深度学习
什么是深度学习[知道]
深度学习(Deep Learning)是机器学习的分支,是一种以人工神经网络为架构,对数据进行特征学习的算法。深度学习中的形容词“深度”是指在网络中使用多层。
深度学习核心思想是通过模仿人脑的神经网络来处理和分析复杂的数据,从大量数据中自动提取复杂特征,擅长处理高维数据,如图像、语音和文本。
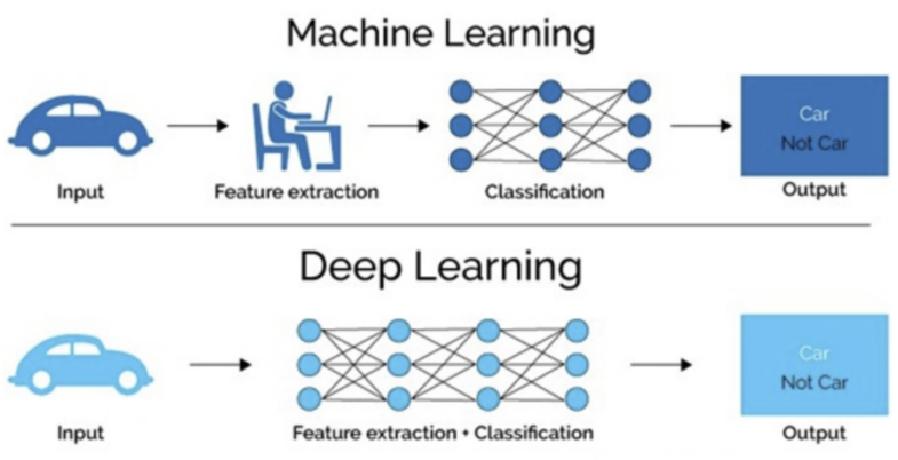
深度学习特点[知道]
多层非线性变换:深度学习模型由多个层次组成,每一层都应用非线性激活函数对输入数据进行变换。较低的层级通常捕捉到简单的特征(如边缘、颜色等),而更高的层级则可以识别更复杂的模式(如物体或面部识别)。
自动特征提取:与传统机器学习算法不同,深度学习能够自动从原始数据中学习到有用的特征,而不需要人工特征工程。这使得深度学习在许多领域中表现出色。
大数据和计算能力:深度学习模型通常需要大量的标注数据和强大的计算资源(如GPU)来进行训练。大数据和高性能计算使得深度学习在图像识别、自然语言处理等领域取得了显著突破。
可解释性差:深度学习模型内部的运作机制相对不透明,被称为“黑箱”,这意味着理解模型为什么做出特定决策可能会比较困难。这对某些应用场景来说是一个挑战。
常见的深度学习模型[了解]
- **卷积神经网络 (Convolutional Neural Networks, CNN)**:
- 主要用于图像处理任务,如图像分类、目标检测、图像分割等。
- 特点是使用卷积层来自动提取图像中的局部特征,并通过池化层减少参数数量,提高计算效率。
- **循环神经网络 (Recurrent Neural Networks, RNN)**:
- 适用于处理序列数据,例如自然语言处理(NLP)、语音识别等。
- RNN具有记忆功能,可以处理输入数据的时间依赖性,但标准RNN难以捕捉长期依赖关系。
- **自编码器 (Autoencoders)**:
- 一种无监督学习模型,通常用于降维、特征学习或者异常检测。
- 自编码器由编码器和解码器两部分组成,前者将输入压缩成一个较低维度的表示,后者尝试从这个低维表示重建原始输入。
- **生成对抗网络 (Generative Adversarial Networks, GAN)**:
- 包含两个子网络:生成器和判别器。生成器负责创建看起来真实的假样本,而判别器则试图区分真假样本。
- GAN广泛应用于图像生成、视频合成等领域。
- Transformer:
- 主要用于自然语言处理(NLP)任务,尤其是机器翻译、文本生成等。
- Transformer摒弃了传统的递归结构,采用自注意力机制(self-attention),使得它能够并行处理整个句子的信息,在机器翻译、文本摘要等任务中表现出色。
深度学习应用场景[了解]
计算机视觉(Computer Vision)
图像分类:将图像分为不同的类别。常用于人脸识别、物体检测等。
- 自动标注社交媒体照片、医疗影像中的病变检测。
目标检测(Object Detection):在图像或视频中定位并分类多个对象。
- 自动驾驶中的行人检测、监控视频中的入侵检测。
面部识别:通过分析面部特征进行身份验证或分类。
- 手机解锁、安防监控系统。
图像生成:基于输入生成新的图像,如风格转换、图像超分辨率等。
- 艺术风格迁移、老旧照片修复。
自然语言处理(Natural Language Processing, NLP)
机器翻译:使用深度学习模型将一种语言的文本自动翻译成另一种语言。
- Google翻译、实时语音翻译。
情感分析:分析文本中的情感倾向,如正面、负面或中性。
- 社交媒体监控、产品评论分析。
文本生成:生成符合语法和语义的自然语言文本。
- 自动写作助手、新闻生成。
语音识别:将语音转化为文字。
- 智能助手(如Siri、Alexa)、自动字幕生成。
聊天机器人(Chatbot):通过深度学习理解用户输入并生成合理的回应。
- 客服机器人、虚拟助手(如GPT类模型)。
推荐系统(Recommendation Systems)
- 电影、音乐推荐:根据用户历史的评分和行为,推荐相关的电影、音乐或电视剧。
- Netflix、Spotify的个性化推荐。
- 电商推荐:根据用户的购买历史和浏览习惯推荐商品。
- 亚马逊、淘宝的商品推荐系统。
- 社交媒体推荐:分析用户的社交行为,推荐相关内容或朋友。
- Facebook、Instagram的内容推荐。
…
- 电影、音乐推荐:根据用户历史的评分和行为,推荐相关的电影、音乐或电视剧。
深度学习发展史[了解]
早期探索
- 20世纪40年代:沃尔特·皮茨(Walter Pitts)和沃伦·麦卡洛克(Warren McCulloch)等开始模仿生物神经系统来构建计算模型,如McCulloch-Pitts神经元
- 1958年:弗兰克·罗森布拉特(Frank Rosenblatt)提出感知器概念,能够进行简单的二分类任务
- 1960年代末:出现了多层感知器(MLP),但当时由于计算能力和数据量的限制,这些模型的应用受到很大限制
挑战与瓶颈
- 1986年:反向传播算法(Backpropagation)的提出标志着神经网络研究的一个重要突破。杰弗里·辛顿(Geoffrey Hinton)和大卫·鲁梅尔哈特(David Rumelhart)等人提出了反向传播算法,使得多层神经网络(即深层网络)能够通过梯度下降优化参数,解决复杂的非线性问题。
- 虽然神经网络方法在一些领域表现不错,但由于计算资源的限制以及对复杂数据(如图像和语音)的处理能力较弱,深度学习未能广泛应用。此时,支持向量机(SVM)、决策树等传统机器学习方法成为主流。
复兴与突破
- 2006年:杰弗里·辛顿和其团队提出了深度信念网络(DBN),标志着深度学习的复兴。他们引入了无监督预训练的技术,使得深层网络能够有效训练。这为深度学习的发展奠定了基础。
- 2012年:深度学习的一个重要突破是AlexNet的出现。亚历克斯·克里泽夫斯基(Alex Krizhevsky)在ImageNet图像分类竞赛中使用了一个深度卷积神经网络,显著提升了图像分类的精度,比传统方法提高了20%以上。AlexNet的成功标志着深度学习在计算机视觉领域的成功应用。
- 2014年:生成对抗网络(GANs)由伊恩·古德费洛(Ian Goodfellow)等人提出,开启了生成模型的新时代,能够生成非常逼真的图像、音频和视频。
- 2015年:ResNet(残差网络)由何凯明(Kaiming He)等提出,解决了深度网络中的梯度消失和梯度爆炸问题,允许训练极深的网络(如50层、152层),极大推动了深度学习在图像识别任务中的应用。
爆发期
- 2016年:Google AlphaGo 战胜李世石(人工智能第三次浪潮),AlphaGo 展现了深度强化学习(Deep Reinforcement Learning)在解决复杂问题上的巨大潜力,将其推向了公众视野。
- 2017年:自然语言处理NLP的Transformer框架出现,奠定了后续预训练语言模型(如 BERT 和 GPT)的基础。
- 2018年:BERT和GPT的出现,基于Transformer架构的预训练语言模型的代表。
- 2022年:ChatGPT的出现,进入到大模型AIGC发展的阶段,开启了 AI 与人交互的新模式,使人们可以更容易地使用 AI 并从中受益。
PyTorch框架简介
什么是PyTorch
PyTorch是一个基于Python的科学计算包
PyTorch安装
pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
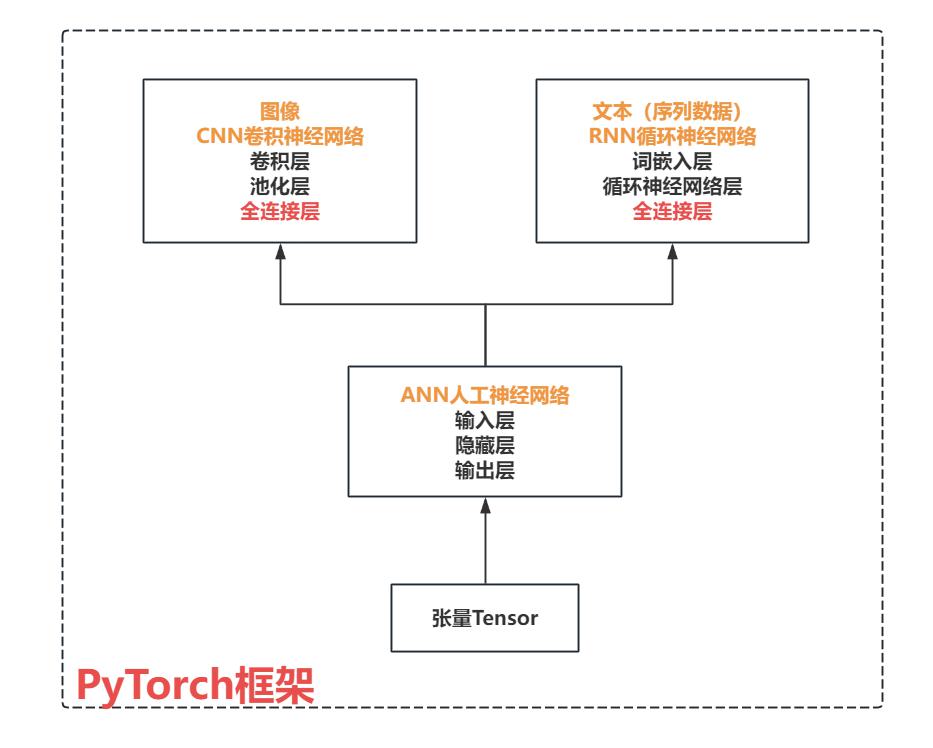
- PyTorch一个基于Python语言的深度学习框架,它将数据封装成张量(Tensor)来进行处理。
- PyTorch提供了灵活且高效的工具,用于构建、训练和部署机器学习和深度学习模型。
- PyTorch广泛应用于学术研究和工业界,特别是在计算机视觉、自然语言处理、强化学习等领域。
PyTorch特点
PyTorch与TensorFlow的比较
- PyTorch与TensorFlow的区别:PyTorch是基于动态图(动态计算图)的,而TensorFlow 1.x是基于静态计算图的(TensorFlow 2.x支持动态图)。这使得PyTorch在灵活性和调试方面优于TensorFlow,尤其是在研究和原型设计中。此外,PyTorch的API设计更加贴近Python,易于学习和使用。
- TensorFlow 2.x(引入了Eager Execution)和PyTorch都支持动态图,但PyTorch因其更直观的编程模式和调试支持,在学术界和一些工业界应用中更为流行。
类似于NumPy的张量计算
- PyTorch中的基本数据结构是张量(Tensor),它与NumPy中的数组类似,但PyTorch的张量具有GPU加速的能力(通过CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的一种并行计算平台和编程模型,它允许开发者利用 NVIDIA GPU 的强大计算能力来加速通用计算任务。),这使得深度学习模型能够高效地在GPU上运行。
自动微分系统
- PyTorch提供了强大的自动微分功能(
autograd模块),能够自动计算模型中每个参数的梯度。 - 自动微分使得梯度计算过程变得简洁和高效,并且支持复杂的模型和动态计算图。
- PyTorch提供了强大的自动微分功能(
深度学习库
- PyTorch提供了一个名为torch.nn的子模块,用于构建神经网络。它包括了大量的预构建的层(如全连接层、卷积层、循环神经网络层等),损失函数(如交叉熵、均方误差等),以及优化算法(如SGD、Adam等)。
torch.nn.Module是PyTorch中构建神经网络的基础类,用户可以通过继承该类来定义自己的神经网络架构。
动态计算图
- PyTorch使用动态计算图机制,允许在运行时构建和修改模型结构,具有更高的灵活性,适合于研究人员进行实验和模型调试。
GPU加速(CUDA支持)
- PyTorch提供对GPU的良好支持,能够在NVIDIA的CUDA设备上高效地进行计算。用户只需要将数据和模型转移到GPU上,PyTorch会自动优化计算过程。
- 通过简单的
tensor.to(device)方法,可以轻松地将模型和数据从CPU转移到GPU或从一个GPU转移到另一个GPU。
跨平台支持
- PyTorch支持在多种硬件平台(如CPU、GPU、TPU等)上运行,并且支持不同操作系统(如Linux、Windows、macOS)以及分布式计算环境(如多GPU、分布式训练)。
PyTorch发展历史
Torch
Torch是最早的Torch框架,最初由Ronan Collobert、Clement Farabet等人开发。它是一个科学计算框架,提供了多维张量操作和科学计算工具。
Torch7
Torch7是Torch的一个后续版本,引入了Lua编程语言,并在深度学习领域取得了一定的成功。遗憾的是,随着pytorch的普及,Torch便不再维护,Torch7也就成为了Torch的最后一个版本。
Pytorch 0.1.0
在Torch的基础上,Facebook人工智能研究院(FAIR)于2016年发布了PyTorch的第一个版本,标志着PyTorch的正式诞生。
初始版本的PyTorch主要基于Torch7,但引入了更加Pythonic的设计风格,使得深度学习模型的定义和调试更加直观和灵活。
Pytorch 0.2.0
该版本首次引入了动态图机制,使得用户能够在构建神经网络时更加灵活。作为Pytorch后期制胜tensorflow的关键机制,该版本象征着Pytorch进入了一个新的阶段。
Pytorch 1.0.0
2018年发布了Pytorch的首个稳定版本,引入了Eager模式简化了模型的构建和训练过程。
Pytorch 2.0
Pytorch2.0引入了torch.compile,可以支持对训练过程的加速,同时引入了TorchDynamo,主要替换torch.jit.trace和torch.jit.script。另外在这个版本中编译器性能大幅提升,分布式运行方面也做了一定的优化。
环境准备
如果遇到如下的错误:

解决方式:
1- 列出虚拟环境
conda env list
2- 创建虚拟环境
conda create -n dl_study python==3.10
3- 部分同学需要执行
conda init
然后重启黑窗口
4- 进入虚拟环境
conda activate dl_study
5- 安装基础软件
pip install torch==2.9.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy==1.26.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas==2.2.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib==3.8.4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install jupyter==1.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple
6- 退出虚拟环境
conda deactivate
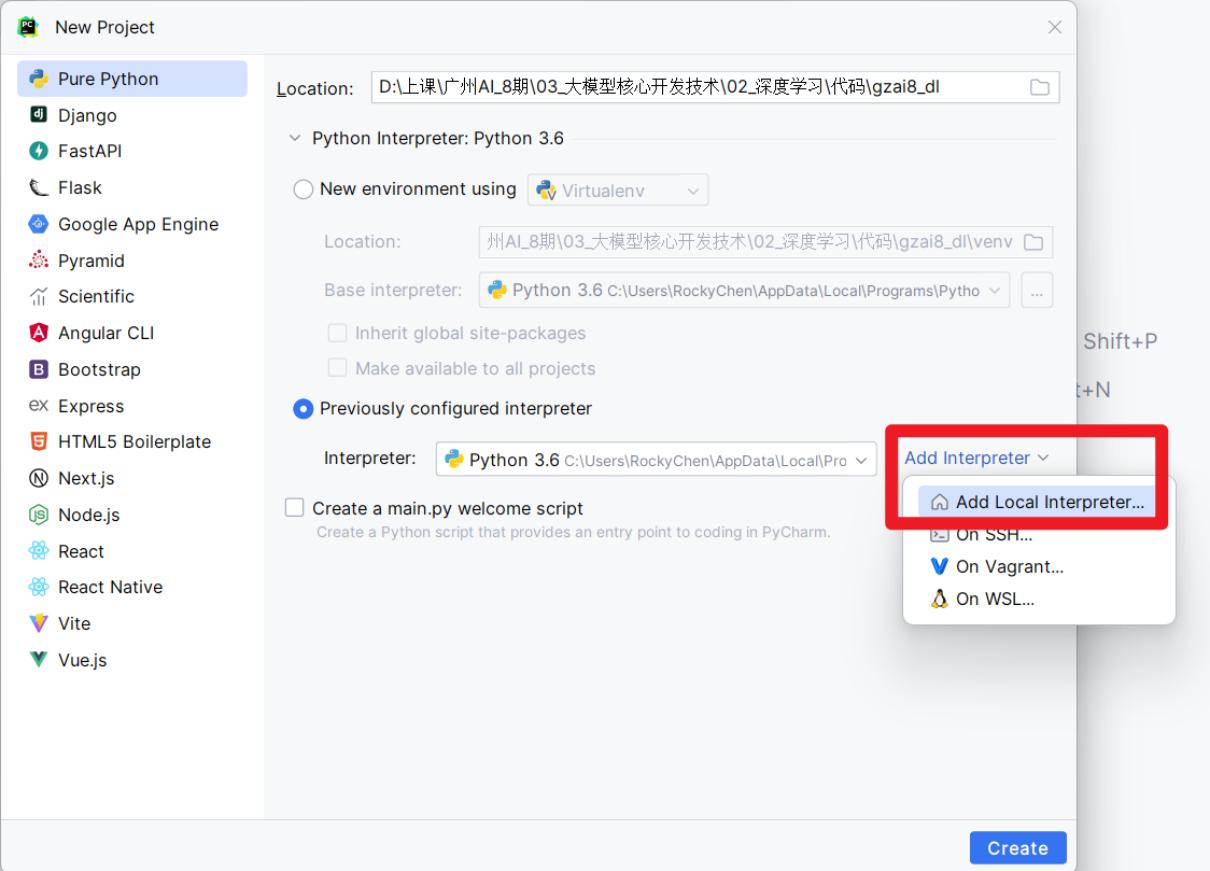
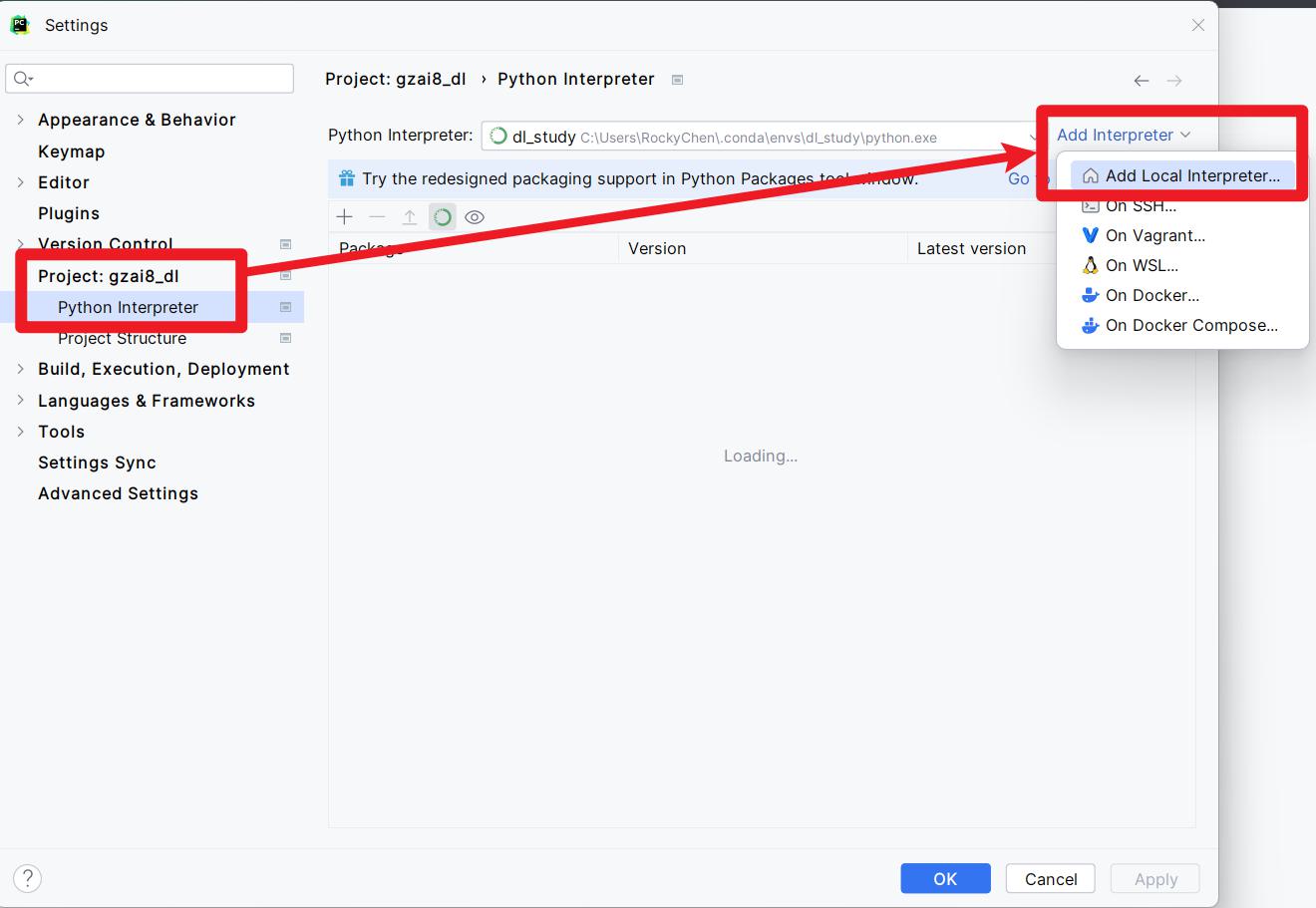
7- 在PyCharm中配置虚拟环境解释器。如下图
- 创建项目的时候设置虚拟环境
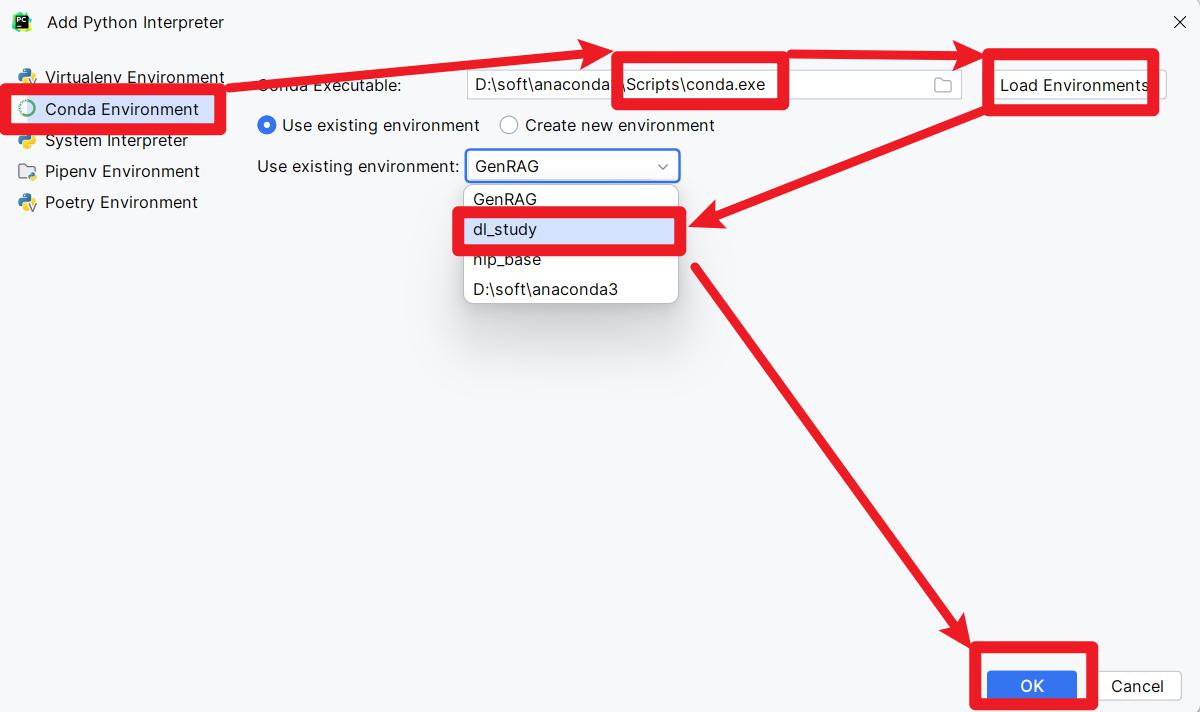
- 项目创建完以后调整虚拟环境
张量创建
掌握:
什么是张量
torch.tensor
torch.linspace
torch.rand
torch.randint
torch.manual_seed
torch.zeros
torch.ones
张量对象.type(数据类型)
什么是张量
张量是PyTorch中的核心数据抽象
PyTorch中的张量就是元素为同一种数据类型的多维矩阵,与NumPy数组类似。
PyTorch中,张量以”类”的形式封装起来,对张量的一些运算、处理的方法(数值计算、矩阵操作、自动求导)被封装在类中。
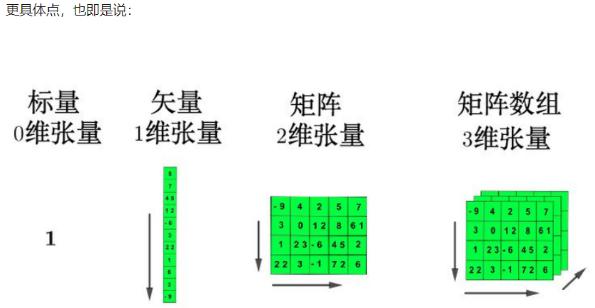
多个二维张量组成三维张量
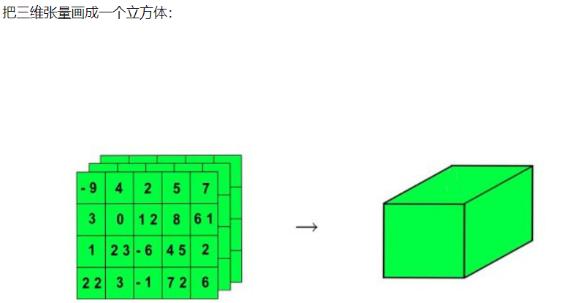
多个三维张量组成四维张量
多个四维张量组成五维张量
基本创建方式
张量的数据类型有
张量中默认的数据类型是float32(torch.FloatTensor)
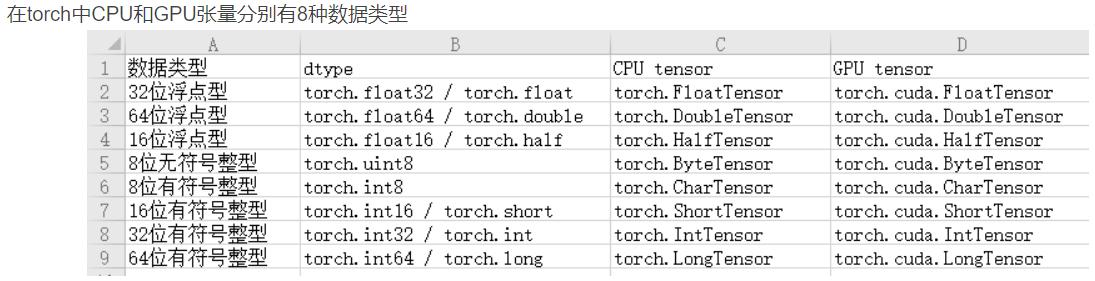
torch.tensor(data=, dtype=) 根据指定数据创建张量
import torch # 需要安装torch模块 import numpy as np # 1. 创建张量标量 data = torch.tensor(10) print(data) # 2. numpy 数组, 由于data为float64, 张量元素类型也是float64 data = np.random.randn(2, 3) print(data,data.dtype) data = torch.tensor(data) print(data,data.dtype) # 3. 传递容器数据类型 # 整数默认是int64 data = torch.tensor([11,22,33]) print(data,data.dtype) # 浮点数默认是float32 data = torch.tensor([1.1, 2.2, 3.3]) print(data,data.dtype)torch.Tensor(size=) 根据形状创建张量, 其也可用来创建指定数据的张量
# 创建2行3列的张量。元素类型默认是float32 data_1 = torch.Tensor(2,3) print(data_1,data_1.dtype) # 注意:如果传递一个标量进去,实际是创建一个长度为5的向量 data_1 = torch.Tensor(5) print(data_1, data_1.dtype) # 如果传递列表, 则创建包含指定元素的张量 data_1 = torch.Tensor([5]) print(data_1, data_1.dtype) data_1 = torch.Tensor([10, 20]) print(data_1)torch.IntTensor()/torch.FloatTensor() 创建指定类型的张量
# 创建2行3列,数据类型为int32的张量 data_2 = torch.IntTensor(2,3) print(data_2,data_2.dtype) # 可以通过传递列表,指定张量具体元素 data_2 = torch.IntTensor([11,22,33]) print(data_2, data_2.dtype) # 注意:创建张量时,如果传递的元素值类型与张量类型不匹配,会自动进行类型转换 data_2 = torch.IntTensor([11.1,22.2,33.3]) data_2 # 3. 其他的类型 data = torch.ShortTensor() # int16 data_2 data = torch.LongTensor() # int64 data_2 data = torch.FloatTensor() # float32 data_2 data = torch.DoubleTensor() # float64 data_2
线性和随机张量
torch.arange(start=, end=, step=):固定步长线性张量
torch.linspace(start=, end=, steps=):固定元素数线性张量
# arange区间是[start,end)左闭右开 data_3 = torch.arange(start=1,end=10,step=2) print(data_3,data_3.dtype) # 生成一维张量。linspace区间是[start,end]左右都是闭区间。注意steps不表示步长,表示生成的元素个数 data_3 = torch.linspace(start=1,end=10,steps=6) data_3torch.randn/rand(size=) 创建随机浮点类型张量
torch.randint(low=, high=, size=) 创建随机整数类型张量 左闭右开
torch.initial_seed() 和 torch.manual_seed(seed=) 随机种子设置
# 创建2行3列的随机值张量。元素值区间在[0,1)之间 data_3 = torch.rand(2,3) data_3 # 创建2行3列的随机值张量。元素值符合标准正态分布 data_3 = torch.randn(2,3) data_3 # 区间是左闭右开 data_3 = torch.randint(low=1,high=10,size=(2,3)) data_3 # 查看随机数种子 seed = torch.initial_seed() seed # 手动设置随机数种子 # 设置以后,生成的随机数将会固定 torch.manual_seed(4) data_3 = torch.randn(2,3) data_3
指定值张量
torch.zeros(size=) 和 torch.zeros_like(input=) 创建全0张量
# 1. 创建指定形状2行3列,值全0张量 data = torch.zeros(2, 3) print(data) # 2. 根据张量形状创建全0张量 data = torch.zeros_like(data) print(data)torch.ones(size=) 和 torch.ones_like(input=) 创建全1张量
# 1. 创建指定形状全1张量 data = torch.ones(2, 3) print(data) # 2. 根据张量形状创建全1张量 data = torch.ones_like(data) print(data)torch.full(size=, fill_value=) 和 torch.full_like(input=, fill_value=) 创建全为指定值张量
# 创建全为指定值张量 data_4 = torch.full(size=(2,3),fill_value=99) data_4 # 根据张量形状创建指定值的张量 data_5 = torch.full_like(data_4, 20) data_5
指定元素类型张量
data.type(dtype=)
data = torch.full(size=(2,3),fill_value=10) print(data, data.dtype) # 神经网络中要求的数据类型就是float32 data_1 = data.type(torch.float32) data_1 # 转换为其他类型 data_1 = data.type(torch.float64) data_1 # 还有其他的写法 data_1 = data.type(torch.FloatTensor) data_1 data_1 = data.type(torch.DoubleTensor) data_1 # data = data.type(torch.ShortTensor) # data = data.type(torch.IntTensor) # data = data.type(torch.LongTensor) # data = data.type(torch.FloatTensor) # data = data.type(dtype=torch.float16)data.half/float/double/short/int/long()
data = torch.full(size=(2,3),fill_value=10) print(data, data.dtype) # float16 data_1 = data.half() data_1 # float64 data_1 = data.double() data_1 # int16 data_1 = data.short() data_1
张量类型转换
掌握:
torch.tensor()
张量对象.item()
张量转换为NumPy数组
使用 t.numpy() 函数可以将张量转换为 ndarray 数组,但是共享内存,可以使用copy函数避免共享。
import torch import numpy as np # 张量 转 numpy的ndarray t_1 = torch.tensor([11,22,33]) print(t_1, type(t_1)) # 共享内存 arr_1 = t_1.numpy() print(arr_1, type(arr_1)) # 可以在后面使用copy(),不共享内存 arr_2 = t_1.numpy().copy() print(arr_2, type(arr_2)) t_1[0] = 100 print(f"t_1={t_1},arr_1={arr_1},arr_2={arr_2}")
NumPy数组转换为张量
使用 torch.from_numpy(ndarray=) 可以将ndarray数组转换为 tensor张量,默认共享内存,使用copy函数避免共享。
使用 torch.tensor(data=) 可以将ndarray数组转换为tensor张量,默认不共享内存。
# numpy的ndarray 转 张量 arr = np.array([11,22,33]) print(arr,type(arr)) # 共享变量 t_1 = torch.from_numpy(arr) print(t_1, type(t_1)) # 不共享变量 t_2 = torch.tensor(arr) print(t_2, type(t_2)) arr[0] = 99 print(f"arr={arr},t_1={t_1},t_2={t_2}")
提取标量张量的数值
对于只有一个元素的张量,使用item()函数将该值从张量中提取出来
# 标量 和 张量 互转 # 1- 标量 转 张量 # t_1 = torch.tensor(24) t_1 = torch.tensor([24]) print(t_1, type(t_1)) # 2- 张量 转 标量 value = t_1.item() print(value, type(value)) # 注意:张量中只有一个值的时候才能够使用item() t_2 = torch.tensor([11,22]) t_2 values = t_2.item() values
张量数值计算
掌握:+ - * / @
基本运算
加减乘除取负号:
+、-、*、/、-
add(other=)、sub、mul、div、neg
add_(other=)、sub_、mul_、div_、neg_(其中带下划线的版本会修改原数据)import torch # 1---- 基本运算 ---- t1 = torch.tensor([[1,2,3],[4,5,6]]) t1 # 张量 和 数值运算,张量中每个元素都会和该数值进行运算 t2 = t1 + 10 t2 t3 = t1 * 10 t3 # 运算函数 # 不带下划线的函数,不会修改源数据 # 下面的两种调用方式都行 # t4 = torch.add(t3,10) t4 = t3.add(10) print(t3, "\n", t4) # 带下划线的函数,会修改源数据 # 同时注意调用方式。只能这么调用 t5 = t3.add_(10) print(t3, "\n", t5) # neg()、neg_()取反函数。正数变负数,负数变正数 t1 = torch.tensor([[1, -2, 3], [4, -5, -6]]) t1 # 不会修改源数据 t2 = t1.neg() print(t1, "\n", t2) # 会修改源数据 t3 = t1.neg_() print(t1, "\n", t3) # 其他函数 t1 = torch.tensor([[1, -2, 3], [4, -5, -6]]) print(t1.sub(100)) # 减法 print(t1.mul(100)) # 乘法 print(t1.div(100)) # 除法
点乘运算
点乘(Hadamard)也称为元素级乘积,指的是相同形状的张量对应位置的元素相乘,使用mul和运算符 * 实现。
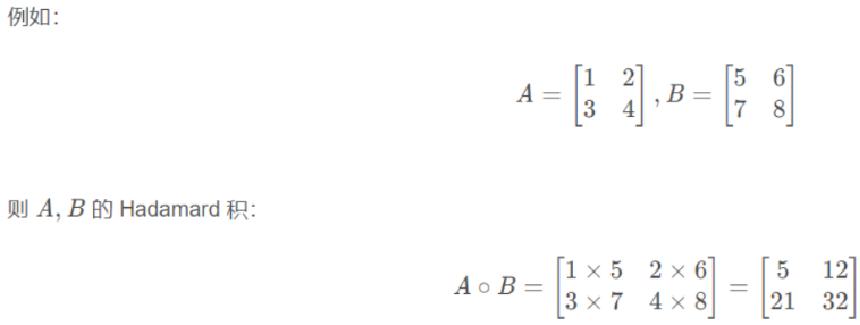
# 定义张量. 3行2列
t1 = torch.tensor([[1, 2], [3, 4], [5, 6]])
# 定义张量. 3行2列
t2 = torch.tensor([[7, 8], [9, 10], [11, 12]])
# t2 = torch.tensor([[7, 8], [9, 10]])
print(f't1: {t1},\n t2: {t2}')
# 点乘
# 要求:两个张量的形状要相同
# 结果:对应位置元素相乘
t3 = t1 * t2
t3
# 点乘函数mul,推荐直接用*
t4 = t1.mul(t2)
t4
矩阵乘法运算
矩阵乘法运算要求第一个矩阵 shape: (n, m),第二个矩阵 shape: (m, p), 两个矩阵点积运算 shape 为: (n, p)。
运算符 @ 用于进行两个矩阵的乘积运算
torch.matmul(input=, other=)
# 定义张量. 3行2列 t1 = torch.tensor([[1, 2, 3], [4, 5, 6]]) # 定义张量. 3行2列 t2 = torch.tensor([[7, 8], [9, 10], [11, 12]]) print(f't1: {t1},\n t2: {t2}') # 要求:前一个矩阵的列数 = 后一个矩阵的行数 t3 = t1 @ t2 t3 # 矩阵相乘函数matmul,推荐使用@ # 下面两个写法都行 t4 = t1.matmul(t2) # t4 = torch.matmul(t1,t2) t4
张量运算函数
tensor.mean(dim=):平均值tensor.sum(dim=):求和。掌握tensor.min/max(dim=):最小值/最大值tensor.pow(exponent=):幂次方 $$x^n$$tensor.sqrt():平方根tensor.exp():指数 $$e^x$$tensor.log():对数 以e为底dim=0按第0维(也就是行)计算,dim=1按第1维(也就是列)计算。dim=-1按最里面的维度进行计算
import torch # 定义张量, 浮点型. t1 = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float) print(t1, t1.shape) # 1- sum求和 # dim=0,按列求和 r1 = t1.sum(dim=0) r1 # dim=1,按行求和 r2 = t1.sum(dim=1) r2 # dim不设置值,对所有元素求和 r3 = t1.sum() r3 # 2- 均值,元素数据类型必须是float,不能是整数 t1 = torch.tensor([[1, 2, 3], [4, 5, 6]],dtype=torch.float32) # t1 = torch.tensor([[1, 2, 3], [4, 5, 6]],dtype=torch.int32) # r1 = t1.mean(dim=0) r1 = t1.mean(dim=1) r1 # 3- 平方/立方/平方根/e的n次幂/对数 t1 = torch.tensor([[1, 2, 3], [4, 5, 6]], dtype=torch.float) print(t1.pow(2)) # 平方 print(t1.pow(3)) # 立方 print(t1.sqrt()) # 开根号 print(t1.exp()) # e的n次幂,元素作为幂使用 print(t1.log()) # 以e为底求对数 print(t1.log2()) # 以2为底的对数 print(t1.log10()) # 以10为底的对数 print(torch.log(t1) / torch.log(torch.tensor(3))) # 以3为底的对数(了解) data1 = torch.randint(low=1,high=4,size=(2,3,4)) print(data1) print(data1.sum(dim=0)) print(data1.sum(dim=1)) print(data1.sum(dim=2)) # dim=-1:不管张量有多少维,全部以最里层的列表为最小单位进行计算 print(data1.sum(dim=-1))
张量索引操作
掌握:范围索引[行索引开始:行索引结束:step, 列索引开始:列索引结束:step],注意是含头不含尾
我们在操作张量时,经常需要去获取某些元素就进行处理或者修改操作,在这里我们需要了解在torch中的索引操作。
import torch
t1 = torch.randint(low=1,high=5,size=(4,5))
t1
# 1---- 行列索引【掌握】 ----
# 张量对象[行索引开始:行索引结束, 列索引开始:列索引结束]
# 获取第1行
print(t1[0])
# 获取第1列
print(t1[:, 0])
# 2---- 列表索引【了解】 ----
# 需求1: 返回(0, 1), (1, 2)两个位置的元素
print(t1[[0, 1], [1, 2]])
# 需求2: 返回(0, 3), (2,4)两个位置的元素.
print(t1[[0, 2], [3, 4]])
# 需求3: 获取第0行的 第3列和第4列; 第2行的 第3列和第4列
print(t1[[[0], [2]], [3, 4]])
# 3---- 范围索引【掌握】 ----
# 含头不含尾
# 张量对象[行索引开始:行索引结束, 列索引开始:列索引结束]
# 需求1: 前3行, 前2列
print(t1[0:3, 0:2])
# 需求2: 第2行到最后, 前2列
print(t1[1:, :2])
# 4---- 布尔索引 ----
# 需求1: 第3列中值大于等于3,对应行数据
# 取出第3列
print(t1[:, 2])
# 判断是否大于等于3
print(t1[:, 2] >= 3)
# 取出对应的行数据
print(t1[t1[:, 2] >= 3])
# 需求2: 第2行中值大于等于3,对应列数据
print(t1[:, t1[1] >= 3])
# 5---- 多维索引【了解】 ----
data = torch.randint(low=1,high=5,size=(3,4,5))
print(data)
# 获取0维上的第1个数据
print(data[0, :, :])
# 获取1维上的第1个数据
print(data[:, 0, :])
# 获取2维上的第1个数据
print(data[:, :, 0])
张量形状操作
掌握:
reshape
squeeze
unsqueeze
transpose
permute
view
张量形状操作是指对张量的维度进行变换的一系列操作。
张量的形状则描述了每个维度上的元素数量。
reshape
保证张量数据个数不变的前提下改变维度
import torch
data = torch.tensor([[10, 20, 30], [40, 50, 60]])
# 1. 使用 shape 属性或者 size 方法都可以获得张量的形状
print(data.shape, data.shape[0], data.shape[1])
print(data.size(), data.size(0), data.size(1)) # 效果同上
# reshape
t2 = t1.reshape(shape=(2,6))
# t2 = t1.reshape(shape=(2,2))
# t2 = t1.reshape(shape=(2,20))
# -1:Pytorch底层自动帮你计算,但是只允许有一个-1
t2 = t1.reshape(shape=(6,-1))
# reshape:能够升维、降维;同时可以在维度不变的情况下修改形状。
t2 = t1.reshape(shape=(-1,))
t2 = t1.reshape(shape=(2,-1,2))
t2 = t1.reshape(shape=(2,1,2,3))
print(t2.shape)
squeeze和unsqueeze
squeeze:删除指定位置形状为1的维度,不指定位置则删除所有形状为1的维度,降维
unsqueeze:在指定位置添加形状为1的维度,升维
# squeeze降维和unsqueeze升维
t1 = torch.randint(low=1,high=5,size=(3,4))
print(t1)
# 升维:dim小于等于张量的维度个数
t2 = t1.unsqueeze(dim=0)
print(t2.shape)
t3 = t1.unsqueeze(dim=1)
print(t3.shape)
t4 = t1.unsqueeze(dim=2)
print(t4.shape)
# t5 = t1.unsqueeze(dim=3)
# print(t5.shape)
"""
squeeze总结:
1- 如果不传递参数,会将所有为1的形状全部删除
2- 如果传递dim参数,当同时满足指定位置和该位置的形状为1的时候,才会删除。否则没影响
"""
t1 = torch.randint(low=1,high=5,size=(3,1,4,1))
print(t1,t1.shape)
t2 = t1.squeeze()
print(t2.shape) # [3,4]
t3 = t1.squeeze(dim=1)
print(t3.shape) # [3,4,1]
t4 = t1.squeeze(dim=0)
print(t4.shape)
transpose和permute
transpose:实现交换张量形状的指定维度, 例如: 一个张量的形状为 (2, 3, 4) ,把 3 和 4 进行交换, 将张量的形状变为 (2, 4, 3)
permute:一次交换更多的维度
t1 = torch.randint(1,10,(2,3,5))
print(t1, t1.shape)
# 需求1: 交换0轴 和 1轴. (2, 3, 5) -> (3, 2, 5)
"""
transpose(参数1,参数2):注意每次只能交换两个维度的位置
参数1、参数2 表示的是要交换哪几个轴的位置。参数传递顺序无所谓
"""
# 下面两个写法效果一样
# t2 = t1.transpose(dim0=1,dim1=0)
t2 = t1.transpose(dim0=0,dim1=1)
print(t2, t2.shape)
print("-"*30)
# 需求2: 从 (2, 3, 5) -> (5, 2, 3)
"""
permute(dims):同一时刻可以交换多个维度的位置。参数中传递的是维度顺序
"""
t3 = t1.permute(dims=[2,0,1])
print(t3, t3.shape)
view
t1 = torch.tensor(data=[[11, 22, 33], [44, 55, 66]])
print(t1.shape)
print(t1.is_contiguous()) # 判断逻辑顺序与内存中的物理顺序是否一致。True表示一致
"""
view修改张量形状的前提是,逻辑顺序与物理存储顺序要保持一致。实际使用更多的是reshape
"""
t2 = t1.view(3,2)
print(t2.shape)
print(t2.is_contiguous())
t3 = t1.transpose(dim0=0,dim1=1)
print(t3.shape)
print(t3.is_contiguous())
# t4 = t3.view(2,3)
t4 = t3.contiguous().view(2,3) # contiguous()让逻辑顺序与物理顺序保持一致
print(t4.shape)
张量拼接操作
掌握:
concat/cat
stack
张量拼接操作用于组合来自不同来源或经过不同处理的数据。
cat/concat
沿着现有维度连接一系列张量。所有输入张量除了指定的拼接维度外,其他维度必须一样。
"""
cat:
1- 不能修改张量的维度个数。例如:不能将2维变3维
2- 除了拼接的维度以外,其他维度必须相同
"""
t1 = torch.randint(1,10,size=(2,3))
t2 = torch.randint(1,10,size=(2,3))
print(t1,t1.shape)
print(t2,t2.shape)
cat_1 = torch.cat([t1,t2],dim=0)
print(cat_1,cat_1.shape)
cat_2 = torch.cat([t1,t2],dim=1)
print(cat_2,cat_2.shape)
# 不能将2维变3维
# torch.cat([t1,t2],dim=2)
t1 = torch.randint(1,10,size=(2,3))
# 除了拼接的维度以外,其他维度必须相同
t2 = torch.randint(1,10,size=(5,3))
# t2 = torch.randint(1,10,size=(2,4))
print(t1,t1.shape)
print(t2,t2.shape)
cat_1 = torch.cat([t1,t2],dim=0)
print(cat_1,cat_1.shape)
stack
在一个新的维度上连接一系列张量,这会增加一个新维度,并且所有输入张量的形状必须完全相同。
import torch
"""
stack:
1- 两个拼接的张量形状必须完全一样
2- 会产生新维度,在新维度上进行拼接操作
"""
t1 = torch.randint(1,10,size=(5,6))
t2 = torch.randint(1,10,size=(5,6))
print(t1,t1.shape)
print(t2,t2.shape)
stack_1 = torch.stack([t1,t2],dim=0)
print(stack_1,stack_1.shape) # [2,5,6]
stack_2 = torch.stack([t1,t2],dim=1)
print(stack_2.shape) # [5,2,6]
stack_3 = torch.stack([t1,t2],dim=2)
print(stack_3.shape) # [5,6,2]
自动微分模块【理解】
自动微分就是自动计算梯度值,也就是计算导数。
- 什么是梯度
- 对函数求导的值就是梯度
- 什么是梯度下降法
- 是一种求最优梯度值的方法,使得损失函数的值最小
- 梯度经典语录
- 对函数求导得到的值就是梯度 (在数值上的理解)
- 在某一个点上,对函数求导得到的值就是该点的梯度
- 没有点就无法求导,没有梯度
- 梯度就是下山最快的方向 (在方向上理解)
- 在平面内,梯度就是某一点上的斜率
- y = 2x^2 某一点x=1的梯度,就是这一点上的斜率
- 反向传播传播的是梯度
- 反向传播利用链式法则不断的从后向前求导,求出来的值就是梯度,所以大家都经常说反向传播传播的是梯度
- 链式法则中,梯度相乘,就是传说中的梯度传播
- 对函数求导得到的值就是梯度 (在数值上的理解)
训练神经网络时,最常用的算法就是反向传播。在该算法中,参数(模型权重)会根据损失函数关于对应参数的梯度进行调整。为了计算这些梯度,PyTorch内置了名为 torch.autograd 的微分模块。它支持任意计算图的自动梯度计算:
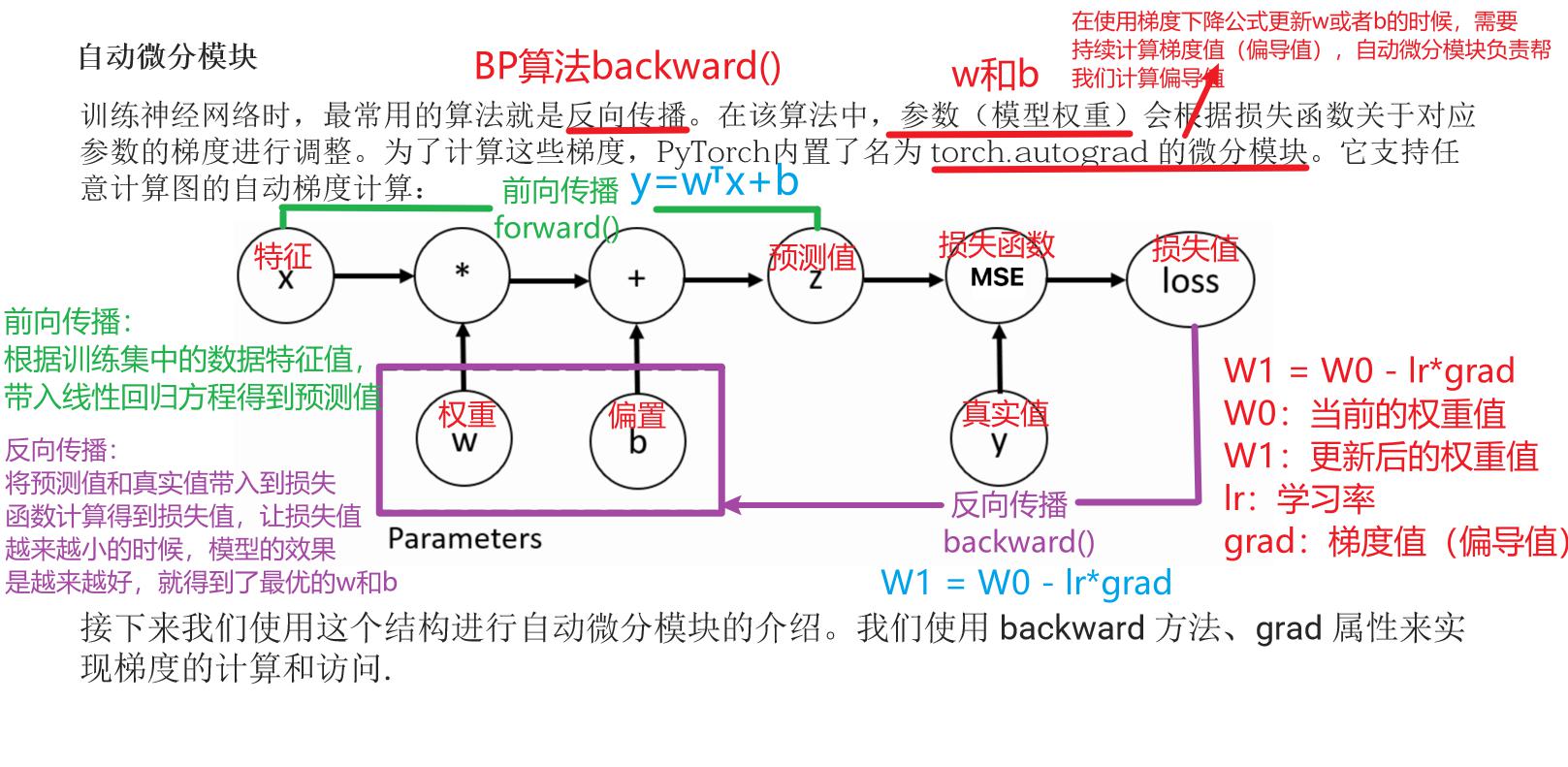
接下来我们使用这个结构进行自动微分模块的介绍,我们使用 backward 方法、grad 属性来实现梯度的计算和访问。
梯度基本计算

标量张量梯度计算_单轮
import torch if __name__ == '__main__': # 只演示反向传播 # 1- 初始化权重 """ 注意: 1- requires_grad必须设置为True,也就是允许进行反向传播计算梯度值。否则报错: RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn 2- 参与反向传播的相关数据的类型,必须是小数,不能是整数。因为经过梯度下降公式,会出现小数的情况 """ # w = torch.tensor(10,requires_grad=True,dtype=torch.float32) # 只有一个权重值,那么说明数据只有一列特征 w = torch.tensor([10,20],requires_grad=True,dtype=torch.float32) # 有多个权重值,那么说明数据有多列特征 # 2- 定义损失函数 # 这里是人工自定义的函数,想怎么写都行。后面是直接调用API loss = 2*w**2 # 3- 反向传播:通过让损失值越来越小,得到最优的w和b """ 如果参数有多个的时候,loss结果是向量张量。但是向量和向量间无法进行求导。 因此可以调用没有参数的sum()或者mean(),将向量转成标量 """ loss.sum().backward() # 4- 更新参数:通过梯度下降公式更新w和b # W1 = W0 - lr*grad lr = 0.1 grad = w.grad w.data = w.data - lr*grad print(f"更新后的权重值:{w},-- {w.data}")标量张量梯度计算_多轮
import torch # 演示多次反向传播的过程 if __name__ == '__main__': # 1- 初始化权重值 w = torch.tensor(10,requires_grad=True,dtype=torch.float32) # 2- 循环多次进行反向传播 epochs = 20 # 20个轮次 for epoch in range(epochs): # 3- 定义损失函数 loss = 2*w**2 # 4- 梯度清零 # 第一次的时候没有梯度值 if w.grad is not None: w.grad.zero_() # 5- 反向传播。只需要掌握这一行代码 loss.sum().backward() # 6- 更新参数 # W1 = W0 - lr*grad old_w = w.data lr = 0.1 grad = w.grad w.data = w.data - lr*grad print(f"第{epoch+1}轮次,历史权重值{old_w},更新后的权重值{w.data}")
自动微分模块应用
演示前向传播和反向传播的过程
import torch
if __name__ == '__main__':
# =============== 前向传播 =================
# 1- 样本数据准备
# 1.1- 特征数据
# 2条样本,每条样本有5列特征
x = torch.ones(size=(2,5))
# 1.2- 目标值
# 形状为什么是3:目标值用向量表示,而这个向量中有3个元素
y = torch.zeros(size=(2,3))
# 1.3- 权重初始值
w = torch.randn(size=(5,3),requires_grad=True,dtype=torch.float32)
# 1.4- 偏置初始值
b = torch.randn(size=(3,),requires_grad=True,dtype=torch.float32)
# 1.5- 预测值
z = x @ w + b
# 1.6- 损失函数
loss = torch.nn.MSELoss()
# 2- 计算损失值
# 内部自动调用forward方法
loss_value = loss(z,y)
# =============== 反向传播 =================
# 3- 反向传播
loss_value.sum().backward()
# 4- 更新参数:w和b
print(f"w的梯度值:{w.grad}")
print(f"b的梯度值:{b.grad}")
PyTorch模拟线性回归模型【熟悉】
我们使用 PyTorch 的各个组件来构建线性回归模型。在pytorch中进行模型构建的整个流程一般分为四个步骤:
- 准备训练集数据
- 构建要使用的模型
- 设置损失函数和优化器
- 模型训练
要使用的API:
- 使用 PyTorch 的 nn.MSELoss() 代替平方损失函数
- 使用 PyTorch 的 data.DataLoader 代替数据加载器
- 使用 PyTorch 的 optim.SGD 代替优化器
- 使用 PyTorch 的 nn.Linear 代替假设函数
from sklearn.datasets import make_regression # 产生样本数据
import torch
from torch.utils.data import TensorDataset,DataLoader # 数据封装相关
import torch.nn as nn
import torch.optim as optim # 优化器对象
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def create_dataset():
"""
coef:是随机生成的100条样本真实的斜率。为什么能够得到真实的斜率呢?老师出卷子,那么老师是知道每道题的真实答案
x:特征值
y:目标值
"""
x,y,coef = make_regression(
n_samples=100, # 生成的样本条数
n_features=1, # 每条样本的特征列数
bias=3.20, # 线性回归方程中的截距,也就是b
coef=True, # 是否需要返回斜率,也就是w
noise=10, # 噪声值。避免让样本连成一条直线
shuffle=True, # 打散样本数据,让模型训练更加充分
random_state=320 # 随机数种子
)
# print(type(x)) # numpy.ndarray
# print(x)
# print(y)
# print(coef) # 30.499504914850426
# 包装成张量返回:因为深度学习只能处理张量数据
x = torch.tensor(x,dtype=torch.float32)
y = torch.tensor(y,dtype=torch.float32)
return x,y,coef
def train_model(x,y,coef):
# 1- 构造数据加载器
"""
不管传递进来的数据类型是啥,都得经过如下的过程
List/ndarray/DataFrame。。。 -> 张量Tensor -> 数据集Dataset -> 数据加载器DataLoader
"""
# 1.1- 张量包装成Dataset
dataset = TensorDataset(x,y)
# 1.2- Dataset变成Dataloader
"""
参数解释:
dataset:数据集对象
batch_size:每个批次中样本条数。一般是2的n次方,例如:1、2、4、。。。64
注意:
1- 变成Dataloader的原因是防止资源不够
2- 什么时候batch_size的值能够大于1?
样本的长度相同的时候,才能设置超过1。里面用到的原理是stack
"""
dataloader = DataLoader(
dataset=dataset,
batch_size=16,
shuffle=True
)
# 2- 创建类的实例对象
# 2.1- 模型实例对象:目前这里是线性回归对象
"""
参数解释:
in_features:输入特征个数。也就是输入层的神经元个数
out_features:输出特征个数。也就是隐藏层的神经元个数
"""
model = nn.Linear(in_features=1,out_features=1,bias=True)
# 2.2- 损失函数对象
loss = nn.MSELoss()
# 2.3- 优化器对象
"""
参数解释:
params:告诉模型,在进行反向传播的时候,需要对算法模型中的哪些参数(就是w和b)进行参数值的更新
lr:梯度下降公式中的学习率
"""
optimizer = optim.SGD(params=model.parameters(),lr=0.01)
# 3- 模型训练
epochs = 100 # 100个轮次
loss_list = [] # 100个轮次的平均损失值列表
# 外层循环控制轮次
for epoch in range(epochs):
total_loss_value = 0.0 # 每个轮次中的总损失值
total_sample_cnt = 0 # 每个轮次中的总样本条数
# 内层循环控制批次
for x_train,y_train in dataloader:
# 3.1- 前向传播:得到预测结果
y_pred = model(x_train)
# 3.2- 计算损失值
# print("预测值形状:",y_pred.shape) # torch.Size([16, 1])
# print("真实值形状:",y_train.shape) # torch.Size([16])
loss_value = loss(y_pred,y_train.reshape(-1,1))
# 3.3- 计算损失信息
# loss_value.item() * len(y_train)目的是因为前面的MSE内部算的平均损失
total_loss_value += loss_value.item() * len(y_train)
total_sample_cnt += len(y_train)
# 3.4- 反向传播固定代码
optimizer.zero_grad() # 梯度清零
loss_value.sum().backward() # 反向传播
optimizer.step() # 更新参数:也就是基于梯度下降公式,更新w和b
# 4- 记录每个轮次的平均损失
avg_loss = total_loss_value / total_sample_cnt
loss_list.append(avg_loss)
print(f"第{epoch+1}轮次,平均损失:{avg_loss}")
# 5- 可视化展示
# 5.1- 循环轮次epochs与损失值的关系
plt.plot(range(epochs), loss_list)
plt.xlabel("循环轮次epochs")
plt.ylabel("损失值")
plt.title("循环轮次epochs与损失值的关系")
plt.grid()
plt.show()
# 5.2- 预测和真实结果对比
"""
1- 展示100条样本的散点图:横轴特征x,纵轴目标y
2- 真实线性回归曲线图
3- 预测线性回归曲线图
"""
plt.scatter(x, y)
axis_x = torch.linspace(x.min(), x.max(), 1000)
# 真实线性回归曲线图
true_fn_torch = torch.tensor([tmp_x * coef + 3.2 for tmp_x in axis_x])
# 预测线性回归曲线图
pred_fn_torch = torch.tensor([tmp_x * model.weight.detach() + model.bias.detach() for tmp_x in axis_x])
plt.plot(axis_x, true_fn_torch, label="真实值", color="red")
plt.plot(axis_x, pred_fn_torch, label="预测值", color="blue")
plt.grid()
plt.legend()
plt.title("真实和预测的对比")
plt.show()
if __name__ == '__main__':
# 1- 创建测试数据
x,y,coef = create_dataset()
# 2- 模型训练
train_model(x,y,coef)
## 神经网络
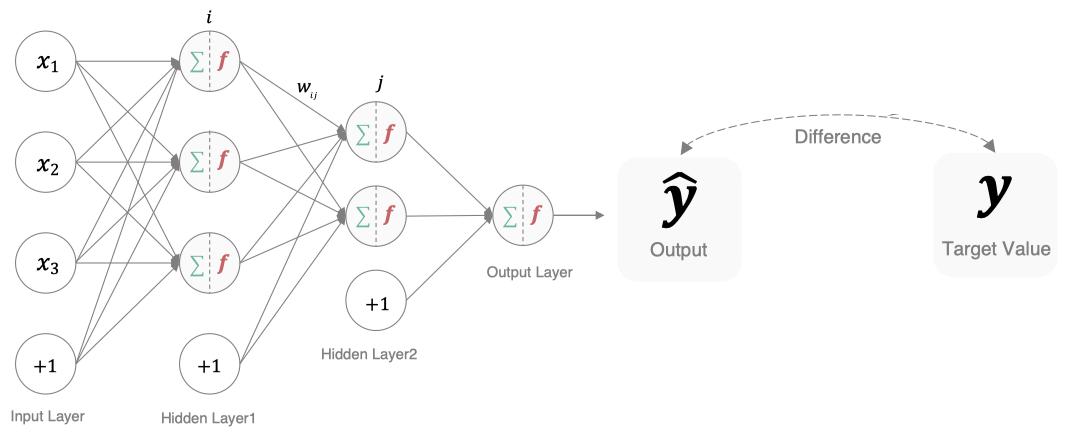
深度学习神经网络就是大脑仿生,数据从输入到输出经过一层一层的神经元产生预测值的过程就是前向传播(也叫正向传播)。
前向传播涉及到人工神经元是如何工作的(也就是神经元的初始化、激活函数),神经网络如何搭建,权重参数计算、数据形状如何变化。千里之行始于足下,我们一起进入深度学习的知识海洋吧。
神经网络概念
什么是神经网络
人工神经网络(Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型。它由多个互相连接的人工神经元(也称为节点)构成,可以用于处理和学习复杂的数据模式,尤其适合解决非线性问题。人工神经网络是机器学习中的一个重要模型,尤其在深度学习领域中得到了广泛应用。
人脑可以看做是一个生物神经网络,由众多的神经元连接而成。各个神经元传递复杂的电信号,树突接收到输入信号,然后对信号进行处理,通过轴突输出信号。下图是生物神经元示意图:
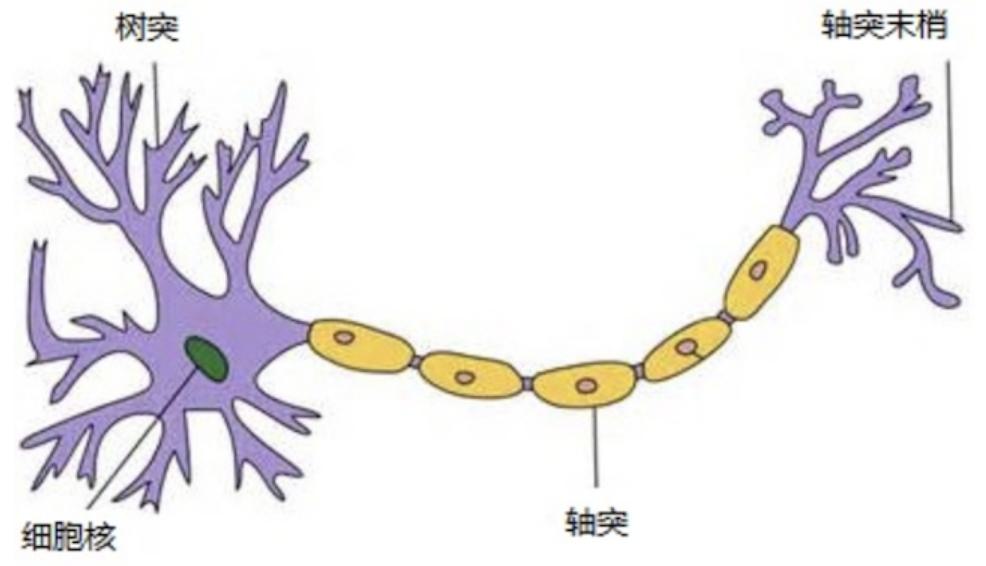
当电信号通过树突进入到细胞核时,会逐渐聚集电荷。达到一定的电位后,细胞就会被激活,通过轴突发出电信号。
如何构建神经网络
神经网络是由多个神经元组成,构建神经网络就是在构建神经元。以下是神经网络中神经元的构建说明:
下面整个图只表示一个神经元
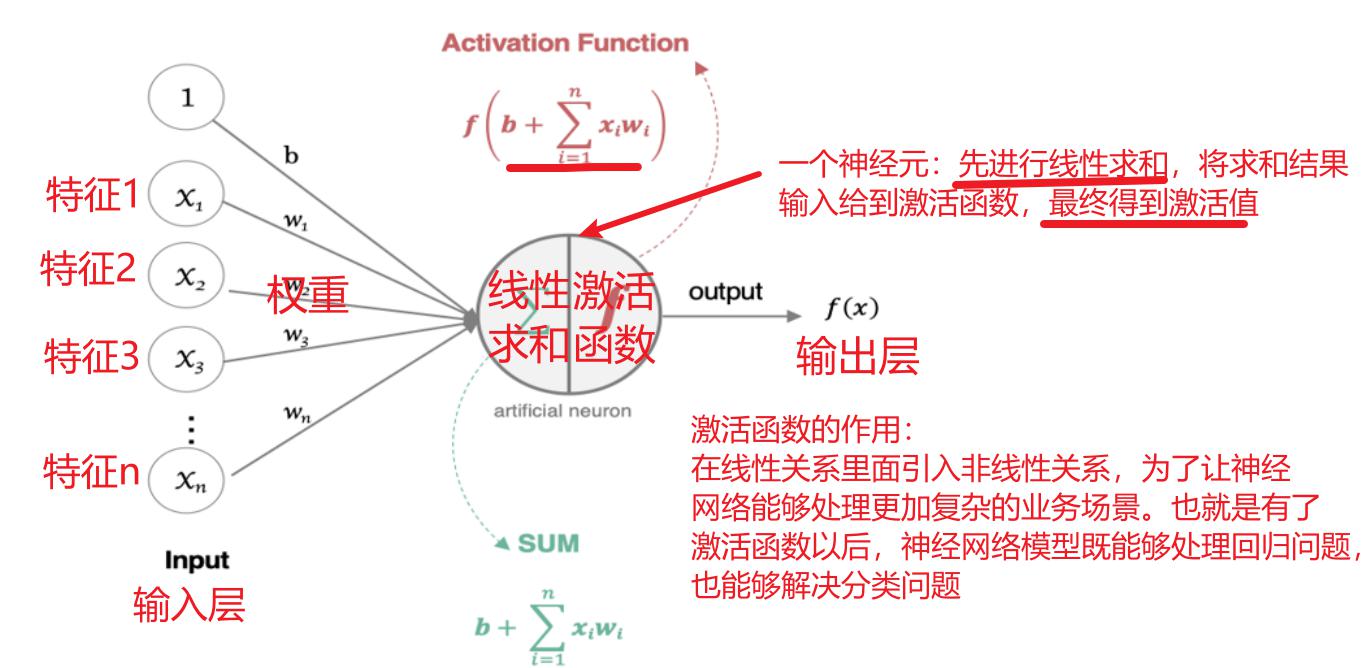
这个流程就像,来源不同树突(树突都会有不同的权重)的信息, 进行的加权计算, 输入到细胞中做加和,再通过激活函数输出细胞值。
同一层的多个神经元可以看作是通过并行计算来处理相同的输入数据,学习输入数据的不同特征。每个神经元可能会关注输入数据中的不同部分,从而捕捉到数据的不同属性。
接下来,我们使用多个神经元来构建神经网络,相邻层之间的神经元相互连接,并给每一个连接分配一个强度,如下图所示:
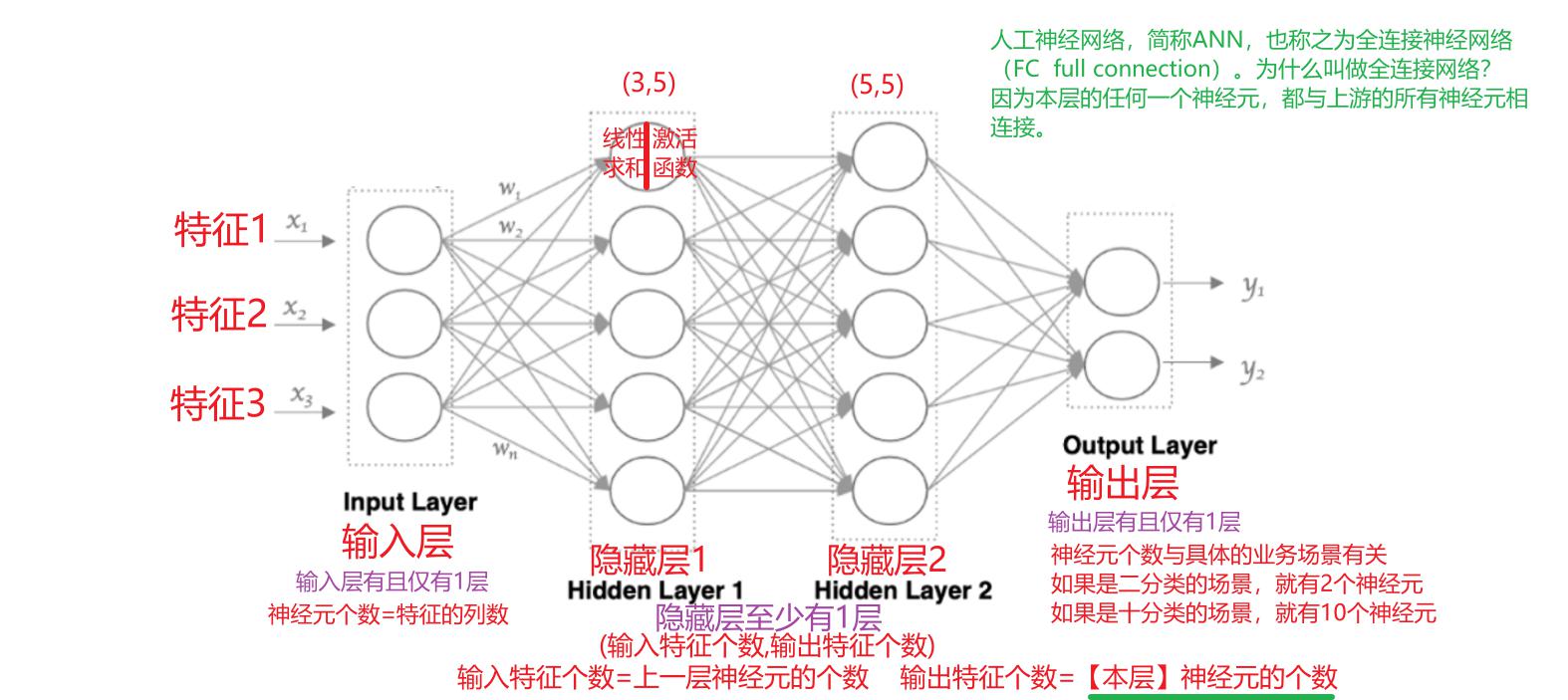
神经网络中信息只向一个方向移动,即从输入节点向前移动,通过隐藏节点,再向输出节点移动。其中的基本部分是:
- 输入层(Input Layer): 即输入x的那一层(如图像、文本、声音等)。每个输入特征对应一个神经元。输入层将数据传递给下一层的神经元。
- 输出层(Output Layer): 即输出y的那一层。输出层的神经元根据网络的任务(回归、分类等)生成最终的预测结果。
- 隐藏层(Hidden Layers): 输入层和输出层之间都是隐藏层,神经网络的“深度”通常由隐藏层的数量决定。隐藏层的神经元通过加权和激活函数处理输入,并将结果传递到下一层。
特点是:
- 同一层的神经元之间没有连接
- 第N层的每个神经元和第N-1层的所有神经元相连(这就是Fully Connected的含义),这就是全连接神经网络(FCNN)
- 全连接神经网络接收的样本数据是二维的,数据在每一层之间需要以二维的形式传递
- 第N-1层神经元的输出就是第N层神经元的输入
- 每个连接都有一个权重值(w系数和b系数)
神经网络内部状态值和激活值
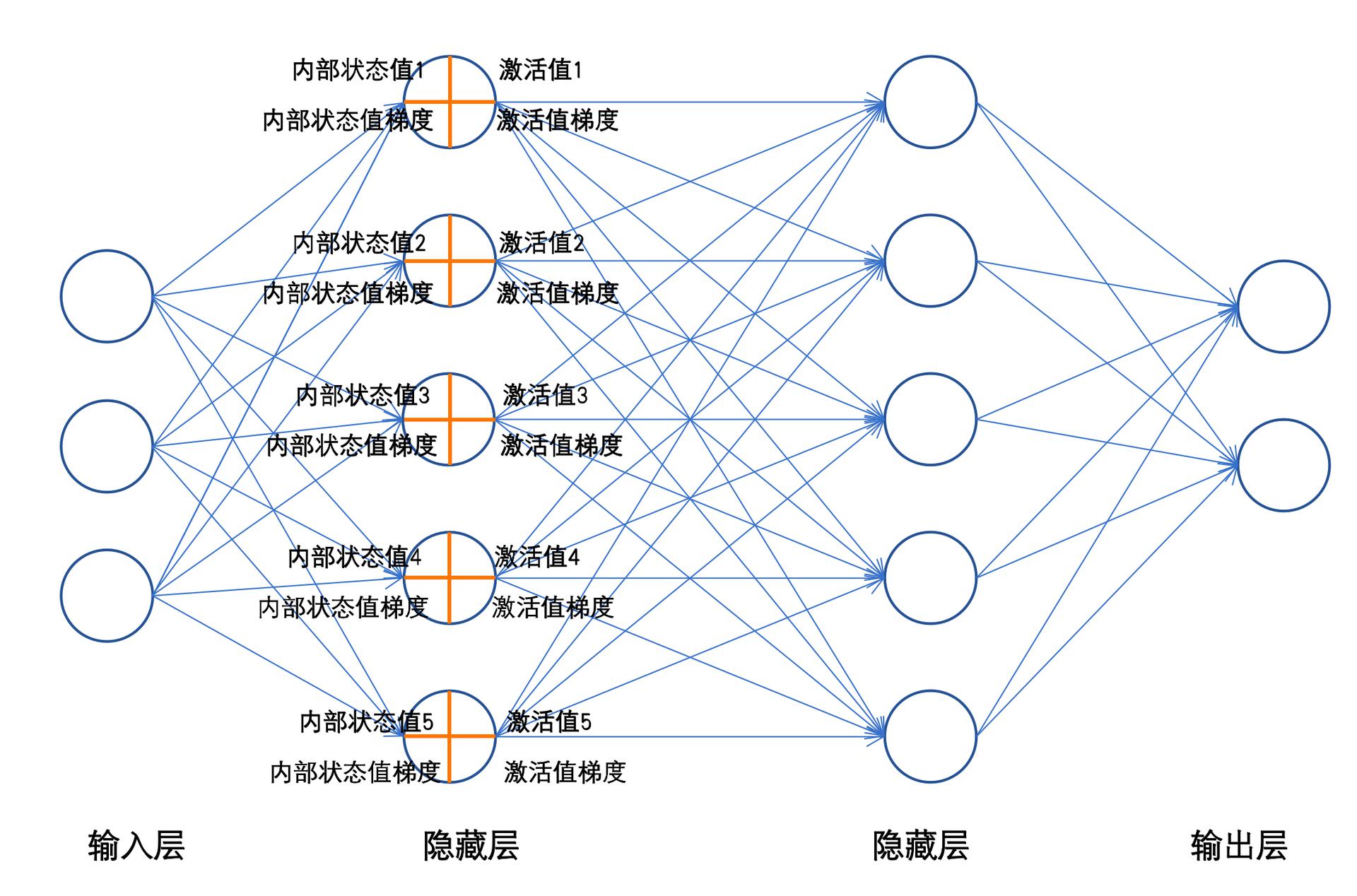
每一个神经元工作时,前向传播会产生两个值,内部状态值(加权求和值)和激活值;反向传播时会产生激活值梯度和内部状态值梯度。
内部状态值
- 神经元或隐藏单元的内部存储值,它反映了当前神经元接收到的输入、历史信息以及网络内部的权重计算结果。
- 每个输入$$x_i$$都有一个与之相乘的权重$$w_i$$,表示每个输入信号的重要性。
- z=w⋅x+b
- w:权重矩阵
- x:输入值
- b:偏置
激活值
- 通过激活函数(如 ReLU、Sigmoid、Tanh)对内部状态值进行非线性变换后得到的结果。激活值决定了当前神经元的输出。
- a=f(z)
- f:激活函数
- z:内部状态值
通过控制每个神经元的内部状态值、激活值的大小;每一层的内部状态值的方差、每一层的激活值的方差可让整个神经网络工作的更好。
所以下面两个小结,我们将要学习神经元的激活函数,神经元的权重初始化。
激活函数
网络非线性因素理解
没有引入非线性因素的网络等价于使用一个线性模型来拟合
通过给网络输出增加激活函数, 实现引入非线性因素, 使得网络模型可以逼近任意函数, 提升网络对复杂问题的拟合能力
激活函数用于对每层的输出数据进行变换, 进而为整个网络注入了非线性因素。此时, 神经网络就可以拟合各种曲线。如果不使用激活函数,整个网络虽然看起来复杂,其本质还相当于一种线性模型,如下公式所示:
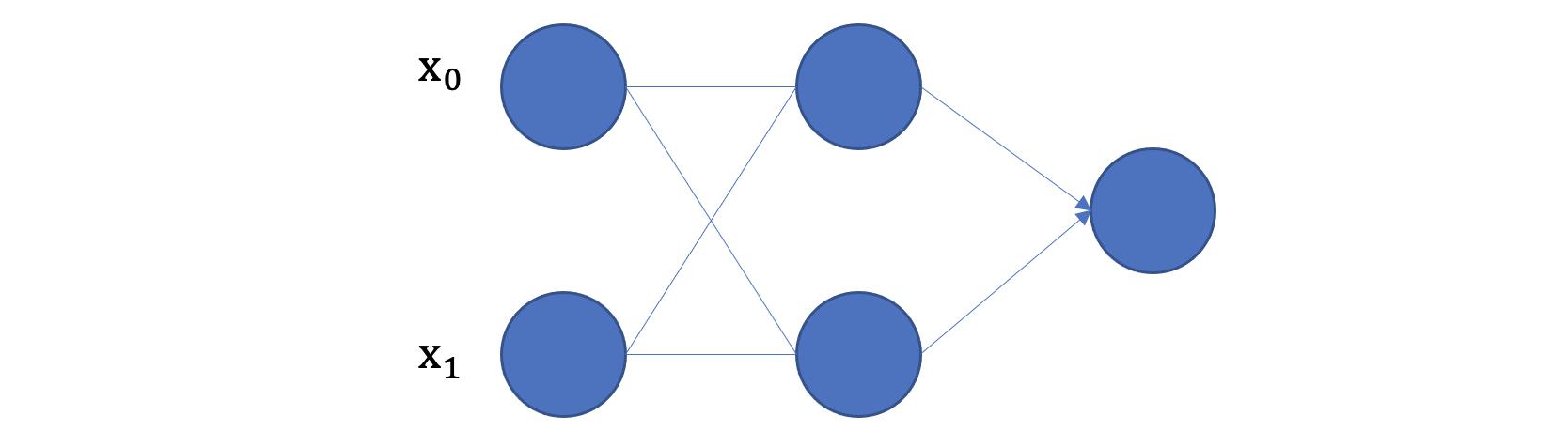
另外通过图像可视化的形式理解:
我们发现增加激活函数之后, 对于线性不可分的场景,神经网络的拟合能力更强。
常见激活函数
激活函数主要用来向神经网络中加入非线性因素,以解决线性模型表达能力不足的问题,它对神经网络有着极其重要的作用。我们的网络参数在更新时,使用的反向传播算法(BP),这就要求我们的激活函数必须可微。
Sigmoid 激活函数
激活函数公式:
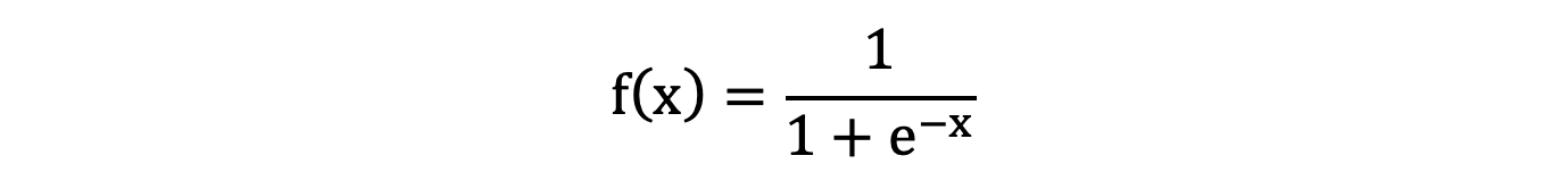
激活函数求导公式:
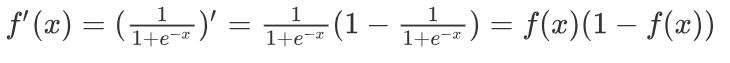
sigmoid 激活函数的函数图像如下:
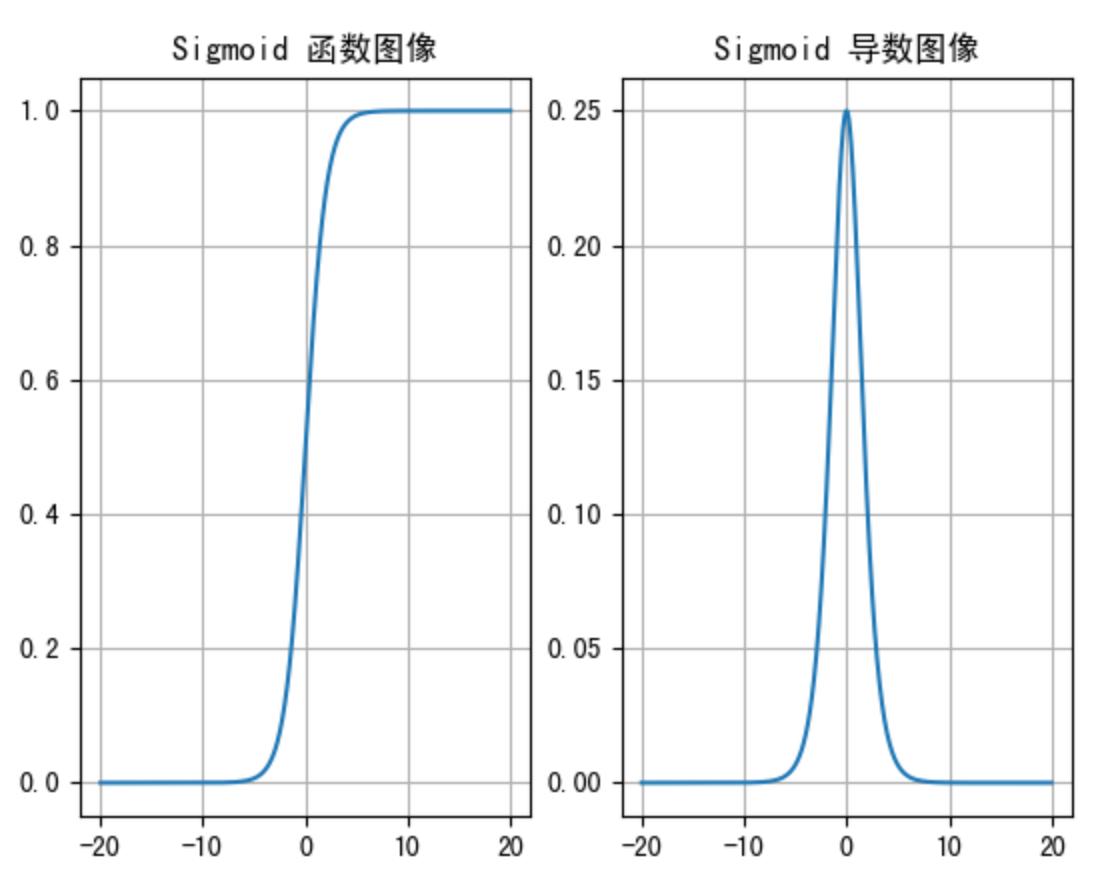
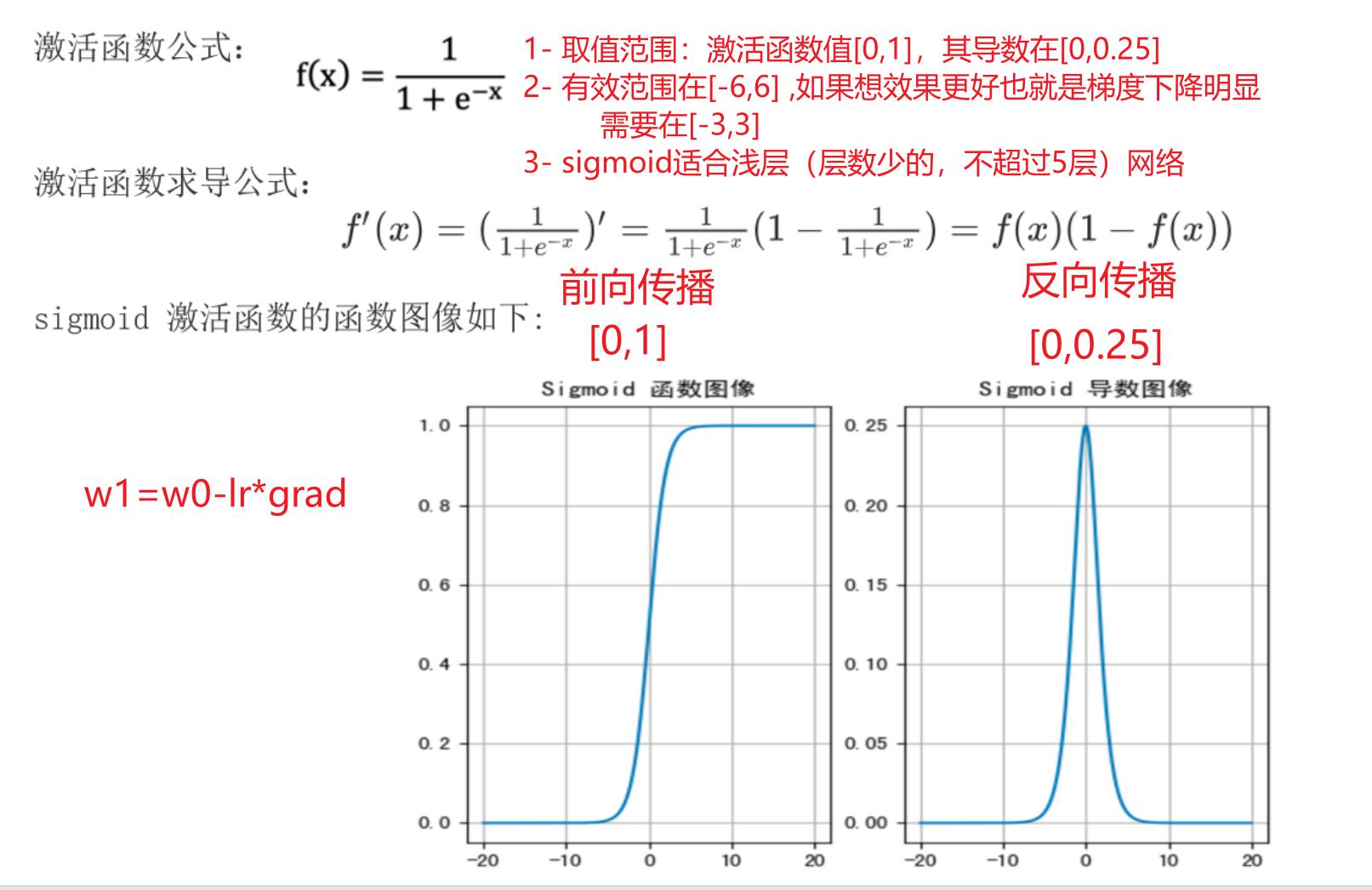
1- sigmoid激活函数本身取值范围[0,1],导数的取值范围[0,0.25]
2- 输入值在[-6,6]之间的时候,效果才会比较明显。将范围缩小到[-3,3]效果更好
3- sigmoid激活函数适合在神经网络层数5层以内,推荐使用输出层,当你是二分类业务问题的时候
- 从sigmoid函数图像可以得到,sigmoid 函数可以将任意的输入映射到 (0, 1) 之间,当输入的值大致在**<-6或者>6**时,意味着输入任何值得到的激活值都是差不多的,这样会丢失部分的信息。比如:输入100和输入10000经过 sigmoid的激活值几乎都是等于1的,但是输入的数据之间相差100倍的信息就丢失了。
- 对于sigmoid函数而言,输入值在**[-6, 6]之间输出值才会有明显差异,输入值在[-3, 3]之间才会有比较好的效果**
- 通过上述导数图像,我们发现导数数值范围是 (0, 0.25),当输入的值<-6或者>6时,sigmoid激活函数图像的导数接近为 0,此时网络参数将更新极其缓慢,或者无法更新。
- 一般来说,sigmoid网络在5层之内就会产生梯度消失现象。而且,该激活函数的激活值并不是以0为中心的,激活值总是偏向正数,导致梯度更新时,只会对某些特征产生相同方向的影响,所以在实践中这种激活函数使用的很少。sigmoid函数一般只用于二分类的输出层。
在 PyTorch中使用sigmoid函数的示例代码如下:
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
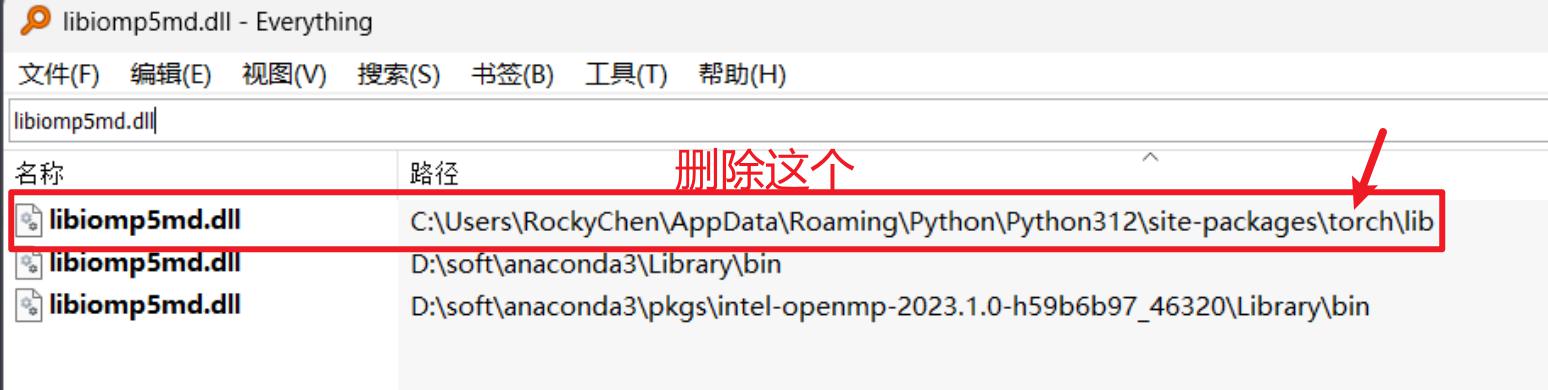
"""
OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
原因:torch和matplotlib工具中都有libiomp5md.dll,只能保留一个
解决:删除torch下的libiomp5md.dll
"""
def sigmoid_demo():
fig,axes = plt.subplots(1,2)
# sigmoid原始函数的图像
x = torch.linspace(start=-20,end=20,steps=1000)
y = torch.sigmoid(x) # 掌握本行代码即可
axes[0].plot(x,y)
axes[0].grid()
axes[0].set_title("sigmoid原始函数的图像")
# sigmoid导数函数的图像
x = torch.linspace(start=-20, end=20, steps=1000, requires_grad=True)
torch.sigmoid(x).sum().backward()
axes[1].plot(x.data, x.grad)
axes[1].grid()
axes[1].set_title("sigmoid导数函数的图像")
plt.show()
if __name__ == '__main__':
# sigmoid激活函数
sigmoid_demo()
Tanh 激活函数
1- Tanh函数本身的取值范围[-1,1],其导数[0,1]
2- 在[-3,3]梯度下降效果较好,在[-1,1]效果更加显著
3- Tanh适合用在隐藏层中
Tanh叫做双曲正切函数,其公式如下:
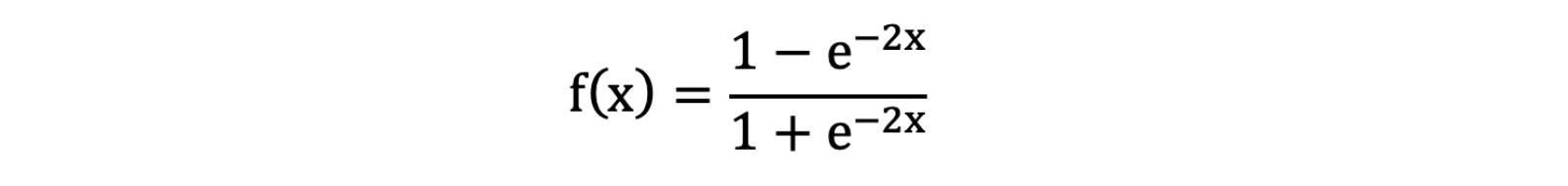
激活函数求导公式:
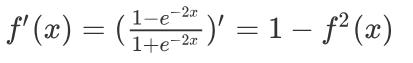
Tanh的函数图像、导数图像如下:
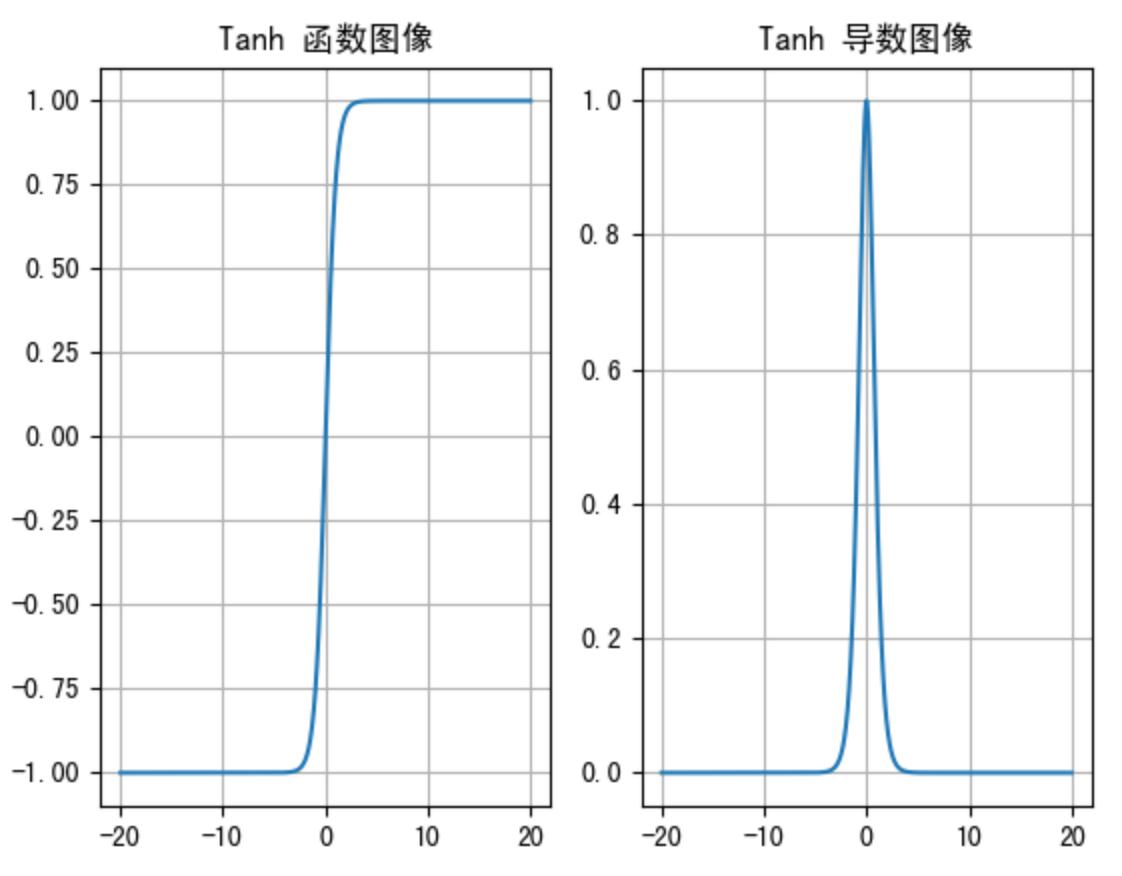
由上面的函数图像可以看到,Tanh函数将输入映射到(-1, 1)之间,图像以0为中心,激活值在0点对称,当输入的值大概**<-3或者>3** 时将被映射为-1或者1。其导数值范围 (0, 1),当输入的值大概<-3或者>3时,其导数近似0。
与Sigmoid相比,它是以0为中心的,使得其收敛速度要比Sigmoid快,减少迭代次数。然而,从图中可以看出,Tanh两侧的导数也为0,同样会造成梯度消失。
若使用时可在隐藏层使用tanh函数,在输出层使用sigmoid函数。
在 PyTorch 中使用tanh函数的示例代码如下:
# 导包
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 遇到的问题: OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
# 解决方案:
# 第一种:去 你的Anaconda软件安装路径下的 anaconda3\Lib\site-packages\torch\lib 删除 libiomp5md.dll 这个文件.
# 第二种:import os os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# 例如: 我的路径是 C:\Software\DevelopSofware\anaconda3\Lib\site-packages\torch\lib
# 需求1: 绘制Tanh函数图像
# 1. 创建1个 1行2列的画布.
fig, axes = plt.subplots(1, 2)
# 2. 准备x轴的值 -> [-20, 20]的等差数列, 1000个元素.
x = torch.linspace(-20, 20, 1000)
# 3. 计算Tanh函数的值
y = torch.tanh(x)
# 4. 绘制折线图.
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title('Tanh 函数图像')
# plt.show()
# 需求2: 绘制Tanh函数的导数图像.
# 1. 准备x轴的值 -> [-20, 20]的等差数列, 1000个元素.
x = torch.linspace(-20, 20, 1000, requires_grad=True)
# 2. 计算Tanh函数的导数
torch.tanh(x).sum().backward() # 表示 标量张量 才能求导.
# 3. 绘制折线图
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title('Tanh 函数导数图像')
plt.show()
ReLU 激活函数
ReLU 激活函数公式如下:
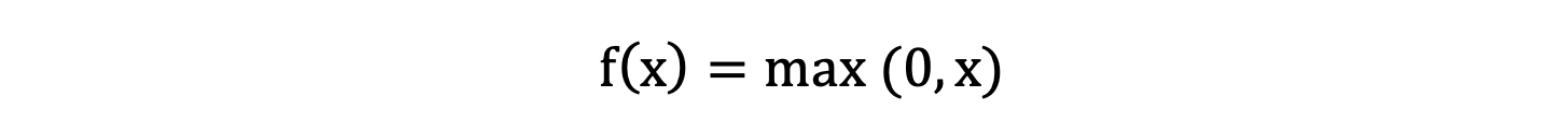
激活函数求导公式:
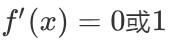
ReLU 的函数图像、导数图像如下:
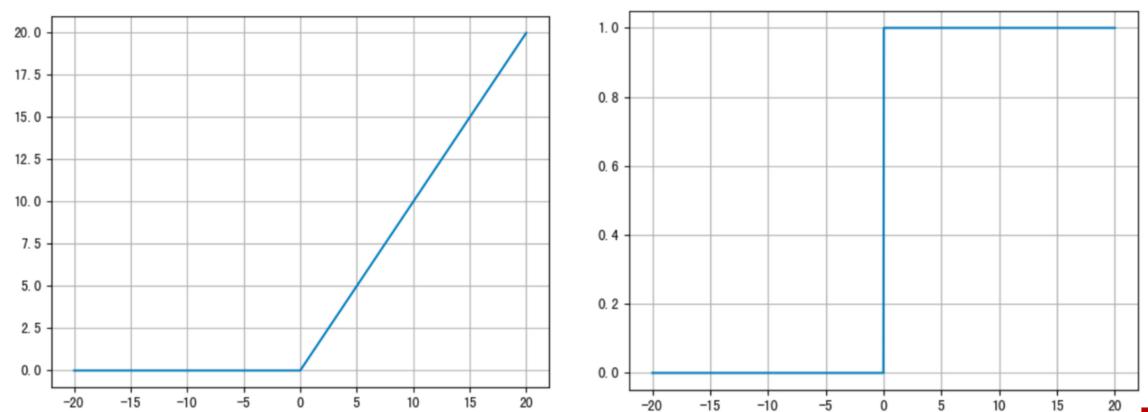
- ReLU 激活函数将小于0的值映射为0,而大于0的值则保持不变,它更加重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率。
- 当x<0时,ReLU导数为0,而当x>0时,则不存在饱和问题。所以,ReLU 能够在x>0时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入小于0区域,导致对应权重无法更新。这种现象被称为“神经元死亡”。
- ReLU是目前最常用的激活函数。与sigmoid相比,RELU的优势是:
- 采用sigmoid函数,计算量大(指数运算),反向传播求误差梯度时,计算量相对大;而采用Relu激活函数,整个过程的计算量节省很多
- sigmoid函数反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练;而采用relu激活函数,当输入的值>0时,梯度为1,不会出现梯度消失的情况
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
在 PyTorch 中使用ReLU函数的示例代码如下:
# 导包
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 遇到的问题: OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
# 解决方案: 去 你的Anaconda软件安装路径下的 anaconda3\Lib\site-packages\torch\lib 删除 libiomp5md.dll 这个文件.
# 例如: 我的路径是 C:\Software\DevelopSofware\anaconda3\Lib\site-packages\torch\lib
# 需求1: 绘制Relu函数图像
# 1. 创建1个 1行2列的画布.
fig, axes = plt.subplots(1, 2)
# 2. 准备x轴的值 -> [-20, 20]的等差数列, 1000个元素.
x = torch.linspace(-20, 20, 1000)
# 3. 计算Relu函数的值
y = torch.relu(x)
# 4. 绘制折线图.
axes[0].plot(x, y)
axes[0].grid()
axes[0].set_title('Relu 函数图像')
# plt.show()
# 需求2: 绘制Relu函数的导数图像.
# 1. 准备x轴的值 -> [-20, 20]的等差数列, 1000个元素.
x = torch.linspace(-20, 20, 1000, requires_grad=True)
# 2. 计算Relu函数的导数
torch.relu(x).sum().backward() # 表示 标量张量 才能求导.
# 3. 绘制折线图
axes[1].plot(x.detach(), x.grad)
axes[1].grid()
axes[1].set_title('Relu 函数导数图像')
plt.show()
SoftMax激活函数
softmax用于多分类过程中,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
计算方法如下图所示:
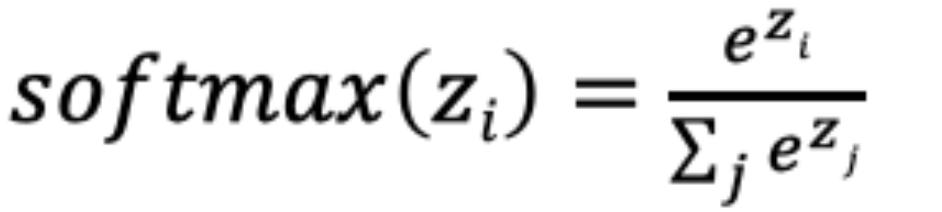
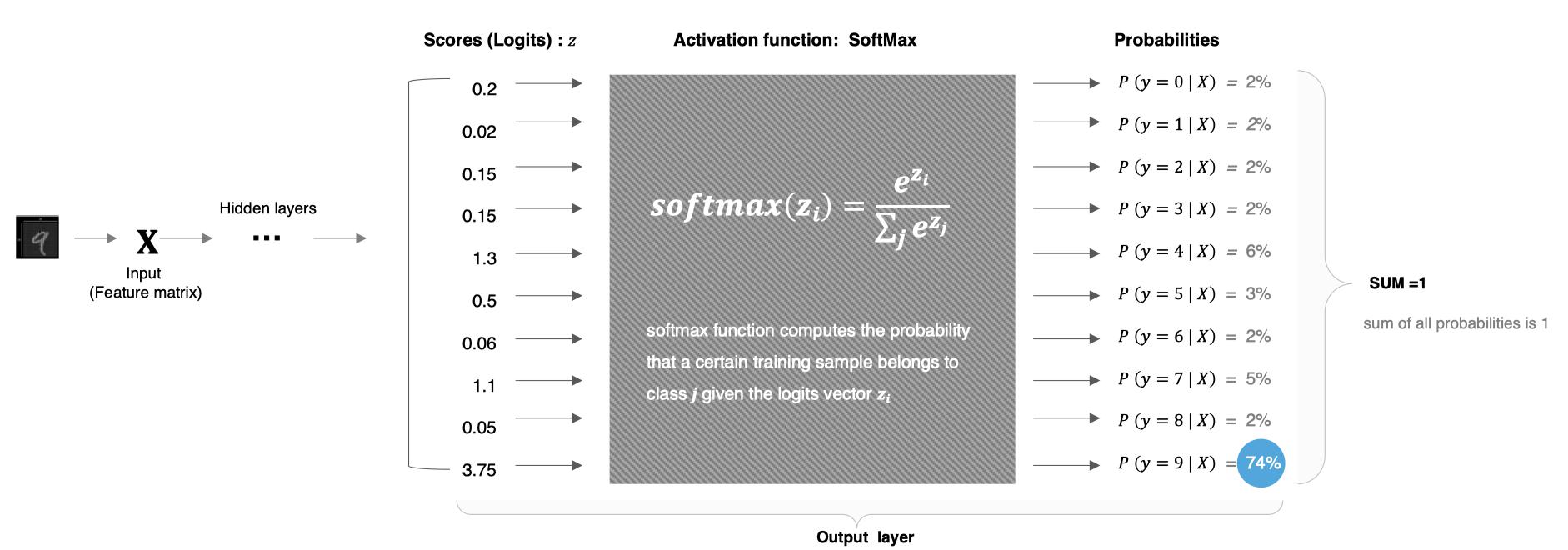
SoftMax就是将网络输出的logits通过softmax函数,映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们将它理解成概率,选取概率最大(也就是值对应最大的)节点,作为我们的预测目标类别。
在 PyTorch 中使用SoftMax函数的示例代码如下:
import torch
def softmax_demo():
# 一条样本
# score = torch.tensor(data=[0.2, 0.02, 0.15, 0.15, 1.3, 0.5, 0.06, 1.1, 0.05, 3.75])
# 多条样本
score = torch.tensor(data=[[0.3, 0.24, 5, -3.1], [-0.1, 0.56, 2.4, 0.35]])
# 将线性求和结果通过softmax转成概率
prob = torch.softmax(score,dim=-1)
print(prob)
print(prob.sum())
如何选择激活函数【重点】
除了上述的激活函数,还存在很多其他的激活函数,如下图所示:
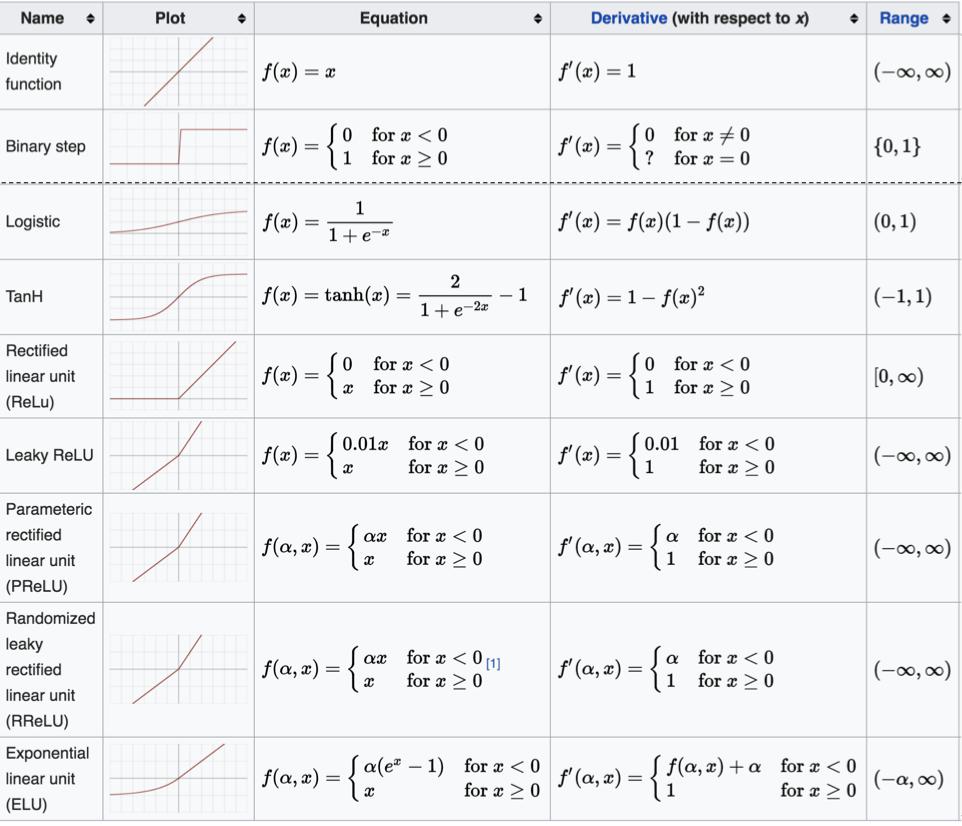
对于隐藏层:
- 优先选择ReLU激活函数
- 如果ReLu效果不好,那么尝试其他激活,如Leaky ReLu等。
- 如果你使用了ReLU, 需要注意一下Dead ReLU问题,避免出现0梯度从而导致过多的神经元死亡。
- 少使用sigmoid激活函数,可以尝试使用tanh激活函数
对于输出层:
- 二分类问题选择sigmoid激活函数。也可以使用softmax激活函数
- 多分类问题选择softmax激活函数
- 回归问题选择identity激活函数
激活函数总结:
1- Sigmoid激活函数
1.1- 既考虑正半轴,也考虑负半轴
1.2- 原始函数的取值区间是[0,1]之间;导数的取值区间是[0,0.25]之间
1.3- 【重点】可以在隐藏层中使用Sigmoid激活函数,但是 隐藏层的层数<=5层。更多推荐是在二分类的场景下使用在输出层中。
2- Tanh激活函数
2.1- 既考虑正半轴,也考虑负半轴
2.2- 原始函数的取值区间是[-1,1]之间;导数的取值区间是[0,1]之间
2.3- 【重点】大多数情况下,Tanh激活函数使用在隐藏层中,但是 隐藏层的层数<=10层。
3- Relu激活函数
3.1- 只考虑正半轴,不考虑负半轴
3.2- 负半轴的导数值为0;正半轴的导数值为1
3.3- 【重点】绝大多数情况下无脑的在隐藏层中使用Relu激活函数
4- Softmax激活函数
4.1- 将线性求和结果输入到函数中,计算得到各个类别的概率值。概率值求和结果是1。
4.2- 【重点】多分类使用Softmax。更多情况下是不管你是几分类问题,基本都使用Sofmax激活函数。
总结:
1- 隐藏层:绝大多数情况下无脑的在隐藏层中使用Relu激活函数;如果Relu的效果一般,可以考虑使用Relu的变体,例如Leakly Relu
2- 输出层:二分类可以使用Sigmoid;多分类使用Softmax。更多情况下是不管你是几分类问题,基本都使用Sofmax激活函数。
3- 输入层:没有线性求和、也没有激活函数
参数初始化
我们在构建网络之后,网络中的参数是需要初始化的。我们需要初始化的参数主要有权重和偏置,偏置一般初始化为0即可,而对权重的初始化则会更加重要。
参数初始化的作用:
- 防止梯度消失或爆炸:初始权重值过大或过小会导致梯度在反向传播中指数级增大或缩小。
- 提高收敛速度:合理的初始化使得网络的激活值分布适中,有助于梯度高效更新。
- 保持对称性破除:权重的初始化需要打破对称性,否则网络的学习能力会受到限制。
常见参数初始化方法
随机初始化
均匀分布初始化:权重参数初始化从区间均匀随机取值,默认区间为(0,1)。可以设置为在(-$$1\over\sqrt{d}$$,$$1\over\sqrt{d}$$)均匀分布中生成当前神经元的权重,其中d为神经元的输入数量。
正态分布初始化:随机初始化从均值为0,标准差是1的高斯分布中取样,使用一些很小的值对参数W进行初始化
优点:能有效打破对称性
缺点:随机选择范围不当可能导致梯度问题
适用场景:浅层网络或低复杂度模型。隐藏层1-3层,总层数不超过5层。
全0初始化:将神经网络中的所有权重参数初始化为0
- 优点:实现简单
- 缺点:无法打破对称性,所有神经元更新方向相同,无法有效训练
- 适用场景:几乎不使用,仅用于b偏置项的初始化
全1初始化:将神经网络中的所有权重参数初始化为1
- 优点:实现简单
- 缺点
- 无法打破对称性,所有神经元更新方向相同,无法有效训练
- 会导致激活值在网络中呈指数增长,容易出现梯度爆炸
- 适用场景
- 测试或调试:比如验证神经网络是否能正常前向传播和反向传播
- 特殊模型结构:某些稀疏网络或特定的自定义网络中可能需要手动设置部分参数为1
- 偏置初始化:偶尔可以将偏置初始化为小的正值(如 0.1),但很少用1作为偏置的初始值
固定值初始化:将神经网络中的所有权重参数初始化为某个固定值
- 优点:实现简单
- 缺点
- 无法打破对称性,所有神经元更新方向相同,无法有效训练
- 初始权重过大或过小可能导致梯度爆炸或梯度消失
- 适用场景
- 测试或调试
kaiming初始化,也叫做HE初始化:专为ReLU和其变体设计,考虑到ReLU激活函数的特性,对输入维度进行缩放
- HE初始化分为正态分布的HE初始化、均匀分布的HE初始化
- 正态分布的he初始化
- w权重值从均值为0, 标准差为std中随机采样,std =
sqrt(2 / fan_in) - std值越大,w权重值离均值0分布相对较广,计算得到的内部状态值有较大的正值或负值
- w权重值从均值为0, 标准差为std中随机采样,std =
- 均匀分布的he初始化
- 它从[-limit,limit] 中的均匀分布中抽取样本,
limit是sqrt(6 / fan_in)
- 它从[-limit,limit] 中的均匀分布中抽取样本,
fan_in输入神经元的个数,当前层接受的来自上一层的神经元的数量。简单来说,就是当前层接收多少个输入
- 正态分布的he初始化
- 优点:适合 ReLU,能保持梯度稳定
- 缺点:对非 ReLU 激活函数效果一般
- 适用场景:深度网络(10层及以上),使用 ReLU、Leaky ReLU 激活函数
- HE初始化分为正态分布的HE初始化、均匀分布的HE初始化
xavier初始化,也叫做Glorot初始化:根据网络输入和输出的维度自动选择权重范围,使输入和输出的方差相同
xavier初始化分为正态分布的xavier初始化、均匀分布的xavier初始化
- 正态化的Xavier初始化
- w权重值从均值为0, 标准差为std中随机采样,std =
sqrt(2 / (fan_in + fan_out)) - std值越小,w权重值离均值0分布相对集中,计算得到的内部状态值有较小的正值或负值
- w权重值从均值为0, 标准差为std中随机采样,std =
- 均匀分布的Xavier初始化
- [-limit,limit] 中的均匀分布中抽取样本, limit 是
sqrt(6 / (fan_in + fan_out))
- [-limit,limit] 中的均匀分布中抽取样本, limit 是
- fan_in 是输入神经元个数,当前层接受的来自上一层的神经元的数量。简单来说,就是当前层接收多少个输入
- fan_out 是输出神经元个数,当前层输出的神经元的数量,也就是当前层会传递给下一层的神经元的数量。简单来说,就是当前层会产生多少个输出。
- 正态化的Xavier初始化
优点:适用于Sigmoid、Tanh 等激活函数,解决梯度消失问题
缺点:对 ReLU 等激活函数表现欠佳
适用场景:深度网络(10层及以上),使用 Sigmoid 或 Tanh 激活函数
import torch.nn as nn
# 1. 均匀分布随机初始化
def test01():
linear = nn.Linear(5, 3)
# 从0-1均匀分布产生参数
nn.init.uniform_(linear.weight)
nn.init.uniform_(linear.bias)
print(linear.weight.data)
# 2. 固定初始化
def test02():
linear = nn.Linear(5, 3)
nn.init.constant_(linear.weight, 5)
print(linear.weight.data)
# 3. 全0初始化
def test03():
linear = nn.Linear(5, 3)
nn.init.zeros_(linear.weight)
print(linear.weight.data)
# 4. 全1初始化
def test04():
linear = nn.Linear(5, 3)
nn.init.ones_(linear.weight)
print(linear.weight.data)
# 5. 正态分布随机初始化
def test05():
linear = nn.Linear(5, 3)
nn.init.normal_(linear.weight, mean=0, std=1)
print(linear.weight.data)
# 6. kaiming 初始化
def test06():
# kaiming 正态分布初始化
linear = nn.Linear(5, 3)
nn.init.kaiming_normal_(linear.weight, nonlinearity='relu')
print(linear.weight.data)
# kaiming 均匀分布初始化
linear = nn.Linear(5, 3)
nn.init.kaiming_uniform_(linear.weight, nonlinearity='relu')
print(linear.weight.data)
# 7. xavier 初始化
def test07():
# xavier 正态分布初始化
linear = nn.Linear(5, 3)
nn.init.xavier_normal_(linear.weight)
print(linear.weight.data)
# xavier 均匀分布初始化
linear = nn.Linear(5, 3)
nn.init.xavier_uniform_(linear.weight)
print(linear.weight.data)
如何选择参数初始化【重点】
参数初始化总结【重点记忆】:
1- 偏置b:大多数情况下使用全0初始化。kaiming初始化、xavier初始化不能用来对b进行初始化
2- 权重w:大多数情况下使用kaiming初始化,也可以使用xavier初始化。
激活函数:
Relu或者Relu的变体:推荐使用kaiming初始化
Sigmoid、Tanh:大多数的初始化都可以。但是,还是推荐后期出来的kaiming初始化、xavier初始化
网络层数(浅层网络,也就是网络层数<=5层):
浅层网络:大多数的初始化都可以。但是,还是推荐后期出来的kaiming初始化、xavier初始化
深层网络:使用kaiming初始化、xavier初始化
神经网络搭建和参数计算【重点】
构建神经网络
在pytorch中定义深度神经网络其实就是层堆叠的过程,继承自nn.Module,实现两个方法:
__init__方法中定义网络中的层结构,主要是全连接层,并进行初始化- forward方法,在调用神经网络模型对象的时候,底层会自动调用该函数。该函数中为初始化定义的layer传入数据,进行前向传播等。
接下来我们来构建如下图所示的神经网络模型:
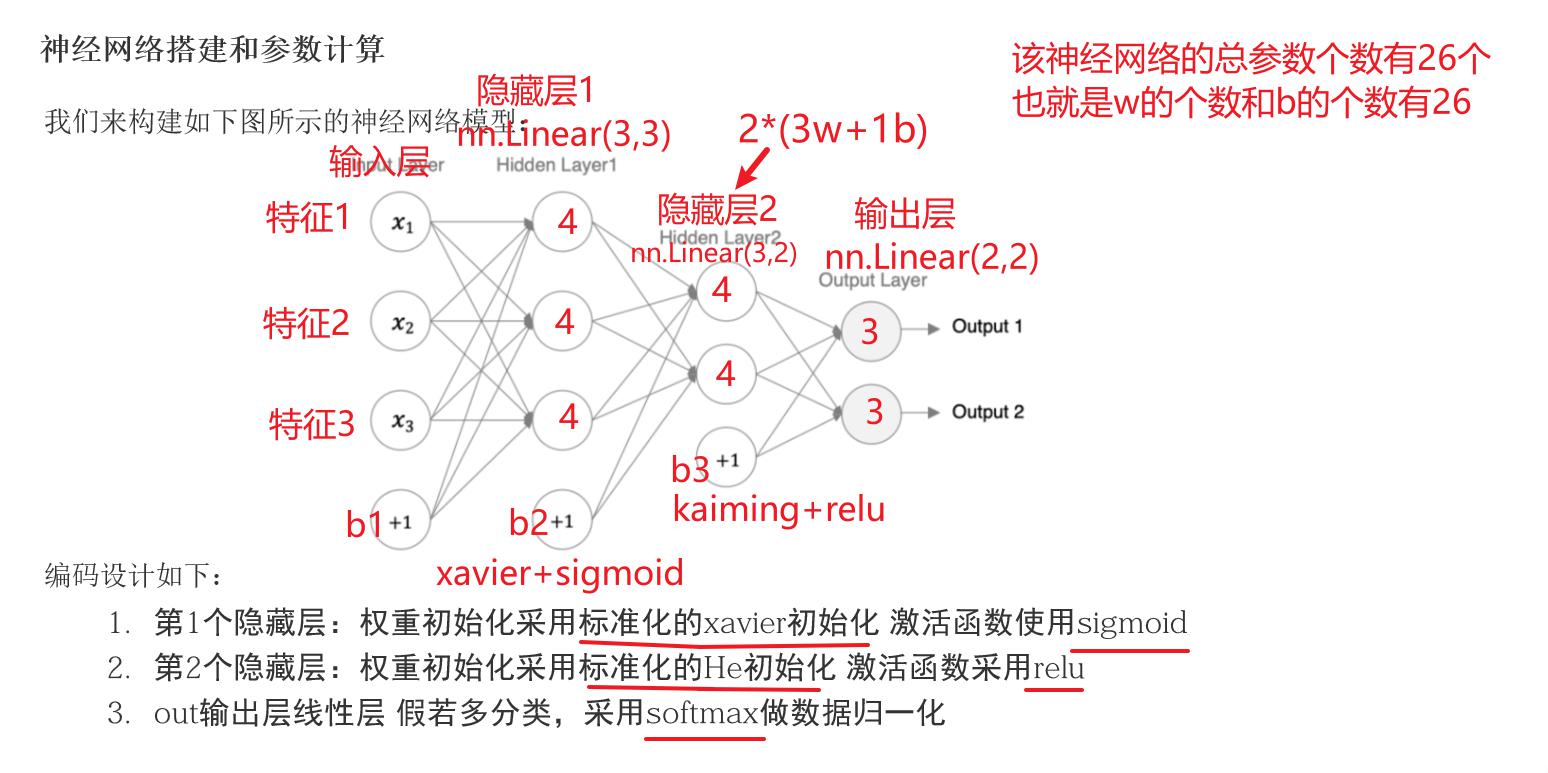
编码设计如下:
- 第1个隐藏层:权重初始化采用标准化的xavier初始化 激活函数使用sigmoid
- 第2个隐藏层:权重初始化采用标准化的He初始化 激活函数采用relu
- out输出层线性层 假若多分类,采用softmax做数据归一化
"""
自定义网络结构的代码开发流程:
1- 定义一个类,类继承自torch.nn.Module父类
注意:Module名称不要写错
2- 实现__init__魔法方法,负责进行初始化的工作。负责的内容有如下这些:
2.1- 初始化父类
2.2- 搭建网络结构:隐藏层、输出层
2.3- 【可选】各个层的参数初始化
3- 实现forward前向传播方法,输入训练集的特征数据,对模型进行训练,并且得到预测结果。注意,forward单词不要写错
输入的特征数据依次按顺序经过各个隐藏层,最终达到输出层
"""
import torch
import torch.nn as nn
# pip install torchsummary==1.5.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
from torchsummary import summary # 用来查看模型的参数信息
class MyModel(nn.Module):
def __init__(self):
# 1- 初始化父类
super().__init__()
# 2- 搭建网络结构
# 2.1- 第一层隐藏层
self.hidden1 = nn.Linear(in_features=3,out_features=3)
# 2.2- 第二层隐藏层
self.hidden2 = nn.Linear(in_features=3,out_features=2)
# 2.3- 输出层
self.out = nn.Linear(in_features=2,out_features=2)
# 3- 参数初始化
# 3.1- 第一层隐藏层
nn.init.xavier_normal_(self.hidden1.weight)
nn.init.zeros_(self.hidden1.bias)
# 3.2- 第二层隐藏层
nn.init.kaiming_normal_(self.hidden2.weight)
nn.init.zeros_(self.hidden2.bias)
def forward(self,x):
"""
前向传播。使用特征数据对模型进行训练,并且得到预测值
:param x: 训练集中的特征数据
:return:
"""
# 1- 调用第一层隐藏层
# 写法一:分开版
# 先线性求和
# x = self.hidden1(x)
# 再将线性求和结果作为输入,给到激活函数,得到激活值
# x = torch.sigmoid(x)
# 写法二:合并版。【推荐】
x = torch.sigmoid(self.hidden1(x))
# 2- 调用第二层隐藏层
x = torch.relu(self.hidden2(x))
# 3- 调用输出层:dim=-1表示以最里层的列表为单位计算概率分布,也就是以每条样本为单位进行计算
output = torch.softmax(self.out(x), dim=-1)
# 4- 返回结果
return output
def train_model():
# 1- 准备样本数据
# 造了5条样本,3列特征
x = torch.randn(size=(5,3))
print(f"输入的样本数据:{x}")
print(f"输入的样本数据形状:{x.shape}")
# 2- 创建算法模型实例对象
model = MyModel()
# 3- 调用模型,底层会自动调用forward前向传播方法,对模型进行训练,得到预测结果
pred_output = model(x)
print(f"预测结果内容:{pred_output}")
print(f"预测结果形状:{pred_output.shape}")
# 4- 查看模型的参数个数信息
"""
参数解释:
model:要查看哪个模型的参数信息
input_size:数据结构要求是元祖。第一个值表示特征的列数
"""
summary(model,input_size=(3,))
print("-"*30)
# 5- 查看模型中权重w和偏置b的初始值
for name,param in model.named_parameters():
print(f"{name}---->{param}")
if __name__ == '__main__':
train_model()
观察数据形状变化
观察程序输入和输出的数据形状变化
- 输入5行数据,输出也是5行数据
- 输入5行数据3个特征,经过第一个隐藏层是3个特征,经过第二个隐藏层是2个特征,经过输出层是2个特征
- 模型最终预测结果是:5行2列数据
mydata.shape---> torch.Size([5, 3]) output.shape---> torch.Size([5, 2]) mydata---> tensor([[-0.3714, -0.8578, -1.6988], [ 0.3149, 0.0142, -1.0432], [ 0.5374, -0.1479, -2.0006], [ 0.4327, -0.3214, 1.0928], [ 2.2156, -1.1640, 1.0289]]) output---> tensor([[0.5095, 0.4905], [0.5218, 0.4782], [0.5419, 0.4581], [0.5163, 0.4837], [0.6030, 0.3970]], grad_fn=<SoftmaxBackward>)
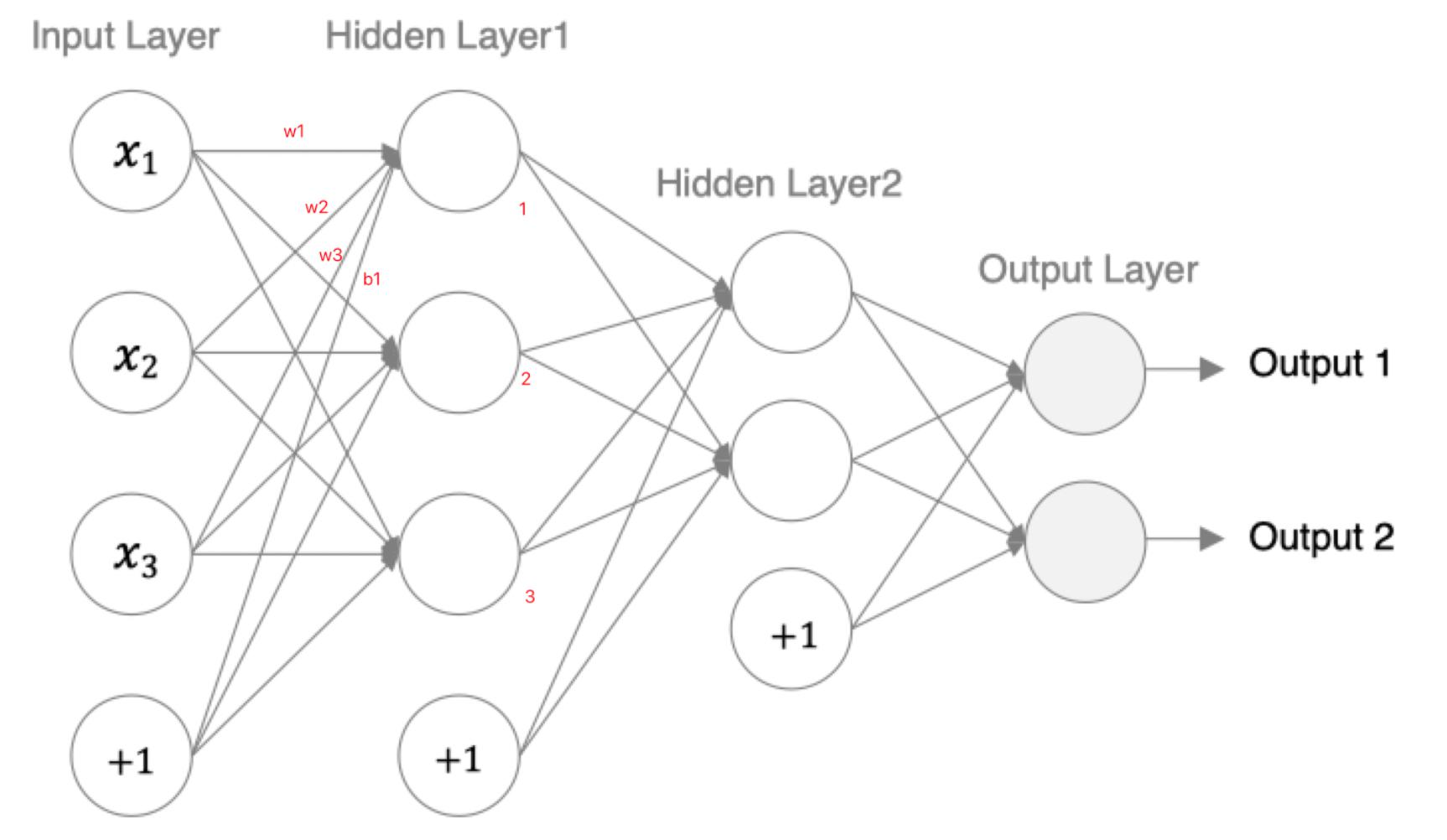
模型参数计算
模型参数的计算
以第一个隐层为例:该隐层有3个神经元,每个神经元的参数为:4个(w1,w2,w3,b1),所以一共用3x4=12个参数。
输入数据和网络权重是两个不同的事儿!对于初学者理解这一点十分重要,要分得清。
---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Linear-1 [5, 3] 12 Linear-2 [5, 2] 8 Linear-3 [5, 2] 6 ================================================================ Total params: 26 Trainable params: 26 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 0.00 Params size (MB): 0.00 Estimated Total Size (MB): 0.00 ----------------------------------------------------------------
查看模型参数
通常继承nn.Module,撰写自己的网络层。它强大的封装不需要我们定义可学习的参数(比如卷积核的权重和偏置参数)。
如何才能查看封装好的,可学习的网络参数哪?
- 模块实例名.name_parameters(),会分别返回name和parameter
# 查看模型中权重w和偏置b的初始值 for name,param in model.named_parameters(): print(f"{name}---->{param}")
损失函数
损失函数概念
在深度学习中, 损失函数是用来衡量模型参数质量的函数, 衡量的方式是比较网络输出(预测值)和真实输出(真实值)的差异。
模型通过最小化损失函数的值来调整参数,使其输出更接近真实值。
损失函数在不同的文献中名称是不一样的,主要有以下几种命名方式:
损失函数作用:
- 评估性能:反映模型预测结果与目标值的匹配程度。
- 指导优化:通过梯度下降等算法最小化损失函数,优化模型参数。
分类任务损失函数
在深度学习的分类任务中使用最多的是交叉熵损失函数,所以在这里我们着重介绍这种损失函数。
多分类任务损失函数
在多分类任务通常使用softmax将logits转换为概率的形式,所以多分类的交叉熵损失也叫做softmax损失,它的计算方法是:
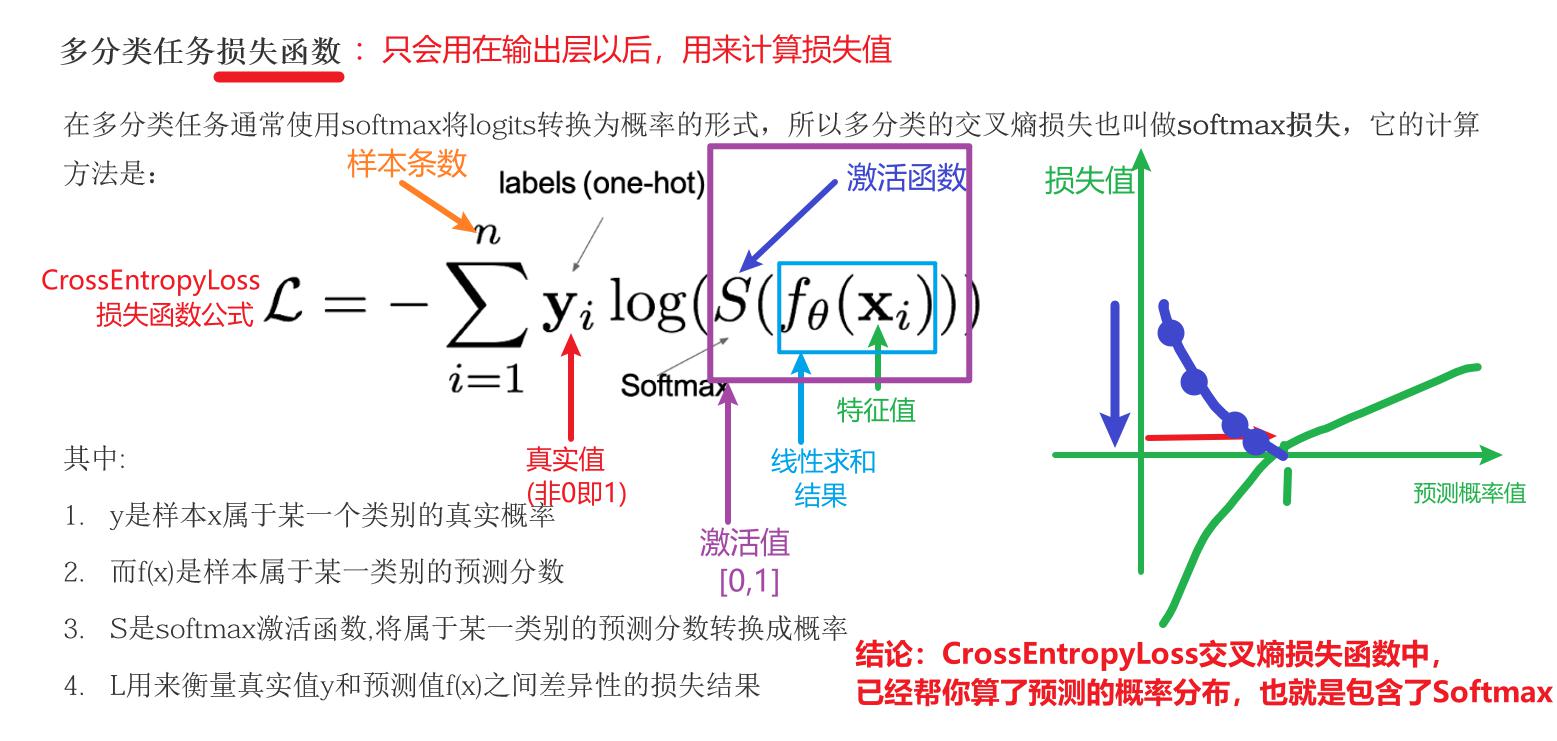
其中:
- $$y_i$$是样本x属于某一个类别的真实概率
- 而f(x)是样本属于某一类别的预测分数
- S是softmax激活函数,将属于某一类别的预测分数转换成概率
- L用来衡量真实值y和预测值f(x)之间差异性的损失结果
例子:
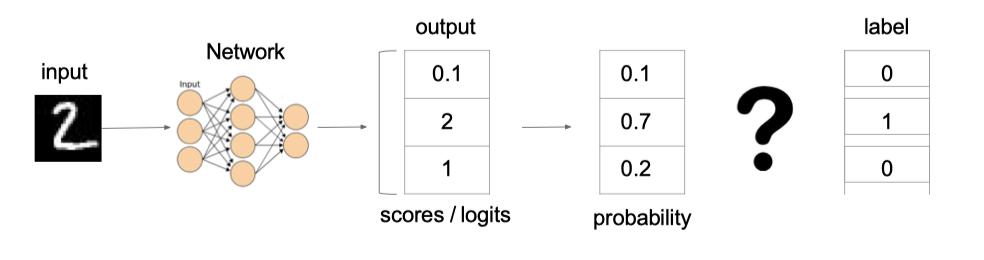
上图中的交叉熵损失为:
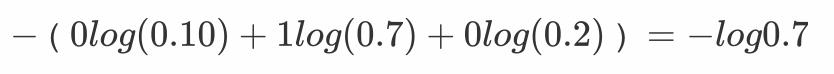
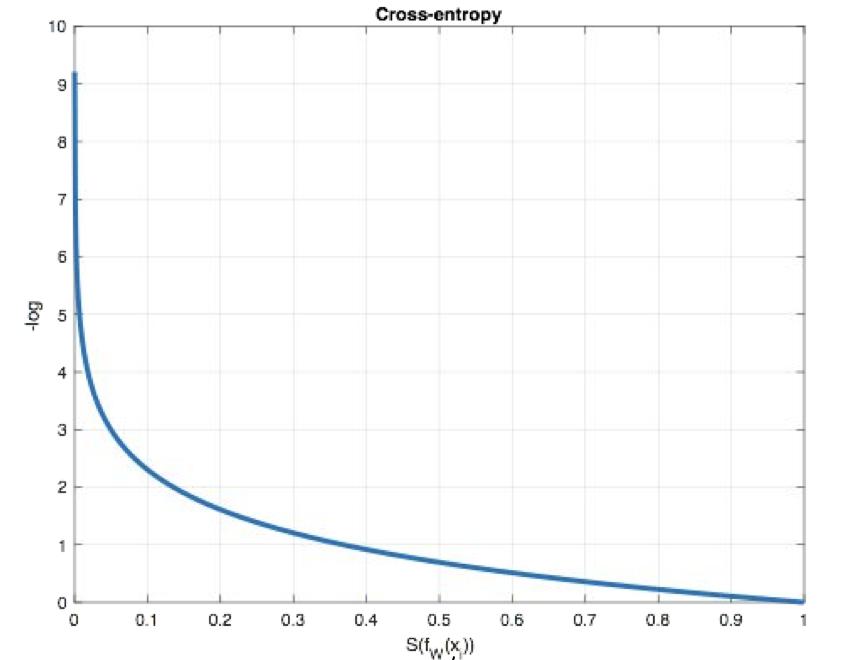
从概率角度理解,我们的目的是最小化正确类别所对应的预测概率的对数的负值(损失值最小),如下图所示:
在PyTorch中使用nn.CrossEntropyLoss()实现,如下所示:
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1- 真实值
"""
总结:
1- 如果真实值是类别ID,那么类型必须是int64或者long长整型。否则会报如下的错误
expected scalar type Long but found Int
2- 如果真实值是one-hot的形式,那么类别ID必须从0开始数;0和1表示的是概率值,因此类型必须是小数。否则报如下的错:
RuntimeError: Expected floating point type for target with class probabilities, got Long
"""
# 写法一:真实值是类别ID
y_true = torch.tensor(data=[2,4], dtype=torch.long)
# 写法二:真实值处理成one-hot的形式
# y_true = torch.tensor(data=[[0,0,1,0,0], [0,0,0,0,1]], dtype=torch.float32)
# 2- 预测值
# 这里给的是线性求和结果
y_pred = torch.tensor(data=[[11,33,22,44,55], [5,8,3.99,-5,-6]], dtype=torch.float32)
# 3- 创建损失函数实例对象
loss = nn.CrossEntropyLoss()
# 4- 计算损失值
loss_value = loss(y_pred,y_true)
print(f"损失值:{loss_value}")
二分类任务损失函数
在处理二分类任务时,我们不再使用softmax激活函数,而是使用sigmoid激活函数,那损失函数也相应的进行调整,使用二分类的交叉熵损失函数:

其中:
y是样本x属于某一个类别的真实概率
而$$\hat{y}$$是样本属于某一类别的预测概率
L用来衡量真实值y与预测值$$\hat{y}$$之间差异性的损失结果。
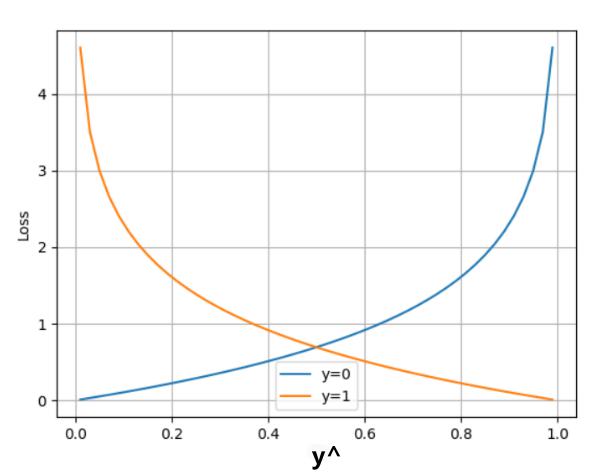
在PyTorch中实现时使用nn.BCELoss()实现,如下所示:
# 二分类问题的损失函数可以使用CrossEntropyLoss进行计算
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1- 真实目标值
# one-hot的形式
y_true = torch.tensor(data=[0,1,0], dtype=torch.float32)
# 2- 预测值
y_pred = torch.tensor(data=[0.6901, 0.5459, 0.2469], dtype=torch.float32)
# 3- 创建损失函数实例对象
loss = nn.BCELoss()
# 4- 计算损失值
loss_value = loss(y_pred,y_true)
print(f"二分类的损失值:{loss_value}")
回归任务损失函数
回归的损失函数总结:
1- L1损失
特点:也称之为MAE损失。曲线不光滑,容易错误极值点
使用:很少使用,一般作为正则化下添加到其他损失函数中
2- L2损失
特点:也称之为MSE损失。因为对损失值求和平方,容易出现梯度爆炸的情况
使用:较少使用,相对比MAE用的多些。一般作为正则化下添加到其他损失函数中
3- SmoothL1损失
特点:集成了L1损失和L2损失,而且避免了它们的确定
使用:经常使用
MAE损失函数
**mean absolute loss(MAE)**也被称为L1 Loss,是以绝对误差作为距离
损失函数公式:
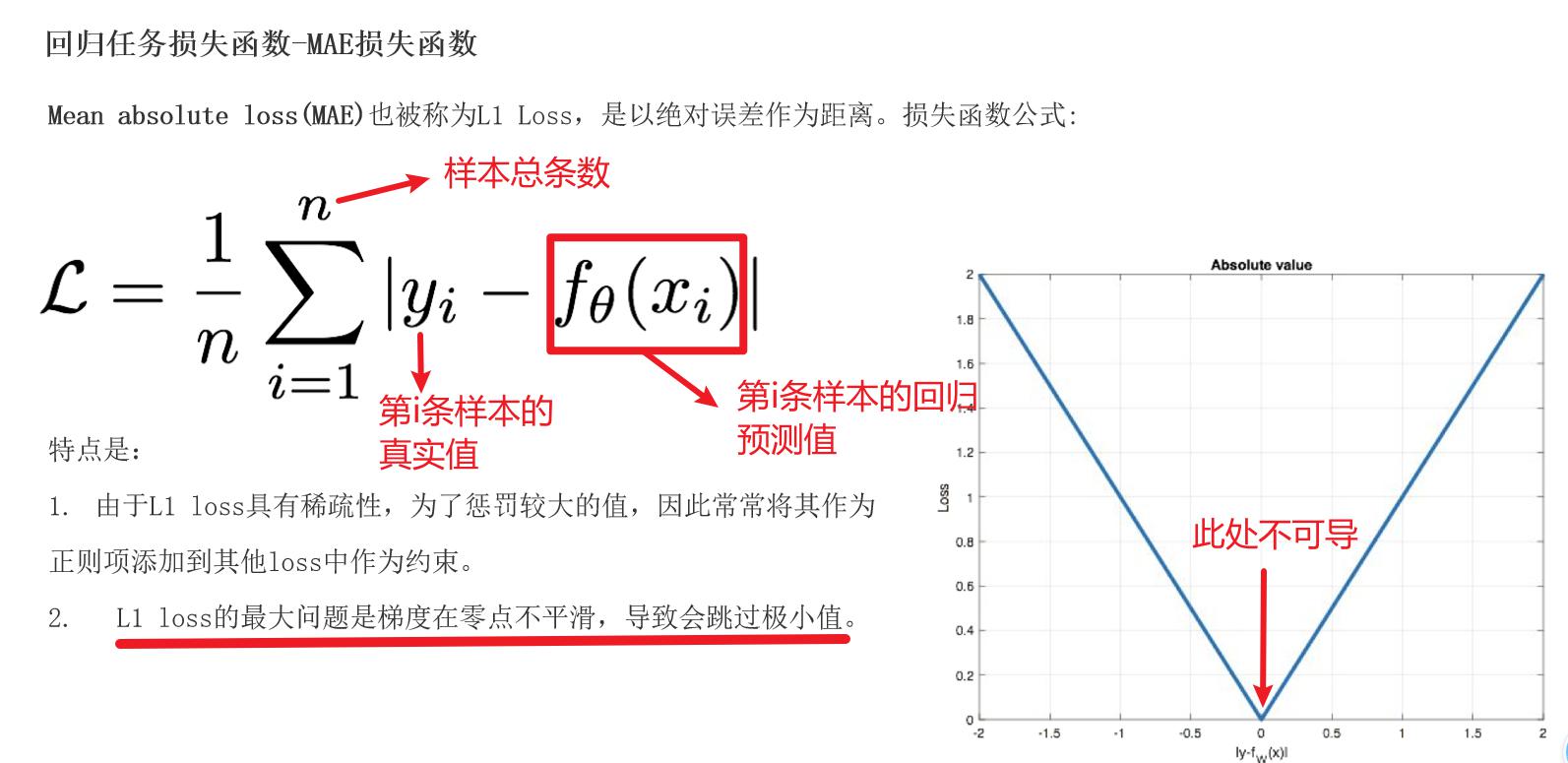
特点是:
- 由于L1 loss具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项添加到其他loss中作为约束。(0点不可导, 产生稀疏矩阵)
- L1 loss的最大问题是梯度在零点不平滑,导致会跳过极小值
- 适用于回归问题中存在异常值或噪声数据时,可以减少对离群点的敏感性
在PyTorch中使用nn.L1Loss()实现,如下所示:
import torch
from torch import nn
# 计算inputs与target之差的绝对值
def test03():
# 1 设置真实值和预测值
y_pred = torch.tensor([1.0, 1.0, 1.9])
y_true = torch.tensor([2.0, 2.0, 2.0])
# 2 实例MAE损失对象
loss = nn.L1Loss()
# 3 计算损失
my_loss = loss(y_pred, y_true)
print('loss:', my_loss)
MSE损失函数
**Mean Squared Loss/ Quadratic Loss(MSE loss)**也被称为L2 loss,或欧氏距离,它以误差的平方和的均值作为距离
损失函数公式:
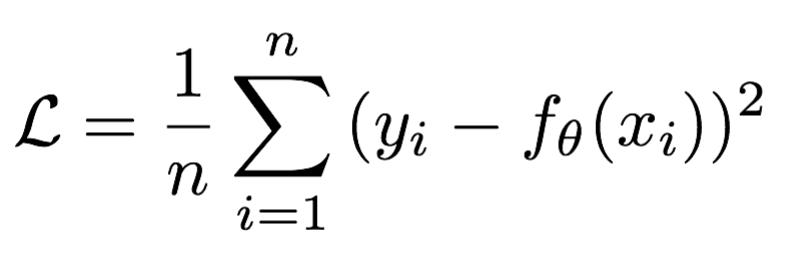
曲线如下图所示:
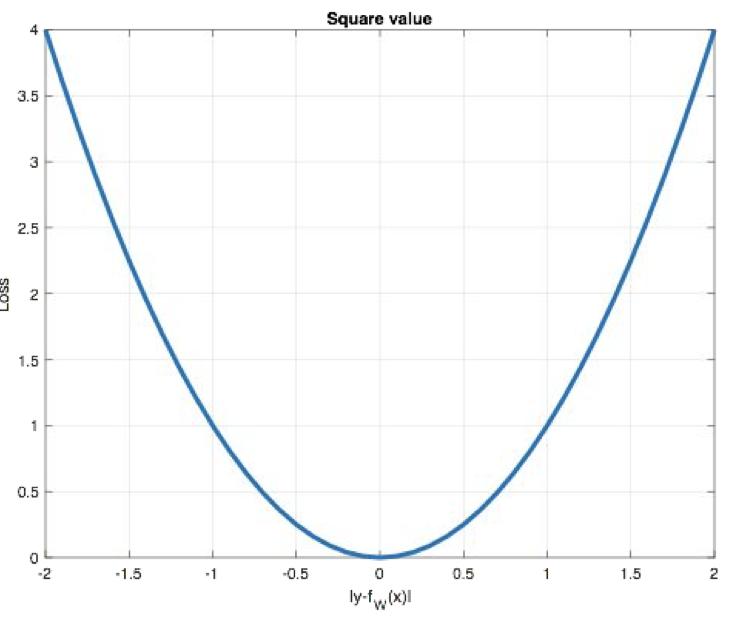
特点是:
L2 loss也常常作为正则项,对于离群点(outliers)敏感,因为平方项会放大大误差
当预测值与目标值相差很大时, 梯度容易爆炸
- 梯度爆炸:网络层之间的梯度(值大于1.0)重复相乘导致的指数级增长会产生梯度爆炸
适用于大多数标准回归问题,如房价预测、温度预测等
在PyTorch中通过nn.MSELoss()实现:
import torch
from torch import nn
def test04():
# 1 设置真实值和预测值
y_pred = torch.tensor([1.0, 1.0, 1.9])
y_true = torch.tensor([2.0, 2.0, 2.0])
# 2 实例MSE损失对象
loss = nn.MSELoss()
# 3 计算损失
my_loss = loss(y_pred, y_true)
print('myloss:', my_loss)
Smooth L1损失函数
smooth L1说的是光滑之后的L1,是一种结合了均方误差(MSE)和平均绝对误差(MAE)优点的损失函数。它在误差较小时表现得像 MSE,在误差较大时则更像 MAE。
Smooth L1损失函数如下式所示:
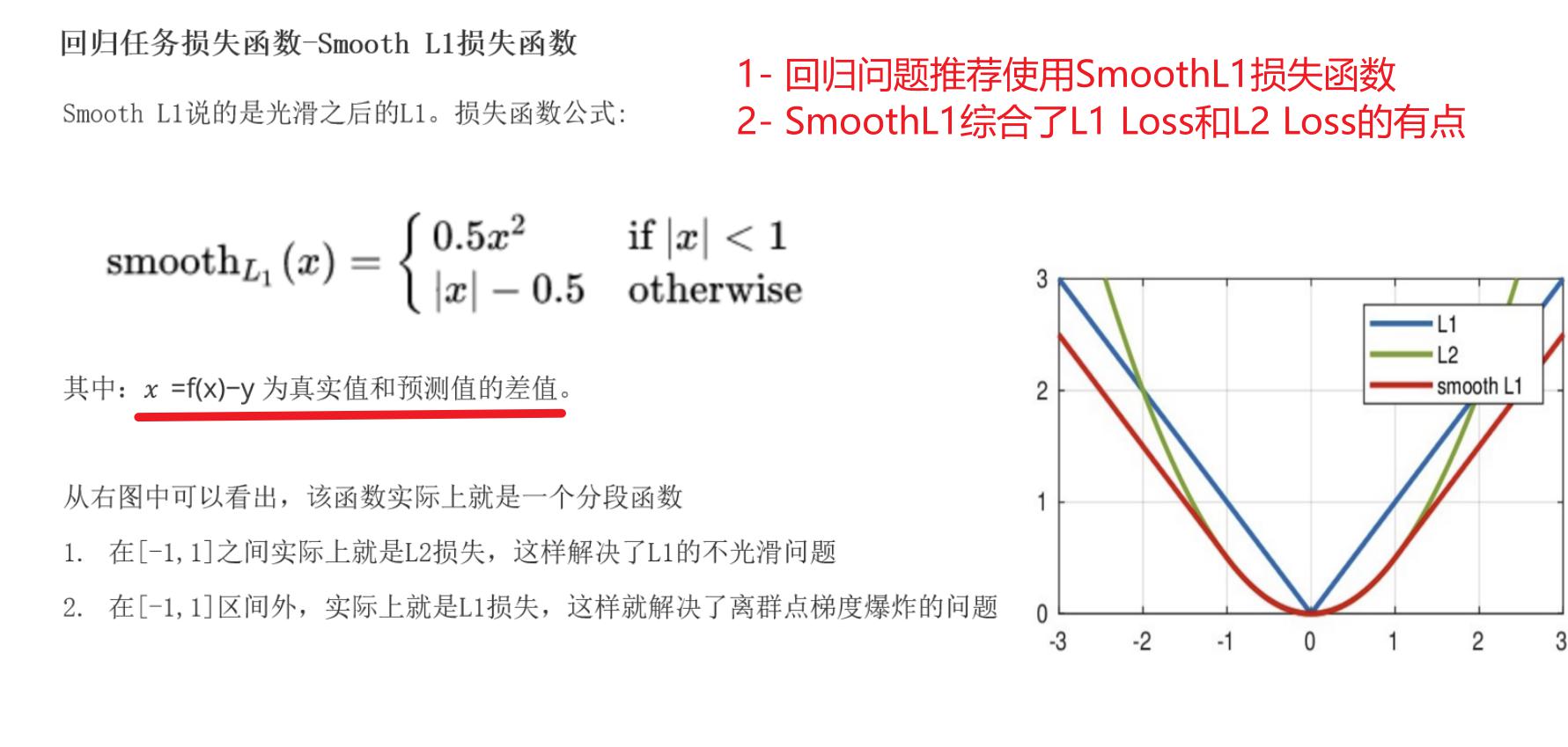
从上图中可以看出,该函数实际上就是一个分段函数
- 在[-1,1]之间实际上就是L2损失,这样解决了L1的不光滑问题
- 在[-1,1]区间外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题
特点是:
对离群点更加鲁棒:当误差较大时,损失函数会线性增加(而不是像MSE那样平方增加),因此它对离群点的惩罚更小,避免了MSE对离群点过度敏感的问题
计算梯度时更加平滑:与MAE相比,Smooth L1在小误差时表现得像MSE,避免了在训练过程中因使用绝对误差而导致的梯度不连续问题
在PyTorch中使用nn.SmoothL1Loss()计算该损失,如下所示:
import torch
from torch import nn
def test05():
# 1- 真实目标值
y_true = torch.tensor(data=[0, 3], dtype=torch.float32)
# 2- 预测目标值
y_pred = torch.tensor(data=[0.8, 1.5], dtype=torch.float32)
# 3- 创建损失函数实例对象
loss = nn.SmoothL1Loss()
# 4- 计算损失值
loss_value = loss(y_pred,y_true)
print(f"SmoothL1Loss损失值:{loss_value}")
总结【掌握】
分类问题的损失函数:
1- 不管是多分类,还是二分类,都可以使用CrossEntropyLoss损失函数
2- 如果是多分类,只能使用CrossEntropyLoss损失函数
3- 如果是二分类,可以使用BCELoss损失函数
回归问题的损失函数:推荐使用SmoothL1损失函数
神经网络优化方法
多层神经网络的学习能力比单层网络强得多。想要训练多层网络,需要更强大的学习算法。误差反向传播算法(Back Propagation)是其中最杰出的代表,它是目前最成功的神经网络学习算法。现实任务使用神经网络时,大多是在使用 BP 算法进行训练,值得指出的是 BP 算法不仅可用于多层前馈神经网络,还可以用于其他类型的神经网络。通常说 BP 网络时,一般是指用 BP 算法训练的多层前馈神经网络。
这就需要了解两个概念:
- 正向传播:指的是数据通过网络从输入层到输出层的传递过程。这个过程的目的是计算网络的输出值(预测值),从而与目标值(真实值)比较以计算误差。
- 反向传播:指的是计算损失函数相对于网络中各参数(权重和偏置)的梯度,指导优化器更新参数,从而使神经网络的预测更接近目标值。
梯度下降算法回顾
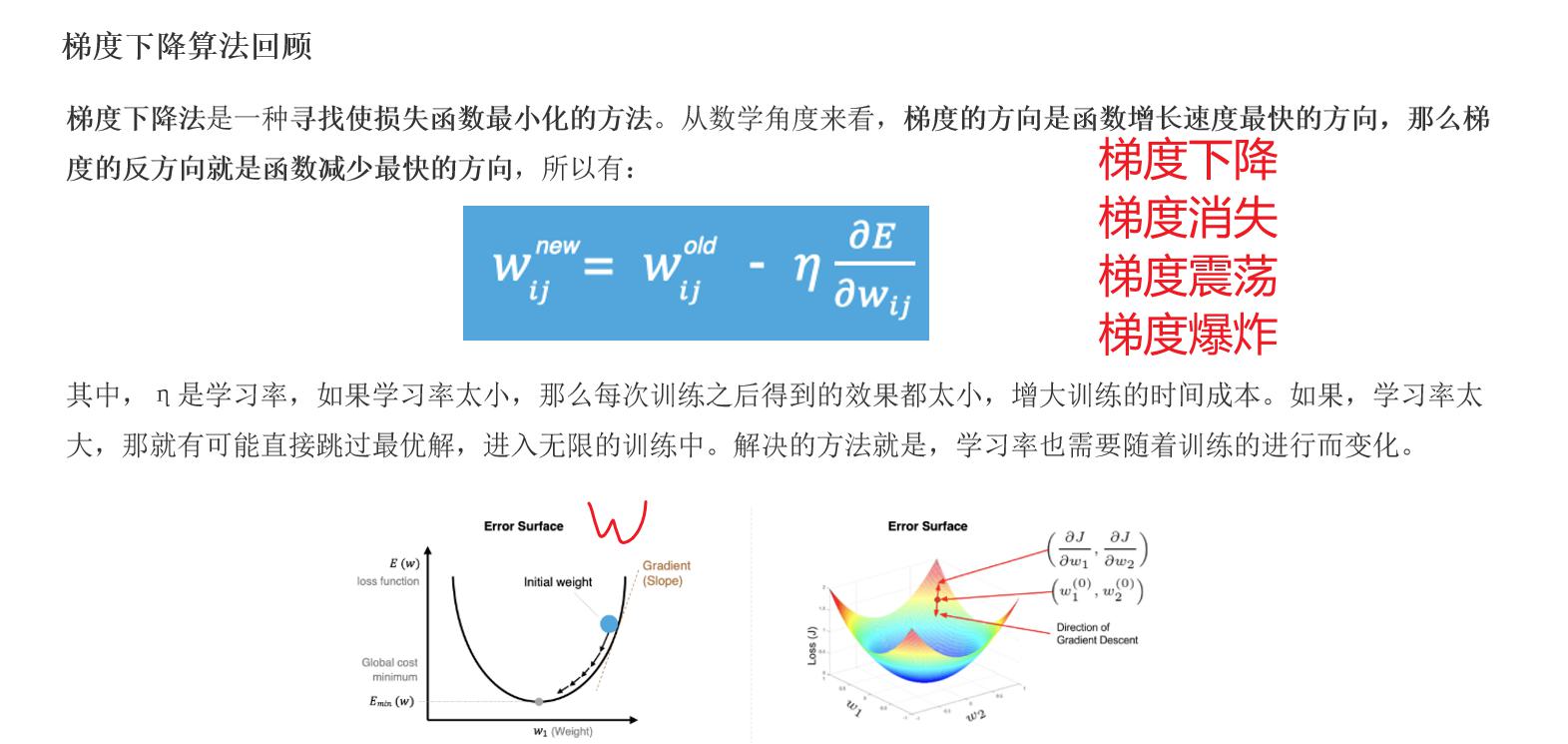
学习率过小或者过大都会存在问题
学习率过小:
1- 下降速度太慢,训练成本增加
2- 可能会遇到鞍点,也就是权重没有变化
学习率过大:
1- 错过损失值的最低点
2- 梯度震荡:在最优解的左右两边来回横跳
3- 梯度爆炸:损失值不是越来越小,反而是越来越大
反向传播(BP算法)
利用反向传播算法对神经网络进行训练。该方法与梯度下降算法相结合,对网络中所有权重计算损失函数的梯度,并利用梯度值来更新权值以最小化损失函数。
反向传播概念
前向传播:指的是数据输入到神经网络中,逐层向前传输,一直运算到输出层为止。
反向传播(Back Propagation):利用损失函数ERROR值,从后往前,结合梯度下降算法,依次求各个参数的偏导,并进行参数更新。
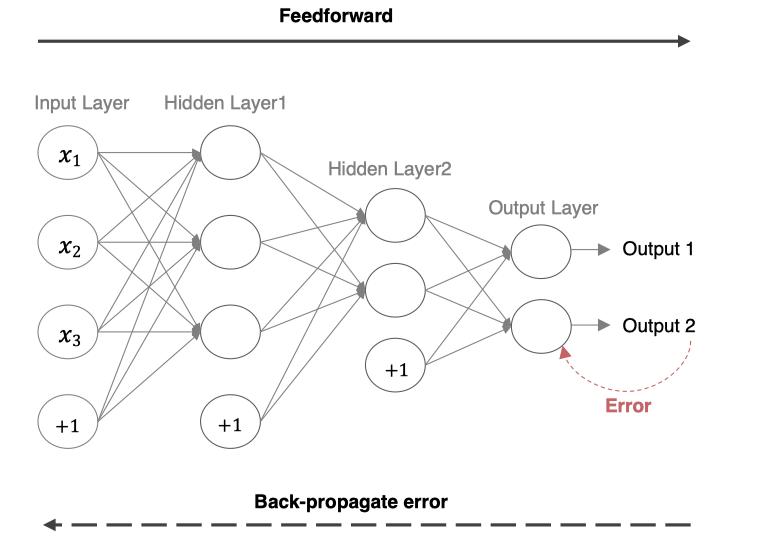
在网络的训练过程中经过前向传播后得到的最终结果跟训练样本的真实值总是存在一定误差,这个误差便是损失函数 ERROR。想要减小这个误差,就用损失函数 ERROR,从后往前,依次求各个参数的偏导,这就是反向传播(Back Propagation)。
反向传播详解
反向传播算法利用链式法则对神经网络中的各个节点的权重进行更新。

梯度下降优化方法
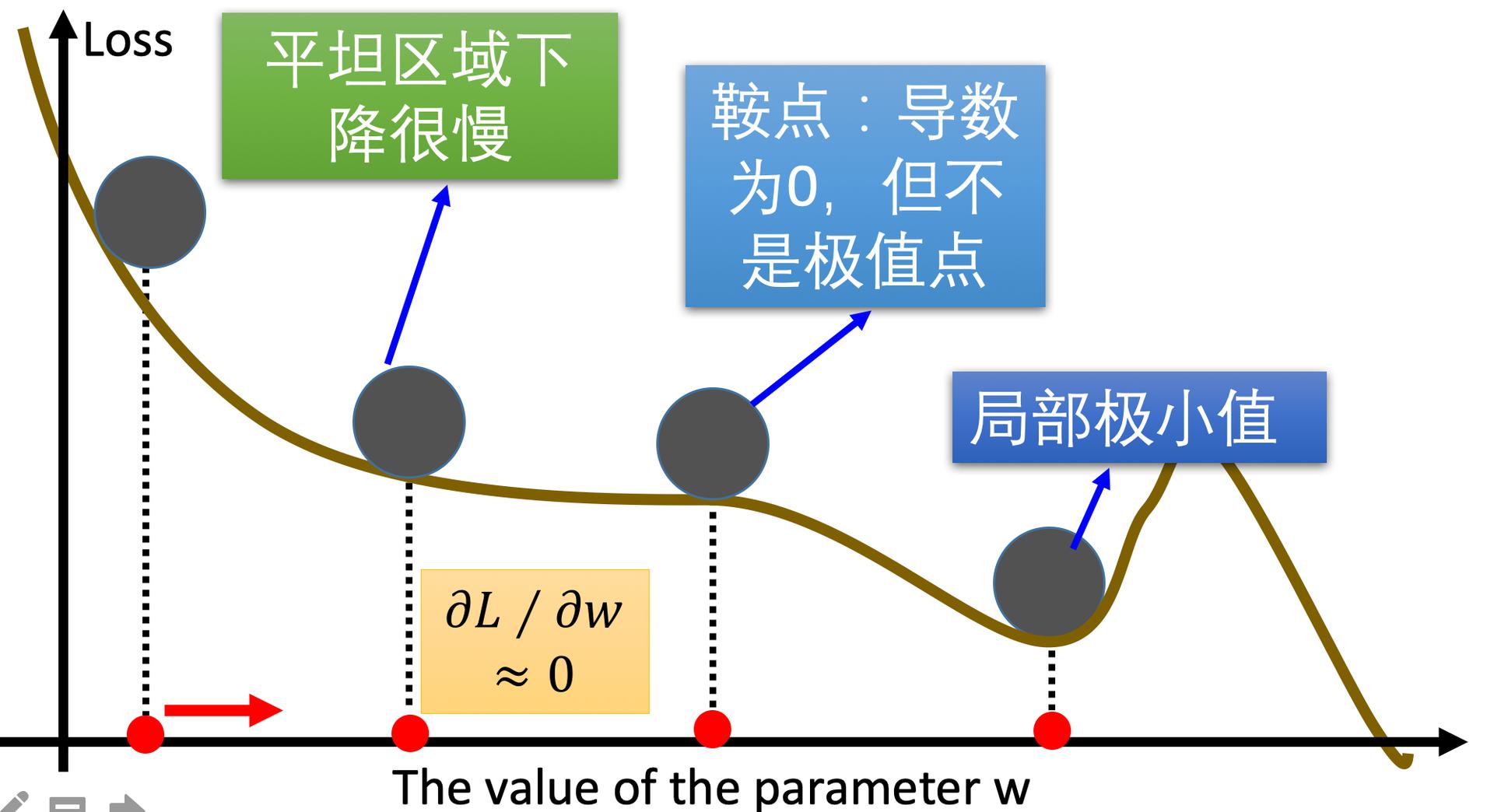
梯度下降优化算法中,可能会碰到以下情况:
- 碰到平缓区域,梯度值较小,参数优化变慢
- 碰到 “鞍点” ,梯度为0,参数无法优化
- 碰到局部最小值,参数不是最优
对于这些问题, 出现了一些对梯度下降算法的优化方法,例如:Momentum、AdaGrad、RMSprop、Adam 等
指数加权平均
我们最常见的算数平均指的是将所有数加起来除以数的个数,每个数的权重是相同的。指数加权平均指的是给每个数赋予不同的权重求得平均数。移动平均数,指的是计算最近邻的 N 个数来获得平均数。
指数移动加权平均则是参考各数值,并且各数值的权重都不同,距离越远的数字对平均数计算的贡献就越小(权重较小),距离越近则对平均数的计算贡献就越大(权重越大)。
比如:明天气温怎么样,和昨天气温有很大关系,而和一个月前的气温关系就小一些。
计算公式可以用下面的式子来表示:

第100天的指数加权平均值为:

下面通过代码来看结果,随机产生 30 天的气温数据:
import torch
import matplotlib.pyplot as plt
ELEMENT_NUMBER = 30
# 1. 实际平均温度
def test01():
# 固定随机数种子
torch.manual_seed(0)
# 产生30天的随机温度
temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10
print(temperature)
# 绘制平均温度
days = torch.arange(1, ELEMENT_NUMBER + 1, 1)
plt.plot(days, temperature, color='r')
plt.scatter(days, temperature)
plt.show()
# 2. 指数加权平均温度
def test02(beta=0.9):
# 固定随机数种子
torch.manual_seed(0)
# 产生30天的随机温度
temperature = torch.randn(size=[ELEMENT_NUMBER,]) * 10
print(temperature)
exp_weight_avg = []
# idx从1开始
for idx, temp in enumerate(temperature, 1):
# 第一个元素的 EWA 值等于自身
if idx == 1:
exp_weight_avg.append(temp)
continue
# 第二个元素的 EWA 值等于上一个 EWA 乘以 β + 当前气温乘以 (1-β)
# idx-2:2-2=0,exp_weight_avg列表中第一个值的下标值
new_temp = exp_weight_avg[idx - 2] * beta + (1 - beta) * temp
exp_weight_avg.append(new_temp)
days = torch.arange(1, ELEMENT_NUMBER + 1, 1)
plt.plot(days, exp_weight_avg, color='r')
plt.scatter(days, temperature)
plt.show()
if __name__ == '__main__':
test01()
test02(0.5)
test02(0.9)
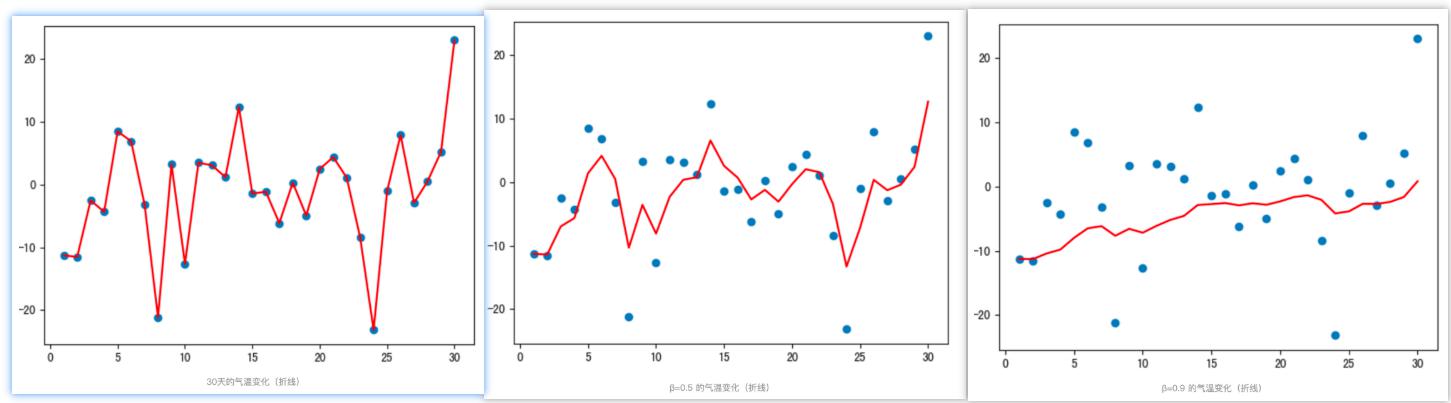
从程序运行结果可以看到:
- 指数加权平均绘制出的气温变化曲线更加平缓
- β 的值越大,则绘制出的折线越加平缓,波动越小(1-β越小,t时刻的$S_t$越不依赖$Y_t$的值)
- β 值一般默认都是 0.9
动量算法Momentum
当梯度下降碰到 “峡谷” 、”平缓”、”鞍点” 区域时, 参数更新速度变慢。 Momentum 通过指数加权平均法,累计历史梯度值,进行参数更新,越近的梯度值对当前参数更新的重要性越大。
梯度计算公式:
$$s_t=βs_{t−1}+(1−β)g_t$$
参数更新公式:
$$w_t=w_{t−1}−ηs_t$$
$s_t$是当前时刻指数加权平均梯度值
$s_{t-1}$是历史指数加权平均梯度值
$g_t$是当前时刻的梯度值
β 是调节权重系数,通常取 0.9 或 0.99
η是学习率
$w_t$是当前时刻模型权重参数

咱们举个例子,假设:权重 β 为 0.9,例如:
第一次梯度值:s1 = g1 = w1
第二次梯度值:s2 = 0.9*s1 + g2*0.1
第三次梯度值:s3 = 0.9*s2 + g3*0.1
第四次梯度值:s4 = 0.9*s3 + g4*0.1
1. w 表示初始梯度
2. g 表示当前轮数计算出的梯度值
3. s 表示历史梯度移动加权平均值
梯度下降公式中梯度的计算,就不再是当前时刻t的梯度值,而是历史梯度值的指数移动加权平均值。
公式修改为:
Wt = Wt-1 - η*St
Wt:当前时刻模型权重参数
St:当前时刻指数加权平均梯度值
η:学习率
Monmentum 优化方法是如何一定程度上克服 “平缓”、”鞍点”、”峡谷” 的问题呢?
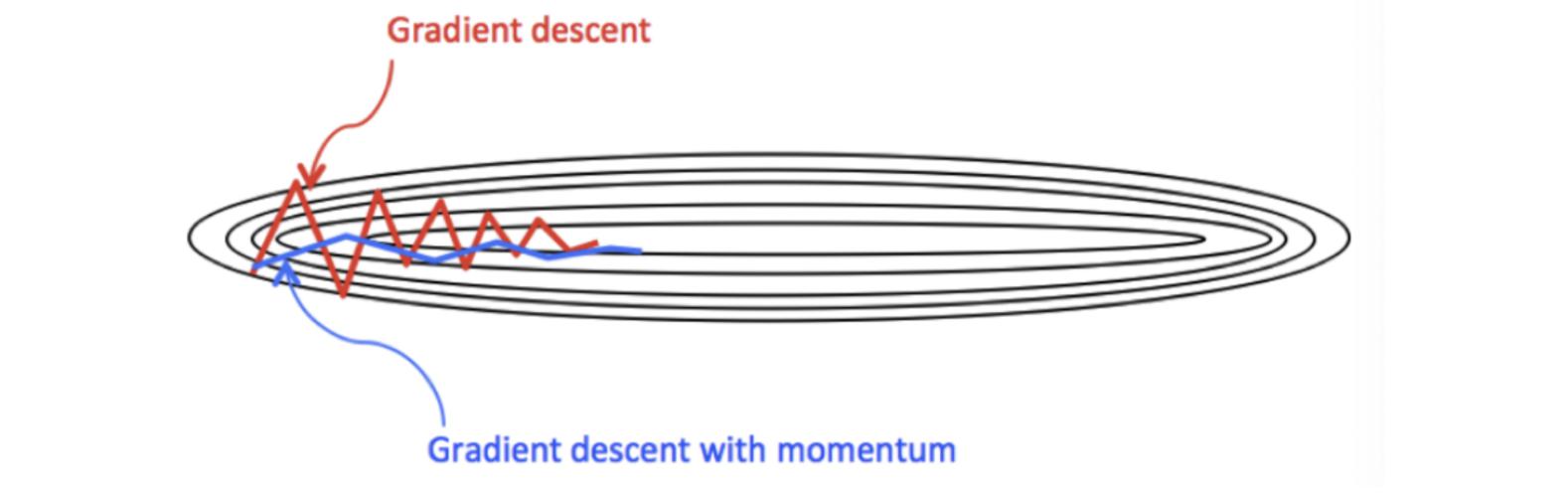
- 当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是 Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点。
- 由于 mini-batch 普通的梯度下降算法,每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长。Momentum 使用移动加权平均,平滑了梯度的变化,使得前进方向更加平缓,有利于加快训练过程。一定程度上有利于降低 “峡谷” 问题的影响。
在pytorch中动量梯度优化法编程实践如下:
import torch
import torch.nn
def momentum_demo():
# 初始化权重值
w = torch.tensor([1.0],requires_grad=True,dtype=torch.float32)
# 自定义损失函数
criterion = (w**2)/2
# 创建优化器对象,作用:1- 计算梯度;2- 自动更新权重
optimizer = torch.optim.SGD(params=[w], lr=0.01, momentum=0.9)
# 反向传播计算梯度
# 梯度清零
optimizer.zero_grad()
# 反向传播
criterion.sum().backward()
# 更新权重
optimizer.step()
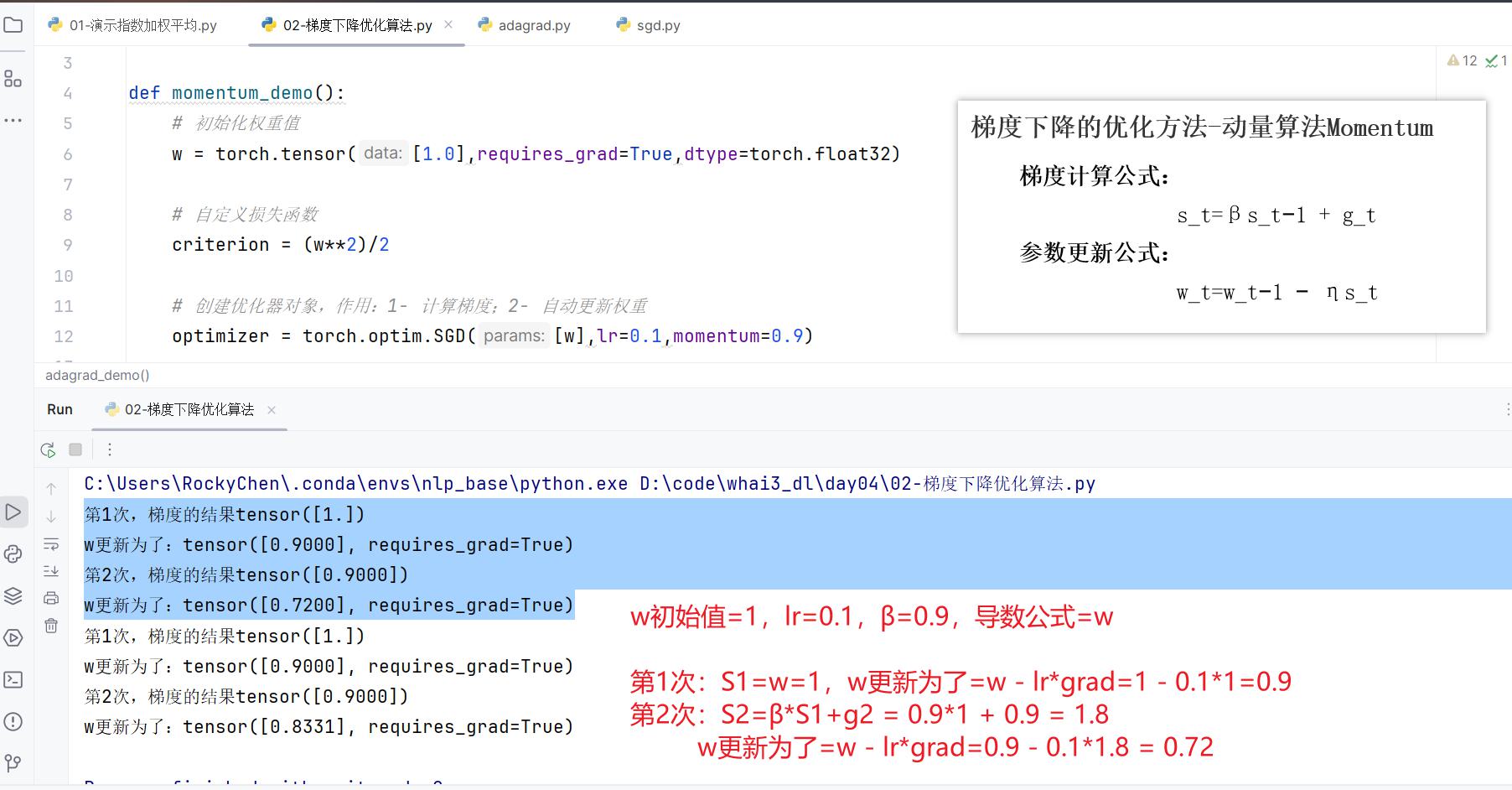
print(f"第1次,梯度的结果{w.grad},更新后的权重值{w.detach()}")
# 第二次
criterion = (w ** 2) / 2
# 反向传播计算梯度
# 梯度清零
optimizer.zero_grad()
# 反向传播
criterion.sum().backward()
# 更新权重
optimizer.step()
print(f"第2次,梯度的结果{w.grad},更新后的权重值{w.detach()}")
if __name__ == '__main__':
# 动量法
momentum_demo()
计算过程如下:
AdaGrad
AdaGrad 通过对不同的参数分量使用不同的学习率,AdaGrad 的学习率总体会逐渐减小,这是因为 AdaGrad 认为:在起初时,我们距离最优目标仍较远,可以使用较大的学习率,加快训练速度,随着迭代次数的增加,学习率逐渐下降。
其计算步骤如下:
初始化学习率 η、初始化参数w、小常数 σ = 1e-10
初始化梯度累计变量 s = 0
从训练集中采样 m 个样本的小批量,计算梯度$g_t$
累积平方梯度: $s_t$ = $s_{t-1}$ + $g_t$ ⊙ $g_t$,⊙ 表示各个分量相乘
学习率 η 的计算公式如下:
η = $$η\over\sqrt{s_t}+σ$$
权重参数更新公式如下:
$w_t$ = $$w_{t-1}$$ - $$η\over\sqrt{s_t}+σ$$ * $g_t$
重复 3-7 步骤
AdaGrad 缺点是可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解。
在PyTorch中AdaGrad优化法编程实践如下:
def test02():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
loss = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:adagrad优化方法
optimizer = torch.optim.Adagrad([w], lr=0.01)
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad, w.detach()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad, w.detach()))
结果显示:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.990000
第2次: 梯度w.grad: 0.990000, 更新后的权重:0.982965
RMSProp
RMSProp 优化算法是对 AdaGrad 的优化。最主要的不同是,其使用指数加权平均梯度替换历史梯度的平方和。
其计算过程如下:
初始化学习率 η、初始化权重参数w、小常数 σ = 1e-10
初始化梯度累计变量 s = 0
从训练集中采样 m 个样本的小批量,计算梯度 $g_t$
使用指数加权平均累计历史梯度,⊙ 表示各个分量相乘,公式如下:
$s_t$ = β$s_{t-1}$ + (1-β)$g_t$⊙$g_t$
学习率 η 的计算公式如下:
η = $η\over\sqrt{s_t}+σ$
权重参数更新公式如下:
$w_t$ = $w_{t-1}$ - $η\over\sqrt{s_t}+σ$ * $g_t$
重复 3-7 步骤
RMSProp 与 AdaGrad 最大的区别是对梯度的累积方式不同,对于每个梯度分量仍然使用不同的学习率。
RMSProp 通过引入衰减系数β,控制历史梯度对历史梯度信息获取的多少. 被证明在神经网络非凸条件下的优化更好,学习率衰减更加合理一些。
需要注意的是:AdaGrad 和 RMSProp 都是对于不同的参数分量使用不同的学习率,如果某个参数分量的梯度值较大,则对应的学习率就会较小,如果某个参数分量的梯度较小,则对应的学习率就会较大一些。
在PyTorch中RMSprop梯度优化法,编程实践如下:
def test03():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
loss = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:RMSprop算法,其中alpha对应beta
optimizer = torch.optim.RMSprop([w], lr=0.01, alpha=0.9)
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad, w.detach()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad, w.detach()))
结果显示:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.968377
第2次: 梯度w.grad: 0.968377, 更新后的权重:0.945788
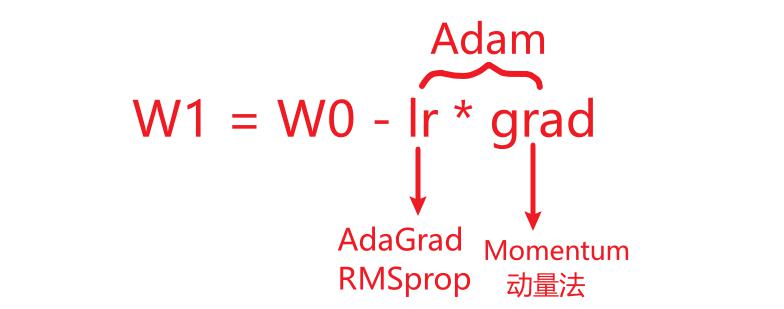
Adam
Momentum 使用指数加权平均计算当前的梯度值
AdaGrad、RMSProp 使用自适应的学习率
Adam优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和 RMSProp 算法结合在一起
- 修正梯度: 使⽤梯度的指数加权平均
- 修正学习率: 使⽤梯度平⽅的指数加权平均
原理:Adam 是结合了 Momentum 和 RMSProp 优化算法的优点的自适应学习率算法。它计算了梯度的一阶矩(平均值)和二阶矩(梯度的方差)的自适应估计,从而动态调整学习率。
梯度计算公式:
$$m_t=β_1m_{t−1}+(1−β_1)g_t$$
$$s_t=β_2s_{t−1}+(1−β_2)gt^2$$
$$\hat{m_t}$$ = $$m_t\over1−β_1^t$$, $$\hat{s_t}$$=$$s_t\over1−β_2^t$$
权重参数更新公式:
$$w_t$$ = $$w_{t−1}$$ − $$η\over\sqrt{\hat{s_t}}+ϵ$$$\hat{m_t}$
其中,$$m_t$$ 是梯度的一阶矩估计,$$s_t$$ 是梯度的二阶矩估计,$$ \hat{m_t}$$和 $$\hat{s_t}$$ 是偏差校正后的估计。
在PyTroch中,Adam梯度优化法编程实践如下:
def test04():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True)
loss = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:Adam算法,其中betas是指数加权的系数
optimizer = torch.optim.Adam([w], lr=0.01, betas=[0.9, 0.99])
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad, w.detach()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad, w.detach()))
结果显示:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.990000
第2次: 梯度w.grad: 0.990000, 更新后的权重:0.980003
小结【掌握】
| 优化算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| SGD | 简单、容易实现。 | 收敛速度较慢,容易震荡(容易受异常样本的影响),特别是在复杂问题中。 | 用于简单任务,或者当数据特征分布相对稳定时。 |
| Momentum | 可以加速收敛,减少震荡,特别是在高曲率区域。 | 需要手动调整动量超参数,可能会在小步长训练中过度更新。 | 用于非平稳优化问题,尤其是深度学习中的应用。 |
| AdaGrad | 自适应调整学习率,适用于稀疏数据。 | 学习率会在训练过程中逐渐衰减,可能导致早期停滞。 | 适合稀疏数据,如 NLP 或推荐系统中的特征。 |
| RMSProp | 解决了 AdaGrad 学习率过早衰减的问题,适应性强。 | 需要选择合适的超参数,更新可能会过于激进。 | 适用于动态问题、非平稳目标函数,如深度学习训练。 |
| Adam | 结合了 Momentum 和 RMSProp 的优点,适应性强且稳定。 | 需要调节更多的超参数,训练过程中可能会产生较大波动。 | 广泛适用于各种深度学习任务,特别是非平稳和复杂问题。 |
- 优先推荐使用Adam,因为它即对学习率也对梯度值进行优化
- 神经网络模型比较简单:可以使用SGD、Momentum
- 神经网络模型比较复杂:推荐使用Adam
- NLP领域,或者处理文字类型的数据:可以使用AdaGrad或者RMSprop
学习率衰减优化方法【理解】
为什么要进行学习率优化
在训练神经网络时,一般情况下学习率都会随着训练而变化。这主要是由于,在神经网络训练的后期,如果学习率过高,会造成loss的振荡,但是如果学习率减小的过慢,又会造成收敛变慢的情况。
运行下面代码,观察学习率设置不同对网络训练的影响:
"""
案例:
通过代码 观察不同的学习率 对 参数更新 的影响.
"""
import torch
import matplotlib.pyplot as plt
# x看成是权重,y看成是loss,下面通过代码来理解学习率的作用
def func(x_t):
return torch.pow(2*x_t, 2) # y = 4 x ^2
# 采用较小的学习率,梯度下降的速度慢
# 采用较大的学习率,梯度下降太快越过了最小值点,导致不收敛,甚至震荡
def dm01(lr=0.3):
x = torch.tensor([2.], requires_grad=True)
# 记录loss迭代次数,画曲线
iter_rec, loss_rec, x_rec = list(), list(), list()
# 实验学习率: 0.01 0.02 0.03 0.1 0.2 0.3 0.4
# lr = 0.1 # 正常的梯度下降
# lr = 0.125 # 当学习率设置0.125 一下子求出一个最优解
# x=0 y=0 在x=0处梯度等于0 x的值x=x-lr*x.grad就不用更新了
# 后续再多少次迭代 都固定在最优点
# lr = 0.3 # x从2.0一下子跨过0点,到了左侧负数区域
# lr = 0.3 # 梯度越来越大 梯度爆炸
max_iteration = 40
for i in range(max_iteration):
y = func(x) # 得出loss值
y.backward() # 计算x的梯度
print("Iter:{}, X:{:8}, X.grad:{:8}, loss:{:10}".format(
i, x.detach().numpy()[0], x.grad.detach().numpy()[0], y.item()))
x_rec.append(x.item()) # 梯度下降点 列表
# 更新参数
x.data.sub_(lr * x.grad) # x = x - x.grad
x.grad.zero_()
iter_rec.append(i) # 迭代次数 列表
loss_rec.append(y.item()) # 损失值 列表,这里将y改为y.item()以获取标量值
# 迭代次数-损失值 关系图
plt.subplot(121).plot(iter_rec, loss_rec, '-ro')
plt.grid()
plt.xlabel("Iteration X")
plt.ylabel("Loss value Y")
# 函数曲线-下降轨迹 显示图
x_t = torch.linspace(-3, 3, 100)
y = func(x_t)
plt.subplot(122).plot(x_t.detach().numpy(), y.detach().numpy(), label="y = 4*x^2")
y_rec = [func(torch.tensor(i)).item() for i in x_rec]
print('x_rec--->', x_rec)
print('y_rec--->', y_rec)
# 指定线的颜色和样式(-ro:红色圆圈,b-:蓝色实线等)
plt.subplot(122).plot(x_rec, y_rec, '-ro')
plt.grid()
plt.legend()
plt.show()
if __name__ == '__main__':
# dm01(0.01) # 学习率过小,梯度下降缓慢,需要迭代计算多次
# dm01(0.1)
dm01(0.2) # 学习率设置的不合理,会出现梯度震荡
# dm01(0.3) # 学习率过大,会出现梯度爆炸
运行效果图如下:
可以看出:采用较小的学习率,梯度下降的速度慢;采用较大的学习率,梯度下降太快越过了最小值点,导致震荡,甚至不收敛(梯度爆炸)。
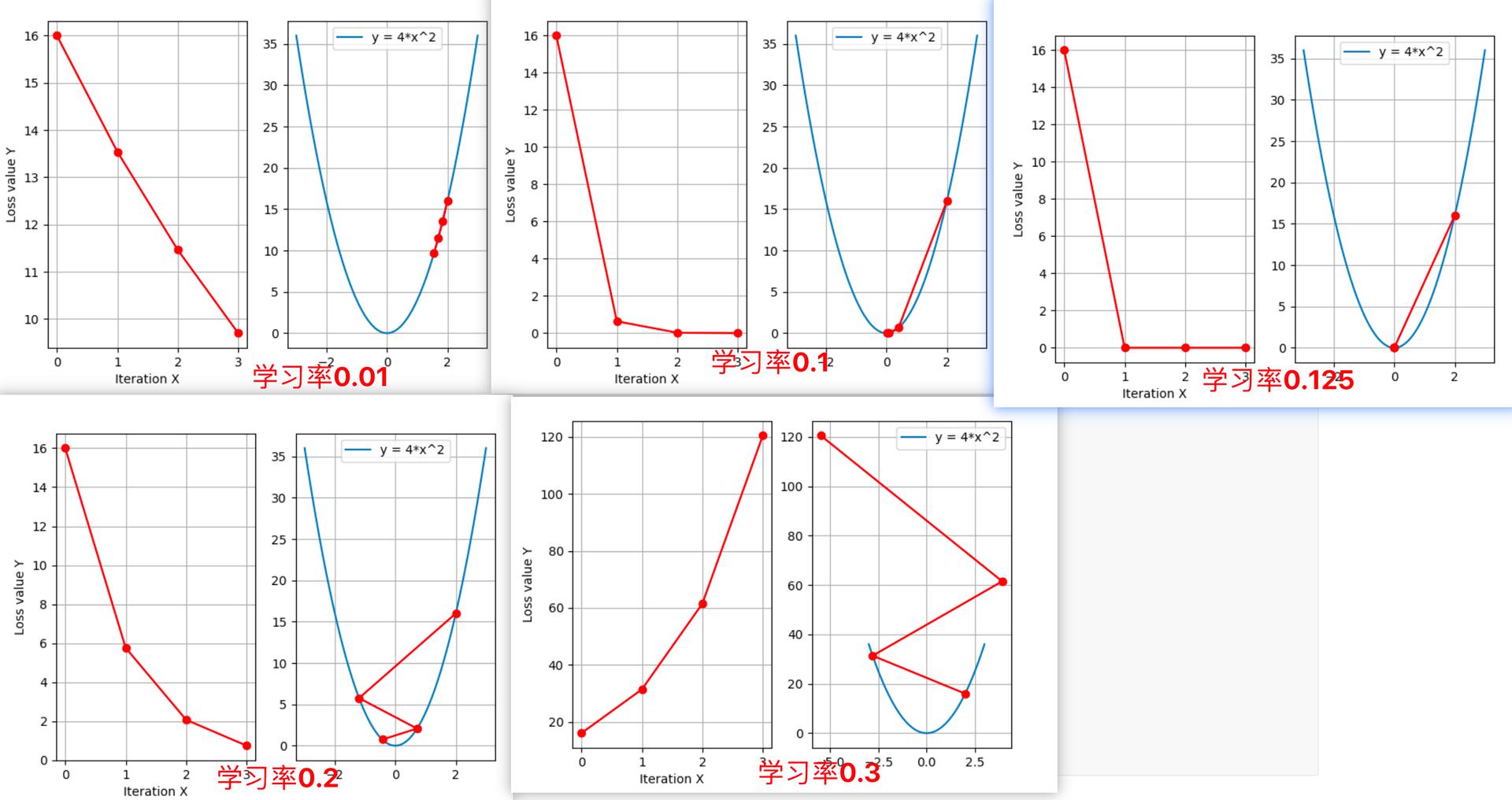
学习率设置总结
1- 机器学习中的学习率范围[0.001, 0.01]
2- 深度学习、大模型[1e-5, 1e-3]
等间隔学习率衰减
等间隔学习率衰减方式如下所示:
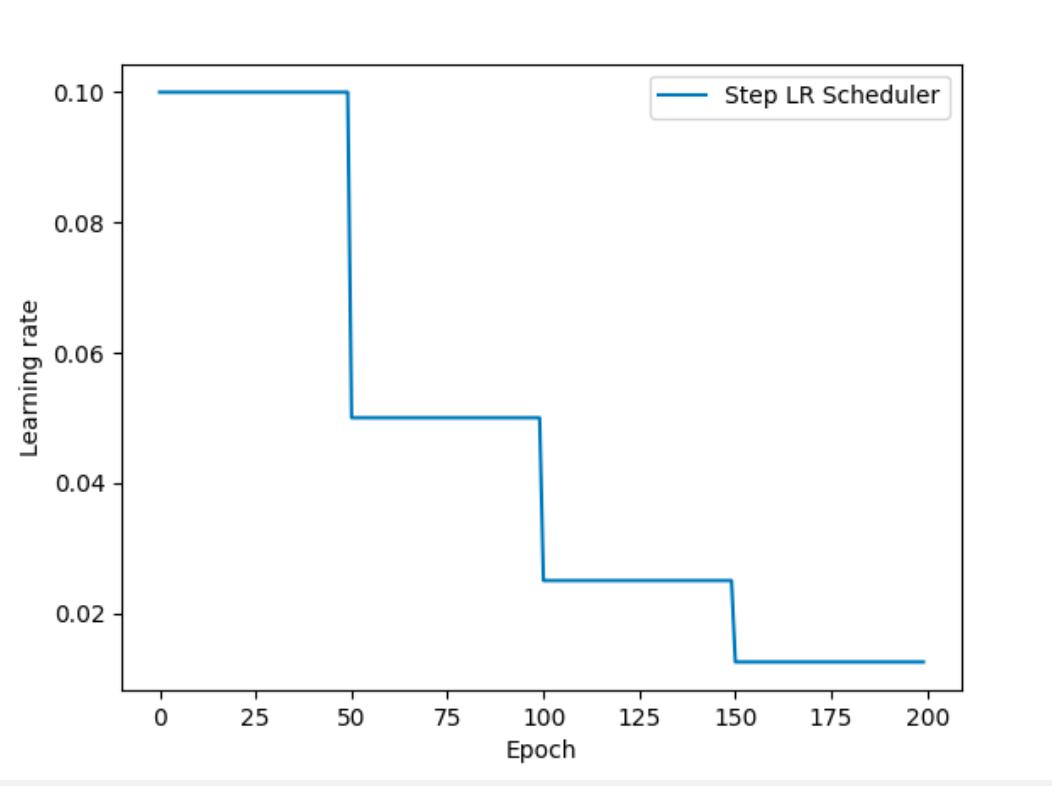
在PyTorch中实现时使用:
# step_size:调整间隔数=50
# gamma:调整系数=0.5
# 调整方式:lr = lr * gamma
optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.5)
具体使用方式如下:
import matplotlib.pyplot as plt
import torch
def demo01():
# 1- 准备数据
# 真实值
y_true = torch.tensor([0])
# 特征数据
x = torch.tensor([1], dtype=torch.float32)
# 初始化权重
w = torch.tensor([1],dtype=torch.float32,requires_grad=True)
# 2- 创建优化器
# 2.1- 自动优化器对象
optimizer = torch.optim.SGD(params=[w],lr=0.1,momentum=0.9)
# 2.2- 指定间隔学习率衰减策略对象【熟悉】
"""
参数解释:
optimizer:底层依赖的梯度下降算法优化器
step_size:每隔多少个epoch轮次,就对学习率调整一次
gamma:学习率的调整系数。更新后的学习率 = 上一次的学习率 * gamma
"""
scheduler = torch.optim.lr_scheduler.StepLR(optimizer=optimizer, step_size=50, gamma=0.5)
# 3- 模型训练
epochs = 200
lr_value_list = [] # 用来存储训练过程中的学习率值
# 外层循环控制轮次
for epoch in range(epochs):
# 内层循环控制批次
for i in range(10):
# 3.1- 前向传播
y_pred = w*x
# 3.2- 计算损失
loss_value = (y_pred-y_true)**2
# 3.3- 反向传播固定代码
optimizer.zero_grad() # 梯度清零
loss_value.sum().backward() # 反向传播
optimizer.step() # 更新参数w和b
# 4- 记录轮次和lr的关系
lr_value_list.append(scheduler.get_last_lr())
scheduler.step() # 内部自动判断是否要进行学习率的更新
# 5- 绘制epoch与lr的变化曲线
plt.plot(range(1,epochs+1),lr_value_list)
plt.xlabel("Epoch")
plt.ylabel("LR")
plt.show()
if __name__ == '__main__':
demo01()
指定间隔学习率衰减
指定间隔学习率衰减的效果如下:
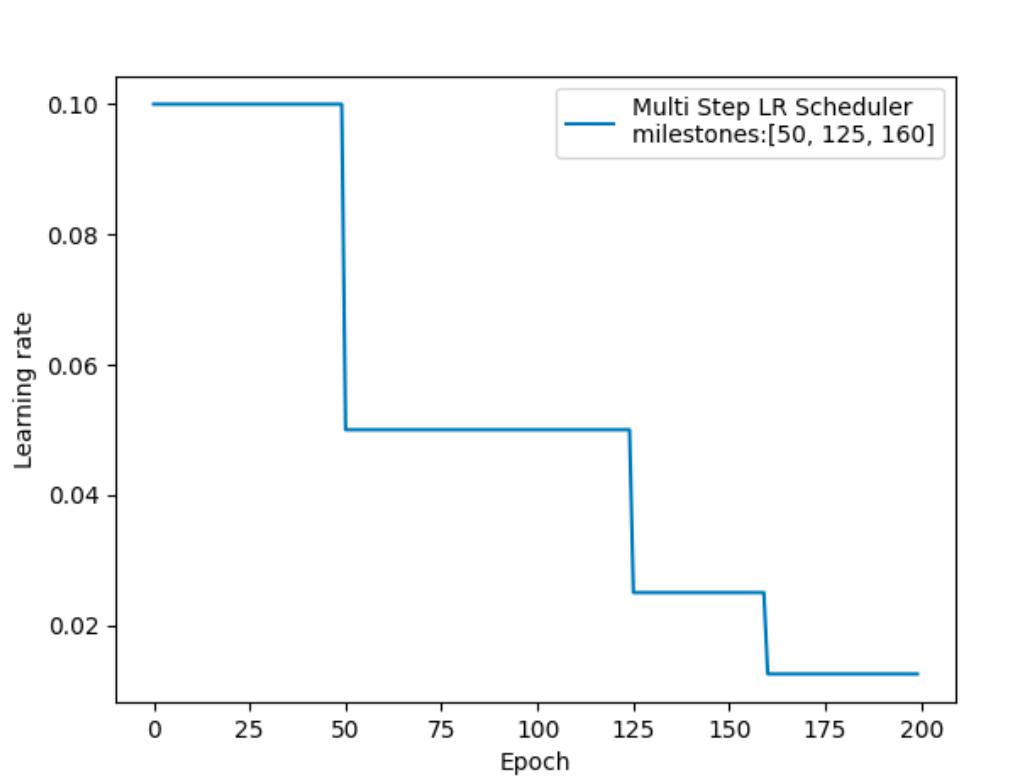
在PyTorch中实现时使用:
# milestones:设定调整轮次:[50, 125, 160]
# gamma:调整系数
# 调整方式:lr = lr * gamma
optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1)
具体使用方式如下所示:
# 导包
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
def demo02():
# 1- 准备数据
# 真实值
y_true = torch.tensor([0])
# 特征数据
x = torch.tensor([1], dtype=torch.float32)
# 初始化权重
w = torch.tensor([1],dtype=torch.float32,requires_grad=True)
# 2- 创建优化器
# 2.1- 自动优化器对象
optimizer = torch.optim.SGD(params=[w],lr=0.1,momentum=0.9)
# 2.2- 指定间隔学习率衰减策略对象
"""
参数解释:
optimizer:底层依赖的梯度下降优化器
milestones:指定当是第几个轮次的时候,进行衰减
gamma:衰减稀疏
"""
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer=optimizer,milestones=[50,125,160],gamma=0.5)
# 3- 模型训练
epochs = 200
lr_value_list = [] # 用来存储训练过程中的学习率值
# 外层循环控制轮次
for epoch in range(epochs):
# 内层循环控制批次
for i in range(10):
# 3.1- 前向传播
y_pred = w*x
# 3.2- 计算损失
loss_value = (y_pred-y_true)**2
# 3.3- 反向传播固定代码
optimizer.zero_grad() # 梯度清零
loss_value.sum().backward() # 反向传播
optimizer.step() # 更新参数w和b
# 4- 记录轮次和lr的关系
lr_value_list.append(scheduler.get_last_lr())
scheduler.step() # 内部自动判断是否要进行学习率的更新
# 5- 绘制epoch与lr的变化曲线
plt.plot(range(1,epochs+1),lr_value_list)
plt.xlabel("Epoch")
plt.ylabel("LR")
plt.show()
# 测试
if __name__ == '__main__':
demo02()
按指数学习率衰减
按指数衰减调整学习率的效果如下:
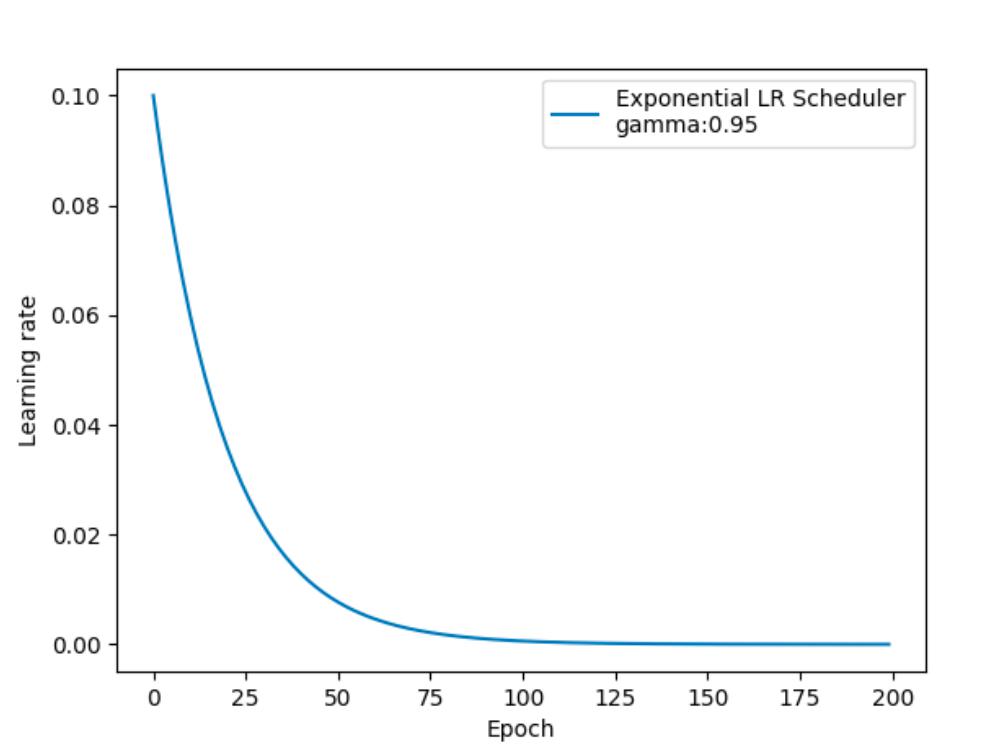
在PyTorch中实现时使用:
# gamma:指数的底
# 调整方式
# lr= lr∗gamma^epoch
optim.lr_scheduler.ExponentialLR(optimizer, gamma)
具体使用方式如下所示:
# 导包
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
# 3. 定义函数, 演示: 如何实现 指数学习率优化.
def demo03():
# 1- 准备数据
# 真实值
y_true = torch.tensor([0])
# 特征数据
x = torch.tensor([1], dtype=torch.float32)
# 初始化权重
w = torch.tensor([1],dtype=torch.float32,requires_grad=True)
# 2- 创建优化器
# 2.1- 自动优化器对象
optimizer = torch.optim.SGD(params=[w],lr=0.1,momentum=0.9)
# 2.2- 指定间隔学习率衰减策略对象
"""
参数解释:
optimizer:底层依赖的梯度下降优化器
gamma:衰减稀疏
"""
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer=optimizer,gamma=0.95)
# 3- 模型训练
epochs = 200
lr_value_list = [] # 用来存储训练过程中的学习率值
# 外层循环控制轮次
for epoch in range(epochs):
# 内层循环控制批次
for i in range(10):
# 3.1- 前向传播
y_pred = w*x
# 3.2- 计算损失
loss_value = (y_pred-y_true)**2
# 3.3- 反向传播固定代码
optimizer.zero_grad() # 梯度清零
loss_value.sum().backward() # 反向传播
optimizer.step() # 更新参数w和b
# 4- 记录轮次和lr的关系
lr_value_list.append(scheduler.get_last_lr())
scheduler.step() # 内部自动判断是否要进行学习率的更新
# 5- 绘制epoch与lr的变化曲线
plt.plot(range(1,epochs+1),lr_value_list)
plt.xlabel("Epoch")
plt.ylabel("LR")
plt.show()
# 测试
if __name__ == '__main__':
demo03()
小结
手动调整学习率的策略相对上一章节中自动调整学习率的方式,手动的方式比较麻烦,因此在实际工作中很少使用。原因是实际工作中的神经网络结构一般都会比较复杂,手动调整很麻烦。
| 方法 | 等间隔学习率衰减 (Step Decay) | 指定间隔学习率衰减 (Exponential Decay) | 指数学习率衰减 (Exponential Moving Average Decay) |
|---|---|---|---|
| 衰减方式 | 固定步长衰减 | 指定步长衰减 | 平滑指数衰减,历史平均考虑 |
| 实现难度 | 简单易实现 | 相对简单,容易调整 | 需要额外历史计算,较复杂 |
| 适用场景 | 大型数据集、较为简单的任务 | 对训练平稳性要求较高的任务 | 高精度训练,避免过快收敛 |
| 优点 | 直观,易于调试,适用于大批量数据 | 易于调试,稳定训练过程 | 平滑且考虑历史更新,收敛稳定性较强 |
| 缺点 | 学习率变化较大,可能跳过最优点 | 在某些情况下可能衰减过快,导致优化提前停滞 | 超参数调节较为复杂,可能需要更多的计算资源 |
正则化方法
什么是正则化
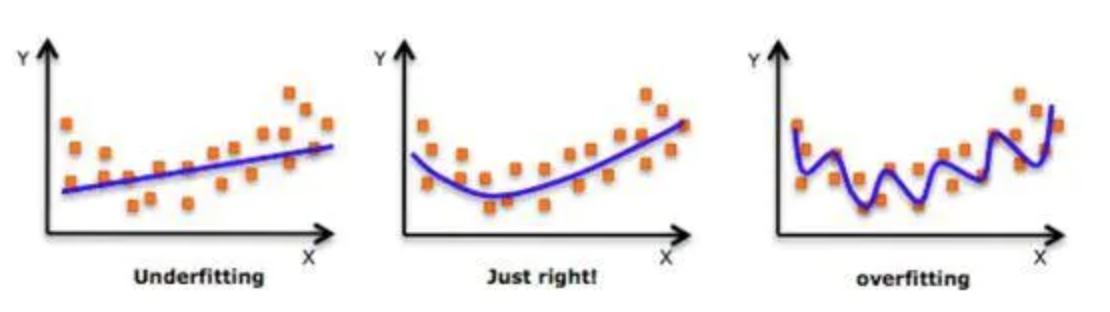
- 在设计机器学习算法时希望在新样本上的泛化能力强。许多机器学习算法都采用相关的策略来减小测试误差,这些策略被统称为正则化
- 神经网络强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略
- 目前在深度学习中使用较多的策略有范数惩罚,DropOut,特殊的网络层等,接下来我们对其进行详细的介绍
Dropout正则化【掌握】
在训练深层神经网络时,由于模型参数较多,在数据量不足的情况下,很容易过拟合。Dropout(中文翻译成随机失活)是一个简单有效的正则化方法。
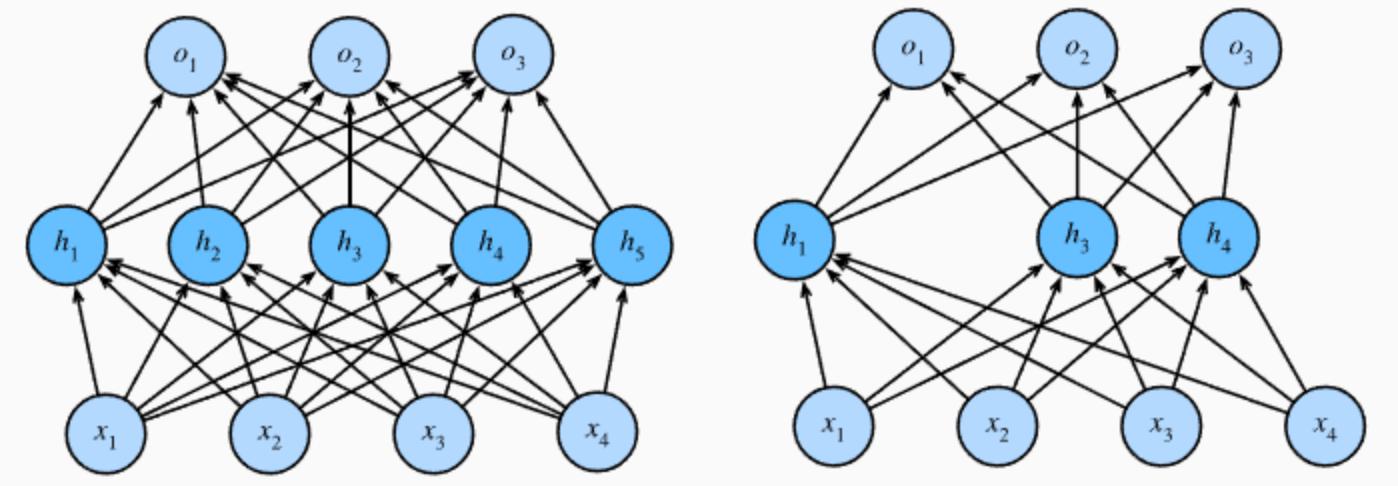
- 在训练过程中,Dropout的实现是**让神经元以超参数p(丢弃概率)的概率停止工作或者激活被置为0,未被置为0的进行缩放,缩放比例为1/(1-p)**。训练过程可以认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更新子网络的参数
- 在实际应用中,Dropout参数p的概率通常取值在0.2到0.5之间
- 对于较小的模型或较复杂的任务,丢弃率可以选择0.3或更小
- 对于非常深的网络,较大的丢弃率(如0.5或0.6)可能会有效防止过拟合
- 实际应用中,通常会在全连接层(激活函数后)之后添加Dropout层
- 在测试过程中,随机失活不起作用:未知数据预测过程中,不允许出现神经元失活
- 在测试阶段,使用所有的神经元进行预测,以获得更稳定的结果
- 直接使用训练好的模型进行测试,由于所有的神经元都参与计算,输出的期望值会比训练阶段高。测试阶段的期望输出是 E[x_test] = x
- 测试/推理模式:model.eval(),作用是不允许神经元失活
- 缩放的必要性
- 在训练阶段,将参与计算的神经元的输出除以(1-p)
- 经过Dropout后的期望输出变为 E[x_dropout] = [(1-p) * x] / (1-p) = x,与测试阶段的期望输出一致
- 训练模型:model.train(),作用是允许神经元失活
为什么模型训练的时候允许神经元失活,而模型预测的时候不允许神经元失活?
1- 训练的时候
原因: 为了缓解模型过拟合的情况,提高模型的泛化能力(新数据的适应能力)。让每个神经元得到充分的训练,达到更好的效果
代码: model.train() 将模式设置为训练模式,也就是在训练过程中允许神经元失活
2- 预测的时候
原因: 为了让所有的神经元都参与到预测的过程,那么预测效果是最好的
代码: model.eval() 将模式设置为预测模式,也就是在预测过程中不允许神经元失活
我们通过一段代码观察下dropout的效果:
import torch
if __name__ == '__main__':
# 1- 准备数据
input_data = torch.randint(low=1,high=10,size=(1,4),dtype=torch.float32)
# 2- 构建网络结构
linear = torch.nn.Linear(in_features=4,out_features=6)
# 3- 创建随机失活层Dropout
dropout = torch.nn.Dropout(p=0.6)
# 4- 演示随机失活的过程
result = linear(input_data) # 线性求和结果
result = torch.tanh(result) # 计算激活值
print(f"随机失活前:{result}")
result = dropout(result) # 调用随机失活层
print(f"随机失活后:{result}")
上述代码将Dropout层的丢弃概率p设置为0.6,此时经过Dropout层计算的张量中就出现了很多0, 未变为0的按照(1/(1-0.6))进行处理。
批量归一正则化(Batch Normalization)【了解】
在神经网络的训练过程中,流经网络的数据都是一个batch,每个batch之间的数据分布变化非常剧烈,这就使得网络参数频繁的进行大的调整以适应流经网络的不同分布的数据,给模型训练带来非常大的不稳定性,使得模型难以收敛。如果我们对每一个batch的数据进行标准化之后,数据分布就变得稳定,参数的梯度变化也变得稳定,有助于加快模型的收敛。
通过标准化每一层的输入,使其均值接近0,方差接近1,从而加速训练并提高泛化能力。
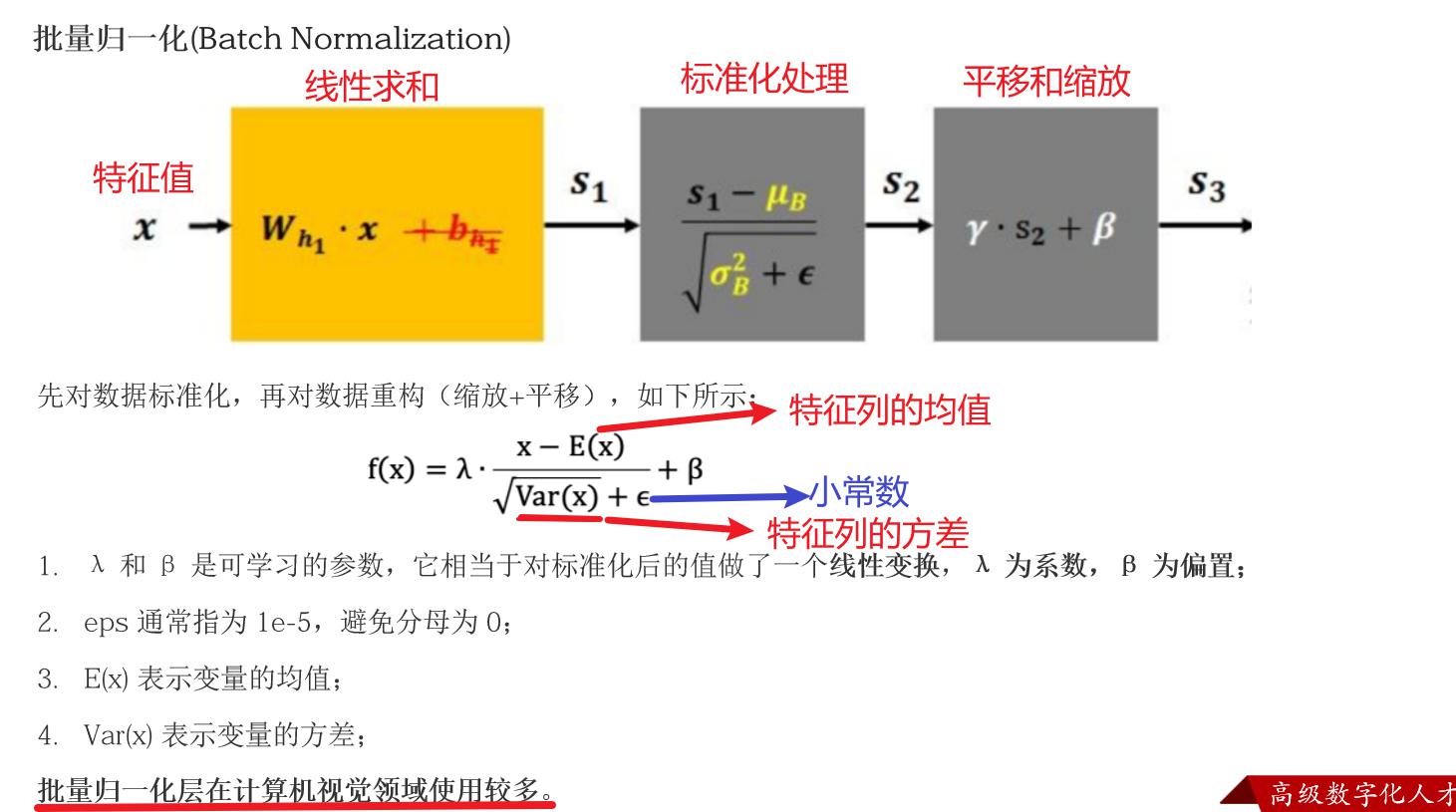
深度学习中的批量归一化BN与机器学习中的标准化处理的区别是啥?
机器学习:对所有的业务数据在输入给到算法之前,统一进行一次性的标准化处理
深度学习:对输入进神经网络的每个批次的数据进行单独的标准化处理。例如:总共有100条样本,16条/批次,7批次,
这7个批次各自计算均值和标准差,然后独立进行标准化处理
先对数据标准化,再对数据重构(缩放+平移),写成公式如下所示:
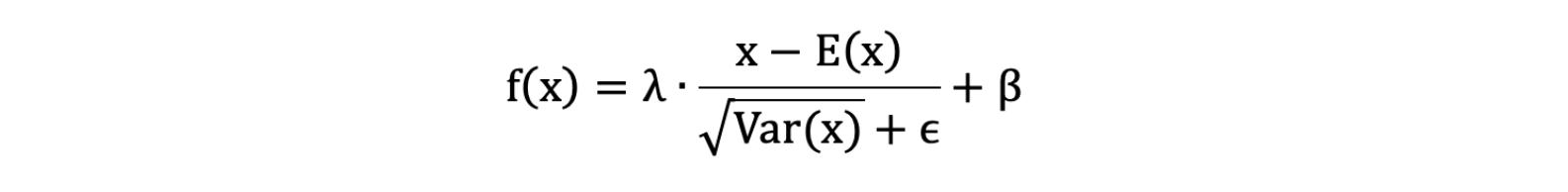
λ和β是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ为系数,β为偏置;
eps 通常指为 1e-5,避免分母为 0;
E(x) 表示变量的均值;
Var(x) 表示变量的方差;
批量归一化的步骤如下:
计算均值和方差:对于每个神经元(即每一层的输入特征),计算该特征在一个小批量(batch)上的均值 $$μ_B$$ 和方差 $$\sigma_B^2$$,它们的计算公式如下:
$$μ_B=\frac{1}{m} \sum_{i=1}^{m} x_i$$
$$σ_B^2=\frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2$$
其中 $$x_i$$ 表示小批量中的第 $$i$$ 个样本,$$m$$ 是小批量的样本数量。
标准化:然后,对每个样本的输入进行标准化,得到归一化的输出:
$$\hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}}$$
其中,$$ϵ$$ 是一个小常数,用来避免除以零的情况。
缩放和平移:为了让网络能够恢复其学习能力,BN 层引入了两个可训练的参数 $$γ$$ 和 $$β$$,分别用于缩放和平移:
$$y_i = \gamma \hat{x}_i + β$$
其中,$$γ$$ 和 $$β$$ 是可学习的参数,通过 γ 和 β,BN 层不再是简单的将每一层输入强行变为标准正态分布,而是允许网络学习更适合于该层的输入分布;规范化操作会丢失原始输入的一些信息,而 $$γ$$ 和 $$β$$ 可以弥补这种信息损失。
批量归一化的作用:输入到神经网络的输入层数据,我们可以进行量纲的处理,例如:标准化、归一化
减少内部协方差偏移:通过对每层的输入进行标准化,减少了输入数据分布的变化,从而加速了训练过程,并使得网络在训练过程中更加稳定。
加速训练:
- 在没有批量归一化的情况下,神经网络的训练通常会很慢,尤其是深度网络。因为在每层的训练过程中,输入数据的分布(特别是前几层)会不断变化,这会导致网络学习速度缓慢。
- 批量归一化通过确保每层的输入数据在训练时分布稳定,有效减少了这种变化,从而加速了训练过程。
起到正则化作用:批量归一化可以视作一种正则化方法,因为它引入了对训练样本的噪声(不同批次的统计信息不同,批次较小的均值和方差估计会更加不准确),使得模型不容易依赖特定的输入特征,从而起到一定的正则化效果,减少了对其他正则化技术(如Dropout)的需求。
提升泛化能力:由于其正则化效果,批量归一化能帮助网络在测试集上取得更好的性能。
批量归一化层在计算机视觉领域使用较多
Batch Normalization 的使用步骤:
- 在网络层后添加 BN 层:
- 通常,BN 层会添加在卷积层 (Conv2d) 或全连接层 (Linear) 之后,激活函数之前。
- 例如:Conv2d -> BN -> ReLU 或者 Linear -> BN -> ReLU。
- 训练时:model.train()
- BN 层会计算当前批次的均值 $$μ$$ 和方差 $$σ²$$。
- 然后,利用这两个统计量对当前批次的数据进行规范化。
- 规范化后的数据会被缩放 $$γ$$ 和平移 $$β$$。
- 同时,BN 层还会维护一个全局均值和全局方差的移动平均值,用于推理阶段。
- 推理时:model.eval()
- 推理时,不会再使用当前批次的均值和方差,而是使用训练阶段计算的全局均值和全局方差。
- 同样,规范化后的数据会被缩放 $$γ$$ 和平移 $$β$$。
import torch
if __name__ == '__main__':
# 1- 准备数据
"""
样本数据是4维,每个位置上的含义解释如下:
1:一个批次中图片的张数
2:图片的通道数
3:图片的高度H
4:图片的宽度W
"""
input_2d = torch.randn(size=(1,2,3,4))
# 2- 创建BN实例对象
"""
BatchNorm2d中的参数解释:
num_features:在处理图片的时候,每张图片的通道数
eps:小常数。为了防止分母为零
momentum:动量法的超参数
affine:该值通常是True。表示神经网络自己去学习得到λ和β
常见类的使用场景:
BatchNorm1d:主要用来处理文本类型的数据
BatchNorm2d:主要用来处理图片类型的数据
BatchNorm3d:主要用来处理视频类型的数据
"""
bn2d = torch.nn.BatchNorm2d(num_features=2, eps=1e-5,momentum=0.1,affine=True)
# 3- 处理数据
result = bn2d(input_2d)
print(f"公式中的λ:{bn2d.weight}")
print(f"公式中的β:{bn2d.bias}")
手机价格分类案例【掌握】
案例需求分析
小明创办了一家手机公司,他不知道如何估算手机产品的价格。为了解决这个问题,他收集了多家公司的手机销售数据。该数据为二手手机的各个性能的数据,最后根据这些性能得到4个价格区间,作为这些二手手机售出的价格区间。主要包括:

我们需要帮助小明找出手机的功能(例如:RAM等)与其售价之间的某种关系。我们可以使用机器学习的方法来解决这个问题,也可以构建一个全连接的网络。
需要注意的是: 在这个问题中,我们不需要预测实际价格,而是一个价格范围,它的范围使用 0、1、2、3 来表示,所以该问题也是一个分类问题。接下来我们还是按照四个步骤来完成这个任务:
- 准备训练集数据
- 构建要使用的模型
- 模型训练
- 模型预测评估
构建数据集
数据共有 2000 条, 其中 1600 条数据作为训练集, 400 条数据用作测试集。 我们使用 sklearn 的数据集划分工作来完成。并使用 PyTorch 的 TensorDataset 来将数据集构建为 Dataset 对象,方便构造数据集加载对象。
import pandas as pd
import torch
import torch.nn as nn
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset,DataLoader
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from torchsummary import summary # 计算模型参数个数
def create_dataset():
# 1- 读取数据
df = pd.read_csv("data/手机价格预测.csv",encoding="UTF-8")
# 2- 得到特征数据和目标值
x = df.iloc[:,:-1]
y = df.iloc[:,-1]
# 3- 划分得到训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=624,shuffle=True)
# print(type(x_train)) # DataFrame
# print(type(y_test)) # Series
# print(type(x_train.values)) # numpy.ndarray
# 4- 将数据转成Tensor张量
"""
深度学习中不支持直接将DataFrame对象转成Tensor张量。会报如下的错。需要调用values,转成numpy.ndarray
ValueError: could not determine the shape of object type 'DataFrame'
"""
x_train = torch.tensor(data=x_train.values,dtype=torch.float32)
x_test = torch.tensor(data=x_test.values,dtype=torch.float32)
y_train = torch.tensor(data=y_train.values,dtype=torch.long)
y_test = torch.tensor(data=y_test.values,dtype=torch.long)
# 5- 将Tensor张量封装成Dataset
train_dataset = TensorDataset(x_train,y_train)
test_dataset = TensorDataset(x_test,y_test)
# 6- 获得样本数据中特征的列数
feature_cnt = x.shape[1]
# 7- 获得样本数据中目标值的取值种类个数
target_cnt = len(np.unique(y))
# 8- 返回
return train_dataset,test_dataset,feature_cnt,target_cnt
构建分类网络模型
构建全连接神经网络来进行手机价格分类,该网络主要由三个线性层来构建,使用relu激活函数。
网络共有 3 个全连接层, 具体信息如下:
第一层: 输入为维度为 20, 输出维度为: 128
第二层: 输入为维度为 128, 输出维度为: 256
第三层: 输入为维度为 256, 输出维度为: 4
"""
自定义神经网络模型的开发步骤
1- 定义一个类继承自nn.Module
2- 实现__init__魔法方法
2.1- 初始化父类
2.2- 定义神经网络结构,隐藏层、输出层
2.3- 【可选】参数初始化
3- 实现forward方法:注意方法名称不要写错
将训练集的特征数据传递进去,前向传播依次经过隐藏层和输出层对模型进行训练,得到预测结果
"""
class PhoneClassifierModel(nn.Module):
def __init__(self,feature_cnt,target_cnt):
# 1- 初始化父类
super().__init__()
# 2- 定义神经网络结构
# 2.1- 第一层隐藏层
# 注意:第一层隐藏层的in_features 等于 输入样本中特征的列数
self.hidden_linear1 = nn.Linear(in_features=feature_cnt,out_features=128)
# 2.2- 第二层隐藏层
self.hidden_linear2 = nn.Linear(in_features=128,out_features=256)
# 2.3- 输出层
self.out_linear = nn.Linear(in_features=256,out_features=target_cnt)
def forward(self,x):
"""
前向传播。输入特征数据给到输入层,数据依次经过隐藏层,到达输出层,得到预测结果
:param x: 训练集的特征数据
:return: 预测结果
"""
# 1- 调用第一层隐藏层
x = torch.relu(self.hidden_linear1(x))
# 2- 调用第二层隐藏层
x = torch.relu(self.hidden_linear2(x))
# 3- 调用输出层
"""
目前是分类问题,后面在模型训练的时候,计划使用CrossEntropyLoss损失函数,该损失函数中自带softmax激活函数功能,因此
输出层中可以不用调用softmax激活函数
"""
output = self.out_linear(x)
return output
if __name__ == '__main__':
# 1- 准备数据
train_dataset,test_dataset,feature_cnt,target_cnt = create_dataset()
# print(f"特征的列数:{feature_cnt}")
# 2- 查看神经网络的参数个数信息
model =PhoneClassifierModel(feature_cnt,target_cnt)
summary(model,input_size=(feature_cnt,))

模型训练
网络编写完成之后,我们需要编写训练函数。所谓的训练函数,指的是输入数据读取、送入网络、计算损失、更新参数的流程,该流程较为固定。我们使用的是多分类交叉生损失函数、使用 SGD 优化方法。最终,将训练好的模型持久化到磁盘中。
# 模型训练
def train_model(train_dataset,feature_cnt,target_cnt):
# 1- 创建数据加载器
# 参数解释:shuffle表示是否打散数据,模型训练的时候推荐设置为True,模型预测的时候推荐设置为False
dataloader = DataLoader(dataset=train_dataset,batch_size=8,shuffle=True)
# 2- 创建类的实例对象
# 2.1- 算法模型实例对象
model = PhoneClassifierModel(feature_cnt,target_cnt)
# 2.2- 损失函数对象
loss = nn.CrossEntropyLoss()
# 2.3- 优化器对象
optimizer = torch.optim.SGD(params=model.parameters(), lr=1e-4)
# 3- 设置模式
# model.train():训练过程中,允许神经元失活
model.train()
# 4- 模型训练
epochs = 50 # 轮次
avg_loss_list = [] # 存储每个轮次的平均损失
# 4.1- 外层循环控制轮次
for epoch in range(epochs):
total_loss_value = 0.0 # 每个轮次的总损失
total_sample_cnt = 0 # 每个轮次的总样本条数
# 4.2- 内层循环控制批次
for x_train,y_train in tqdm(dataloader):
# 4.3- 前向传播
y_pred = model(x_train)
# 4.4- 计算损失值
# print(f"预测结果的张量形状:{y_pred.shape}")
# print(f"真实结果的张量形状:{y_train.shape}")
"""
注意:这里不要调用y_train.reshape(-1,1),因为是CrossEntropyLoss损失函数对象。如果调用了reshape,那么会报错
RuntimeError: 0D or 1D target tensor expected, multi-target not supported
错误解释:期望真实值的张量形状是0维或1维
"""
loss_value = loss(y_pred,y_train)
# 4.5- 更新损失值的信息
total_loss_value += loss_value.item()
total_sample_cnt += len(y_train)
# 4.6- 反向传播固定代码
optimizer.zero_grad() # 梯度清零
loss_value.sum().backward() # 反向传播
optimizer.step() # 更新参数:内部就会基于梯度下降公式,对w和b进行更新
avg_loss = total_loss_value / total_sample_cnt
avg_loss_list.append(avg_loss)
print(f"第{epoch+1}轮次,平均损失为{avg_loss}")
# 5- 保存训练好的模型
# state_dict():将模型的内部状态信息保留下来,例如:w、b的值;优化器的配置参数值;梯度值等
torch.save(model.state_dict(), "./model/price.pkl")
# 6- 可视化展示损失值随轮次的变化过程
plt.plot(range(epochs),avg_loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid()
plt.show()
模型评估
使用训练好的模型,对未知的样本的进行预测的过程。我们这里使用前面单独划分出来的验证集来进行评估。
# 模型预测
def eval_model(test_dataset,feature_cnt,target_cnt):
# 1- 创建数据加载器
dataloader = DataLoader(dataset=test_dataset,batch_size=8,shuffle=False)
# 2- 加载训练好的模型
model = PhoneClassifierModel(feature_cnt,target_cnt)
model.load_state_dict(torch.load("./model/price.pkl"))
# 3- 设置模型的模式:评估/预测的时候,禁止神经元失活
model.eval()
# 4- 评估
"""
torch.no_grad():评估/预测的时候,禁止进行反向传播计算梯度值,也就是禁止模型对w和b进行更新。如果不加该代码,那么这个过程就相当于是在进行模型训练
"""
correct_cnt = 0 # 预测正确的总样本条数
with torch.no_grad():
for x_test,y_test in tqdm(dataloader):
# 4.1- 前向传播得到预测结果
y_pred = model(x_test)
# 4.2- 获得预测概率最高的那个值,该值就是最终的预测结果
y_pred_id = torch.argmax(y_pred,dim=-1)
# print(f"y_pred形状--->{y_pred.shape}")
# print(f"y_pred--->{y_pred}")
# print(f"y_pred--->{torch.softmax(y_pred, dim=-1)}")
# print(f"y_pred_id--->{y_pred_id}")
# print(f"y_test--->{y_test}")
# 4.3- 统计预测正确的样本条数
# print(y_pred_id==y_test)
# print((y_pred_id==y_test).sum())
correct_cnt += (y_pred_id==y_test).sum().item()
# 5- 计算准确率
correct_rate = correct_cnt / len(test_dataset)
print(f"预测的正确率是:{correct_rate}")
网络性能优化
我们前面的网络模型在测试集的准确率为: 0.64250, 我们可以通过以下方面进行调优:
- 对输入数据进行标准化
- 调整优化方法
- 调整学习率
- 增加Dropout/批量归一化层
- 增加网络层数、神经元个数
- 增加训练轮数
- 等等…
进行下如下调整:
- 优化方法由 SGD 调整为 Adam
- 学习率由 1e-3 调整为 1e-4
- 对数据进行标准化
- 增加网络深度, 即: 增加网络参数量
import pandas as pd
import torch
import torch.nn as nn
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from torch.utils.data import TensorDataset,DataLoader
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from torchsummary import summary # 计算模型参数个数
def create_dataset():
# 1- 读取数据
df = pd.read_csv("data/手机价格预测.csv",encoding="UTF-8")
# 2- 得到特征数据和目标值
x = df.iloc[:,:-1]
y = df.iloc[:,-1]
# 3- 划分得到训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2,random_state=624,shuffle=True)
# print(type(x_train)) # DataFrame
# print(type(y_test)) # Series
# print(type(x_train.values)) # numpy.ndarray
# 特征预处理:标准化
transformer = StandardScaler()
x_train = transformer.fit_transform(x_train)
x_test = transformer.transform(x_test)
# print(type(x_train)) # numpy.ndarray
# 4- 将数据转成Tensor张量
"""
StandardScaler处理后的数据类型就是numpy.ndarray,不需要调用values
"""
x_train = torch.tensor(data=x_train,dtype=torch.float32)
x_test = torch.tensor(data=x_test,dtype=torch.float32)
y_train = torch.tensor(data=y_train.values,dtype=torch.long)
y_test = torch.tensor(data=y_test.values,dtype=torch.long)
# 5- 将Tensor张量封装成Dataset
train_dataset = TensorDataset(x_train,y_train)
test_dataset = TensorDataset(x_test,y_test)
# 6- 获得样本数据中特征的列数
feature_cnt = x.shape[1]
# 7- 获得样本数据中目标值的取值种类个数
target_cnt = len(np.unique(y))
# 8- 返回
return train_dataset,test_dataset,feature_cnt,target_cnt
"""
自定义神经网络模型的开发步骤
1- 定义一个类继承自nn.Module
2- 实现__init__魔法方法
2.1- 初始化父类
2.2- 定义神经网络结构,隐藏层、输出层
2.3- 【可选】参数初始化
3- 实现forward方法:注意方法名称不要写错
将训练集的特征数据传递进去,前向传播依次经过隐藏层和输出层对模型进行训练,得到预测结果
"""
class PhoneClassifierModel(nn.Module):
def __init__(self,feature_cnt,target_cnt):
# 1- 初始化父类
super().__init__()
# 2- 定义神经网络结构
# 2.1- 第一层隐藏层
# 注意:第一层隐藏层的in_features 等于 输入样本中特征的列数
self.hidden_linear1 = nn.Linear(in_features=feature_cnt,out_features=128)
# 2.2- 第二层隐藏层
self.hidden_linear2 = nn.Linear(in_features=128,out_features=256)
# 2.3- 第三层隐藏层
self.hidden_linear3 = nn.Linear(in_features=256, out_features=512)
# 2.4- 第四层隐藏层
self.hidden_linear4 = nn.Linear(in_features=512, out_features=128)
# 2.5- Dropout随机失活层
self.dropout = nn.Dropout(p=0.1)
# 2.6- 输出层
self.out_linear = nn.Linear(in_features=128,out_features=target_cnt)
def forward(self,x):
"""
前向传播。输入特征数据给到输入层,数据依次经过隐藏层,到达输出层,得到预测结果
:param x: 训练集的特征数据
:return: 预测结果
"""
# 1- 调用第一层隐藏层
x = torch.relu(self.hidden_linear1(x))
# 2- 调用第二层隐藏层
x = torch.relu(self.hidden_linear2(x))
# 3- 调用第三层隐藏层
x = torch.relu(self.hidden_linear3(x))
# 4- 调用第四层隐藏层+随机失活
x = self.dropout(torch.relu(self.hidden_linear4(x)))
# 5- 调用输出层
"""
目前是分类问题,后面在模型训练的时候,计划使用CrossEntropyLoss损失函数,该损失函数中自带softmax激活函数功能,因此
输出层中可以不用调用softmax激活函数
"""
output = self.out_linear(x)
return output
# 模型训练
def train_model(train_dataset,feature_cnt,target_cnt):
# 1- 创建数据加载器
# 参数解释:shuffle表示是否打散数据,模型训练的时候推荐设置为True,模型预测的时候推荐设置为False
dataloader = DataLoader(dataset=train_dataset,batch_size=8,shuffle=True)
# 2- 创建类的实例对象
# 2.1- 算法模型实例对象
model = PhoneClassifierModel(feature_cnt,target_cnt)
# 2.2- 损失函数对象
loss = nn.CrossEntropyLoss()
# 2.3- 优化器对象
optimizer = torch.optim.Adam(params=model.parameters(),lr=1e-4,betas=(0.9, 0.999))
# 3- 设置模式
# model.train():训练过程中,允许神经元失活
model.train()
# 4- 模型训练
epochs = 50 # 轮次
avg_loss_list = [] # 存储每个轮次的平均损失
# 4.1- 外层循环控制轮次
for epoch in range(epochs):
total_loss_value = 0.0 # 每个轮次的总损失
total_sample_cnt = 0 # 每个轮次的总样本条数
# 4.2- 内层循环控制批次
for x_train,y_train in tqdm(dataloader):
# 4.3- 前向传播
y_pred = model(x_train)
# 4.4- 计算损失值
# print(f"预测结果的张量形状:{y_pred.shape}")
# print(f"真实结果的张量形状:{y_train.shape}")
"""
注意:这里不要调用y_train.reshape(-1,1),因为是CrossEntropyLoss损失函数对象。如果调用了reshape,那么会报错
RuntimeError: 0D or 1D target tensor expected, multi-target not supported
错误解释:期望真实值的张量形状是0维或1维
"""
loss_value = loss(y_pred,y_train)
# 4.5- 更新损失值的信息
total_loss_value += loss_value.item()
total_sample_cnt += len(y_train)
# 4.6- 反向传播固定代码
optimizer.zero_grad() # 梯度清零
loss_value.sum().backward() # 反向传播
optimizer.step() # 更新参数:内部就会基于梯度下降公式,对w和b进行更新
avg_loss = total_loss_value / total_sample_cnt
avg_loss_list.append(avg_loss)
print(f"第{epoch+1}轮次,平均损失为{avg_loss}")
# 5- 保存训练好的模型
# state_dict():将模型的内部状态信息保留下来,例如:w、b的值;优化器的配置参数值;梯度值等
torch.save(model.state_dict(), "./model/price.pkl")
# 6- 可视化展示损失值随轮次的变化过程
plt.plot(range(epochs),avg_loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid()
plt.show()
# 模型预测
def eval_model(test_dataset,feature_cnt,target_cnt):
# 1- 创建数据加载器
dataloader = DataLoader(dataset=test_dataset,batch_size=8,shuffle=False)
# 2- 加载训练好的模型
model = PhoneClassifierModel(feature_cnt,target_cnt)
model.load_state_dict(torch.load("./model/price.pkl"))
# 3- 设置模型的模式:评估/预测的时候,禁止神经元失活
model.eval()
# 4- 评估
"""
torch.no_grad():评估/预测的时候,禁止进行反向传播计算梯度值,也就是禁止模型对w和b进行更新。如果不加该代码,那么这个过程就相当于是在进行模型训练
"""
correct_cnt = 0 # 预测正确的总样本条数
with torch.no_grad():
for x_test,y_test in tqdm(dataloader):
# 4.1- 前向传播得到预测结果
y_pred = model(x_test)
# 4.2- 获得预测概率最高的那个值,该值就是最终的预测结果
y_pred_id = torch.argmax(y_pred,dim=-1)
# print(f"y_pred形状--->{y_pred.shape}")
# print(f"y_pred--->{y_pred}")
# print(f"y_pred--->{torch.softmax(y_pred, dim=-1)}")
# print(f"y_pred_id--->{y_pred_id}")
# print(f"y_test--->{y_test}")
# 4.3- 统计预测正确的样本条数
# print(y_pred_id==y_test)
# print((y_pred_id==y_test).sum())
correct_cnt += (y_pred_id==y_test).sum().item()
# 5- 计算准确率
correct_rate = correct_cnt / len(test_dataset)
print(f"预测的正确率是:{correct_rate}")
if __name__ == '__main__':
# 1- 准备数据
train_dataset,test_dataset,feature_cnt,target_cnt = create_dataset()
# print(f"特征的列数:{feature_cnt}")
# 2- 模型训练
train_model(train_dataset,feature_cnt,target_cnt)
# 3- 查看神经网络的参数个数信息
# model =PhoneClassifierModel(feature_cnt,target_cnt)
# summary(model,input_size=(feature_cnt,))
# 4- 模型评估
eval_model(test_dataset,feature_cnt,target_cnt)
图像基础知识
图像基本概念
图像是人类视觉的基础,是自然景物的客观反映,是人类认识世界和人类本身的重要源泉。“图”是物体反射或透射光的分布,“像“是人的视觉系统所接受的图在人脑中所形成的印象或认识,照片、绘画、剪贴画、地图、书法作品、手写汉字、传真、卫星云图、影视画面、X光片、脑电图、心电图等都是图像。
在计算机中,按照颜色和灰度的多少可以将图像分为四种基本类型。
二值图像
一幅二值图像的二维矩阵仅由0、1两个值构成,“0”代表黑色,“1”代白色。由于每一像素(矩阵中每一元素)取值仅有0、1两种可能,所以计算机中二值图像的数据类型通常为1个二进制位。二值图像通常用于文字、线条图的扫描识别(OCR)和掩膜图像的存储。
灰度图像
灰度图像矩阵元素的取值范围通常为[0,255]。因此其数据类型一般为8位无符号整数的(int8),这就是人们经常提到的256灰度图像。“0”表示纯黑色,“255”表示纯白色,中间的数字从小到大表示由黑到白的过渡色。二值图像可以看成是灰度图像的一个特例。
索引图像
索引图像的文件结构比较复杂,除了存放图像的二维矩阵外,还包括一个称之为颜色索引矩阵MAP的二维数组。MAP的大小由存放图像的矩阵元素值域决定,如矩阵元素值域为[0,255],则MAP矩阵的大小为256Ⅹ3,用MAP=[RGB]表示。MAP中每一行的三个元素分别指定该行对应颜色的红、绿、蓝单色值,MAP中每一行对应图像矩阵像素的一个灰度值,如某一像素的灰度值为64,则该像素就与MAP中的第64行建立了映射关系,该像素在屏幕上的实际颜色由第64行的[RGB]组合决定。也就是说,图像在屏幕上显示时,每一像素的颜色由存放在矩阵中该像素的灰度值作为索引通过检索颜色索引矩阵MAP得到。
真彩色RGB图像
RGB图像与索引图像一样都可以用来表示彩色图像。与索引图像一样,它分别用红(R)、绿(G)、蓝(B)三原色的组合来表示每个像素的颜色。但与索引图像不同的是,RGB图像每一个像素的颜色值(由RGB三原色表示)直接存放在图像矩阵中,由于每一像素的颜色需由R、G、B三个分量来表示,M、N分别表示图像的行列数,三个M x N的二维矩阵分别表示各个像素的R、G、B三个颜色分量。RGB图像的数据类型一般为8位无符号整形。注意:通道的顺序是 BGR 而不是 RGB。

图像类型 通道数 像素值范围 主要特点 常见用途 二值图像 1通道 0 或 1 每个像素只有黑与白两种值 形态学操作、二值化、轮廓检测 灰度图像 1通道 0 到 255 每个像素表示灰度(亮度) 图像预处理、物体检测、人脸识别 索引图像 1通道 0 到 255(索引) 像素值为颜色表的索引,颜色表决定实际颜色 存储压缩、较少颜色的图像表示 RGB图像 3通道(R、G、B) 0 到 255 每个像素由红、绿、蓝三个通道组成 普通彩色图像显示、图像处理与分析 简单的讲:图像是由像素点组成的,每个像素点的取值范围为: [0, 255] 。像素值越接近于0,颜色越暗,接近于黑色;像素值越接近于255,颜色越亮,接近于白色。
在深度学习中,我们使用的图像大多是彩色图,彩色图由RGB3个通道组成,如下图所示:
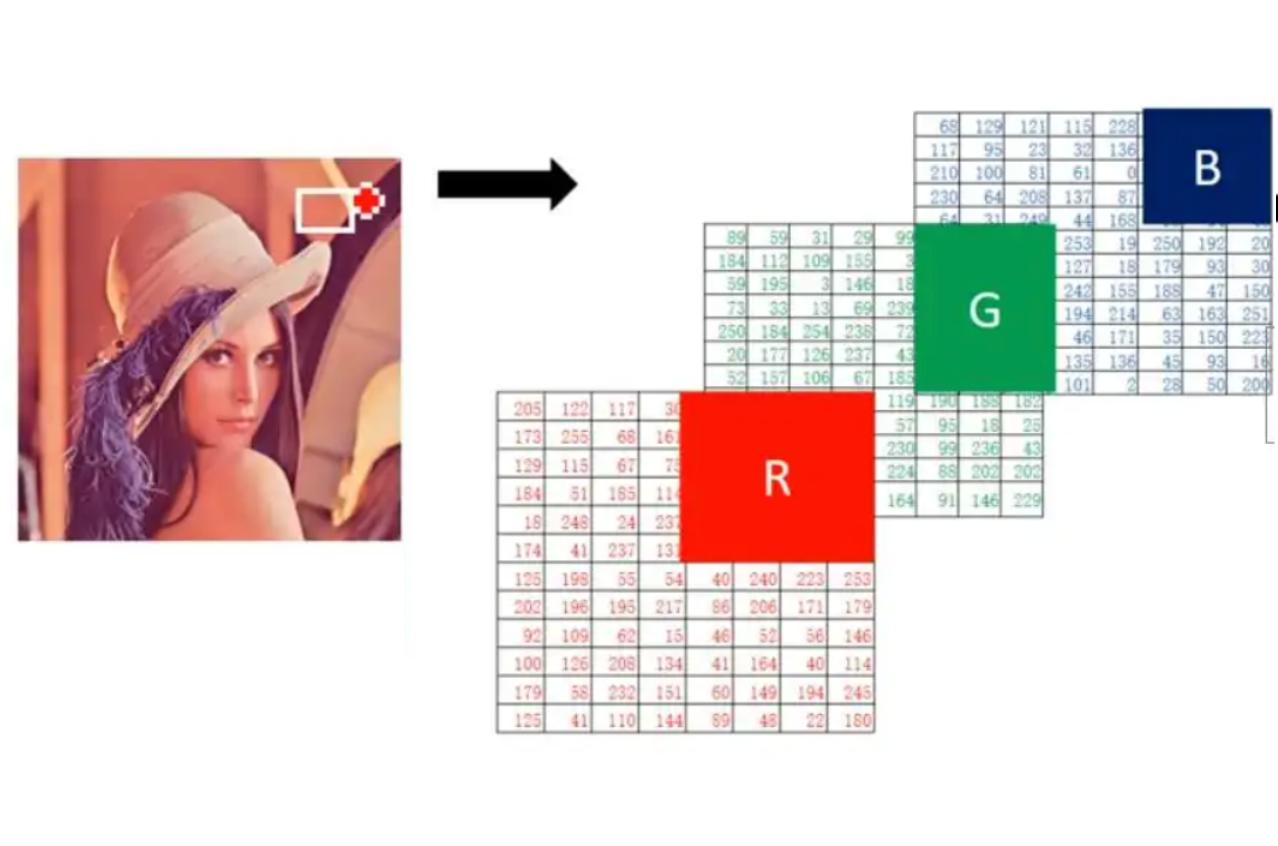
图像加载
使用 matplotlib 库来实际理解下上面讲解的图像知识。
import numpy as np
import matplotlib.pyplot as plt
def demo01():
# 绘制纯黑的图片
black_arr = np.zeros(shape=(200, 200, 3))
plt.imshow(black_arr)
plt.show()
# 绘制纯白的图片
white_arr = np.full(shape=(200, 200, 3), fill_value=255)
plt.imshow(white_arr)
# plt.axis("off")
plt.show()
# 绘制彩色的图片
color_arr = np.random.randint(low=0, high=256, size=(200, 200, 3))
plt.imshow(color_arr)
plt.show()
def demo02():
# 1- 读取图片
img_arr = plt.imread("data/img.jpg")
print(img_arr)
print(f"图片数组的形状:{img_arr.shape}") # (640, 640, 3) H高度 W宽度 C通道
# 2- 展示图片
plt.imshow(img_arr)
plt.imsave("data/img_copy.jpg",img_arr)
plt.show()
if __name__ == '__main__':
# demo01()
demo02()
输出结果:
全黑和全白图像:
图像的形状为:
图像的形状(H,W,C):
(640, 640, 3)

卷积神经网络概述
什么是卷积神经网络
卷积神经网络是深度学习在计算机视觉领域的突破性成果,专门用于处理图像、视频、语音等数据的神经网络
在计算机视觉领域, 往往我们输入的图像都很大,使用全连接网络的话,计算的代价较高。另外图像也很难保留原有的特征,导致图像处理的准确率不高。
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络。卷积层的作用就是用来自动学习、提取图像的特征。
CNN网络主要由三部分构成:卷积层、池化层和全连接层构成:
(1)卷积层负责提取图像中的局部特征
(2)池化层用来大幅降低参数量级(降维)
(3)全连接层类似人工神经网络的部分,用来输出想要的结果

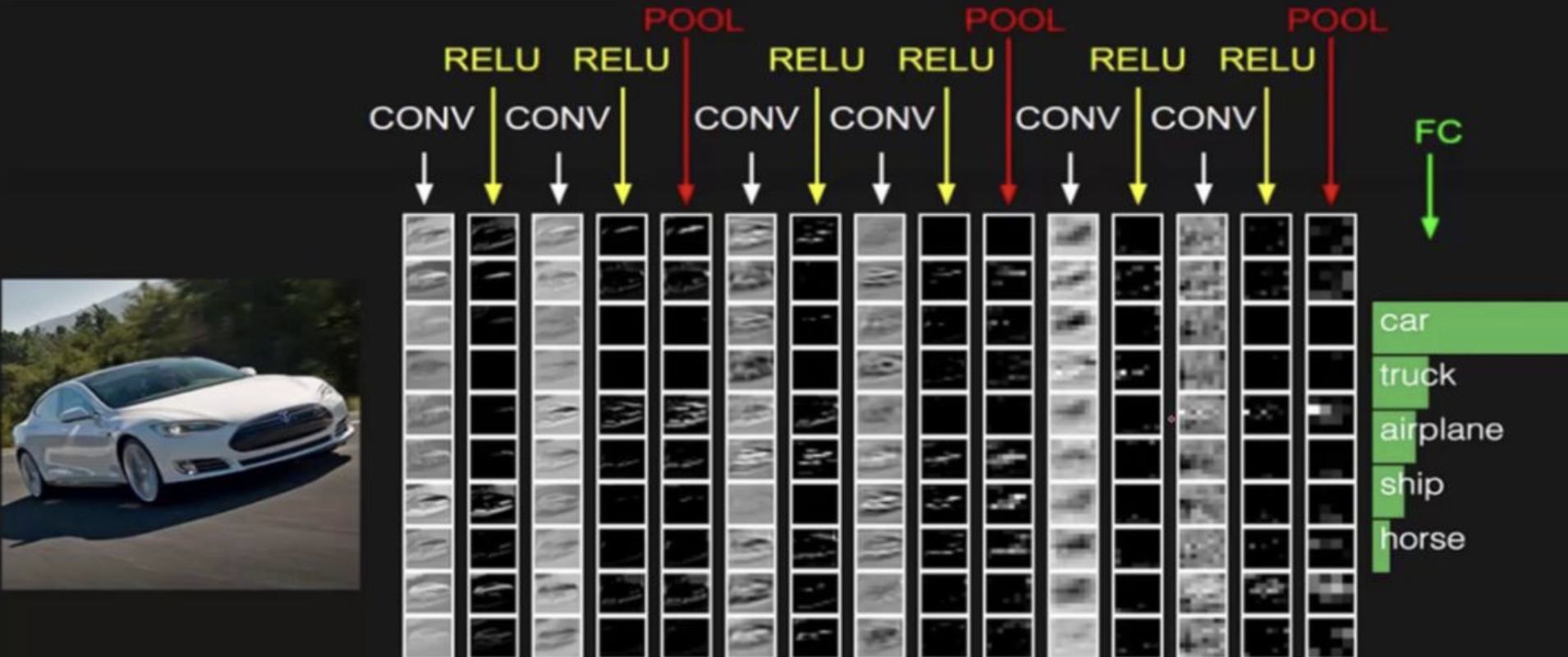
上图中CNN要做的事情是:给定一张图片,是车还是马未知,是什么车也未知,现在需要模型判断这张图片里具体是一个什么东西,总之输出一个结果:如果是车,那是什么车
- 最左边是
- 数据输入层:对数据做一些处理,比如取均值(各维度都减对应维度的均值,使得输入数据各个维度都中心化为0,避免数据过多偏差,影响训练效果)、归一化(把所有的数据都归一到同样的范围)、PCA等等。CNN只对训练集做“去均值”这一步。
- 中间是
- 卷积层(CONV):线性乘积求和,提取图像中的局部特征
- 激励层(RELU):ReLU激活函数,输入数据转换成输出数据
- 池化层(POOL):取区域平均值或最大值,大幅降低参数量级(降维)
- 最右边是
- 全连接层(FC):接收二维数据集,输出CNN模型预测结果
卷积神经网络应用
图像分类:最常见的应用,例如识别图片中的物体类别
目标检测:检测图像中物体的位置和类别
图像分割:将图像分成多个区域,用于语义分割
人脸识别:识别图像中的人脸
医学图像分析:用于检测医学图像中的异常(如癌症检测、骨折检测等)
自动驾驶:用于识别交通标志、车辆、行人
CNN中的经典算法/网络架构
**LeNet-5:**作为最早的CNN架构之一,证明了CNN在图像识别任务上的有效性,为后续的CNN发展奠定了基础
- 卷积层: 提取图像的边缘、角点等基本特征
- 池化层 (子采样层): 降低特征图的维度,减少计算量,并提高模型对输入图像微小变化的鲁棒性
- 全连接层: 将卷积层和池化层提取的特征进行组合,用于最终的分类
**AlexNet:**显著提升了ImageNet图像分类的准确率,证明了深度学习在计算机视觉领域的潜力,并推动了深度学习的快速发展
- 卷积层: 使用更大的卷积核和更多的卷积核,提取更丰富的图像特征
- ReLU激活函数: 加速训练过程,并提高模型的性能
- 最大池化层: 降低特征图的维度
- Dropout层: 防止过拟合
- 全连接层: 用于最终的分类
**VGGNet:**探索了网络深度对性能的影响,证明了更深的网络可以提取更抽象和更具表达力的特征
- 卷积层: 使用更小的卷积核 (3x3),并堆叠多个卷积层,增加了网络的深度,提取更复杂的特征
- 最大池化层: 降低特征图的维度
- 全连接层: 用于最终的分类
**GoogLeNet (Inception):**提出了 Inception 模块,在提高性能的同时减少了计算量,为后续的网络架构设计提供了新的思路
- Inception 模块: 并行使用不同大小的卷积核和池化操作,然后将它们的输出连接起来,增加了网络的宽度,提高了网络的效率
**ResNet:**解决了深度网络训练困难的问题,使得可以训练更深的网络,从而显著提高了模型的性能
- 残差块 (Residual Block): 引入跳跃连接 (Shortcut Connection),允许梯度直接反向传播到浅层,解决了深度网络的梯度消失问题,使得训练非常深的网络成为可能
DenseNet:
- 密集块 (Dense Block): 将每一层都与之前的所有层连接,特征重用更加充分,进一步提高了网络的性能和参数效率
- DenseNet通过密集连接(Dense Connectivity)在网络中各层之间建立了直接的连接,即每一层都接收前面所有层的输出作为输入。这种设计增强了特征传递和梯度流动,避免了梯度消失问题,并提高了信息的利用率
卷积层
卷积层(Convolutional Layer)通过卷积操作提取输入数据中的特征(例如图像中的边缘、纹理、形状等)。
卷积层利用卷积核(滤波器)对输入进行处理,从而生成特征图(feature map),并且每个卷积层能够提取不同层次的特征,从低级特征(如边缘)到高级特征(如物体的形状)。
卷积层的主要作用如下:
特征提取:卷积层的主要作用是从输入图像中提取低级特征(如边缘、角点、纹理等)。通过多个卷积层的堆叠,网络能够逐渐从低级特征到高级特征(如物体的形状、区域等)进行学习。
权重共享:在卷积层中,同一个卷积核在整个输入图像上共享权重,这使得卷积层的参数数量大大减少,减少了计算量并提高了训练效率。
局部连接:卷积层中的每个神经元仅与输入图像的一个小局部区域相连,这称为局部感受野,这种局部连接方式更符合图像的空间结构,有助于捕捉图像中的局部特征。
空间不变性:由于卷积操作是局部的并且采用权重共享,卷积层在处理图像时具有平移不变性。也就是说,不论物体出现在图像的哪个位置,卷积层都能有效地检测到这些物体的特征。
卷积计算
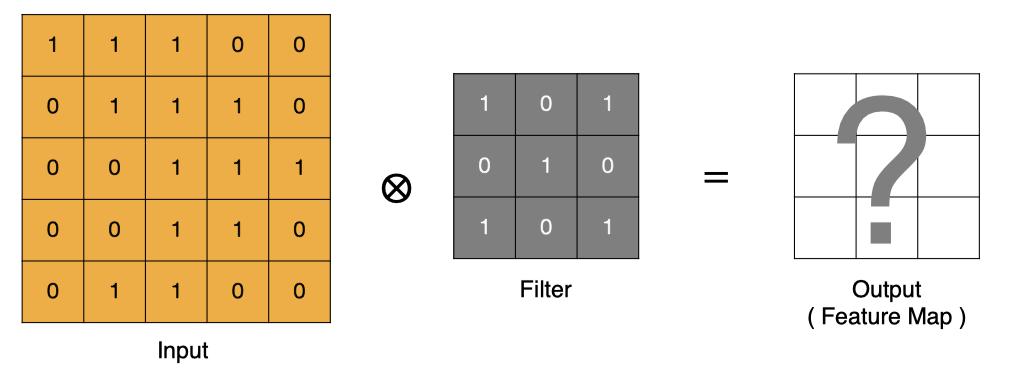
input 表示输入的图像
filter 表示卷积核, 也叫做滤波器(滤波矩阵)
- 一组固定的权重,因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter
- 非严格意义上来讲,下图中红框框起来的部分便可以理解为一个滤波器,即带着一组固定权重的神经元。多个滤波器叠加便成了卷积层
- 一个卷积核就是一个神经元
input 经过 filter 得到输出为最右侧的图像,该图叫做特征图
那么, 它是如何进行计算的呢?卷积运算本质上就是在滤波器和输入数据的局部区域间做点积。
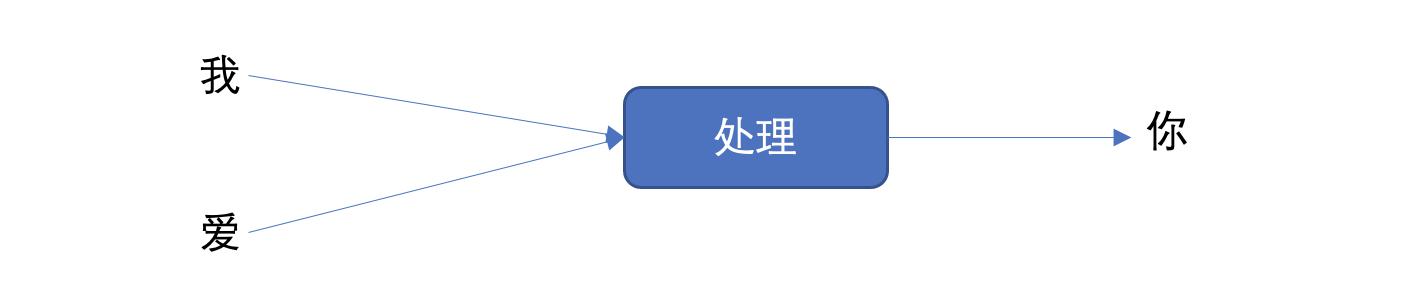
左上角的点计算方法:
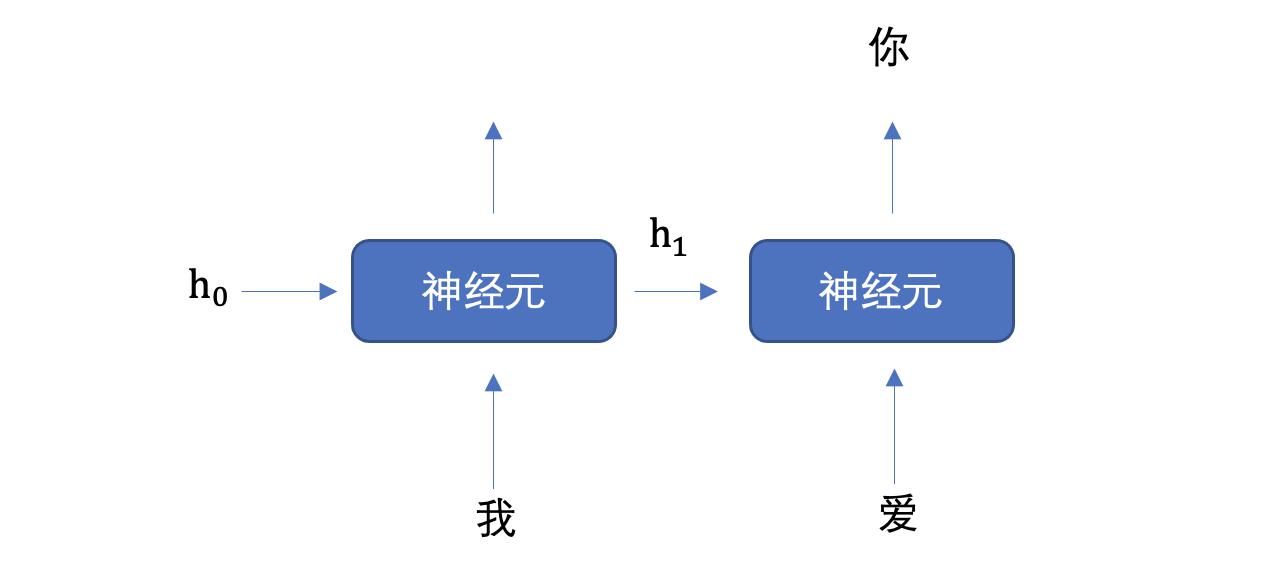
按照上面的计算方法可以得到最终的特征图为:
图像上的卷积:
在下图对应的计算过程中,输入是一定区域大小(width*height)的数据,和滤波器filter(带着一组固定权重的神经元)做内积后得到新的二维数据。
具体来说,左边是图像输入,中间部分就是滤波器filter(带着一组固定权重的神经元),不同的滤波器filter会得到不同的输出数据,比如颜色深浅、轮廓。相当于如果想提取图像的不同特征,则用不同的滤波器filter,提取想要的关于图像的特定信息:颜色深浅或轮廓。
Padding(填充)
Padding的作用: 图片中重点内容不一定在正中间,为了能够对图片四周的像素点也进行充分的特征提取,因此使用Padding在图片的四周进行填充。
通过上面的卷积计算过程,最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变, 可以在原图周围添加 Padding 来实现。
Padding(填充)操作是一种用于在输入特征图的边界周围添加额外像素(通常是零)。
Padding的主要作用:
- 保持空间维度:如果不使用 padding,每次卷积操作后,特征图的尺寸都会缩小。多次卷积后,特征图会变得非常小,可能会丢失重要的边缘信息。Padding可以帮助维持输出特征图的尺寸与输入相同或接近相同。
- 保留边缘信息:图像边缘的像素在卷积过程中参与的计算次数较少,这意味着边缘信息在特征提取过程中容易丢失。Padding通过在边缘添加额外的像素,增加了边缘像素的参与度,从而更好地保留了边缘信息。
- 提高性能:Padding有助于避免由于特征图尺寸快速缩小而导致的信息丢失,从而提高模型的性能,尤其是在处理较小的图像或需要进行多层卷积时。
Padding的类型:
- Valid Padding (No Padding): 不进行任何填充。卷积核只在输入图像的有效区域内滑动。输出尺寸会缩小。
- Same Padding: 添加足够的填充,使得输出特征图的尺寸与输入相同。
- Full Padding: 尽可能多地添加填充,使得卷积核的每个元素都至少在输入图像上滑动一次。输出尺寸会增大。
Padding的选择:取决于具体的应用场景和网络架构
- Valid Padding: 适用于不需要保持输出尺寸的场景,或者输入图像足够大,边缘信息丢失不重要的情况。
- Same Padding: 广泛应用于各种CNN架构中,因为它可以保持特征图的尺寸,方便网络设计和计算。
- Full Padding: 较少使用,因为它会增加计算量,并且可能会在边缘引入一些伪影。
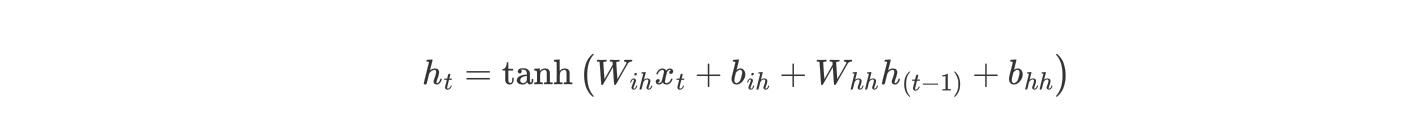
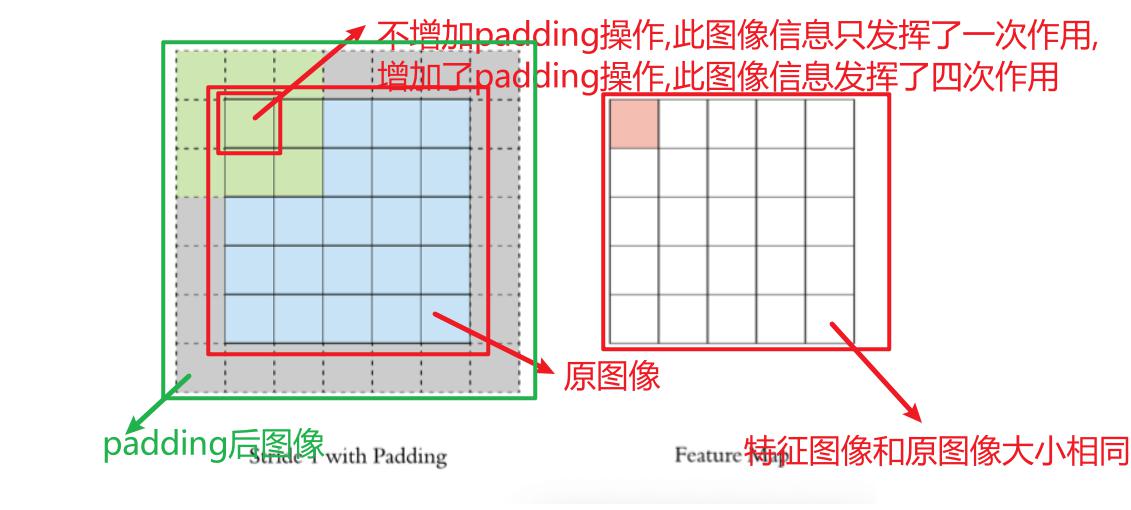
Stride(步长)
Stride(步长)指的是卷积核在图像上滑动时的步伐大小,即每次卷积时卷积核在图像中向右(或向下)移动的像素数。步长直接影响卷积操作后输出特征图的尺寸,以及计算量和模型的特征提取能力。
Stride的作用:
- 降低计算复杂度:更大的步长意味着卷积核移动的次数更少,从而减少了计算量,并加快了训练和推理速度。
- 减小特征图尺寸:步长越大,生成的特征图尺寸越小。这类似于池化的降维效果。
- 增大感受野:虽然更大的步长会减小特征图的尺寸,但它同时也会增大每个神经元在输入数据上的感受野。这意味着每个神经元能够捕捉到更大范围的输入信息。
Stride的选择:取决于具体的应用场景和网络架构
- Stride = 1: 这是最常见的设置,尤其是在网络的早期层。它允许保留更多的空间细节。
- Stride > 1: 通常用于减小特征图的尺寸和增大感受野,例如在网络的后期层或需要进行快速降维时。 常见的设置包括 stride=2 或 stride=4。
按照步长为1来移动卷积核,计算特征图如下所示:

如果把Stride增大为2,也是可以提取特征图的,如下图所示:

多通道卷积计算
实际中的图像都是多个通道组成的,我们怎么计算卷积呢?
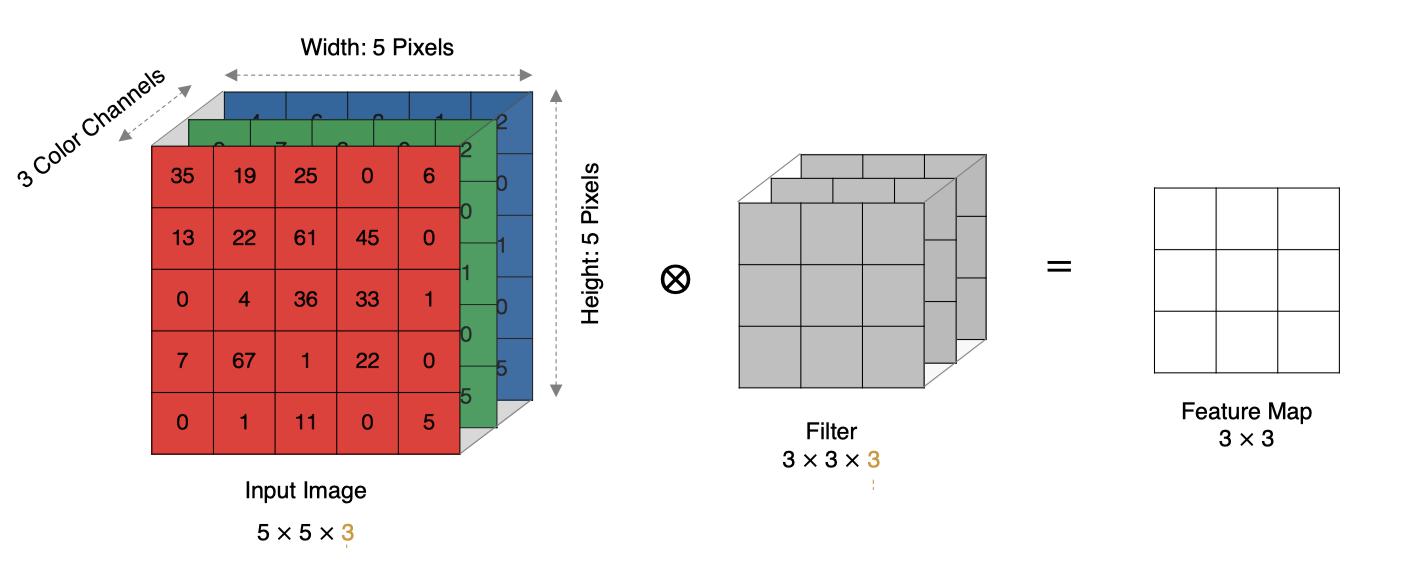
计算方法如下:
- 当输入有多个通道(Channel), 例如 RGB 三个通道, 此时要求卷积核需要拥有相同的通道数(图像有多少通道,每个卷积核就有多少通道).
- 每个卷积核通道与对应的输入图像的各个通道进行卷积.
- 将每个通道的卷积结果按位相加得到最终的特征图.
如下图所示:
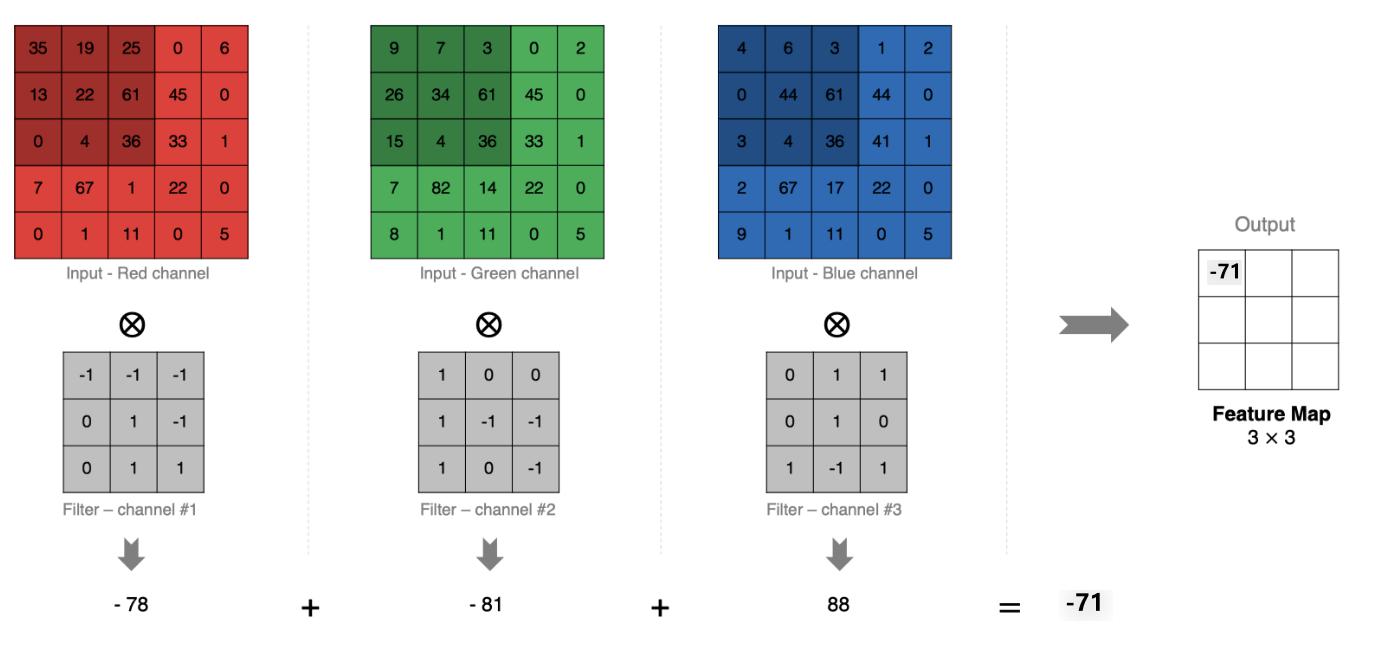
多卷积核卷积计算
上面的例子里我们只使用一个卷积核进行特征提取, 实际对图像进行特征提取时, 我们需要使用多个卷积核进行特征提取. 这个多个卷积核可以理解为从不同到的视角、不同的角度对图像特征进行提取.
那么, 当使用多个卷积核时, 应该怎么进行特征提取呢?
通过以下例子查看多卷积核卷积计算流程:
可以看到:
- 两个神经元,意味着有两个滤波器
- 数据窗口每次移动两个步长取3*3的局部数据,即stride=2
- zero-padding=1。输入数据由
5*5*3变为7*7*3 - 左边是输入(7*7*3中,7*7代表图像的像素/长宽,3代表R、G、B 三个颜色通道)
- 中间部分是两个不同的滤波器Filter w0、Filter w1
- 最右边则是两个不同的输出
特征图大小【掌握】
输出特征图的大小与以下参数息息相关:
- size: 卷积核/过滤器大小,一般会选择为奇数,比如有
1*1,3*3,5*5 - Padding: 零填充的方式
- Stride: 步长
那计算方法如下图所示:
- 输入图像大小: W x W
- 卷积核大小: F x F
- Stride: S
- Padding: P
- 输出图像大小: N x N
以下图为例:
- 图像大小: 5 x 5
- 卷积核大小: 3 x 3
- Stride: 1
- Padding: 1
- (5 - 3 + 2) / 1 + 1 = 5(如果除不尽向下取整), 即得到的特征图大小为: 5 x 5
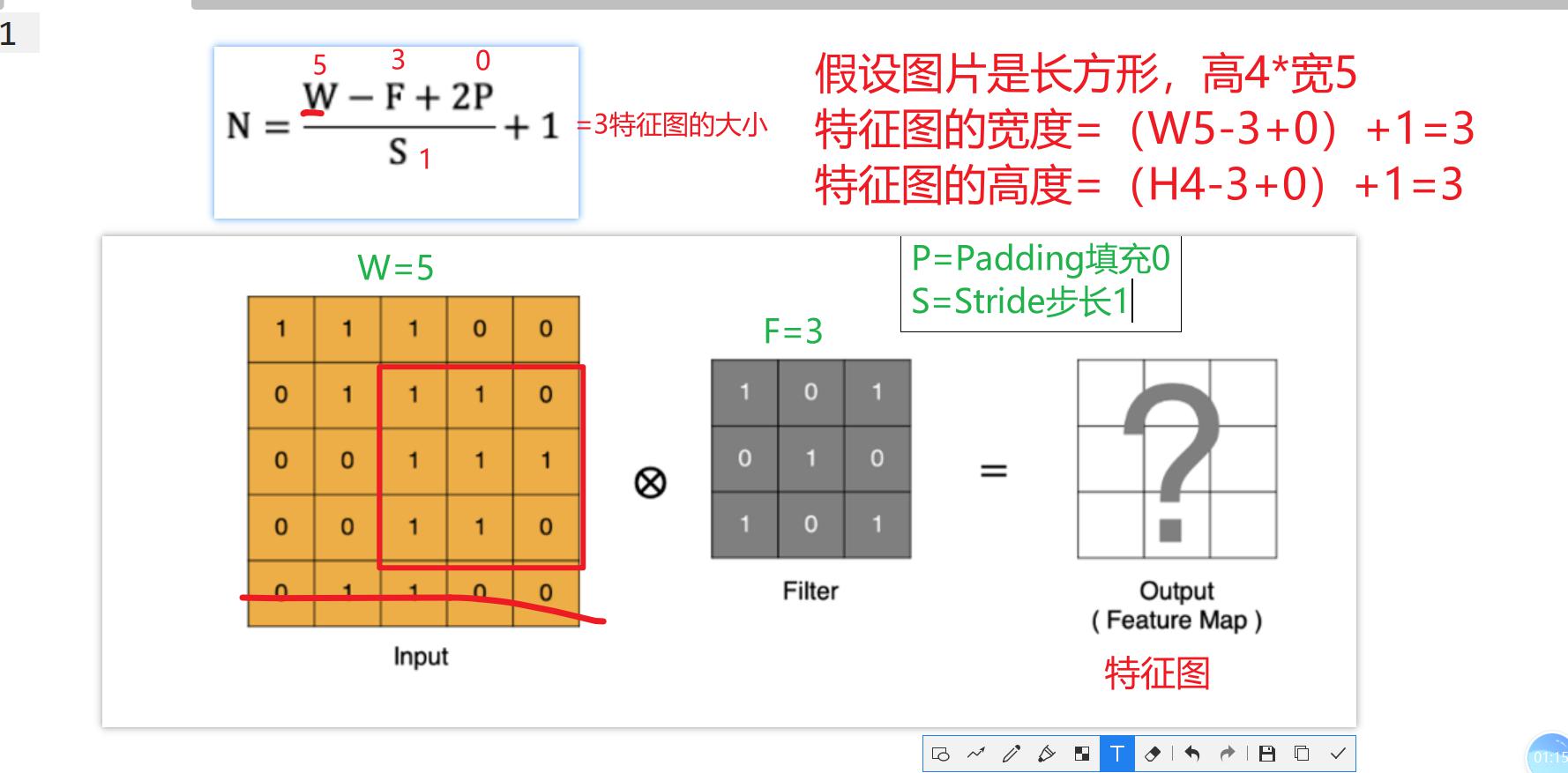
PyTorch卷积层API
在PyTorch中进行卷积的API是:
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
参数解释:
in_channels:输入的原始图片通道
out_channels:卷积处理后的图片通道,自定义。该该参数值也是卷积核的个数,同时也是特征图的个数。因为一个卷积核输出一个特征图
kernel_size:卷积核的大小。可以是一个数字,也可以是一个元祖。卷积核的大小一般是3*3、5*5、7*7、9*9、11*11
如果是一个数字,那么卷积核就是一个正方形
如果是一个元祖,那么高度、宽度不相等
stride:卷积核向右、向下移动的步长。可以是一个数字,也可以是一个元祖。一般是1-3之间
如果是一个数字,那么卷积核向右、向下移动的步长相等
如果是一个元祖,那么卷积核向右、向下移动的步长不相等
padding:原始图形的四周填充的圈数。一般是0-2之间
padding=0:不进行任何的填充
padding=数字:四周填充指定的圈数
padding="same":自适应。达到特征图的尺寸与原始图片的尺寸相同
我们接下来对下面的图片进行特征提取:

下面演示多通道多卷积核卷积:
"""
CNN卷积神经网络阶段性总结
1- 组成结构
输入层
隐藏层
卷积层
池化层
输出层
2- 卷积层处理图片前的流程如下
2.1- 原始图片的张量形状 [H高度,W宽度,C通道]
2.2- 处理前需要进行如下转换
[H高度,W宽度,C通道] -> [C通道,H高度,W宽度] -> [N图片的张数,C通道,H高度,W宽度]
原因:
1- 为什么将C提到前面:为了对图片的多个通道进行并行的特征提取
2- N图片的张数,理解为一个batch批次中图片的张数,也就是样本的条数
3- 卷积层处理图片后,如果要展示出来,它的流程如下:
[N图片的张数,C通道,H高度,W宽度] -> [C通道,H高度,W宽度] -> [H高度,W宽度,C通道]
"""
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch import Tensor
if __name__ == '__main__':
# 1- 读取图片
img_arr = plt.imread("data/img.jpg")
# print(img_arr)
# print(type(img_arr)) # numpy.ndarray
# print(img_arr.shape) # (640, 640, 3)
# 变成Tensor张量
img_tensor = torch.tensor(img_arr,dtype=torch.float32)
# 获得原始图片的通道数
original_channels = img_tensor.shape[-1]
# 2- 卷积层处理图片前的流程如下
# 2.1- 原始图片的张量形状调整
# [H高度,W宽度,C通道] -> [C通道,H高度,W宽度]
# 0 1 2 -> 2 0 1
permute_tensor = img_tensor.permute(dims=(2,0,1))
# print(permute_tensor.shape) # [3, 640, 640]
# 2.2- 增加批次信息
# [C通道,H高度,W宽度] -> [N图片的张数,C通道,H高度,W宽度]
unsqueeze_tensor = permute_tensor.unsqueeze(dim=0)
# print(unsqueeze_tensor.shape) # [1, 3, 640, 640]
# 3- 创建卷积层
"""
参数解释:
in_channels:输入的原始图片通道
out_channels:卷积处理后的图片通道,自定义。该该参数值也是卷积核的个数,同时也是特征图的个数。因为一个卷积核输出一个特征图
kernel_size:卷积核的大小。可以是一个数字,也可以是一个元祖。卷积核的大小一般是3*3、5*5、7*7、9*9、11*11
如果是一个数字,那么卷积核就是一个正方形
如果是一个元祖,那么高度、宽度不相等
stride:卷积核向右、向下移动的步长。可以是一个数字,也可以是一个元祖。一般是1-3之间
如果是一个数字,那么卷积核向右、向下移动的步长相等
如果是一个元祖,那么卷积核向右、向下移动的步长不相等
padding:原始图形的四周填充的圈数。一般是0-2之间
padding=0:不进行任何的填充
padding=数字:四周填充指定的圈数
padding="same":自适应。达到特征图的尺寸与原始图片的尺寸相同
"""
conv2d = nn.Conv2d(in_channels=original_channels, out_channels=5, kernel_size=3, stride=1, padding=0)
# 4- 调用卷积层,得到特征图
feature_maps:Tensor = conv2d(unsqueeze_tensor)
# (W-F+2P)/S + 1 = (640-3+2*0)/1 + 1 = 638
# print(feature_maps.shape) # [1,5,638,638]
# 5- 卷积层处理图片后,各个通道分别展示出来
# 5.1- 去掉批次信息
# [N图片的张数,C通道,H高度,W宽度] -> [C通道,H高度,W宽度]
squeeze_tensor = feature_maps.squeeze(dim=0)
# print(squeeze_tensor.shape) # [5,638,638]
# 5.2- 张量形状还原回图片的形状
# [C通道,H高度,W宽度] -> [H高度,W宽度,C通道]
# 0 1 2 -> 1 2 0
new_img_tensor = squeeze_tensor.permute(dims=(1,2,0))
print(new_img_tensor.shape) # [638,638,5]
# 5.3- 可视化展示
# 第一个通道
plt.imshow(new_img_tensor[:,:,0].data.numpy())
# print(new_img_tensor[:,:,0].shape) # [638,638],取第一个通道
plt.show()
# 第二个通道
plt.imshow(new_img_tensor[:, :, 1].data.numpy())
plt.show()
# 第三个通道
plt.imshow(new_img_tensor[:, :, 2].data.numpy())
plt.show()
# 第四个通道
plt.imshow(new_img_tensor[:, :, 3].data.numpy())
plt.show()
# 第五个通道
plt.imshow(new_img_tensor[:, :, 4].data.numpy())
plt.show()
生成特征图显示:
池化层
池化层总结:
1- 作用:对卷积层输出的特征图激活以后的数据进行降维(下采样)操作
2- 特点:池化层是一个无参数的操作,也就是不需要根据输入数据进行训练学习得到w权重、b偏置
3- 计算:实际工作中绝大多数情况使用的是最大池化
池化层(Pooling Layer)是用于降低输入数据的空间维度(例如图像的高度和宽度),从而减少计算量、减少内存消耗,并提高模型的鲁棒性。
池化层通常位于卷积层之后,它通过对卷积层输出的特征图进行下采样,保留最重要的特征信息,同时丢弃一些不重要的细节。
池化层的主要作用如下:
降维和计算量减少:池化层通过减少特征图的尺寸,从而降低了计算量,特别是在多层网络中,随着层数的增加,池化能够显著减少计算资源的消耗。
提高鲁棒性:池化操作可以使得特征对小的变换、平移和旋转变得更加不敏感。这样,模型在面对噪声或图像的轻微变化时,依然能够稳定工作。
防止过拟合:通过池化减少了特征图的大小,减少了模型的复杂度,从而有助于防止过拟合,尤其是在较小的数据集上。
抽象特征:通过池化层的操作,可以提取更为抽象和高层次的特征,使得网络能够学习到更具泛化能力的表示。
池化层计算
最大池化(Max Pooling) :通过池化窗口进行最大池化,取窗口中的最大值作为输出

平均池化(Avg Pooling) :取窗口内的所有值的均值作为输出
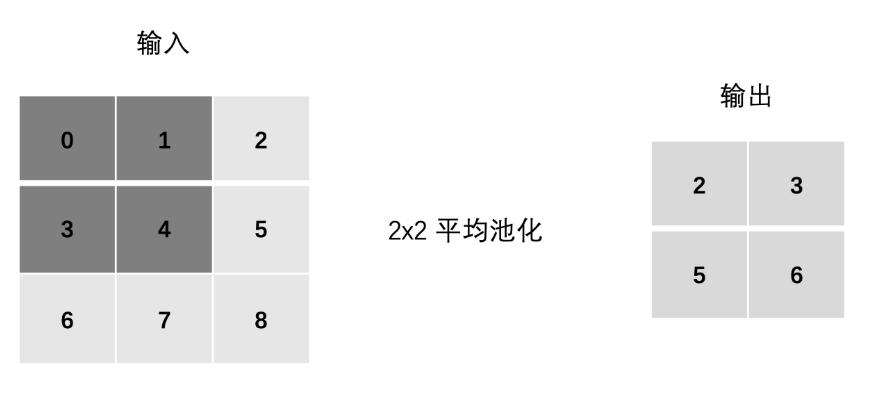
Padding(填充)
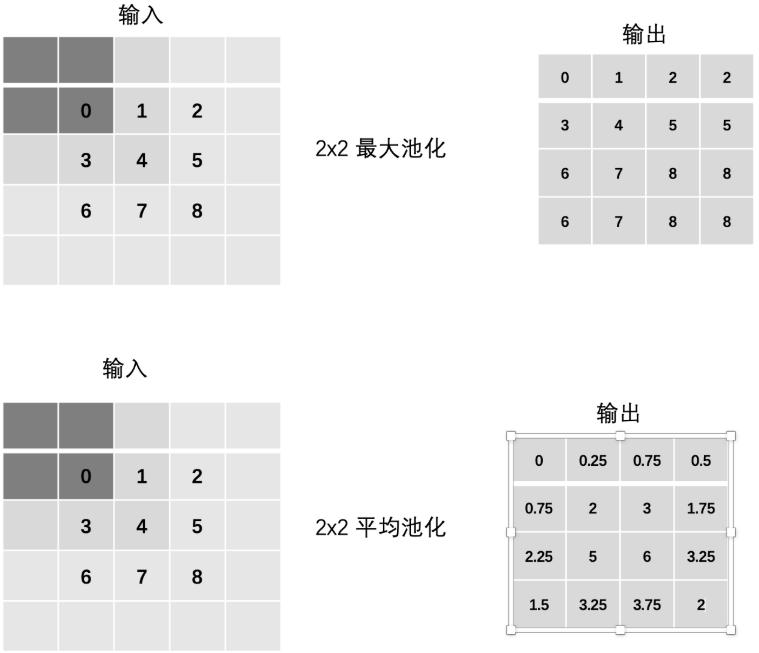
Stride(步长)
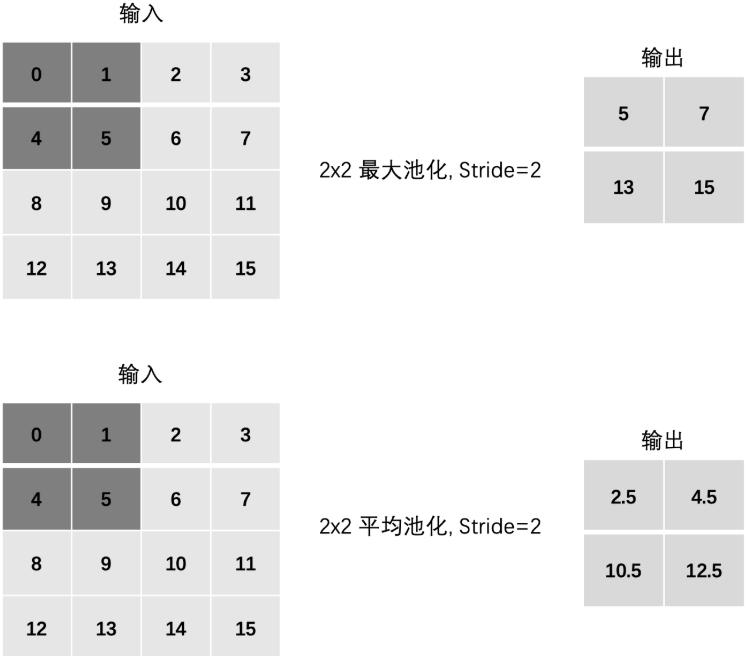
多通道池化计算
在处理多通道输入数据时,池化层对每个输入通道分别池化,而不是像卷积层那样将各个通道的输入相加。这意味着池化层的输出和输入的通道数是相等。
池化只在宽高维度上池化,在通道上是不发生池化(池化前后,多少个通道还是多少个通道)
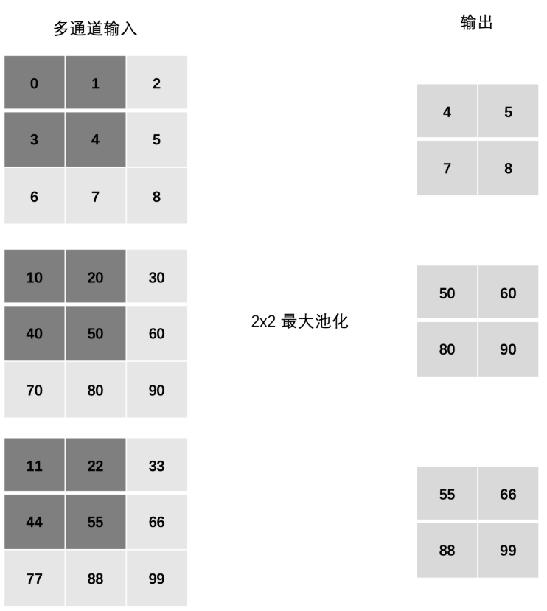
PyTorch池化层API
在PyTorch中进行池化的API是:
# 最大池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
# 平均池化
nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
"""
参数说明:
kernel_size:核的高和宽设置,一般为3,5,7...
stride:核移动的步长
padding:在四周加入padding的数量,默认补0
"""
"""
CNN卷积神经网络中,卷积层和池化层的区别
1- 卷积层:
作用:从原始图片中提取出特征
参数:该过程涉及模型需要训练得到参数w和b。卷积核中每个单元格就是一个w
2- 池化层:
作用:减少特征个数。一般跟在卷积层的后面。也就是对卷积以后得到的特征图中的特征值进行减少
参数:【重点】该过程只是一个非常简单的取最大值或算平均的过程,因此不涉及模型的任何参数
"""
import torch
import torch.nn as nn
# 单通道
def demo01():
torch.manual_seed(626)
# 1- 准备数据:卷积以后得到的特征图
img_data = torch.randint(low=0,high=10,size=(1,4,5), dtype=torch.float32)
print(f"卷积以后得到的特征图:{img_data}")
# 2- 池化过程
# 2.1- 最大池化
# 创建池化层对象
max_pool = nn.MaxPool2d(kernel_size=2,stride=1,padding=0)
# 调用池化
max_result = max_pool(img_data)
print(f"最大池化结果:{max_result}")
# 2.2- 平均池化
# 创建池化层对象
avg_pool = nn.AvgPool2d(kernel_size=2,stride=1,padding=0)
# 调用池化
avg_result = avg_pool(img_data)
print(f"平均池化结果:{avg_result}")
# 多通道
def demo02():
torch.manual_seed(626)
# 1- 准备数据:卷积以后得到的特征图
img_data = torch.randint(low=0,high=10,size=(3,4,5), dtype=torch.float32)
print(f"卷积以后得到的特征图:{img_data}")
# 2- 池化过程
# 2.1- 最大池化
# 创建池化层对象
max_pool = nn.MaxPool2d(kernel_size=2,stride=1,padding=0)
# 调用池化
max_result = max_pool(img_data)
print(f"最大池化结果:{max_result}")
# 2.2- 平均池化
# 创建池化层对象
avg_pool = nn.AvgPool2d(kernel_size=2,stride=1,padding=0)
# 调用池化
avg_result = avg_pool(img_data)
print(f"平均池化结果:{avg_result}")
if __name__ == '__main__':
# demo01()
demo02()
图像分类案例【理解】
咱们使用前面学习到的知识来构建一个卷积神经网络, 并训练该网络实现图像分类。要完成这个案例,咱们需要学习的内容如下:
了解 CIFAR10 数据集,对应的官网https://cave.cs.toronto.edu/kriz/cifar.html
搭建卷积神经网络
编写训练函数
编写预测函数
需要先安装torchvision
pip install torchvision==0.23.0 -i https://mirrors.aliyun.com/pypi/simple/
导入工具包
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10
from torchvision.transforms import ToTensor # pip install torchvision -i https://mirrors.aliyun.com/pypi/simple/
import torch.optim as optim
from torch.utils.data import DataLoader
import time
import matplotlib.pyplot as plt
from torchsummary import summary
CIFAR10 数据集
CIFAR-10数据集5万张训练图像、1万张测试图像、10个类别、每个类别有6k个图像,图像大小32×32×3。下图列举了10个类,每一类随机展示了10张图片:

PyTorch 中的 torchvision.datasets 计算机视觉模块封装了 CIFAR10 数据集, 使用方法如下:
import torch
import torch.nn as nn
from torchvision.datasets import CIFAR10 # 图片数据集
from torchvision.transforms import ToTensor # 将图片转成张量。张量的形状就是 [C通道数,H高度,W宽度]
import matplotlib.pyplot as plt
def create_dataset():
# 1- 加载图片数据
"""
参数解释:
root:CIFAR10压缩包所在的目录
download:如果root指定的目录中没有找到图片集的压缩包,就会在线下载
train:是否要加载训练集。True:加载训练集的图片;False:加载测试集的图片
transform:指定对图片进行什么样的处理转换。ToTensor()将图片由[H,W,C]转成[C,H,W]
"""
train_dataset = CIFAR10(root="data",download=True,train=True,transform=ToTensor())
test_dataset = CIFAR10(root="data",download=True,train=False,transform=ToTensor())
# 2- 返回结果
return train_dataset,test_dataset
if __name__ == '__main__':
# 1- 准备数据集Dataset
train_dataset,test_dataset = create_dataset()
# {'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
print("分类ID的信息:",train_dataset.class_to_idx)
print("查看某张图片的信息:",train_dataset[0])
print("查看某张图片的张量形状:",train_dataset[100][0].shape) # [3, 32, 32]
print("查看某张图片的类别ID:",train_dataset[100][1])
# 可视化展示某张图片
plt.imshow(train_dataset[100][0].permute(dims=(1,2,0)))
plt.title(train_dataset[100][1])
plt.show()
搭建图像分类网络
搭建的CNN网络结构如下:
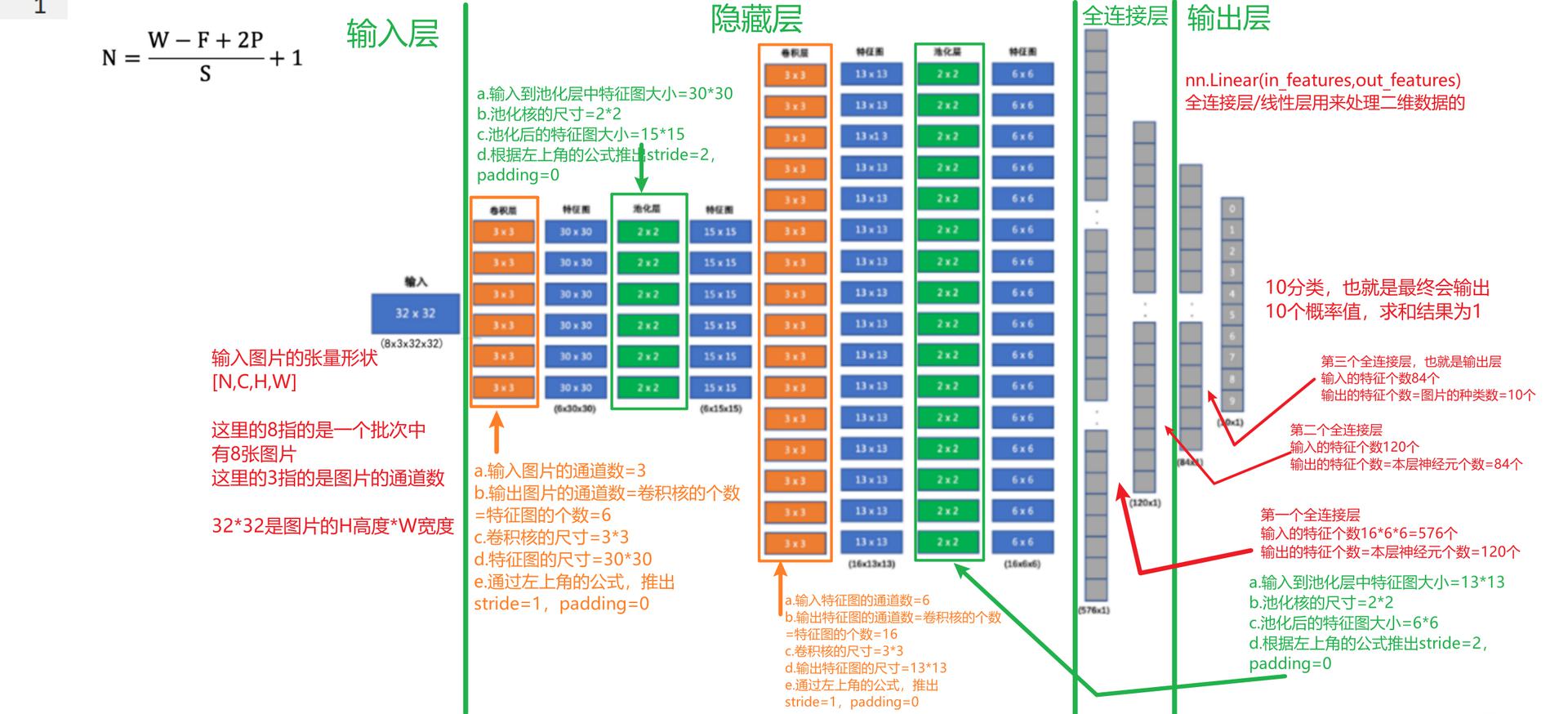
我们要搭建的网络结构如下:
- 输入形状: 32x32
- 第一个卷积层输入 3 个 Channel, 输出 6 个 Channel, Kernel Size 为: 3x3
- 第一个池化层输入 30x30, 输出 15x15, Kernel Size 为: 2x2, Stride 为: 2
- 第二个卷积层输入 6 个 Channel, 输出 16 个 Channel, Kernel Size 为 3x3
- 第二个池化层输入 13x13, 输出 6x6, Kernel Size 为: 2x2, Stride 为: 2
- 第一个全连接层输入 576 维, 输出 120 维
- 第二个全连接层输入 120 维, 输出 84 维
- 最后的输出层输入 84 维, 输出 10 维
我们在每个卷积计算之后应用 relu 激活函数来给网络增加非线性因素。
构建网络代码实现如下:
class PictureCNN(nn.Module):
def __init__(self):
# 1- 初始化父类
super().__init__()
# 2- 搭建网络结构
# 2.1- 第一套 卷积+池化
self.conv1 = nn.Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
# 2.2- 第二套 卷积+池化
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=0)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
# 2.3- 第一层全连接层
# 最后一层池化层的特征图通过reshape调整得到,576=16个特征图*(6池化后特征图的高度 * 6池化后特征图的宽度)
self.linear1 = nn.Linear(in_features=576,out_features=120)
# 2.4- 第二层全连接层
self.linear2 = nn.Linear(in_features=120, out_features=84)
# 2.5- 输出层
self.out_linear = nn.Linear(in_features=84, out_features=10)
def forward(self,x):
print("1-->",x.shape)
# 1- 第一套 卷积+池化。先卷积,再调用激活函数,最后进行池化
# 激活函数:不会改变张量的形状,只会改变值的大小
# x的形状就是 [N图片的张数,C通道,H高度,W宽度]
x = self.pool1(torch.relu(self.conv1(x)))
print("2-->", x.shape)
# 2- 第二套 卷积+池化
x = self.pool2(torch.relu(self.conv2(x)))
# 3- 第一层全连接层
# 注意:全连接层处理的是二维张量数据,因此要对池化后的结果进行降维,也就是4维降到2维
"""
x.shape[0]:获得 当前批次中图片的张量,也就是 N图片的张数
x.reshape(x.shape[0],-1)处理后的张量形状[N, C*H*W],C*H*W代表的是一张图片经过卷积、池化处理后的特征个数
注意:reshape的前提是调整前后的元素个数,不能发生变化
"""
print("3-->", x.shape)
x = x.reshape(x.shape[0],-1)
print("4-->", x.shape)
x = torch.relu(self.linear1(x))
# 4- 第二层全连接层
x = torch.relu(self.linear2(x))
# 5- 输出层
# 目前是一个分类场景,后面在模型训练的时候会调用CrossEntropyLoss,它自带Softmax
output = self.out_linear(x)
print("5-->", output.shape)
return output
if __name__ == '__main__':
# 1- 准备数据集Dataset
train_dataset,test_dataset = create_dataset()
# {'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
# print("分类ID的信息:",train_dataset.class_to_idx)
#
# print("查看某张图片的信息:",train_dataset[0])
# print("查看某张图片的张量形状:",train_dataset[100][0].shape) # [3, 32, 32]
# print("查看某张图片的类别ID:",train_dataset[100][1])
# 可视化展示某张图片
# plt.imshow(train_dataset[100][0].permute(dims=(1,2,0)))
# plt.title(train_dataset[100][1])
# plt.show()
# 2- 计算模型参数量
model = PictureCNN()
summary(model=model,input_size=(3,32,32),batch_size=1)
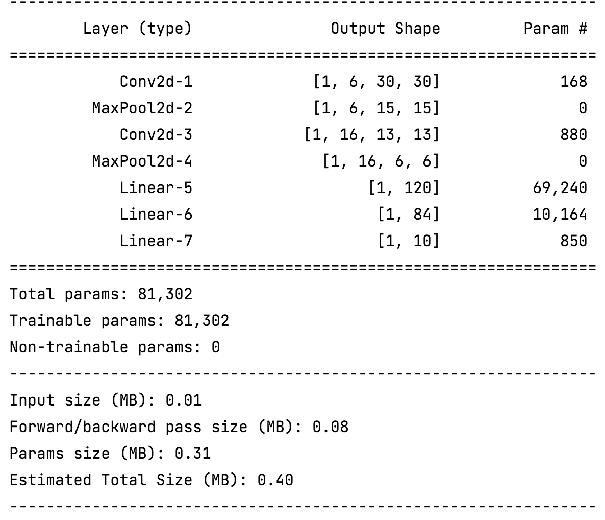
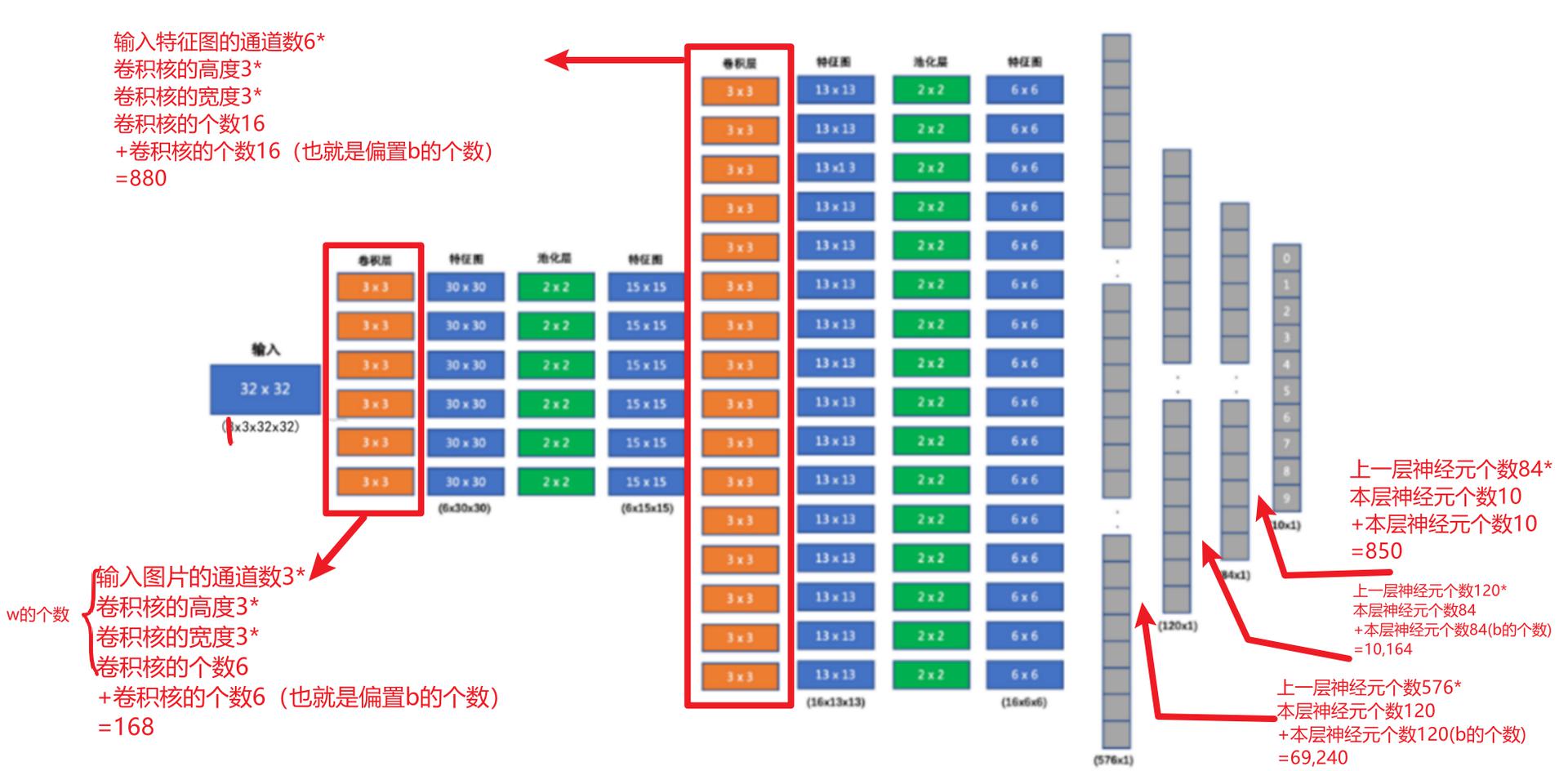
编写训练函数
在训练时,使用多分类交叉熵损失函数,Adam 优化器。具体实现代码如下:
def train_model(train_dataset):
# 1 - 创建DataLoader数据加载器
dataloader = DataLoader(dataset=train_dataset,batch_size=8,shuffle=True)
# 2 - 创建类的实例对象
# 2.1 - 算法模型实例对象
model = PictureCNN()
# 2.2 - 损失函数对象。例如:CrossEntropyLoss
loss = nn.CrossEntropyLoss()
# 2.3 - 优化器对象。例如:Adam
optimizer = torch.optim.Adam(params=model.parameters(),lr=1e-4,betas=(0.9, 0.999))
# 3 - 设置模式
model.train()
# 4 - 模型训练
epochs = 1
avg_loss_list = [] # 用来存储每个轮次的平均损失
# 4.1 - 外层循环控制轮次
for epoch in range(epochs):
total_loss_value = 0.0 # 每个轮次的总损失
total_sample_cnt = 0 # 每个轮次的总样本条数
# 4.2 - 内层循环控制批次
for x_train,y_train in tqdm(dataloader):
# 4.3 - 前向传播
y_predict = model(x_train)
# 4.4 - 计算损失
loss_value = loss(y_predict, y_train)
# 4.5 - 【可选】计算损失值相关的统计指标
total_loss_value += loss_value.item()
total_sample_cnt += len(y_train)
# 4.6 - 反向传播固定代码
optimizer.zero_grad()
loss_value.sum().backward()
optimizer.step()
# 此代码只是为了加快演示速度。实际工作中是没有
if total_sample_cnt>=8000:
break
# 4.7 - 【可选】输出损失值相关的统计指标
avg_loss = total_loss_value/total_sample_cnt
avg_loss_list.append(avg_loss)
print(f"第{epoch+1}轮次,平均损失{avg_loss}")
# 5 - 保存训练好的模型
torch.save(model.state_dict(),"model/picture_cnn.pkl")
# 6 - 绘制损失值和轮次的变化曲线
plt.plot(range(epochs),avg_loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid()
plt.show()
编写预测函数
加载训练好的模型,对测试集中的1万条样本进行预测,查看模型在测试集上的准确率。
def eval_model(test_dataset):
# 1 - 创建DataLoader数据加载器
dataloader = DataLoader(dataset=test_dataset,batch_size=8,shuffle=False)
# 2 - 加载训练好的模型
# 2.1 - 创建类的实例对象
model = PictureCNN()
# 2.2 - 加载模型
model.load_state_dict(torch.load("model/picture_cnn.pkl"))
# 3 - 设置模式
model.eval()
# 4 - 模型评估
correct_cnt = 0 # 预测正确的总样本条数
# 禁止模型进行反向传播梯度下降,也就是禁止更新参数
with torch.no_grad():
# 5 - 循环进行预测
for x_test,y_test in tqdm(dataloader):
# 5.1- 前向传播model(x_train)
y_predict = model(x_test)
# 5.2- 统计预测正确的样本条数
# 5.2.1- 取预测结果中最大值对应的索引
print(f"预测值-->{y_predict}-->{y_predict.shape}")
y_predict_id = torch.argmax(y_predict, dim=-1)
print(f"预测值-->{y_predict_id}-->{y_predict_id.shape}")
# 5.2.2- 统计预测正确的样本条数
correct_cnt += (y_predict_id==y_test).sum().item()
# 5.3- 输出评估指标。例如:准确率
rate = correct_cnt/len(test_dataset)
print(f"预测的总准确率{rate}")
完整代码
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10 # 图片数据集
from torchvision.transforms import ToTensor # 将图片转成张量。张量的形状就是 [C通道数,H高度,W宽度]
from torchsummary import summary
import matplotlib.pyplot as plt
from tqdm import tqdm
def create_dataset():
# 1- 加载图片数据
"""
参数解释:
root:CIFAR10压缩包所在的目录
download:如果root指定的目录中没有找到图片集的压缩包,就会在线下载
train:是否要加载训练集。True:加载训练集的图片;False:加载测试集的图片
transform:指定对图片进行什么样的处理转换。ToTensor()将图片由[H,W,C]转成[C,H,W]
"""
train_dataset = CIFAR10(root="data",download=True,train=True,transform=ToTensor())
test_dataset = CIFAR10(root="data",download=True,train=False,transform=ToTensor())
# 2- 返回结果
return train_dataset,test_dataset
# 搭建网络结构
class PictureCNN(nn.Module):
def __init__(self):
# 1- 初始化父类
super().__init__()
# 2- 搭建网络结构
# 2.1- 第一套 卷积+池化
self.conv1 = nn.Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1,padding=0)
self.pool1 = nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
# 2.2- 第二套 卷积+池化
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=0)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
# 2.3- 第一层全连接层
# 最后一层池化层的特征图通过reshape调整得到,576=16个特征图*(6池化后特征图的高度 * 6池化后特征图的宽度)
self.linear1 = nn.Linear(in_features=576,out_features=120)
# 2.4- 第二层全连接层
self.linear2 = nn.Linear(in_features=120, out_features=84)
# 2.5- 输出层
self.out_linear = nn.Linear(in_features=84, out_features=10)
def forward(self,x):
print("1-->",x.shape)
# 1- 第一套 卷积+池化。先卷积,再调用激活函数,最后进行池化
# 激活函数:不会改变张量的形状,只会改变值的大小
# x的形状就是 [N图片的张数,C通道,H高度,W宽度]
x = self.pool1(torch.relu(self.conv1(x)))
print("2-->", x.shape)
# 2- 第二套 卷积+池化
x = self.pool2(torch.relu(self.conv2(x)))
# 3- 第一层全连接层
# 注意:全连接层处理的是二维张量数据,因此要对池化后的结果进行降维,也就是4维降到2维
"""
x.shape[0]:获得 当前批次中图片的张量,也就是 N图片的张数
x.reshape(x.shape[0],-1)处理后的张量形状[N, C*H*W],C*H*W代表的是一张图片经过卷积、池化处理后的特征个数
注意:reshape的前提是调整前后的元素个数,不能发生变化
"""
print("3-->", x.shape)
x = x.reshape(x.shape[0],-1)
print("4-->", x.shape)
x = torch.relu(self.linear1(x))
# 4- 第二层全连接层
x = torch.relu(self.linear2(x))
# 5- 输出层
# 目前是一个分类场景,后面在模型训练的时候会调用CrossEntropyLoss,它自带Softmax
output = self.out_linear(x)
print("5-->", output.shape)
return output
# 模型训练
def train_model(train_dataset):
# 1 - 创建DataLoader数据加载器
dataloader = DataLoader(dataset=train_dataset,batch_size=8,shuffle=True)
# 2 - 创建类的实例对象
# 2.1 - 算法模型实例对象
model = PictureCNN()
# 2.2 - 损失函数对象。例如:CrossEntropyLoss
loss = nn.CrossEntropyLoss()
# 2.3 - 优化器对象。例如:Adam
optimizer = torch.optim.Adam(params=model.parameters(),lr=1e-4,betas=(0.9, 0.999))
# 3 - 设置模式
model.train()
# 4 - 模型训练
epochs = 1
avg_loss_list = [] # 用来存储每个轮次的平均损失
# 4.1 - 外层循环控制轮次
for epoch in range(epochs):
total_loss_value = 0.0 # 每个轮次的总损失
total_sample_cnt = 0 # 每个轮次的总样本条数
# 4.2 - 内层循环控制批次
for x_train,y_train in tqdm(dataloader):
# 4.3 - 前向传播
y_predict = model(x_train)
# 4.4 - 计算损失
loss_value = loss(y_predict, y_train)
# 4.5 - 【可选】计算损失值相关的统计指标
total_loss_value += loss_value.item()
total_sample_cnt += len(y_train)
# 4.6 - 反向传播固定代码
optimizer.zero_grad()
loss_value.sum().backward()
optimizer.step()
# 此代码只是为了加快演示速度。实际工作中是没有
if total_sample_cnt>=8000:
break
# 4.7 - 【可选】输出损失值相关的统计指标
avg_loss = total_loss_value/total_sample_cnt
avg_loss_list.append(avg_loss)
print(f"第{epoch+1}轮次,平均损失{avg_loss}")
# 5 - 保存训练好的模型
torch.save(model.state_dict(),"model/picture_cnn.pkl")
# 6 - 绘制损失值和轮次的变化曲线
plt.plot(range(epochs),avg_loss_list)
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid()
plt.show()
# 模型预测/评估
def eval_model(test_dataset):
# 1 - 创建DataLoader数据加载器
dataloader = DataLoader(dataset=test_dataset,batch_size=8,shuffle=False)
# 2 - 加载训练好的模型
# 2.1 - 创建类的实例对象
model = PictureCNN()
# 2.2 - 加载模型
model.load_state_dict(torch.load("model/picture_cnn.pkl"))
# 3 - 设置模式
model.eval()
# 4 - 模型评估
correct_cnt = 0 # 预测正确的总样本条数
# 禁止模型进行反向传播梯度下降,也就是禁止更新参数
with torch.no_grad():
# 5 - 循环进行预测
for x_test,y_test in tqdm(dataloader):
# 5.1- 前向传播model(x_train)
y_predict = model(x_test)
# 5.2- 统计预测正确的样本条数
# 5.2.1- 取预测结果中最大值对应的索引
print(f"预测值-->{y_predict}-->{y_predict.shape}")
y_predict_id = torch.argmax(y_predict, dim=-1)
print(f"预测值-->{y_predict_id}-->{y_predict_id.shape}")
# 5.2.2- 统计预测正确的样本条数
correct_cnt += (y_predict_id==y_test).sum().item()
# 5.3- 输出评估指标。例如:准确率
rate = correct_cnt/len(test_dataset)
print(f"预测的总准确率{rate}")
if __name__ == '__main__':
# 1- 准备数据集Dataset
train_dataset,test_dataset = create_dataset()
# {'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
# print("分类ID的信息:",train_dataset.class_to_idx)
#
# print("查看某张图片的信息:",train_dataset[0])
# print("查看某张图片的张量形状:",train_dataset[100][0].shape) # [3, 32, 32]
# print("查看某张图片的类别ID:",train_dataset[100][1])
# 可视化展示某张图片
# plt.imshow(train_dataset[100][0].permute(dims=(1,2,0)))
# plt.title(train_dataset[100][1])
# plt.show()
# 2- 计算模型参数量
# model = PictureCNN()
# summary(model=model,input_size=(3,32,32),batch_size=1)
# 3- 训练模型
# train_model(train_dataset)
# 4- 模型评估
eval_model(test_dataset)
模型优化
CNN网络模型在训练集样本上的准确率远远高于测试集,说明模型产生了过拟合问题,我们把学习率由1e-3修改为1e-4、增加网络参数量和增加dropout正则化
经过训练,模型在测试集的准确率由 0.61,提升到了 0.93,同学们也可以自己修改相应的网络结构、训练参数等来提升模型的性能。
循环神经网络RNN
RNN概念
循环神经网络(Recurrent Neural Network, RNN)是一种专门处理序列数据的神经网络。与传统的前馈神经网络不同,RNN具有“循环”结构,能够处理和记住前面时间步的信息,使其特别适用于时间序列数据或有时序依赖的任务。
我们要明确什么是序列数据,时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系。
RNN应用场景
- 自然语言处理(NLP):文本生成、语言建模、机器翻译、情感分析等。
- 时间序列预测:股市预测、气象预测、传感器数据分析等。
- 语音识别:将语音信号转换为文字。
- 音乐生成:通过学习音乐的时序模式来生成新乐曲。
自然语言处理概述
自然语言处理(Nature language Processing, NLP)研究的主要是通过计算机算法来理解自然语言。
对于自然语言来说,处理的数据主要就是人类的语言,例如:汉语、英语、法语等,该类型的数据不像我们前面接触过的结构化数据、或者图像数据可以很方便的进行数值化。
NLP的目标是让机器能够“听懂”和“读懂”自然语言,并进行有效的交流和分析。
NLP涵盖了从文本到语音、从语音到文本的各个方面,它涉及多种技术,包括语法分析、语义理解、情感分析、机器翻译等。
词嵌入层
在 RNN(Recurrent Neural Network) 中,词嵌入层(Word Embedding Layer) 是处理自然语言数据的关键组成部分。它将输入的离散单词(通常是词汇表中的索引)转换为连续的、低维的向量表示,从而使得神经网络能够理解和处理这些词汇的语义信息。
词嵌入层作用
词嵌入层的主要目的是将每个词映射为一个固定长度的向量(将文本转换为向量),这些向量能够捕捉词与词之间的语义关系。
传统的文本表示方法(如one-hot编码)无法反映单词之间的相似性,因为在one-hot编码中,每个单词都被表示为一个高维稀疏向量,而词嵌入通过低维稠密向量表示单词,能够更好地捕捉词汇之间的语义相似性。
词嵌入层首先会根据输入的词的数量构建一个词向量矩阵,例如: 我们有 100 个词,每个词希望转换成 128 维度的向量,那么构建的矩阵形状即为: 100*128,输入的每个词都对应了一个该矩阵中的一个向量。
词嵌入层在RNN中的作用:
- 输入表示:RNN通常用于处理序列数据。在处理文本时,RNN的输入是由单词构成的序列。由于神经网络不能直接处理离散的单词标识符(如整数索引或字符),因此需要通过词嵌入层将每个单词转换为一个固定长度的稠密向量。这些向量作为RNN的输入,帮助RNN理解词语的语义。
- 降低维度:词嵌入层将原本高维的稀疏表示(如one-hot编码)转化为低维的稠密向量,减少了计算量,同时保持了词汇之间的语义关系。
- 捕捉语义相似性:通过训练,词嵌入能够学习到词语之间的关系。例如,语义相似的词(如“猫”和“狗”)在向量空间中会比较接近,而语义不相关的词(如“猫”和“汽车”)则会较为遥远。
词嵌入层工作流程

分词器的使用
- 安装分词器
pip install jieba -i https://pypi.mirrors.ustc.edu.cn/simple/
- 代码示例
import jieba
if __name__ == '__main__':
content = "北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。"
# 1- 方式一:掌握
"""
解释:lcut:将分词后的结果转成List列表
"""
result = jieba.lcut(content)
print(result)
print(type(result))
# 2- 方式二:了解。结果不是List列表,而是生成器对象
result = jieba.cut(content)
print(result)
print(type(result))
# 3- 方式三:了解。
result = jieba.lcut_for_search(content)
print(result)
print(type(result))
词嵌入层使用
在PyTorch中,我们可以使用 nn.Embedding 词嵌入层来实现输入词的向量化。
nn.Embedding 对象构建时,最主要有两个参数:
num_embeddings:表示词的数量
embedding_dim:表示用多少维的向量来表示每个词
nn.Embedding(num_embeddings=10, embedding_dim=4)
接下来,我们将会学习如何将词转换为词向量,其步骤如下:
- 先将语料进行分词,构建词与索引的映射,我们可以把这个映射叫做词表,词表中每个词都对应了一个唯一的索引;
- 然后使用 nn.Embedding 构建词嵌入矩阵,词索引对应的向量即为该词对应的数值化后的向量表示。
例如,我们的文本数据为: “北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。”,接下来,我们看下如何使用词嵌入层将其进行转换为向量表示,步骤如下:
import jieba
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1- 准备数据
content = "北京冬奥的进度条已经过半,不少外国运动员在完成自己的比赛后踏上归途。"
# 2- 分词->去重->词汇表
# 2.1- 分词
word_list = jieba.lcut(content)
# 2.2- 去重;词汇表
word_dict = {} # key:词;value:词索引
for word in word_list:
# 下面的两种判断是否存在的方式都可以
if not word_dict.__contains__(word):
# if word not in word_dict:
word_dict[word] = len(word_dict)
# print(word_dict)
# 3- 创建词嵌入层
"""
参数解释:
num_embeddings:词汇表中词的个数
embedding_dim:词向量的维度。也就是向量中数值的个数。实际工作中该值一般是128、256、512、1024
"""
ebd = nn.Embedding(num_embeddings=len(word_dict),embedding_dim=5)
# 4- 获得每个词的词向量
for word,index in word_dict.items():
# print(f"{word}-->{index}")
word_vector = ebd(torch.tensor(index))
print(f"{word}-->{index}-->{word_vector}")
输出结果:
北京-->0-->tensor([ 1.8365, -1.1930, -0.7671, -0.0263, -0.9620],
grad_fn=<EmbeddingBackward0>)
冬奥-->1-->tensor([-2.2175, 1.1294, 1.0134, -1.4473, -0.5877],
grad_fn=<EmbeddingBackward0>)
的-->2-->tensor([ 0.8060, 1.9055, 1.0596, -1.7156, -0.0680],
grad_fn=<EmbeddingBackward0>)
进度条-->3-->tensor([-2.3712, -0.9855, -0.0962, -0.1724, 1.7630],
grad_fn=<EmbeddingBackward0>)
已经-->4-->tensor([-0.2547, -0.0923, 1.0898, 1.9266, -0.8104],
grad_fn=<EmbeddingBackward0>)
过半-->5-->tensor([ 0.1004, -0.6968, -0.4914, 1.0362, -0.8456],
grad_fn=<EmbeddingBackward0>)
,-->6-->tensor([ 0.5707, 1.7843, -0.0986, 0.7991, 0.2735],
grad_fn=<EmbeddingBackward0>)
不少-->7-->tensor([ 0.3971, 1.8092, -0.4077, 0.7398, 0.1181],
grad_fn=<EmbeddingBackward0>)
外国-->8-->tensor([-1.1708, 0.3971, -0.2811, 2.9349, 1.2779],
grad_fn=<EmbeddingBackward0>)
运动员-->9-->tensor([-0.2668, 0.1465, 0.4595, 0.5848, -1.3521],
grad_fn=<EmbeddingBackward0>)
在-->10-->tensor([ 0.6567, -0.0350, 1.5159, -0.8919, 1.3033],
grad_fn=<EmbeddingBackward0>)
完成-->11-->tensor([-0.8162, -0.6269, -1.6094, 0.8972, -1.3617],
grad_fn=<EmbeddingBackward0>)
自己-->12-->tensor([-0.6450, -1.3022, -0.8917, -0.9443, -1.1941],
grad_fn=<EmbeddingBackward0>)
比赛-->13-->tensor([ 0.3863, 1.0043, -1.3108, -0.2949, -0.5909],
grad_fn=<EmbeddingBackward0>)
后-->14-->tensor([ 2.1033, 0.4528, -0.2645, -0.1123, -0.9049],
grad_fn=<EmbeddingBackward0>)
踏上-->15-->tensor([-0.3240, -1.7451, -1.1242, 0.2082, -0.7655],
grad_fn=<EmbeddingBackward0>)
归途-->16-->tensor([ 0.2559, -1.7731, 0.5060, -0.0252, 0.2032],
grad_fn=<EmbeddingBackward0>)
。-->17-->tensor([-0.0091, -0.7264, -0.4198, 0.1622, -0.9622],
grad_fn=<EmbeddingBackward0>)
循环网络层【重点】
文本数据是具有序列特性的,例如: “我爱你”, 这串文本就是具有序列关系的,”爱” 需要在 “我” 之后,”你” 需要在 “爱” 之后, 如果颠倒了顺序,那么可能就会表达不同的意思。
为了表示出数据的序列关系,我们需要使用循环神经网络(Recurrent Nearal Networks, RNN) 来对数据进行建模,RNN 是一个具有记忆功能的网络,它作用于处理带有序列特点的样本数据。
RNN网络层原理
当我们希望使用循环网络来对 “我爱你” 进行语义提取时,RNN计算过程是什么样的呢?
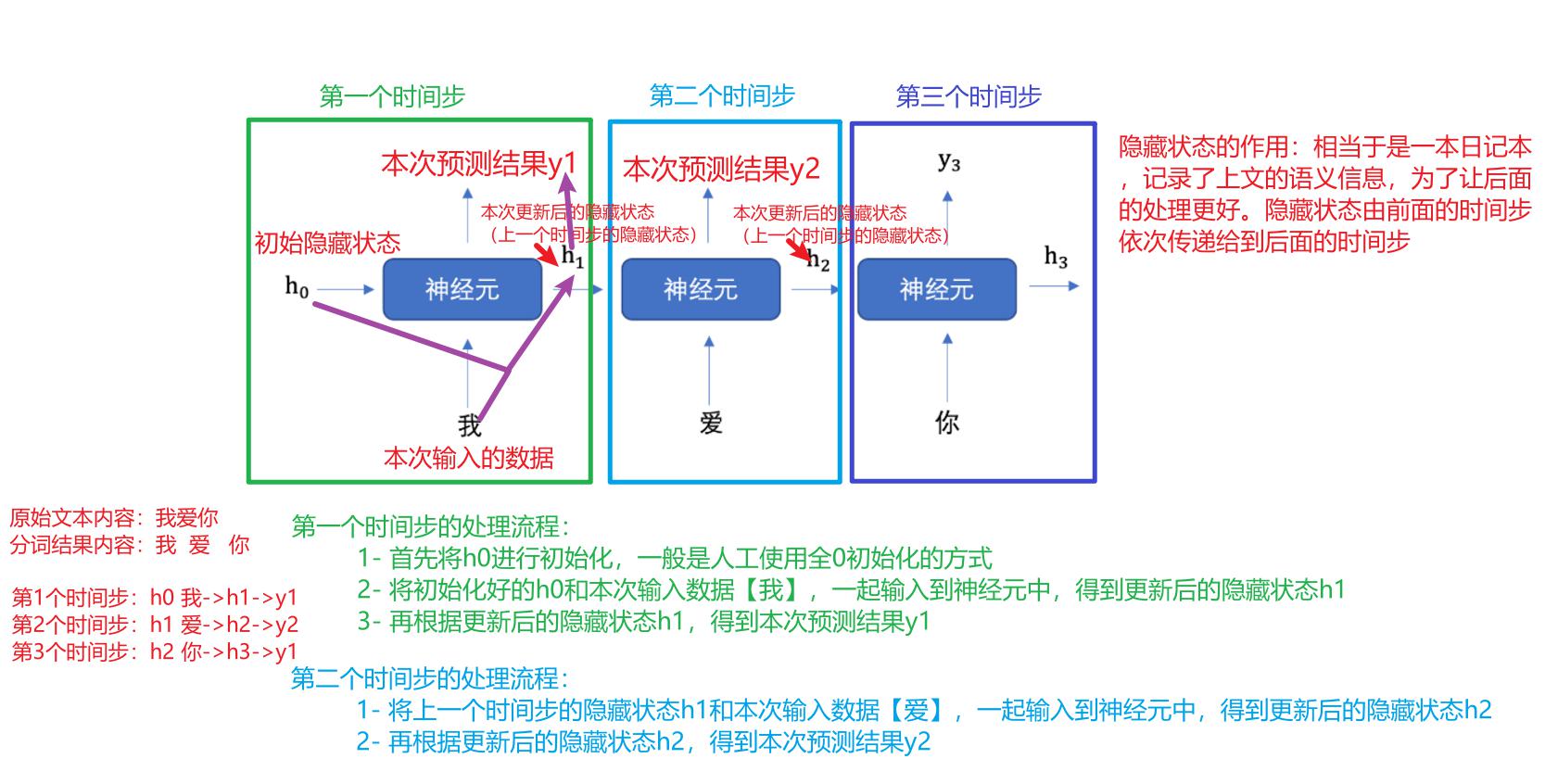
上图中h表示隐藏状态,隐藏状态保存了序列数据中的历史信息,并将这些信息传递给下一个时间步,从而允许RNN处理和预测序列数据中的元素。
每一次的输入都会包含两个值:上一个时间步的隐藏状态、当前状态的输入值x
每一次的输出都会包含两个值:输出当前时间步的隐藏状态、当前时间步的预测结果y
隐藏状态作用:
记忆功能:隐藏状态就像RNN的记忆,它能够在不同的时间步之间传递信息。当一个新的输入进入网络时,当前的隐藏状态会结合这个新输入来生成新的隐藏状态。
上下文理解:由于隐藏状态携带了过去的信息,它可以用于理解和生成与上下文相关的输出。这对于语言模型、机器翻译等任务尤其重要。
连接不同时间步:隐藏状态通过网络内部的循环连接将各个时间步连接起来,使得网络可以处理变长的序列数据。
上图中,为了更加容易理解,虽然画了 3 个神经元, 但是实际上只有一个神经元,”我爱你” 三个字是重复输入到同一个神经元中。
我们举个例子来理解上图的工作过程,假设我们要实现文本生成,也就是输入 “我爱” 这两个字,来预测出 “你”,其如下图所示:
将上图展开成不同时间步的形式,如下图所示:
首先初始化出第一个隐藏状态,一般都是全0的一个向量,然后将 “我” 进行词嵌入,转换为向量的表示形式,送入到第一个时间步,然后输出隐藏状态 h1,然后将 h1 和 “爱” 输入到第二个时间步,得到隐藏状态 h2, 将 h2 送入到全连接网络,得到 “你” 的预测概率。
RNN神经元内部是如何计算的呢?
1. 计算隐藏状态:每个时间步的隐藏状态$$h_t$$是根据当前输入$$x_t$$和前一时刻的隐藏状态$$h_{t-1}$$计算的。
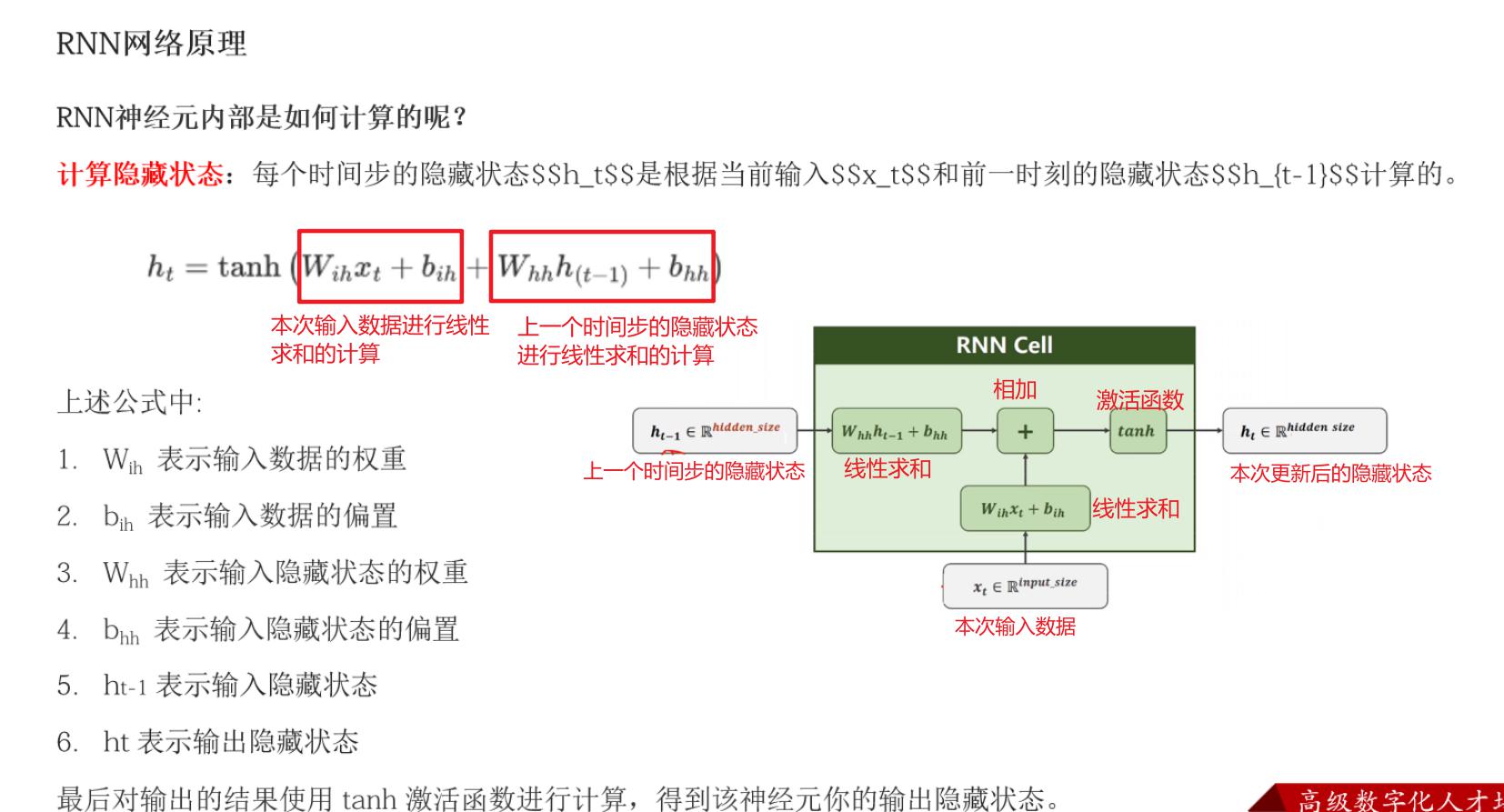
上述公式中:
- $$W_{ih}$$ 表示输入数据的权重
- $$b_{ih}$$ 表示输入数据的偏置
- $$W_{hh}$$ 表示输入隐藏状态的权重
- $$b_{hh}$$ 表示输入隐藏状态的偏置
- $$h_{t-1}$$ 表示输入隐藏状态
- $$h_t$$ 表示输出隐藏状态
最后对输出的结果使用tanh激活函数进行计算,得到该神经元你的输出隐藏状态。
2. 计算当前时刻的输出:网络的输出$$y_t$$是当前时刻的隐藏状态经过一个线性变换得到的。
$$y_t=W_{hy}h_t+b_y$$

- $$y_t$$ 是当前时刻的输出(通常是一个向量,表示当前时刻的预测值,RNN层的预测值)
- $$h_t$$ 是当前时刻的隐藏状态
- $$W_{hy}$$ 是从隐藏状态到输出的权重矩阵
- $$b_y$$ 是输出层的偏置项
3. 词汇表映射:输出$$y_t$$是一个向量,该向量经过全连接层后输出得到最终预测结果$$y_{pred}$$,$$y_{pred}$$中每个元素代表当前时刻生成词汇表中某个词的得分(或概率,通过激活函数:如softmax)。词汇表有多少个词,$$y_{pred}$$就有多少个元素值,最大元素值对应的词就是当前时刻预测生成的词。
神经元工作机制总结:
接收输入:每个RNN神经元接收来自输入数据$$x_t$$和前一时刻的隐藏状态$$h_{t-1}$$。
更新隐藏状态:神经元通过一个加权和(由权重矩阵和偏置项组成)更新当前时刻的隐藏状态$$h_t$$,该隐藏状态包含了来自过去的记忆以及当前输入的信息。
输出计算:基于当前隐藏状态$$h_t$$,神经元生成当前时刻的输出$$y_t$$,该输出可以用于任务的最终预测。
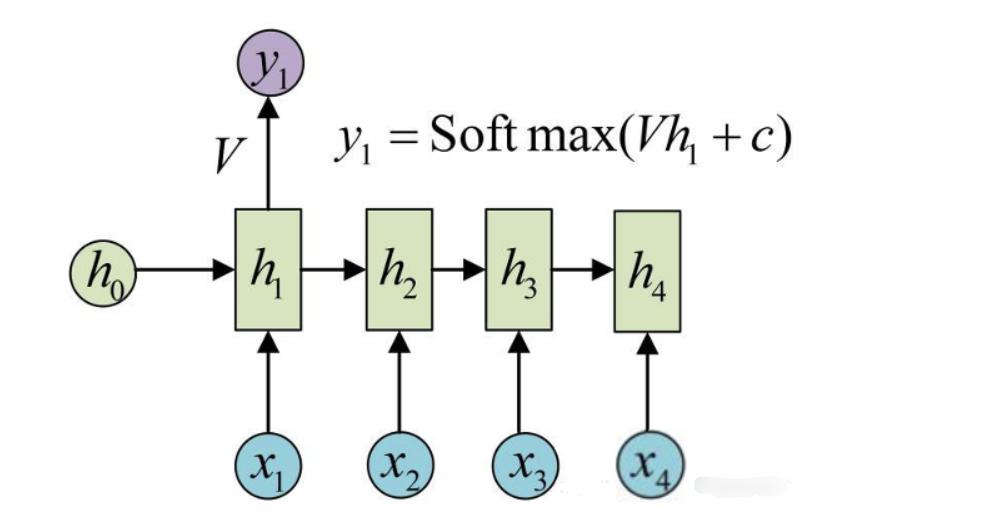
文本生成示例:
假设我们使用RNN进行文本生成,输入是一个初始词语或一段上下文(例如,“m”)。RNN会通过隐藏状态逐步生成下一个词的概率分布,然后根据概率选择最可能的下一个词。
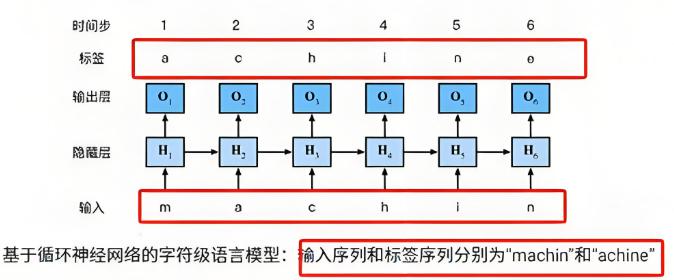
输入:“m” → 词向量输入$$x_1$$(对应“m”)
初始化隐藏状态$$h_0$$,一般初始值为0
隐藏状态更新$$h_1$$,并计算输出$$y_1$$
经过全连接层输出层计算输出$$y_{pred}$$,使用softmax函数将$$y_{pred}$$转换为概率分布
选择概率最高的词作为输出词(例如“a”)
输入新的词“a”,继续处理下一个时间步,直到生成完整的词或句子
小结:在循环神经网络中,词与输出的对应关系通常通过以下几个步骤建立
- 词嵌入:将词转化为向量表示(词向量)。
- RNN处理:通过RNN层逐步处理词向量,生成每个时间步的隐藏状态。
- 输出映射:通过线性变换将隐藏状态映射到输出,通常是一个词汇表中的词的概率分布。
PyTorch RNN层的使用
API介绍
RNN = nn.RNN(input_size, hidden_size,num_layers)参数意义是:
- input_size:输入数据的维度,也就是词向量的维度。可以理解为输入层神经元个数
- hidden_size:隐藏层的维度,也就是当前层神经元输出的数据维度。
- num_layers:隐藏层的层数,默认为1
- 一层隐藏层
import torch
import torch.nn as nn
if __name__ == '__main__':
# 1- 创建RNN循环网络层
"""
参数解释:
input_size:输入的词向量维度。也就是向量中有多少个数字
hidden_size:隐藏状态的向量维度。也就是隐藏状态也是用向量来进行体现
num_layers:隐藏层的层数。也就是循环网络层的层数
"""
rnn = nn.RNN(input_size=4,hidden_size=5,num_layers=1)
# 2- 准备数据
# 2.1- 本次输入数据
x = torch.randn(size=(3, 2, 4))
# 2.2- 上一个时间步的隐藏状态:初始隐藏状态一般使用全0初始化
h0 = torch.zeros(size=(1, 2, 5))
# 3- 调用RNN循环网络层【掌握】
"""
输入参数的张量形状解释:
本次输入数据x,张量形状: [seq_len每条句子中词的个数, batch_size一个批次中句子的条数, input_size词向量的维度]
上一个时间步的隐藏状态h0,张量形状:[num_layers隐藏层的层数, batch_size一个批次中句子的条数, hidden_size隐藏状态的向量维度]
返回结果的张量形状解释:
本次预测结果output,张量形状: [seq_len每条句子中词的个数, batch_size一个批次中句子的条数, hidden_size隐藏状态的向量维度]
更新后的隐藏状态hidden,张量形状:[num_layers隐藏层的层数, batch_size一个批次中句子的条数, hidden_size隐藏状态的向量维度]
"""
output,hidden = rnn(x,h0)
# 4- 输出结果
print(f"本次预测结果的形状:{output.shape}") # [3, 2, 5]
print(f"本次更新后的隐藏状态的形状:{hidden.shape}") # [1, 2, 5]
print(f"本次预测结果的内容:\n{output}")
print(f"本次更新后的隐藏状态的内容:\n{hidden}")
一层隐藏层结果解释:

- 多层隐藏层【了解】
不管是一层隐藏层,还是多层隐藏层,隐藏层输出结果output和更新后的隐藏状态hidden的内容区别如下:
1- 隐藏层输出结果output:记录的是最后一层隐藏层中,每个时间步的隐藏状态
2- 更新后的隐藏状态hidden:记录的是每一层隐藏层中,最后一个时间步的隐藏状态
import torch
import torch.nn as nn
"""
不管是一层隐藏层,还是多层隐藏层,隐藏层输出结果output和更新后的隐藏状态hidden的内容区别如下:
1- 隐藏层输出结果output:记录的是最后一层隐藏层中,每个时间步的隐藏状态
2- 更新后的隐藏状态hidden:记录的是每一层隐藏层中,最后一个时间步的隐藏状态
"""
if __name__ == '__main__':
# 1- 创建RNN循环网络层
"""
参数解释:
input_size:输入的词向量维度。也就是向量中有多少个数字
hidden_size:隐藏状态的向量维度。也就是隐藏状态也是用向量来进行体现
num_layers:隐藏层的层数。也就是循环网络层的层数
"""
rnn = nn.RNN(input_size=4,hidden_size=5,num_layers=2)
# 2- 准备数据
# 2.1- 本次输入数据
x = torch.randn(size=(3, 1, 4))
# 2.2- 上一个时间步的隐藏状态:初始隐藏状态一般使用全0初始化
h0 = torch.zeros(size=(2, 1, 5))
# 3- 调用RNN循环网络层【掌握】
"""
输入参数的张量形状解释:
本次输入数据x,张量形状: [seq_len每条句子中词的个数, batch_size一个批次中句子的条数, input_size词向量的维度]
上一个时间步的隐藏状态h0,张量形状:[num_layers隐藏层的层数, batch_size一个批次中句子的条数, hidden_size隐藏状态的向量维度]
返回结果的张量形状解释:
本次预测结果output,张量形状: [seq_len每条句子中词的个数, batch_size一个批次中句子的条数, hidden_size隐藏状态的向量维度]
更新后的隐藏状态hidden,张量形状:[num_layers隐藏层的层数, batch_size一个批次中句子的条数, hidden_size隐藏状态的向量维度]
"""
output,hidden = rnn(x,h0)
# 4- 输出结果
print(f"本次预测结果的形状:{output.shape}") # [3, 1, 5]
print(f"本次更新后的隐藏状态的形状:{hidden.shape}") # [2, 1, 5]
print(f"本次预测结果的内容:\n{output}")
print(f"本次更新后的隐藏状态的内容:\n{hidden}")
多层隐藏层的结果分析:
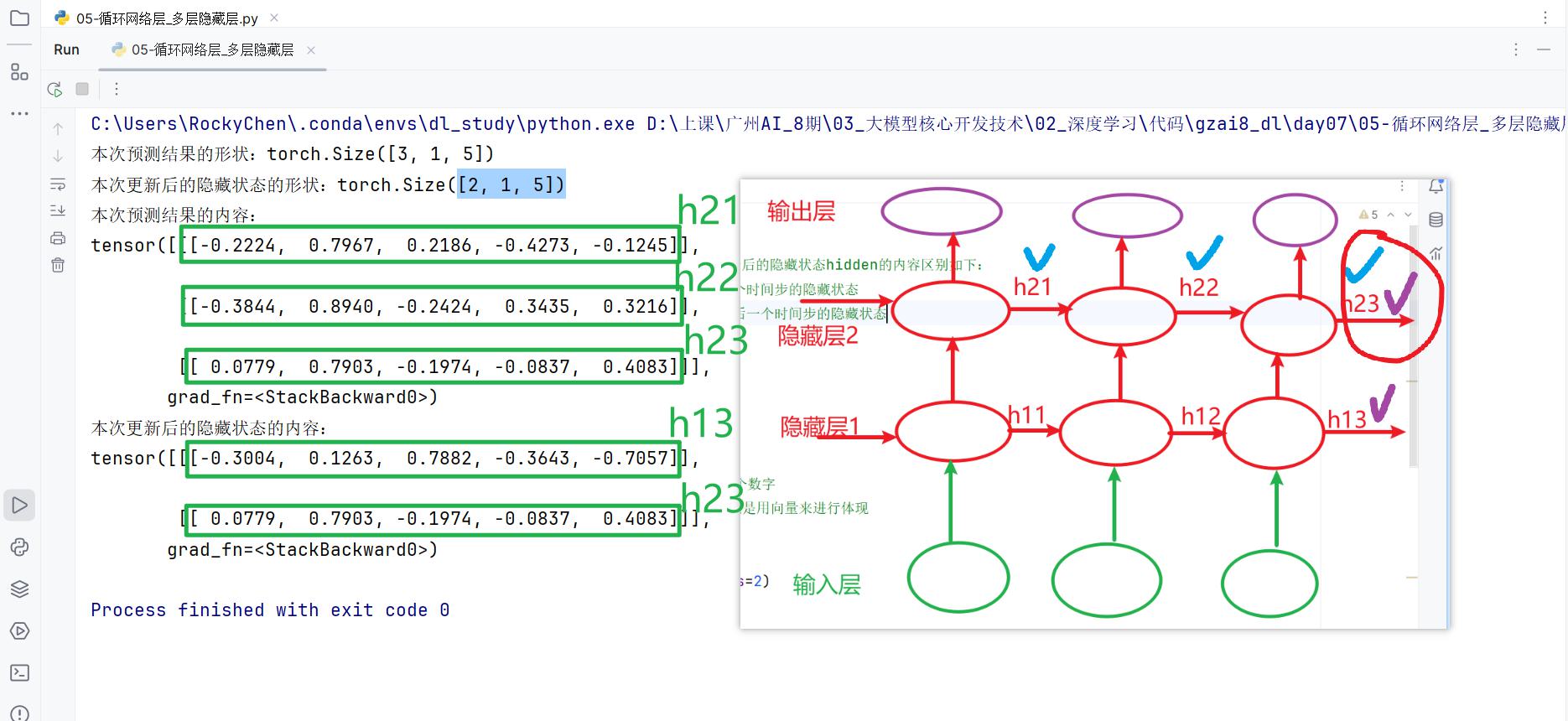
输入数据和输出结果
将RNN实例化就可以将数据送入其中进行处理,处理的方式如下所示:
output, hn = RNN(x, h0)- 输入数据:主要包括词嵌入的x 、初始的隐藏层h0
- x的表示形式为[seq_len, batch, input_size],即[句子中词的个数,batch的大小也就是每次处理多少条句子,词向量的维度]
- h0的表示形式为[num_layers, batch, hidden_size],即[隐藏层的层数,batch的大小也就是每次处理多少条句子,隐藏层的维度]
- 输出结果:主要包括输出结果output,最后一层的hn
- output的表示形式与输入x类似,为[seq_len, batch, input_size],即[句子中词的个数,batch的大小也就是每次处理多少条句子,输出向量的维度]
- hn的表示形式与输入h0一样,为[num_layers, batch, hidden_size],即[隐藏层的层数,batch的大小也就是每次处理多少条句子,隐藏层的维度]
- 输入数据:主要包括词嵌入的x 、初始的隐藏层h0
文本生成案例【理解】
文本生成任务是一种常见的自然语言处理任务,输入一个开始词能够预测出后面的词序列。本案例将会使用循环神经网络来实现周杰伦歌词生成任务。

导入工具包
import torch
import jieba
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
import time
数据集
我们收集了周杰伦从第一张专辑《Jay》到第十张专辑《跨时代》中的歌词,来训练神经网络模型,当模型训练好后,我们就可以用这个模型来创作歌词。数据集如下:
想要有直升机
想要和你飞到宇宙去
想要和你融化在一起
融化在宇宙里
我每天每天每天在想想想想著你
这样的甜蜜
让我开始相信命运
感谢地心引力
让我碰到你
漂亮的让我面红的可爱女人
...
该数据集共有 5819 行文本。
构建词表
在进行自然语言处理任务之前,首要做的就是构建词表。
所谓的词表就是将语料进行分词,然后给每一个词分配一个唯一的编号,便于我们送入词嵌入层。
接下来, 我们对周杰伦歌词的数据进行处理构建词表,具体流程如下:
- 获取文本数据
- 分词,并进行去重
- 构建词表
def build_vocab():
# 1- 读取文件,分词
"""
最后的结果如下:每个子列表代表一句歌词
[[词1, 词2, ..], [词1, 词2, ..]...]
"""
line_list = []
unique_word_list = []
for line in open("data/jaychou_lyrics.txt",encoding="UTF-8",mode="r"):
# 1.1- 分词
word_list = jieba.lcut(line)
line_list.append(word_list)
# 1.2- 对词去重
for word in word_list:
if word not in unique_word_list:
unique_word_list.append(word)
# 2- 构建字典:词作为key,索引作为value
word_to_index = {word:index for index,word in enumerate(unique_word_list)}
# print(f"line_list-->{line_list}")
# print(f"word_to_index-->{word_to_index}")
# 3- 将歌词内容中的词转成索引的表示
"""
需求描述:
第一步:原始歌词内容
想要有直升机
想要和你飞到宇宙去
第二步:每句歌词单独分词,得到line_list
[[想要,有,直升机,\n], [想要,和,你,飞到,宇宙,去,\n]]
第三步:对line_list中每句歌词进行循环,然后将歌词中的词替换成词索引
[[0, 1, 2, 3], [0, 4, 5, 6, 7, 8, 3]]
第四步:将所有的歌词以空格为分隔符拼接到一起
拼接的原因:a、歌词不等长;b、传进去的目标值y可能会出现跨歌词行的情况;c、同时需要将歌词的分界线明确区分
corpus_idx [0, 1, 2, 3, 40, 0, 4, 5, 6, 7, 8, 3, 40...]
"""
# 3.1- 第三步:对line_list中每句歌词进行循环,然后将歌词中的词替换成词索引
# [[0, 1, 2, 3], [0, 4, 5, 6, 7, 8, 3]]
corpus_idx = []
for line in line_list:
# 内层循环对每句歌词进行单独处理
for word in line:
word_index = word_to_index[word]
corpus_idx.append(word_index)
# 3.2- 第四步:将所有的歌词以空格为分隔符拼接到一起
corpus_idx.append(word_to_index[" "])
return len(unique_word_list),word_to_index,corpus_idx,unique_word_list
构建数据集对象
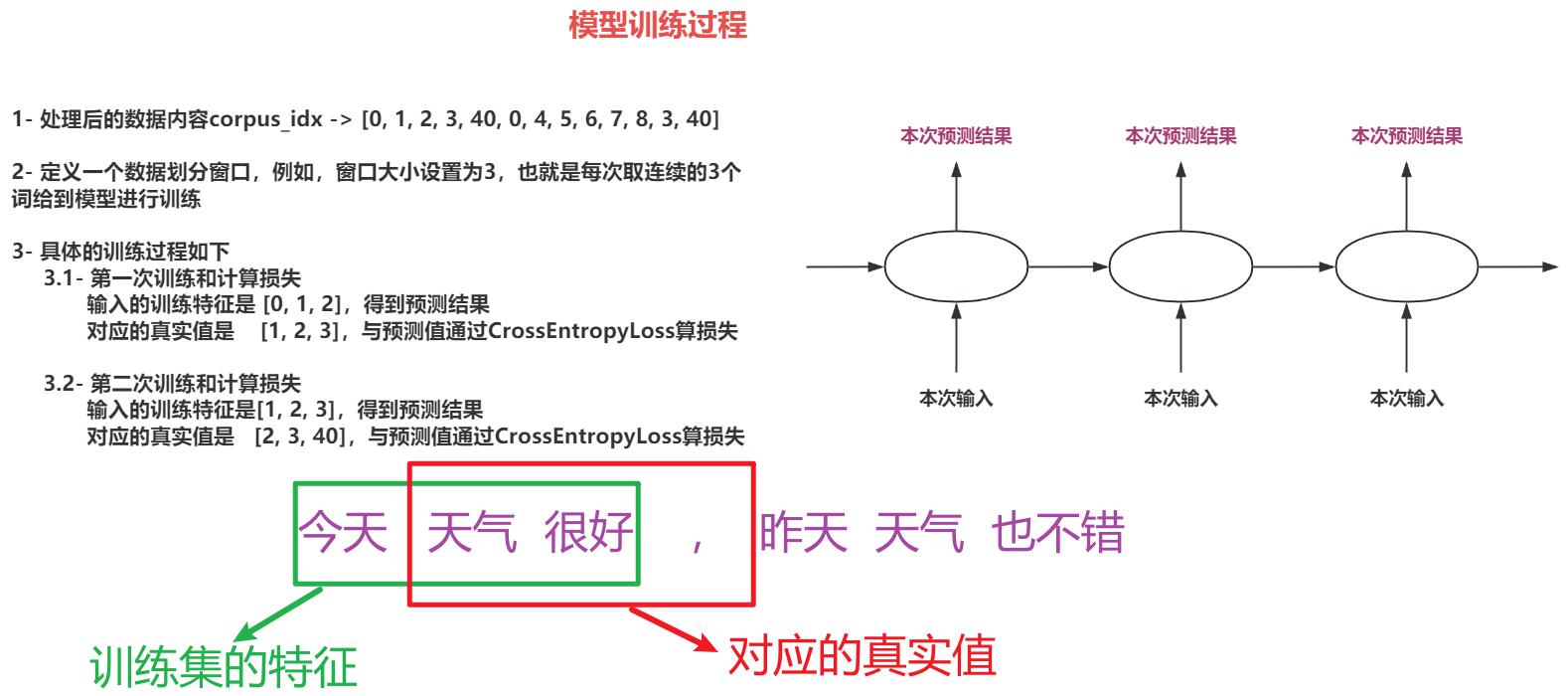
我们在训练的时候,为了便于读取语料,并送入网络,所以我们会构建一个Dataset对象
class LyricsDataset(Dataset):
"""
自定义Dataset的流程如下:
1- 继承Dataset父类
2- 重写如下的3个方法
2.1- __init__:主要用来对属性值进行设置
2.2- __len__:返回样本的条数。len(dataset)的时候,该方法会被自动调用
2.3- __getitem__:根据索引,获得对应的样本数据
"""
def __init__(self,corpus_idx, seq_len):
self.corpus_idx = corpus_idx
self.seq_len = seq_len
self.word_cnt = len(corpus_idx) # 歌词中总的词个数,目前49135
self.sample_cnt = self.word_cnt - self.seq_len # 统计样本条数
def __len__(self):
return self.sample_cnt
def __getitem__(self, index):
# 1- 防止index出现负索引;防止索引越界
"""
防止index出现负索引max(index, 0)
防止索引越界min()
"""
index = min(max(index, 0), self.sample_cnt - 1)
# 2- 获得特征数据的开始索引和结束索引
start = index
end = start + self.seq_len
# 3- 获得特征数据
x = self.corpus_idx[start:end]
# 4- 获得对应的目标值数据
y = self.corpus_idx[start+1:end+1]
return torch.tensor(x), torch.tensor(y)
构建网络模型
我们用于实现《歌词生成》的网络模型,主要包含了三个层:
- 词嵌入层: 用于将语料转换为词向量
- 循环网络层: 提取句子语义
- 全连接层: 输出对词典中每个词的预测概率
简单代码写法:batch_first=True的情况
class LyricsRNNModel(nn.Module):
def __init__(self,unique_word_num):
# 1- 初始化父类
super().__init__()
# 2- 设置属性值
# 词汇表中词的总数
self.unique_word_num = unique_word_num
# 3- 定义网络结构
# 3.1- 词嵌入层
self.ebd = nn.Embedding(num_embeddings=self.unique_word_num,embedding_dim=128)
# 3.2- 循环网络层(隐藏层)
"""
batch_first解释:是否将batch_size的张量形状放在张量的最前面
注意:该参数只会影响调用完RNN后的output,hidden不受影响
也就是output的形状
由原始默认的 [seq_len每条句子中有几个词,batch_size一个批次中有几条句子,hidden_size隐藏状态向量维度]
自动变成 [batch_size一个批次中有几条句子,seq_len每条句子中有几个词,hidden_size隐藏状态向量维度]
"""
self.rnn = nn.RNN(input_size=128,hidden_size=256,num_layers=1,batch_first=True)
# 3.3- 输出层
self.output_linear = nn.Linear(in_features=256,out_features=self.unique_word_num)
def forward(self,input,hidden):
"""
前向传播。相对ANN、CNN来说,RNN往后需要传递两个参数:本次输入数据,上一个时间步的隐藏状态
:param input: 输入数据,张量形状 [batch_size每个批次中有多少条句子, seq_len],里面存储的是词索引
:param hidden: 隐藏状态,张量形状 [num_layers,batch_size,hidden_size]
:return:
"""
# 1- 调用词嵌入层:将词索引转成词向量
print(f"1-->input-->{input.shape}")
embed = self.ebd(input)
print(f"2-->embed-->{embed.shape}")
# 2- 调用循环网络层
"""
输入参数张量形状:
embed:[batch_size,seq_len,input_size]
hidden:[num_layers,batch_size,hidden_size]
输出结果张量形状:
output:[batch_size,seq_len,hidden_size]
hidden:[num_layers,batch_size,hidden_size]
"""
print(f"3-->hidden-->{hidden.shape}")
output,hidden = self.rnn(embed, hidden)
print(f"4-->hidden-->{hidden.shape}")
print(f"5-->output-->{output.shape}")
# 3- 调用输出层得到结果
# 3.1- 将output降维为二维,元素个数不能减少
# [batch_size,seq_len,hidden_size] 转成 [batch_size*seq_len, hidden_size]
print(f"6-->output-->{output.shape[-1]}")
output = output.reshape(-1,output.shape[-1])
print(f"7-->output-->{output.shape}")
# 3.2- 调用线性层
output = self.output_linear(output)
print(f"8-->output-->{output.shape}")
return output,hidden
# 初始化隐藏状态。一般用全0初始化
def init_hidden(self,batch_size):
return torch.zeros(size=(1,batch_size,256))
构建训练函数
前面的准备工作完成之后, 我们就可以编写训练函数。训练函数主要负责编写数据迭代、送入网络、计算损失、反向传播、更新参数,其流程基本较为固定。
由于我们要实现文本生成,文本生成本质上,输入一串文本,预测下一个文本,也属于分类问题,所以,我们使用多分类交叉熵损失函数。优化方法我们学习过 SGB、AdaGrad、Adam 等,在这里我们选择学习率、梯度自适应的 Adam 算法作为我们的优化方法。
训练完成之后,我们使用 torch.save 方法将模型持久化存储。
def train_model(corpus_idx,unique_word_num):
# 1- 准备数据:得到DataLoader
dataset = LyricsDataset(corpus_idx, 30)
dataloader = DataLoader(dataset=dataset,batch_size=32,shuffle=True)
# 2- 创建类的实例对象
# 2.1- 模型实例对象
model = LyricsRNNModel(unique_word_num=unique_word_num)
# 2.2- 损失函数对象
loss = nn.CrossEntropyLoss()
# 2.3- 优化器对象
optimizer = torch.optim.Adam(params=model.parameters(),lr=1e-4,betas=(0.9,0.999))
# 3- 设置模式
model.train()
# 4- 训练
epochs = 30
for epoch in range(epochs):
total_loss_value = 0.0
total_sample_cnt = 0
for i,(x_train,y_train) in enumerate(tqdm(dataloader)):
# 4.1- 前向传播
# 获得当前批次大小,也就是获得当前批次中样本的条数。最后一个批次中的样本条数,不一定够一个完整的批次
# 如果直接写32,会报错:RuntimeError: Expected hidden size (1, 17, 256), got [1, 32, 256]
current_batch_size = x_train.shape[0]
# 初始隐藏状态
hidden = model.init_hidden(current_batch_size)
y_pred,hidden = model(x_train,hidden)
# 4.2- 计算损失
# y_train.reshape(-1)结果是 [batch_size*seq_len]
print(f"9-->y_train-->{y_train.reshape(-1).shape}")
loss_value = loss(y_pred,y_train.reshape(-1))
# 4.3- 更新损失信息
total_loss_value += loss_value.item()
total_sample_cnt += len(y_train)
# 4.4- 反向传播固定代码
optimizer.zero_grad()
loss_value.sum().backward()
optimizer.step()
# 实际工作中没有这块代码
# if i>600:
# break
# 5- 每个轮次输出统计信息
print(f"第{epoch+1}轮次,平均损失{total_loss_value/total_sample_cnt}")
# 6- 保存训练好的模型
torch.save(model.state_dict(),"model/sing.pkl")
构建预测函数
从磁盘加载训练好的模型,进行预测。预测函数,输入第一个指定的词,我们将该词输入网路,预测出下一个词,再将预测的出的词再次送入网络,预测出下一个词,以此类推,知道预测出我们指定长度的内容。
def pred_model(start_word,lyrics_length,word_to_index,unique_word_list):
# 1- 环境准备
# 将开始词变成索引
start_word_index = word_to_index[start_word]
# 2- 加载训练好的模型
model = LyricsRNNModel(unique_word_num=len(word_to_index))
model.load_state_dict(torch.load("model/sing.pkl"))
# 3- 设置模式
model.eval()
# 4- 预测
# 定义变量,用来存储完整的歌词
pred_content = start_word
# 初始隐藏状态
hidden = model.init_hidden(batch_size=1)
for i in range(lyrics_length):
# 4.1- 前向传播
y_pred,hidden = model(torch.tensor([[start_word_index]]),hidden)
# 4.2- 获得预测概率最高的那个词的索引
y_pred_index = torch.argmax(y_pred,dim=-1)
# 4.3- 调整start_word_index的值。将上一个时间步预测词的词索引 作为 本次时间步的输入数据 来使用
start_word_index = y_pred_index
# 4.4- 输出当前的预测结果
pred_word = unique_word_list[y_pred_index]
pred_content += pred_word
print(pred_content)
完整代码
import jieba
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from tqdm import tqdm
def build_vocab():
# 1- 读取文件,分词
"""
最后的结果如下:每个子列表代表一句歌词
[[词1, 词2, ..], [词1, 词2, ..]...]
"""
line_list = []
unique_word_list = []
for line in open("data/jaychou_lyrics.txt",encoding="UTF-8",mode="r"):
# 1.1- 分词
word_list = jieba.lcut(line)
line_list.append(word_list)
# 1.2- 对词去重
for word in word_list:
if word not in unique_word_list:
unique_word_list.append(word)
# 2- 构建字典:词作为key,索引作为value
word_to_index = {word:index for index,word in enumerate(unique_word_list)}
# print(f"line_list-->{line_list}")
# print(f"word_to_index-->{word_to_index}")
# 3- 将歌词内容中的词转成索引的表示
"""
需求描述:
第一步:原始歌词内容
想要有直升机
想要和你飞到宇宙去
第二步:每句歌词单独分词,得到line_list
[[想要,有,直升机,\n], [想要,和,你,飞到,宇宙,去,\n]]
第三步:对line_list中每句歌词进行循环,然后将歌词中的词替换成词索引
[[0, 1, 2, 3], [0, 4, 5, 6, 7, 8, 3]]
第四步:将所有的歌词以空格为分隔符拼接到一起
拼接的原因:a、歌词不等长;b、传进去的目标值y可能会出现跨歌词行的情况;c、同时需要将歌词的分界线明确区分
corpus_idx [0, 1, 2, 3, 40, 0, 4, 5, 6, 7, 8, 3, 40...]
"""
# 3.1- 第三步:对line_list中每句歌词进行循环,然后将歌词中的词替换成词索引
# [[0, 1, 2, 3], [0, 4, 5, 6, 7, 8, 3]]
corpus_idx = []
for line in line_list:
# 内层循环对每句歌词进行单独处理
for word in line:
word_index = word_to_index[word]
corpus_idx.append(word_index)
# 3.2- 第四步:将所有的歌词以空格为分隔符拼接到一起
corpus_idx.append(word_to_index[" "])
return len(unique_word_list),word_to_index,corpus_idx,unique_word_list
class LyricsDataset(Dataset):
"""
自定义Dataset的流程如下:
1- 继承Dataset父类
2- 重写如下的3个方法
2.1- __init__:主要用来对属性值进行设置
2.2- __len__:返回样本的条数。len(dataset)的时候,该方法会被自动调用
2.3- __getitem__:根据索引,获得对应的样本数据
"""
def __init__(self,corpus_idx, seq_len):
self.corpus_idx = corpus_idx
self.seq_len = seq_len
self.word_cnt = len(corpus_idx) # 歌词中总的词个数,目前49135
self.sample_cnt = self.word_cnt - self.seq_len # 统计样本条数
def __len__(self):
return self.sample_cnt
def __getitem__(self, index):
# 1- 防止index出现负索引;防止索引越界
"""
防止index出现负索引max(index, 0)
防止索引越界min()
"""
index = min(max(index, 0), self.sample_cnt - 1)
# 2- 获得特征数据的开始索引和结束索引
start = index
end = start + self.seq_len
# 3- 获得特征数据
x = self.corpus_idx[start:end]
# 4- 获得对应的目标值数据
y = self.corpus_idx[start+1:end+1]
return torch.tensor(x), torch.tensor(y)
class LyricsRNNModel(nn.Module):
def __init__(self,unique_word_num):
# 1- 初始化父类
super().__init__()
# 2- 设置属性值
# 词汇表中词的总数
self.unique_word_num = unique_word_num
# 3- 定义网络结构
# 3.1- 词嵌入层
self.ebd = nn.Embedding(num_embeddings=self.unique_word_num,embedding_dim=128)
# 3.2- 循环网络层(隐藏层)
"""
batch_first解释:是否将batch_size的张量形状放在张量的最前面
注意:该参数只会影响调用完RNN后的output,hidden不受影响
也就是output的形状
由原始默认的 [seq_len每条句子中有几个词,batch_size一个批次中有几条句子,hidden_size隐藏状态向量维度]
自动变成 [batch_size一个批次中有几条句子,seq_len每条句子中有几个词,hidden_size隐藏状态向量维度]
"""
self.rnn = nn.RNN(input_size=128,hidden_size=256,num_layers=1,batch_first=True)
# 3.3- 输出层
self.output_linear = nn.Linear(in_features=256,out_features=self.unique_word_num)
def forward(self,input,hidden):
"""
前向传播。相对ANN、CNN来说,RNN往后需要传递两个参数:本次输入数据,上一个时间步的隐藏状态
:param input: 输入数据,张量形状 [batch_size每个批次中有多少条句子, seq_len],里面存储的是词索引
:param hidden: 隐藏状态,张量形状 [num_layers,batch_size,hidden_size]
:return:
"""
# 1- 调用词嵌入层:将词索引转成词向量
print(f"1-->input-->{input.shape}")
embed = self.ebd(input)
print(f"2-->embed-->{embed.shape}")
# 2- 调用循环网络层
"""
输入参数张量形状:
embed:[batch_size,seq_len,input_size]
hidden:[num_layers,batch_size,hidden_size]
输出结果张量形状:
output:[batch_size,seq_len,hidden_size]
hidden:[num_layers,batch_size,hidden_size]
"""
print(f"3-->hidden-->{hidden.shape}")
output,hidden = self.rnn(embed, hidden)
print(f"4-->hidden-->{hidden.shape}")
print(f"5-->output-->{output.shape}")
# 3- 调用输出层得到结果
# 3.1- 将output降维为二维,元素个数不能介绍
# [batch_size,seq_len,hidden_size] 转成 [batch_size*seq_len, hidden_size]
print(f"6-->output-->{output.shape[-1]}")
output = output.reshape(-1,output.shape[-1])
print(f"7-->output-->{output.shape}")
# 3.2- 调用线性层
output = self.output_linear(output)
print(f"8-->output-->{output.shape}")
return output,hidden
# 初始化隐藏状态。一般用全0初始化
def init_hidden(self,batch_size):
return torch.zeros(size=(1,batch_size,256))
def train_model(corpus_idx,unique_word_num):
# 1- 准备数据:得到DataLoader
dataset = LyricsDataset(corpus_idx, 30)
dataloader = DataLoader(dataset=dataset,batch_size=32,shuffle=True)
# 2- 创建类的实例对象
# 2.1- 模型实例对象
model = LyricsRNNModel(unique_word_num=unique_word_num)
# 2.2- 损失函数对象
loss = nn.CrossEntropyLoss()
# 2.3- 优化器对象
optimizer = torch.optim.Adam(params=model.parameters(),lr=1e-4,betas=(0.9,0.999))
# 3- 设置模式
model.train()
# 4- 训练
epochs = 30
for epoch in range(epochs):
total_loss_value = 0.0
total_sample_cnt = 0
for i,(x_train,y_train) in enumerate(tqdm(dataloader)):
# 4.1- 前向传播
# 获得当前批次大小,也就是获得当前批次中样本的条数。最后一个批次中的样本条数,不一定够一个完整的批次
# 如果直接写32,会报错:RuntimeError: Expected hidden size (1, 17, 256), got [1, 32, 256]
current_batch_size = x_train.shape[0]
# 初始隐藏状态
hidden = model.init_hidden(current_batch_size)
y_pred,hidden = model(x_train,hidden)
# 4.2- 计算损失
# y_train.reshape(-1)结果是 [batch_size*seq_len]
print(f"9-->y_train-->{y_train.reshape(-1).shape}")
loss_value = loss(y_pred,y_train.reshape(-1))
# 4.3- 更新损失信息
total_loss_value += loss_value.item()
total_sample_cnt += len(y_train)
# 4.4- 反向传播固定代码
optimizer.zero_grad()
loss_value.sum().backward()
optimizer.step()
# 实际工作中没有这块代码
# if i>600:
# break
# 5- 每个轮次输出统计信息
print(f"第{epoch+1}轮次,平均损失{total_loss_value/total_sample_cnt}")
# 6- 保存训练好的模型
torch.save(model.state_dict(),"model/sing.pkl")
def pred_model(start_word,lyrics_length,word_to_index,unique_word_list):
# 1- 环境准备
# 将开始词变成索引
start_word_index = word_to_index[start_word]
# 2- 加载训练好的模型
model = LyricsRNNModel(unique_word_num=len(word_to_index))
model.load_state_dict(torch.load("model/sing.pkl"))
# 3- 设置模式
model.eval()
# 4- 预测
# 定义变量,用来存储完整的歌词
pred_content = start_word
# 初始隐藏状态
hidden = model.init_hidden(batch_size=1)
for i in range(lyrics_length):
# 4.1- 前向传播
y_pred,hidden = model(torch.tensor([[start_word_index]]),hidden)
# 4.2- 获得预测概率最高的那个词的索引
y_pred_index = torch.argmax(y_pred,dim=-1)
# 4.3- 调整start_word_index的值。将上一个时间步预测词的词索引 作为 本次时间步的输入数据 来使用
start_word_index = y_pred_index
# 4.4- 输出当前的预测结果
pred_word = unique_word_list[y_pred_index]
pred_content += pred_word
print(pred_content)
if __name__ == '__main__':
# 1- 准备数据
unique_word_num,word_to_index,corpus_idx,unique_word_list = build_vocab()
# print(unique_word_num) # 5703
# print(len(word_to_index))
# print(len(corpus_idx)) # 49135
# 2- 测试自定义数据集
# dataset = LyricsDataset(corpus_idx, 3)
# x,y = dataset[0]
# print(f"{x}")
# print(f"{y}")
#
# print("-"*30)
#
# x, y = dataset[1]
# print(f"{x}")
# print(f"{y}")
# 3- 模型训练
train_model(corpus_idx,unique_word_num)
# 4- 模型评估
pred_model(start_word="太阳",lyrics_length=100,word_to_index=word_to_index,unique_word_list=unique_word_list)
版权声明
本文为 程序员青阳 原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文链接及本声明。