + i
print(f"线程1_{my_sum}")
def fn2():
global my_sum
for i in range(1000001):
my_sum = my_sum + i
print(f"线程2_{my_sum}")
if __name__ == '__main__':
# 创建线程
thread_1 = threading.Thread(target=fn1)
thread_2 = threading.Thread(target=fn2)
# 启动线程
thread_1.start()
thread_2.start()
# 主线程代码
time.sleep(5)
print(f"主线程_{my_sum}")

线程锁
学习线程锁的原因如下:
1- 自己在进行技术选型,推荐Python解释器的版本选择3.8及以上
2- 你去到公司以后,有可能需要维护低版本的旧项目,你要明白低版本中有什么问题
3- 知道通过什么方式将线程不安全的代码变成线程安全的
语法格式:
创建锁对象:lock = threading.Lock()
获取锁:lock.acquire()
释放锁:lock.release()
注意: 低版本(3.8版本以下)的Python解释器,会存在修改全局变量异常的情况,需要使用线程锁。高版本没有这个问题。
import threading
import time
# 创建锁对象
lock = threading.Lock()
# 全局变量
my_sum = 0
def fn1():
global my_sum
for i in range(1000001):
# 获得锁/加锁
lock.acquire()
my_sum = my_sum + i
# 释放锁/解锁
lock.release()
print(f"线程1_{my_sum}")
def fn2():
global my_sum
for i in range(1000001):
# 获得锁/加锁
lock.acquire()
my_sum = my_sum + i
# 释放锁/解锁
lock.release()
print(f"线程2_{my_sum}")
if __name__ == '__main__':
# 创建线程
thread_1 = threading.Thread(target=fn1)
thread_2 = threading.Thread(target=fn2)
# 启动线程
thread_1.start()
thread_2.start()
# 主线程代码
time.sleep(5)
print(f"主线程_{my_sum}")

死锁
import threading
import time
"""
死锁总结:
1- 产生原因:锁使用完以后没有释放
2- 如何避免:锁使用完以后及时释放
"""
# 创建锁对象
lock = threading.Lock()
# 全局变量
my_sum = 0
def fn1():
global my_sum
for i in range(1000001):
# 获得锁/加锁
lock.acquire()
my_sum = my_sum + i
print(f"线程1_{my_sum}")
def fn2():
global my_sum
for i in range(1000001):
# 获得锁/加锁
lock.acquire()
my_sum = my_sum + i
print(f"线程2_{my_sum}")
if __name__ == '__main__':
# 创建线程
thread_1 = threading.Thread(target=fn1)
thread_2 = threading.Thread(target=fn2)
# 启动线程
thread_1.start()
thread_2.start()
# 主线程代码
time.sleep(5)
print(f"主线程_{my_sum}")
【掌握】进程和线程对比总结
关系对比
① 线程是依附在进程里面的,没有进程就没有线程。
② 一个进程默认提供一条线程,进程可以创建多个线程。
区别对比
① 进程之间不共享全局变量
② 线程之间共享全局变量
③ 创建进程的资源开销要比创建线程的资源开销要大
④ 进程是操作系统资源分配的基本单位,线程是CPU调度的基本单位
优缺点对比
① 进程优缺点:
优点:可以用多核
缺点:资源开销大
② 线程优缺点
优点:资源开销小
缺点:不能使用多核
正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串做替换或者从某个串中取出符合某个条件的子串等。
正则表达式的作用
① 数据验证(表单验证、如手机、邮箱、IP地址)
② 数据检索(数据检索、数据抓取)
③ 数据隐藏(135****6235 王先生)
④ 数据过滤(论坛敏感关键词过滤)
…
re模块
在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个re模块
re模块使用三步走
# 第一步:导入re模块
import re
# 第二步:使用match方法进行匹配操作
result = re.match(pattern正则表达式, string要匹配的字符串, flags=0)
# 第三步:如果数据匹配成功,使用group方法来提取数据
result.group()
import re
if __name__ == '__main__':
# 正则表达式的前面推荐加上r,意思是正则表达式是怎么写的就怎么使用
result = re.match(pattern=r".it",string="aitcast")
# result = re.match(pattern=r".it",string="aaaaitcast")
if result:
print("匹配上了,内容是啥:",result.group())
else:
print("没有匹配到任何内容")
match函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配数据。
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配,这个功能是为了支持多语言版本的字符集使用环境的,比如在转义符\w,在英文环境下,它代表[a-zA-Z0-9_],即所以英文字符和数字。如果在一个法语环境下使用,缺省设置下,不能匹配”é” 或 “ç”。加上这L选项和就可以匹配了。不过这个对于中文环境似乎没有什么用,它仍然不能匹配中文字符。 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | VERBOSE,冗余模式, 此模式忽略正则表达式中的空白和#号的注释,例如写一个匹配邮箱的正则表达式。该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
import re
if __name__ == '__main__':
# re.I:忽略大小写。也就是a和A当成同一个来看
result = re.findall(r"[a-z]","aB23cD",flags=re.I)
print(result)
print("-"*30)
# re.S:让.能够匹配上\n
result = re.findall(r".*", "aB23\ncD",flags=re.S)
print(result)
re模块的相关方法
☆ re.match(pattern, string, flags=0)
- 从字符串的起始位置匹配,如果匹配成功则返回匹配内容, 否则返回None
☆ re.findall(pattern, string, flags=0)
- 扫描整个串,返回所有与pattern匹配的列表
- 注意: 如果pattern中有分组则返回与分组匹配的列表
- 举例:
re.findall("\d","chuan1zhi2") >> ["1","2"]
☆ re.finditer(pattern, string, flags)
- 功能与上面findall一样,不过返回的是迭代器
参数说明:
- pattern : 模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags: 匹配方式(正则标志修饰符):
- re.I 使匹配对大小写不敏感,I代表Ignore忽略大小写
- re.S 使 . 匹配包括换行在内的所有字符
- re.M 多行模式,会影响^,$
正则表达式快速入门
案例1:查找一个字符串中是否具有数字“8”
import re
result = re.findall('8', '13566128753')
# print(result)
if result:
print(result)
else:
print('未匹配到任何数据')
案例2:查找一个字符串中是否具有数字
import re
result = re.findall('\d', 'a1b2c3d4f5')
# print(result)
if result:
print(result)
else:
print('未匹配到任何数据')
案例3:查找一个字符串中是否具有非数字
import re
result = re.findall('\D', 'a1b2c3d4f5')
# print(result)
if result:
print(result)
else:
print('未匹配到任何数据')
正则表达式基础语法
正则表达式通常是由两部分数据组成的:普通字符 与 元字符
普通字符:0123456789abcd@…
元字符:正则表达式所特有的符号 => [0-9],^,*,+,?
查什么
| 代码 | 功能 |
|---|---|
| .(英文点号) | 匹配任意某1个字符(除了\n) |
| [ ] | 匹配[ ]中列举的某1个字符,专业名词 => 字符簇 |
| [^指定字符] | 匹配除了指定字符以外的其他某个字符,^专业名词 => 托字节 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字 |
| \s | 匹配空白,即 空格,tab键 |
| \S | 匹配非空白 |
| \w | 匹配非特殊字符,即a-z、A-Z、0-9、_ |
| \W | 匹配特殊字符,即非字母、非数字、非下划线 |
字符簇常见写法:
① [abcdefg] 代表匹配abcdefg字符中的任意某个字符(1个)
② [aeiou] 代表匹配a、e、i、o、u五个字符中的任意某个字符
③ [a-z] 代表匹配a-z之间26个字符中的任意某个
④ [A-Z] 代表匹配A-Z之间26个字符中的任意某个
⑤ [0-9] 代表匹配0-9之间10个字符中的任意某个
⑥ [0-9a-zA-Z] 代表匹配0-9之间、a-z之间、A-Z之间的任意某个字符。没有顺序要求
字符簇 + 托字节结合代表取反的含义:
① [^aeiou] 代表匹配除了a、e、i、o、u以外的任意某个字符
② [^a-z] 代表匹配除了a-z以外的任意某个字符
\d 等价于 [0-9], 代表匹配0-9之间的任意数字
\D 等价于 [^0-9],代表匹配非数字字符,只能匹配1个
查多少
| 代码 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无限次,即可有可无(0到多) |
| + | 匹配前一个字符出现1次或者无限次,即至少有1次(1到多) |
| ? | 匹配前一个字符出现1次或者0次,即要么有1次,要么没有(0或1) |
| {m} | 匹配前一个字符出现m次,匹配手机号码\d{11} |
| {m,n} | 匹配前一个字符出现从m到n次,\w{6,10},代表前面这个字符出现6到10次 |
基本语法:
正则匹配字符.或\w或\S + 跟查多少
如\w{6, 10}
如.*,匹配前面的字符出现0次或多次
贪婪模式和非贪婪模式
贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配
正则中的量词:*和+,默认都是贪婪模式的匹配,可以在他们后面加?将其变为非贪婪模式。
常用贪婪模式如: .*
常用非贪婪模式如: .*?
从哪查
| 代码 | 功能 |
|---|---|
| ^ | 匹配以某个字符串开头 |
| $ | 匹配以某个字符串结尾 |
综合代码
匹配单个字符
import re
if __name__ == '__main__':
# findall:对字符串的全部内容进行正则表达式的查找,只要满足正则表达式就返回。返回结果类型是List列表
result = re.findall(pattern=r".",string="a1b2c3c8f8")
print(result)
print(type(result))
print("-"*30)
# []匹配中括号中的任意一个内容
result = re.findall(pattern=r"[kfc]", string="a1b2c3c8f8kfc")
print(result)
print("-" * 30)
# [^]匹配除了中括号中,其他的任意一个内容
result = re.findall(pattern=r"[^kfc]", string="a1b2c3c8f8kfc")
print(result)
print("-" * 30)
# \d:匹配任意一个数字
result = re.findall(pattern=r"\d", string="a1b2c3c8f8kfc")
print(result)
print("-" * 30)
# \D:匹配任意一个非数字
result = re.findall(pattern=r"\D", string="a1b2c3c8f8kfc")
print(result)
print("-" * 30)
# \s:匹配任意个空白字符(空格、制表\t)
result = re.findall(pattern=r"\s", string="a1b 2c3c 8f8kfc")
print(result)
匹配多个字符串
import re
if __name__ == '__main__':
"""
下面代码的结果解释:['', '', 'abcd', '', '', '']
前2个空字符串对应的是1、2数字匹配后的结果
后2个空字符串对应的是3、4数字匹配后的结果
最后一个空字符串对应的是整个字符串匹配后的结果
"""
# result = re.findall(r"\D*","12abcd34")
# result = re.findall(r"[a-z]*","12abcd34")
# a-z表示匹配a-z之间的共26个小写字母
result = re.findall(r"[a-zA-Z]*","12abcd34ABCD")
print(result)
print("-"*30)
# +有多少个就匹配多少
# result = re.findall(r"[a-z]+", "12abcd34")
result = re.findall(r"[a-z]+", "12abcdefg34xyz")
print(result)
print("-" * 30)
"""
?总结:最多匹配1次,即使匹配不上也会返回空字符串
*总结:如果符合要求的连续出现,作为整体匹配上;如果匹配不上,也会返回空字符串
"""
result = re.findall(r"[a-z]*", "12abcdefg34xyz")
print(result)
result = re.findall(r"[a-z]?", "12abcdefg34xyz")
print(result)
print("-" * 30)
result = re.findall(r"[a-z]{2}", "12abcdefg34xyz")
print(result) # ['ab', 'cd', 'ef', 'xy']
print("-" * 30)
# {m,n}:内容连续出现的次数在[m,n]之间的时候就能够整体匹配上
# result = re.findall(r"[a-z]{2,3}", "12ab34xyz") #['ab', 'xyz']
# result = re.findall(r"[a-z]{2,5}", "12ab34xyz") #['ab', 'xyz']
# result = re.findall(r"[a-z]{2,3}", "12abcd34xyz") #['abc', 'xyz']
result = re.findall(r"[a-z]{2,3}", "12abcd34x")
print(result)
匹配开头和结尾
import re
if __name__ == '__main__':
# 需求:必须以小写字母开头,后面内容任意
result = re.findall(r"^[a-z].*","a2345b")
print(result)
print("-"*30)
# 需求:必须以小写字母结束,前面内容任意
result = re.findall(r".*[a-z]$", "a2345b")
print(result)
print("-" * 30)
# 需求:必须以小写字母开头和结束,中间内容任意
result = re.findall(r"^[a-z].*[a-z]$", "a2345b")
print(result)
print("-" * 30)
# 需求:必须以小写字母开头和结束,中间内容必须有5个数字
result = re.findall(r"^[a-z][0-9]{5}[a-z]$", "a23456b")
# result = re.findall(r"^[a-z][0-9]{5}[a-z]$", "a234567b")
# result = re.findall(r"^[a-z]\d{5}[a-z]$", "a23456b")
# result = re.findall(r"^[a-z]\d{5}[a-z]$", "a234567b")
print(result)
【熟悉】几个重要概念
子表达式(分组)
在正则表达式中,通过一对圆括号括起来的内容,我们就称之为”子表达式”,又称之为分组。
re.search(r'\d(\d)(\d)', 'abcdef123ghijklmn')
注意:Python正则表达式前的 r 表示原生字符串(rawstring),该字符串声明了引号中的内容表示该内容的原始含义,避免了多次转义造成的反斜杠困扰。
正则表达式中\d\d\d中,(\d)(\d)就是子表达式,一共有两个()圆括号,则代表两个子表达式
说明:findall方法,如果pattern中有分组则返回与分组匹配的列表,所以分组操作中不适合使用findall方法,建议使用search(匹配一个)或finditer(匹配多个)方法。
捕获
当正则表达式在字符串中匹配到相应的内容后,计算机系统会自动把子表达式所匹配的到内容放入到系统的对应缓存区中(缓存区从$1开始)
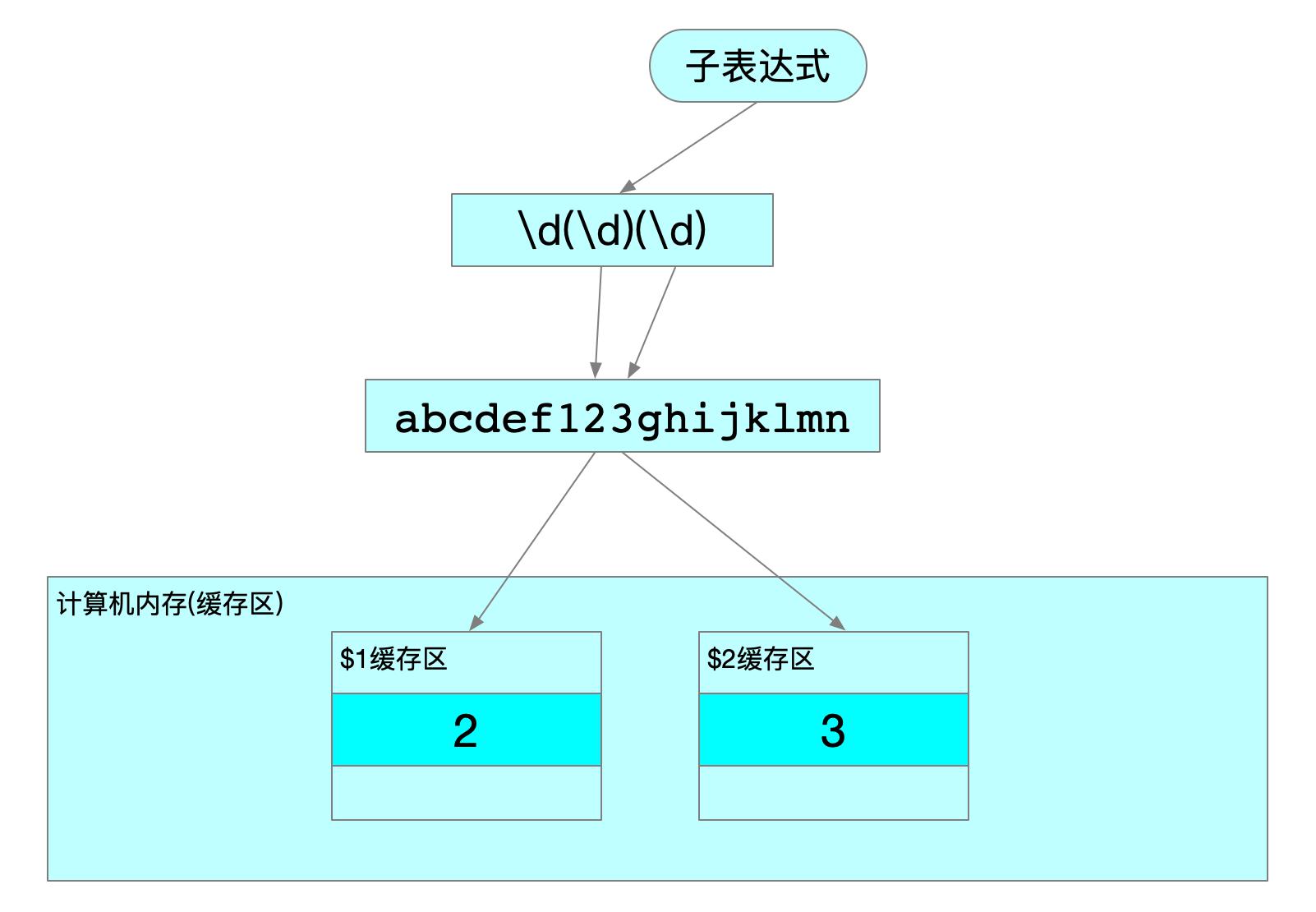
案例演示:
import re
# 匹配字符串中连续出现的两个相同的单词
str1 = 'abcdef123ghijklmn'
result = re.search(r'\d(\d)(\d)', str1)
print(result.group()) # 123
print(result.group(1)) # 2
print(result.group(2)) # 3
反向引用
在正则表达式中,我们可以通过\n(n代表第n个缓存区的编号)来引用缓存区中的内容,我们把这个过程就称之为”反向引用”。
① 连续4个数字
re.search(r’\d\d\d\d, str1)
1234、5678、6789
② 连续的4个数字,但是数字的格式为1111、2222、3333、4444、5555效果?
re.search(r’(\d)\1\1\1, str1)
★几个练习题
① 查找连续的四个数字,如:3569
答:\d{4}
② 查找连续的相同的四个数字,如:1111,2222, 3333, 4444
答:(\d)\1\1\1
③ 查找数字,如:1221,3443
答:(\d)(\d)\2\1
④ 查找字符,如:AABB,TTMM(提示:A-Z,正则:[A-Z])
答:([A-Z])\1([A-Z])\2
⑤ 查找连续相同的四个数字或四个字符(提示:\w)
答:(\w)\1\1\1
综合代码
import re
if __name__ == '__main__':
# 判断邮箱是否是163、126、qq邮箱中的其中一种
# result = re.findall(r"163|126|qq","abc@163.com")
# result = re.findall(r"163|126|qq","abc@126.com")
result = re.findall(r"163|126|qq","abc@qq.com")
print(result)
print("-"*30)
result = re.findall(r"(163|126|qq)(.com)$","abc@qq.com")
# result = re.findall(r"163|126|qq(.com)$","qq@199.com")
print(result)
print("-"*30)
# \2引用第2个分组的正则表达式,而且要求匹配的内容要相同;分组编号从1开始数
result = re.findall(r"([a-z])(\d)(\2)(\1)", "a22a") # 引用分组
# result = re.findall(r"([a-z])(\d)(\2)(\1)", "a23a") # 要求匹配的内容要相同
# result = re.findall(r"([a-z])(\d)(\1)(\0)", "a22a") # 分组编号从1开始数
print(result)
print("-" * 30)
"""
sub进行字符串内容的替换
参数解释:
pattern:正则表达式
repl:替换后的新内容
string:要处理的字符串
"""
line = "i love heima!"
line = re.sub(pattern=r"([.!?])", repl=r" \1", string=line)
# line = re.sub(pattern=r"([.!?])", repl=r" ", string=line)
print(f"-{line}-")
版权声明
本文为 程序员青阳 原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文链接及本声明。