Numpy
Numpy
一、【了解】Numpy优势
Numpy介绍
Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
ndarray:n dimension array
ndarray介绍
NumPy provides an N-dimensional array type, the ndarray,
which describes a collection of “items” of the same type.
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
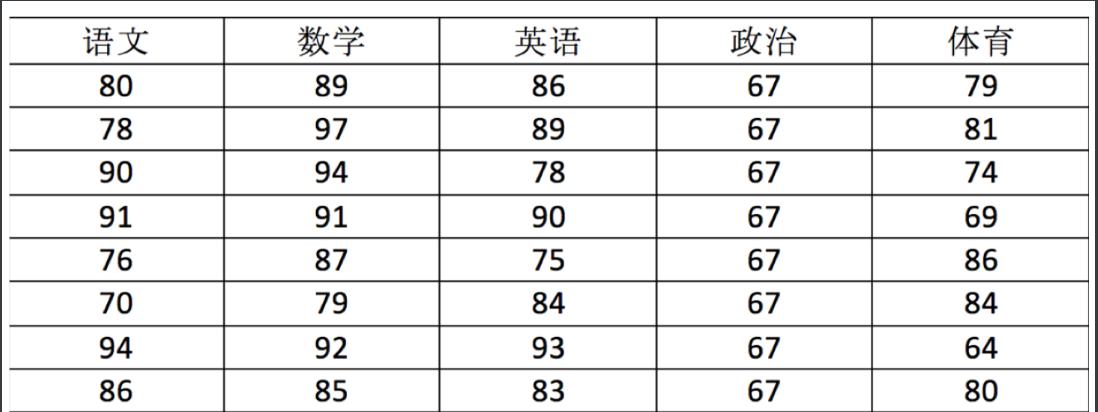
用ndarray进行存储:
import numpy as np
# 创建ndarray
score = np.array(
[[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
score
返回结果:
array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
提问:
使用Python列表可以存储一维数组,通过列表的嵌套可以实现多维数组,那么为什么还需要使用Numpy的ndarray呢?
ndarray与Python原生list运算效率对比
在这里我们通过一段代码运行来体会到ndarray的好处
import random
import time
import numpy as np
a = []
for i in range(100000000):
a.append(random.random())
start = time.time()
sum(a)
print("python运行耗时:",time.time()-start)
print("-"*50)
b = np.array(a)
start = time.time()
np.sum(b)
print("numpy运行耗时:",time.time()-start)
其中第一个时间显示的是使用原生Python计算时间,第二个内容是使用numpy计算时间:
python运行耗时: 0.7574722766876221
--------------------------------------------------
numpy运行耗时: 0.11530804634094238
从中我们看到ndarray的计算速度要快很多,节约了时间。
机器学习的最大特点就是大量的数据运算,那么如果没有一个快速的解决方案,那可能现在python也在机器学习领域达不到好的效果。
Numpy专门针对ndarray的操作和运算进行了设计,所以数组的存储效率和输入输出性能远优于Python中的嵌套列表,数组越大,Numpy的优势就越明显。
思考:
ndarray为什么可以这么快?
ndarray的优势
内存块风格
ndarray到底跟原生python列表有什么不同呢,请看一张图:
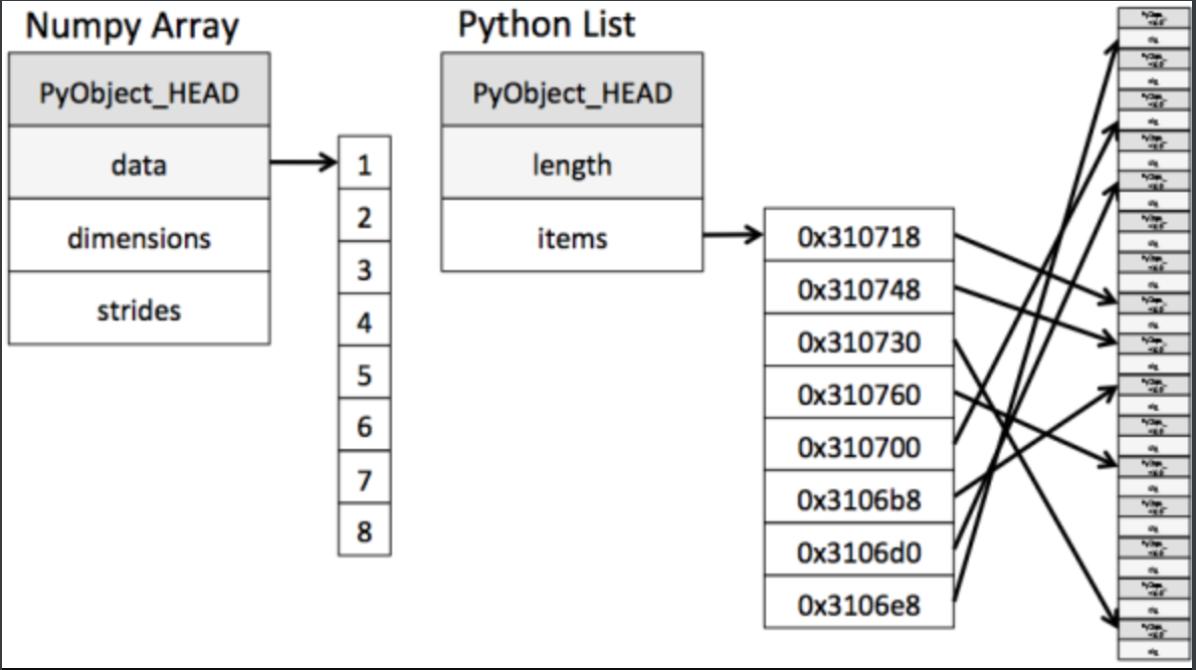
从图中我们可以看出ndarray在存储数据的时候,数据与数据的地址都是连续的,这样就给使得批量操作数组元素时速度更快。
这是因为ndarray中的所有元素的类型都是相同的,而Python列表中的元素类型是任意的,所以ndarray在存储元素时内存可以连续,而python原生list就只能通过寻址方式找到下一个元素,这虽然也导致了在通用性能方面Numpy的ndarray不及Python原生list,但在科学计算中,Numpy的ndarray就可以省掉很多循环语句,代码使用方面比Python原生list简单的多。
ndarray支持并行化运算(向量化运算)
numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算
效率远高于纯Python代码
Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,所以,其效率远高于纯Python代码。
二、ndarray数据结构
掌握内容
属性
shape
dtype
ndarray的属性
数组属性反映了数组本身固有的信息。
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量(个数) |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.dtype | 数组元素的类型 |
ndarray的形状
首先创建一些数组。
arr1 = np.array([11, 22, 33, 44])
print("arr1的维度个数:",arr1.ndim)
print("arr1的形状:",arr1.shape) # 4个元素
print("arr1的元素数据类型:",arr1.dtype)
arr2 = np.array([
[1,2,3],
[4,5,6]
])
print("arr2的维度个数:",arr2.ndim) # 2
print("arr2的形状:",arr2.shape) # 2行3列
print("arr2的元素数据类型:",arr2.dtype)
arr3 = np.array([
[
[1,2,3],
[4,5,6]
],
[
[1,2,3],
[4,5,6]
]
])
print("arr3的元素个数:",arr3.size) # 12个元素
print("arr3的维度个数:",arr3.ndim) # 3
print("arr3的形状:",arr3.shape) # 2,2,3
print("arr3的元素数据类型:",arr3.dtype)
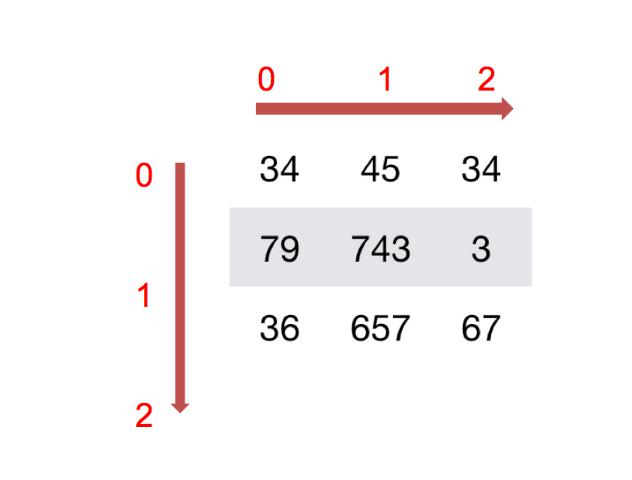
如何理解数组的形状?
二维数组:
三维数组:
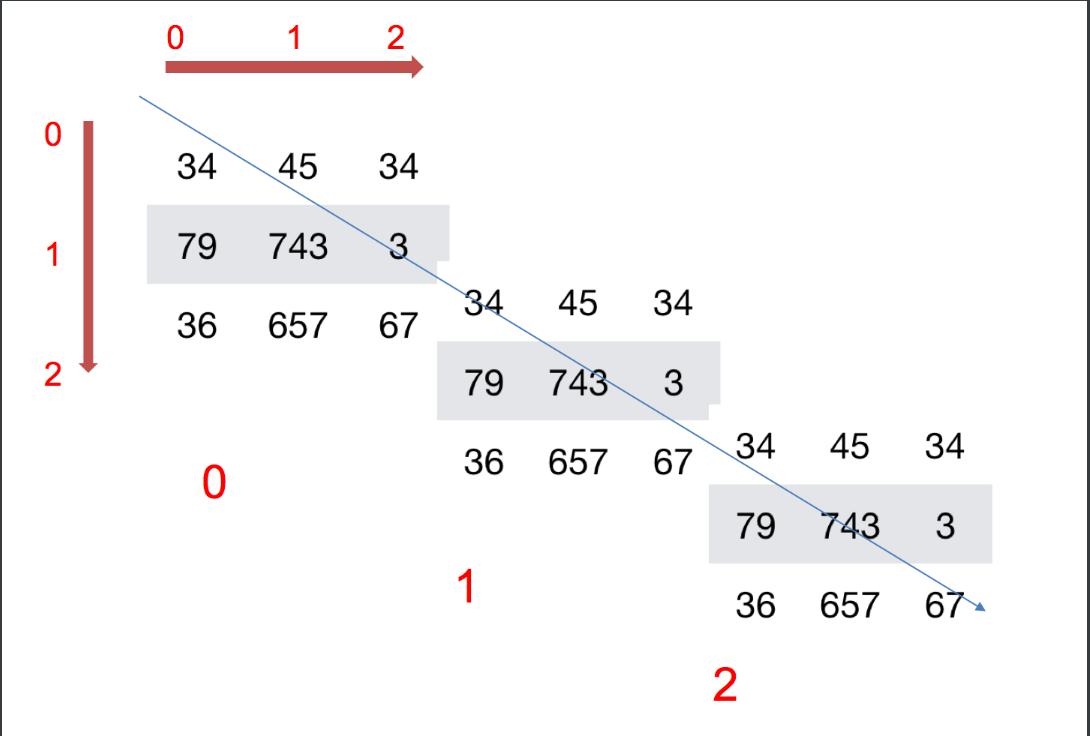
ndarray的类型
| 名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 用一个字节存储的布尔类型(True或False) | ‘b’ |
| np.int8 | tinyint一个字节大小,-128 至 127 | ‘i’ |
| np.int16 | smallint整数,-32768 至 32767 | ‘i2’ |
| np.int32 | int整数,-2^31 至 2^32 -1 | ‘i4’ |
| np.int64 | bigint整数,-2^63 至 2^63 - 1 | ‘i8’ |
| np.uint8 | tinyint unsigned无符号整数,0 至 255 | ‘u’ |
| np.uint16 | smallint unsigned无符号整数,0 至 65535 | ‘u2’ |
| np.uint32 | 无符号整数,0 至 2^32 - 1 | ‘u4’ |
| np.uint64 | 无符号整数,0 至 2^64 - 1 | ‘u8’ |
| np.float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | ‘f2’ |
| np.float32 | float单精度浮点数:32位,正负号1位,指数8位,精度23位 | ‘f4’ |
| np.float64 | double双精度浮点数:64位,正负号1位,指数11位,精度52位 | ‘f8’ |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | ‘c8’ |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | ‘c16’ |
| np.object_ | python对象 | ‘O’ |
| np.string_ | 字符串 | ‘S’ |
| np.unicode_ | unicode类型(字符串) | ‘U’ |
常用的几个:
无符号:只有正数,没有负数,也就是>=0
**np.int32**:32位整数,是最常用的整数类型,适用于大多数整数运算。
**np.float64**:64位浮点数,是默认的浮点数类型,广泛用于科学计算。
**np.bool_**:布尔类型,用于表示True或False,常用于条件判断和逻辑操作。
**np.string_/np.unicode_**:定长字符串类型,常用于二进制数据 或 多语言文本数据
**np.object_**:用于存储任意Python对象,特别是在处理混合类型数据或需要灵活性的时候。
np.string_只支持ASCII编码,不支持Unicode,而np.unicode_支持Unicode字符。
np.string_更适合处理旧有的二进制数据,而np.unicode_更适合处理现代文本数据。
创建数组的时候指定类型
# 小数转成整数,直接舍弃所有的小数内容,只保留整数部分
arr5 = np.array([[1.999, 2.123, 3.456],[4.5, 5.6, 6.7]], dtype=np.int32)
arr5,arr5.dtype
# S15:S是string的首字母;15表示的是最长字符串的长度
arr6 = np.array(['python', 'tensorflow', 'scikit-learnabc', 'numpy'], dtype=np.string_)
arr6,arr6.dtype
arr7 = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.double) # double就是float64
arr7,arr7.dtype
- 注意:若不指定,整数默认int64,小数默认float64
三、基本操作
掌握内容
生成数组
ones
zeros
array
arange
np.random.randint
索引切片
二维数组[行索引开始:行索引结束:步长, 列索引开始:列索引结束:步长],注意是左闭右开的区间
形状修改
reshape
T
去重
unique
生成数组的方法
生成0和1的数组
- **np.ones(shape, dtype)**:创建形状指定的,并且元素值都为1的数组
- np.ones_like(a, dtype) :用于创建一个与数组
a形状相同且所有元素都为1的数组的函数。 - **np.zeros(shape, dtype)**:创建形状指定的,并且元素值都为0的数组
- np.zeros_like(a, dtype) : :用于创建一个与数组
a形状相同且所有元素都为0的数组的函数。
ones = np.ones([4,8])
ones
返回结果:
array([[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.]])
np.zeros_like(ones)
返回结果:
array([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
从现有数组生成
- **np.array(object, dtype)**:新建一个,相当于深拷贝
- **np.asarray(a, dtype)**:没有新建,引用指向同一片内存区域,相当于浅拷贝
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
# 从现有的数组当中创建
a1 = np.array(a)
id(a1)
# 相当于浅拷贝,并没有真正的创建一个新的
a2 = np.asarray(a)
id(a2)
# 修改值
a[1,1] = 99
print(f"a--->{a}")
print(f"a1--->{a1}")
print(f"a2--->{a2}")
生成固定范围的数组
类似于之前讲过的range()
np.linspace (start, stop, num, endpoint)
- 创建等差数组 — 指定数量
- 参数:
- start:序列的起始值
- stop:序列的终止值
- num:要生成的等间隔样例数量,默认为50
- endpoint:序列中是否包含stop值,默认为True
"""
参数解释:
start:开始值
stop:结束值
endpoint:stop是否包含在内
num:等差数组中元素的个数
"""
arr9 = np.linspace(start=1,stop=10,num=10,endpoint=True)
arr9 # 产生的是 10行1列 的 列向量(既有大小,也有方向)
np.arange(start,stop, step, dtype)
- 创建等差数组 — 指定步长
- 参数
- step:步长,默认值为1
# np.arange:使用和参数与range函数完全一样
arr10 = np.arange(start=1,stop=6,step=2)
arr10
np.logspace(start,stop, num)
创建等比数列
参数:
- num:要生成的等比数列数量,默认为50
"""
参数解释:
start:开始值
stop:结束值
endpoint:stop是否包含在内
num:等差数组中元素的个数
base:幂次方的底。a**x,也就是这里的a的值
"""
arr11 = np.logspace(start=0,stop=5,num=6,endpoint=True,base=10)
arr11 = np.logspace(start=0,stop=5,num=6,endpoint=True,base=2)
arr11
生成随机数组
使用模块介绍
- np.random模块
# 设置随机数种子
np.random.seed(523)
"""
np.random.rand():产生0-1的随机小数;结果数据是均匀分布的
"""
arr12 = np.random.rand(2,4)
arr12
"""
np.random.randint:生成指定范围的随机整数
参数解释:
low:范围下限。包含
high:范围上限。不包含
size:数组的形状
"""
arr13 = np.random.randint(low=1,high=7,size=(2,3,4))
arr13
"""
np.random.randn:生成随机小数,结果符合标准正态分布
标准正态分布:也称之为高斯分布。均值mean=0,标准差std=1
"""
arr14 = np.random.randn(10,10,10)
arr14
数组的索引、切片
一维、二维、三维的数组如何索引?
- 直接进行索引,切片
- 二维数组[行索引开始:行索引结束:步长, 列索引开始:列索引结束:步长],含头不含尾
基本索引:
import numpy as np
# 创建一个 2x3 的数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 访问第1行第2列的元素(注意:索引从0开始)
element = arr[0, 1]
print("第1行第2列的元素:", element) # 输出: 2
# 访问第2行第3列的元素
element = arr[1, 2]
print("第2行第3列的元素:", element) # 输出: 6
切片操作
二维数组:可以通过 [row, column] 进行索引和切片,提取特定的行、列或子矩阵。
三维数组:可以通过 [depth, row, column] 进行索引和切片,提取特定的层、行、列或子阵列。
import numpy as np
# 创建一个 7x7 的数组
# 二维数组[行索引开始:行索引结束:步长, 列索引开始:列索引结束:步长]
arr = np.array(
[
[10, 2, 3, 73, 8, 7, 6],
[11, 5, 6, 74, 8, 9, 10],
[22, 5, 6, 75, 8, 9, 10],
[33, 5, 6, 76, 8, 9, 10],
[44, 5, 6, 77, 8, 9, 10],
[55, 5, 6, 78, 8, 9, 10],
[66, 5, 6, 79, 8, 9, 10],
]
)
sub_array = arr[1:6:2, 0:6:3]
print(sub_array)
# 提取第1行和第2行的所有列
sub_array = arr[0:2, :]
print("第1行和第2行的所有列:\n", sub_array)
# 提取第2列和第3列的所有行
sub_array = arr[:, 1:3]
print("第2列和第3列的所有行:\n", sub_array)
# 提取第1行第2列到第3列的元素
sub_array = arr[0, 1:3]
print("第1行第2列到第3列的元素:", sub_array)
- 三维数组索引方式:
# 三维
a1 = np.array([[[1,2,3],[4,5,6]], [[12,3,34],[5,6,7]]])
# 返回结果
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[12, 3, 34],
[ 5, 6, 7]]])
# 索引、切片
sub_array = a1[0, 0, 1]
print(sub_array) # 输出: 2
形状修改
ndarray.reshape(shape)
- 修改前后元素个数不能变
arr2 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
arr2
# reshape前后的元素个数不能变,不能变多不能变少
# reshape中的-1表示Numpy自动的帮我们计算形状
# reshape还可以升维或者降维
arr3 = arr2.reshape(3,3)
arr3 = arr2.reshape(1,9)
arr3 = arr2.reshape(1,-1)
# arr3 = arr2.reshape(1,3,3) # 升维
arr3 = arr2.reshape(9,1,1) # 升维
# 下面的都是错误的写法
# arr3 = arr2.reshape(2,4) # 元素个数少了
# arr3 = arr2.reshape(2,5) # 元素个数多了
# arr3 = arr2.reshape(2,4.5) # 传递小数
arr3
np.resize(数组对象, new_shape)
- 修改前后元素个数可以不同
# 【了解】resize:调整形状前后的元素个数可以不一致
arr3 = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
arr3
# 注意:resize需要通过np来进行调用,不能直接通过具体的array数组调用
arr4 = np.resize(a=arr3,new_shape=(3,3))
arr4 = np.resize(a=arr3,new_shape=(3,4))
arr4 = np.resize(a=arr3,new_shape=(3,2))
arr4
ndarray.T
- 数组的转置
- 将数组的行、列进行互换
import numpy as np
# 创建一个 2x3 的二维数组
arr = np.array([[1, 2, 3],
[4, 5, 6]])
# 对数组进行转置
transposed_arr = arr.T
print("原始数组:\n", arr)
print("转置后的数组:\n", transposed_arr)
运行结果
原始数组:
[[1 2 3]
[4 5 6]]
转置后的数组:
[[1 4]
[2 5]
[3 6]]
类型修改
ndarray.astype(type)
- 返回修改了类型之后的数组
import numpy as np
# 创建一个浮点数类型的数组
arr = np.array([1.1, 2.2, 3.3, 4.4, 5.5])
# 使用 .astype(np.int32) 将数组的元素类型转换为 int32
arr_int32 = arr.astype(np.int32)
print("原始数组:", arr)
print("原始数组的类型:", arr.dtype)
print("转换后的数组:", arr_int32)
print("转换后的数组类型:", arr_int32.dtype)
ndarray.tobytes()
- 构造包含数组中原始数据字节的Python字节
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[12, 3, 34], [5, 6, 7]]])
arr.tobytes()
为什么转二进制?方便网络传输
数组的去重
np.unique()
temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
np.unique(temp)
array([1, 2, 3, 4, 5, 6])
四、ndarray运算
掌握内容
all
any
argmax:与idxmax的作用完全一致,取最大值对应的索引
逻辑运算
# 过滤出分数超过60分,并且小于90分的成绩
score = np.random.randint(40, 100, (10, 5))
six_stu = score[6:, :]
six_stu
# 过滤出分数超过60分,并且小于90分的成绩。将对应成绩设置为1
six_stu[ (six_stu>60) & (six_stu<90)] = 1
six_stu
通用判断函数
np.all()
当你需要检查数组中的所有元素是否都满足条件时使用,如果所有元素都满足条件,返回
True,否则返回Falsenp.any()
当你需要检查数组中是否至少有一个元素满足条件时使用,如果有一个元素满足条件,返回
True,否则返回False
# 判断前4名同学的成绩[0:4, :]是否全及格
four_stu = score2[0:4, :]
four_stu>=60
# 所有学生的所有成绩,全部都>=60分的时候,结果才是True;否则,只要出现一个成绩<60,结果就是False
np.all(four_stu>=60)
# 判断前4名同学的成绩[0:4, :]是否有大于90分的
# 只要能够找出一个值满足条件,结果就是True;否则,全部都不满足的时候才是False
np.any(four_stu>90)
np.where(三元运算符)
通过使用np.where能够进行更加复杂的运算
np.where() => 类似Python中的if…else结构
复合逻辑需要结合np.logical_and和np.logical_or使用
np.random.seed(523)
score3 = np.random.randint(40, 100, (10, 5))
score3
# 判断前四名学生,前四门课程中,成绩中大于60的置为1,否则为0
arr1 = np.where(score3[:4, :4]>60, 1,0)
arr1
# 判断前四名学生,前四门课程中,成绩中大于60且小于90的换为1,否则为0
# 写法一:推荐
arr2 = np.where((score3[:4, :4]>60) & (score3[:4, :4]<90), 1,0)
# 写法二:使用函数包起来
arr2 = np.where(np.logical_and(score3[:4, :4]>60, score3[:4, :4]<90), 1,0)
arr2
# 判断前四名学生,前四门课程中,成绩中大于90或小于60的换为1,否则为0
# 写法一:推荐
arr3 = np.where((score3[:4, :4]<60) | (score3[:4, :4]>90), 1,0)
# 写法二:使用函数包起来
arr3 = np.where(np.logical_or(score3[:4, :4]<60, score3[:4, :4]>90), 1,0)
arr3
统计运算
如果想要知道学生成绩最大的分数,或者做小分数应该怎么做?
统计指标
在数据挖掘/机器学习领域,统计指标的值也是我们分析问题的一种方式。常用的指标如下:
- min(a, axis)
- Return the minimum of an array or minimum along an axis.
- max(a, axis])
- Return the maximum of an array or maximum along an axis.
- median(a, axis)
- Compute the median along the specified axis.
- mean(a, axis, dtype)
- Compute the arithmetic mean along the specified axis.
- std(a, axis, dtype)
- Compute the standard deviation along the specified axis.
- var(a, axis, dtype)
- Compute the variance along the specified axis.
var方差是衡量数据点离平均值的平方偏差程度。方差的值总是非负的,方差越大,数据越分散。
std标准方差是衡量数据点离平均值的平均偏差程度。值越小,数据越集中;值越大,数据越分散。
案例:学生成绩统计运算
score = np.random.randint(40, 100, (10, 5))
print("学生各科成绩的最大分:{}".format(np.max(temp, axis=0)))
print("学生各科成绩的最小分:{}".format(np.min(temp, axis=0)))
print("学生各科成绩波动情况:{}".format(np.std(temp, axis=0)))
print("学生各科成绩的平均分:{}".format(np.mean(temp, axis=0)))
axis=0:表示沿着行的方向(垂直向下)跨越,对每一列进行操作,结果是行数被修改了。
axis=1:表示沿着列的方向(水平向右)跨越,对每一行进行操作,结果是列数被修改了。
该参数的使用和参数值含义,与Pandas中完全一样。
如果需要统计出某科最高分对应的是哪个同学?
- np.argmax(temp, axis=)
- np.argmin(temp, axis=)
print("学生各科成绩最高分对应的学生下标:{}".format(np.argmax(temp, axis=0)))
五、数组间运算
掌握内容
矩阵运算
np.matmul(矩阵A, 矩阵B) 或者 矩阵A@矩阵B
前提:前一个矩阵的列数,与后一个矩阵的行数相同,才能计算。矩阵运算没有广播机制
数组与数的运算
arr = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr + 1
arr / 2
# 可以对比python列表的运算,看出区别 => 列表是整体操作,numpy是每个元素单独操作
a = [1, 2, 3, 4, 5]
a * 3
矩阵运算
矩阵运算的前提:前一个矩阵的列数,与后一个矩阵的行数相同,才能计算
"""
矩阵乘法运算总结:
1- A @ B = C, A的列数 必须 与 B的行数 相同
2- A[m行,n列] B[p行,q列],那么结果C的形状是[m行,q列]
"""
np.random.seed(520)
arr3 = np.random.randint(low=1,high=5,size=(2,4))
arr3
np.random.seed(520)
arr4 = np.random.randint(low=1,high=5,size=(4,3))
arr4
# 写法一:推荐。使用@符号
result_1 = arr3 @ arr4
# 写法二:使用matmul函数。matrix multiply
result_1 = np.matmul(arr3, arr4)
result_1
【了解】数组与数组的运算
广播机制总结:
1- 是Numpy底层内部自动进行的一种机制,我们无法人为的控制
2- 价值:实现形状不同数组之间的运算,核心就是通过广播机制自动的达到数组形状完全相同的前提要求
思考
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]]) # 2 x 6
arr2 = np.array([[1, 2, 3, 4], [3, 4, 5, 6]]) # 2 x 4
上面这个能进行加法运算吗,结果是不行的!
广播机制
数组在进行加法运算时,要求数组的形状要完全相等的。当形状不相等的数组执行算术运算的时候,就会出现广播机制,该机制会对数组进行扩展,使数组的shape属性值一样,这样,就可以进行矢量化运算了。下面通过一个例子进行说明:
arr1 = np.array([[0],[1],[2],[3]]) # 4 x 1
arr1.shape
# (4, 1)
arr2 = np.array([1,2,3]) # 1 x 3
arr2.shape
# (3,)
arr1+arr2
# 结果是:
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])
上述代码中,数组arr1是4行1列,arr2是1行3列。这两个数组要进行相加,按照广播机制会对数组arr1和arr2都进行扩展,使得数组arr1和arr2都变成4行3列。
下面通过一张图来描述广播机制扩展数组的过程:
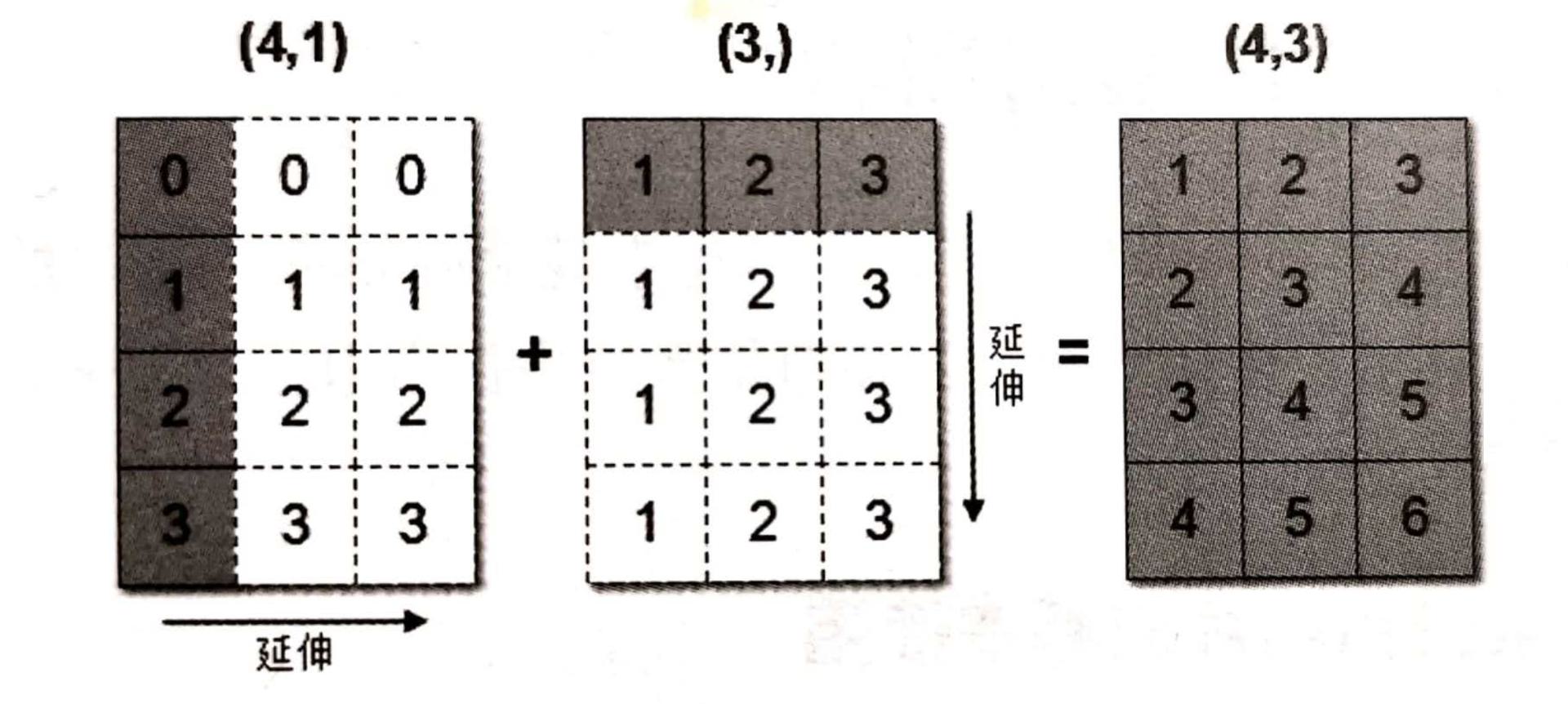
什么情况下才能进行广播机制:
- 形状完全相等
两个数组在该维度上的大小完全相同。
import numpy as np
# 数组 A: 形状 (2, 3)
A = np.array([[1, 2, 3],
[4, 5, 6]])
# 数组 B: 形状 (2, 3)
B = np.array([[10, 20, 30],
[40, 50, 60]])
# 运算
result = A + B
print("结果:\n", result)
运行结果:
[[11 22 33]
[44 55 66]]
- 其中至少一个维度大小为 1
两个数组中,至少有一个在该维度上的大小为 1。NumPy 会自动将这个大小为 1 的维度“拉伸”以匹配另一个数组。
import numpy as np
# 数组 A: 形状 (2, 3)
A = np.array([[1, 2, 3],
[4, 5, 6]])
# 数组 B: 形状 (1, 3)
B = np.array([[10, 20, 30]])
# 运算
result = A + B
print("结果:\n", result)
运行结果:
[[11 22 33]
[14 25 36]]
- 其中一个数组缺少该维度
如果两个数组的维度数量不同,维度较少的数组在前面会被视为用1来填充,然后再进行比较。- 例如:形状为
(3, 4)的数组和形状为(4,)的数组比较时,(4,)会被视为(1, 4),因此它们是兼容的。
- 例如:形状为
import numpy as np
# 1. 创建一个形状: (3, 4)
arr1 = np.array([
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
])
# 2. 创建一个形状: (1,4)
arr2 = np.array([10, 20, 30, 40])
# 3. 进行加法运算
result = arr1 + arr2
print("运算结果:\n", result)
运行结果:
[[11 22 33 44]
[15 26 37 48]
[19 30 41 52]]
思考:下面两个ndarray是否能够进行加法运算?可以
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]]) # (2, 6)
arr2 = np.array([[1], [3]]) # (2, 1)
版权声明
本文为 程序员青阳 原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文链接及本声明。